数据库
数据库的基本概念
数据库:DataBase 按照一定数据结构来组织、存储和管理数据的仓库。存储在一起的相关数据的一个集合。
数据库管理系统:DataBase Management System(DBMS)为管理数据库而设计的一个电脑软件系统。
分为两种:关系数据库:建立在关系模型基础上的数据库 sqlserver mysql oracle access
非关系型数据库:不同点:不使用SQL作为查询语言。
数据库系统:数据库和数据库管理系统组成。
创建数据库
服务器名称:locan . 127.0.0.1 远程:服务器IP,端口号
身份验证: windows身份验证
sql server身份验证:需要登录名和密码
windows身份验证登录,安全性——登录名——右击登录名,选择新建登录名,选择SQL SERVER身份验证,设置登录密码,给她设置服务器角色(也就是权限)。
创建数据库过程:右击数据库节点,选择新建数据库,设置数据库名称,路径。
数据库的组成
数据库:文件的形式
文件和文件组组成。
数据库文件:
MDF:存放数据和数据库的初始化信息。有且只能有一个
NDF:存放除了主要数据文件以外的所有数据库的文件。可有可无,有的话可以有多个
LDF:存放用于恢复数据库的所有日志信息。至少有一个,可以有多个
文件组:是数据库文件的一种逻辑管理单位,它将数据库文件分成不同的文件组,方便对文件的分配和管理。分为两种类型:
1)主文件组 Primary 主要数据文件和没有明确指派给其他文件组的文件
2)用户自定义文件组 create database或alter database语句中, filegroup关键字指定的文件组
设计原则: 1)文件只能是一个文件组的成员
2)文件或文件组不能由一个以上的数据库使用
3)数据和日志信息不能属于同一个文件或文件组
4)日志文件不能作为文件组的一部分
数据库对象
1.表 包含数据库中所有数据的对象,行和列组成,用于组织和存储数据
2.字段 表中的列 自己的属性:数据类型、大小(长度)
3.视图 表(虚拟表)一张或多张表中导出的表 用户查看数据的一种方式,结构和数据是建立在对表的查询基础之上的
4.索引 为了给用户提供一种快速访问数据的途径,索引是依赖于表而建立的,检索数据时,不用对整个表进行扫描,可以快速找到所需的数据。
5.存储过程 是一组为了完成特定功能的SQL语句的集合(可以有查询、插入、删除、修改),编译后,存储在数据库中,以名称进行调用,当调用执行时,这些操作就会被执行。
6.触发器 在数据库中,属于用户定义的SQL事务命令集合,针对于表来说,当对表执行增删改操作时,命令就会自动触发而去执行。
7.约束 对数据表的列,进行的一种限制。可以更好的规范表中的列
8.缺省值 对表中的列可以指定一个默认值,当进行插入时,如果没有为这个列插入值,那么就会自动以预先设置的默认值进行自动补充。
数据类型
数值型:
1)整型:bigint int smallint tinyint
2)浮点型:float 近似数值,存在精度损失 real 近似数值。real=float(24)
decimal 精确数值 不存在精度损失 decimal(18,2)
3)货币型:money smallmoney
4)二进制数据类型:bit binary(n) varbinary(n) varbinary(max) image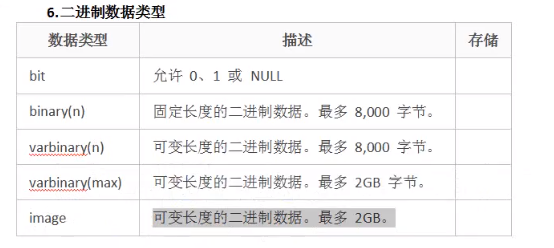
字符型
Character字符串:char(n) varchar(n) varchar(max) text
Unicode字符串:nchar(n) nvarchar(n) nvarchar(max) ntext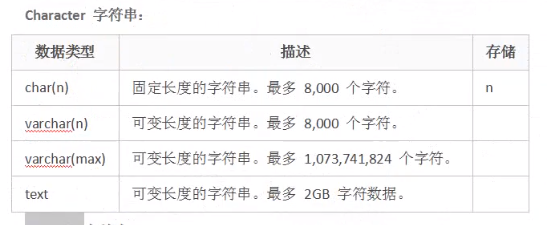
前面带n,存储中文汉字还是英文或数字,长度都是1,存储大小2个字节,。不带n,英文或数字,就是1个字节,中文就是两个长度
日期型
datetime 精确度高,3.33毫秒
datetime2 精度更高,100纳秒
smalldatetime 精度1分钟
date 仅存储日期
time 存储时间
datetimeoffset
timestamp
其他类型
uniqueidentifer 也就是guid(全球唯一标识符)。
创建表及主外键
1、工具创建表 列 数据类型 是否null
一个表中,会存在很多条记录,需要一个列来唯一标识一条数据。
主键:唯一标识一条数据。值非空且唯一
什么是标识列?一个列设置成标识列,它就不能再手动插入,插入时,自动生成的。
这个列,类型必须是不带小数的数值型 整型
标识列:标识种子 第一条记录标识列的值 100 增量
删除了数据,再插入,就会出现不连续的情况 缺点吧n
当你创建了一个表同时也设置了表的主键,此时想要设置标识规范为自增,然而标识规范默认为“否”,原因可能有两方面:
记得Ctrl+S保存此表;
检查表中主键的类型,一般情况下int型可以设置,char、nchar、varchar等类型标识规范都设置不了。
2、创建主键 联合主键 唯一标识
创建一个主键,同时自动创建了一个聚集索引
3、创建外键
外键:一般在两个表之间要建立关联的时候,创建
一个列创建为外键,它在另外一张表必须是主键
两个表一旦建立外键关系,外键表里的对应的外键列,它的值必须是它对应的主键表里的主键值,如果想插入一个不存在的值,是插入不进去的。
一个表里可以有多个外键,也可以没有,一个表只能有一个主键,也可以没主键,但一般都会设置一个主键。
数据库约束
1、约束定义:规定表中的数据规则。如果存在违反约束的数据行为,行为就会被阻止
什么时候创建约束?
创建表之后,使用脚本创建表:可以再创建的过程中,也可以在创建后。
2、分类
主键 primary key 唯一性、非空,不能修改
外键 foreign key 加强两个表的一列或多列数据之间的联系的。先建立主表的主键, 然后再定义从表中外键。只有主表中的主键才能被从表用来作为外键使用。主表限制了从表更新和插入操作。当删除主表中的某种数据,应该是先删除从表中相关的数据,再删除主表。
unique 唯一性约束 确保表中的一列数据没有相同的值。与主键约束相似,但又不同。主键只能有一个,但一个表中可以定义多个唯一约束。
check 通过逻辑表达式来判断数据的有效性,用来限制输入一列或多列的值的范围
default 默认值约束。用户在插入新的数据行时,如果该行没有指定数据,那么系统将默认值赋给该列 ,如果没有设置默认值,系统会默认为NULL。
getdate()
脚本创建数据库
use master --选择要操作的数据库go --批处理命令--为什么创建新的数据库,要选择master?--master:系统数据库,它记录了sql server系统的所有系统级信息,还记录了所有其他数据库的存在,数据库文件的位置,sqlserver的初始化信息。--创建数据库create database TestNewBase --数据库名称on primary --主文件组(name='TestNewBase',--数据库主要数据文件的逻辑名filename='D:\办公软件\SQL SERVER\新建文件夹\TestNewBase.mdf',--数据库主要文件的路径(绝对路径)size=5mb,--数据库主要文件的初始大小filegrowth=1mb--文件的增量)log on --创建日志文件(name='TestNewBas_log',filename='D:\办公软件\SQL SERVER\新建文件夹\TestNewBase.ldf',size=1mb,filegrowth=10%)godrop database TestNewBasego
T-SQL
T-SQL概述

master存储了所有的数据库信息
model数据库会让所有创建的数据库一样
msdb备份还原等功能
tempdb临时存储功能
resource是一个隐藏的只读数据库,看不到的
启动和停止sqlserver服务

补充:可以在服务器名称中输入localhost连接服务器
或者输入一个“.”代表本地
或者是127.0.0.1代表本机地址
或者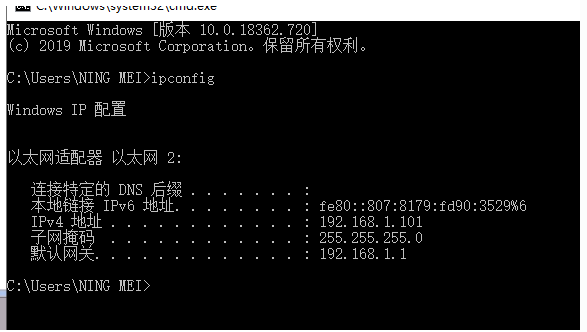
通过IP地址进入
设置通过SQL SERVER验证模式连接服务器的密码
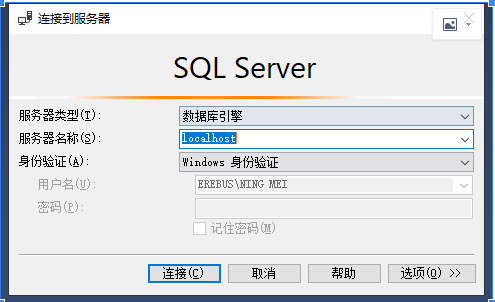
创建表
表信息准备
产品信息表:标识列 int
编号 varchar(50)
名称 nvarchar(50)
产品类型 TypeId int
价格 decimal(18,2)
数量 int
产品类型表:编号 TypeId int
名称 nvarchar(20)
--数据定义语言 dlluse my_databasegocreate table ProductInfos(Id int identity(1001,1) primary key not null, --标识种子,增量ProNo varchar(50) not null,ProName nvarchar(50) not null,TypeId int not null,Price decimal(18,2) default (0.00) null,ProCount int default 0 null)gocreate table ProductType(TypeId int identity(1,1) primary key not null,TypeName nvarchar(50) not null)--删除表drop table ProductInfosgo
模糊查询
like sql提供四种匹配模式:
1、% 0个或多个
2、_ 匹配单个字符
3、[] 范围匹配 括号中所有字符中的一个
4、[^] 不在括号中所有字符之内的单个字符
聚合函数
--select count(1)伪造列select count(1) Record from UserInfos --一般统计一个表的记录数
全连交叉连接
--全连接--full(outer) join 全外连接 返回左表和右表中所有行,当某一行在另一个表中没有匹配,另一个表中的列返回nul--交叉连接--cross join 笛卡尔积 等价于inner join--如果不带where子句时,返回被连接的两个表的笛卡尔积,返回的行数是两个表行数的乘积。--带where子句,等价于inner join返回的是匹配的数据。select * from UserInfos ucross join DeptInfos dwhere u.Dept = D.Dept
类型转换函数convert和cast
--支持 数字+数字 --求和 字符串+字符串--拼接--字符串+数字--需要转换数据类型--convert convert(类型,表达式)select 'cbd' + convert(varchar,2)--把数字转换成字符串,拼接select convert(varchar(10),getdate(),100) ---日期格式--cast(表达式 as 类型)
字符串操作函数
字符串操作:从一个字符串里找一个子串,位置
取子串
大小写
去空格
重复N此
顺序颠倒
替换
--返回字符串中指定的子串出现的开始位置select CHARINDEX('bc','abcdbc') --2 索引从1开始--返回字符串中指定的子串出现的开始位置,子串前后必须带%select PATINDEX('%bc%','abcdbc') --2--大小写转换select LOWER('aCDdG')select UPPER('abdff')--取长度select LEN('abd')select LTRIM(' abd ') --RTRIM TRIM--取子串select LEFT('abddffeed',4) ---rightselect SUBSTRING('bdfdfsasdf',3,4)--从左边第三个开始取4个字符--将指定字符串重复4次select REPLICATE('abc',4)--字符串翻转select REVERSE('abdfdsf')--替换指定字符串select REPLACE('abcdefg','cd','ss')--替换指定长度字符串select STUFF('abcdefg',2,3,'tt')
PATINDEX
CHARINDEX
SUBSTRING
STUFF
REPLICATE
视图、索引、存储过程
索引介绍
1、索引的作用:数据的查询 查理速度 —-应用系统成败的标准。 最普遍—-优化方式
2、索引是什么?一本书 目录 查找页码
索引—目录,快速的定位我们要查找的数据,而不必去扫描整个表。—从而可以加快我们查询的速度。—提高系统的性能。
索引有缺点:占用存储空间,索引并不是越多越好,索引并不总是能提高系统性能的。
索引的目的:可以更快加速高效地查询数据,减少系统的响应时间。
索引分为 聚集索引:Clustered 逻辑顺序与物理顺序是一致的 最多只能有一个,可以没有
主键
非聚集索引:NonClustered 逻辑顺序与物理顺序是并不一致的。 可以有多个,也可以没有
唯一索引
非聚集索引比聚集索引 效率低。
如果需要多个列上建立索引,这些列建立组合索引。
列:小数据类型的, 访问速度特别快。
索引是看不见的,但是如果你创建了索引,在查询大数据的时候,它的优势就是显而易见的。
脚本创建索引
--默认非聚集create clustered index PK_UserInfos --创建主键索引on UserInfos(UserId)with(drop_existing=on --先删除原来的,create一个新的 off不删除原有的,提示一个错误:索引已存在)--唯一非聚集索引create unique nonclustered index uq_UserInfoson UserInfos(UserName)with(pad_index=on, --指定fillfactor时他的设置才有效fillfactor=50,--填充因子,指定创建索引时,每个索引页的数据占索引页大小的百分比,根据读写大小设置--读写比例:1:100 100--读小于写 50-70--读写各一半 80-90ignore_dup_key=on,)--复合索引:多个列上创建的索引create nonclustered index Index_UserInfoson UserInfos(UserName,DeptId)with(drop_existing=on--只有存在索引的时候才能创建,如果为off,那么只有不存在的时候才能创建)
视图介绍
视图:虚拟表 由一个或多个表通过查询而定义的 将查询定义保存起来,实际不包含数据。有例外:有一种类型的视图,当达到某一种条件,它就包含了数据。
与表的区别:表是存储数据的地方,视图存储的是查询语句(索引视图除外,具体化了)
作用:简化查询 将许多表的数据组合到一个表里面
增加数据的保密性 将有秘密性质的数据不显示出来,安全性得到保证
缺点:只是简化查询,并不提高查询速度 增加了维护成本
分类:标准视图 :存储查询定义,没有存储数据。
索引视图(被具体化了的视图,创建了索引,显著提高查询性能,聚合了很多行的查询,不太适合经常更新基本数据集。已经经过计算和存储,可以为视图创建索引),被具体化如果修改那么也会修改原表中的数据
分区视图:一台或多台服务器间水平连接一组成员表的分区数据。
脚本创建视图
------------------创建标准视图------------------------create view vUserInfosNew --视图名称as--T-SQL查询语句select UserId,UserName,DeptId,DeptNamefrom UserInfos uinner join DeptInfos don d.DeptId=u.DeptIdgo--使用视图就和使用表一样select * from vUserInfosNewwhere DeptId>1order by UserId desc---------创建索引视图----------------------------------适合于聚合多行数据的情况下--数据是实际存在,删除视图里的数据,基础表里的数据也被删除--索引视图里不要去删除修改数据--*不能出现,因为被具体化了的--表名前面要加所有者dbocreate view vUserInfos_Index with schemabinding--注意schemabingding关键字asselect UserId,UserName,Age from dbo.UserInfosgo--使用select * from vUserInfos_Index--索引视图创建唯一聚集索引,提高查询效率create unique clustered index uq_vUserInfos_Indexon vUserInfos_Index(UserId)go------------------创建分区视图---------------------create view vTestInfosasselect * from Testunion allselect * from Test3go--使用视图select * from vTestInfos
标准视图与分区视图 都不允许删除修改里面的数据,会影响基础表
索引视图 删除了,对应的基础表数据也被删除了,慎用。
存储过程介绍
存储过程:一种为了完成特定功能的一个或一组SQL语句集合。经编译后存储在服务器端的数据库中,可以利用存储过程来加速SQL语句的执行。调用名称,传入参数,执行来完成特定功能。
分类:系统存储过程:master数据库中,其他数据库中是可以直接调用,并且调用时不必在前面加上数据库名,创建数据库时,这些系统存储过程在新的数据库中自动创建。
自定义存储过程:用户自己创建,完成特定功能而创建。既可以传入参数,也可以有返回值,表名存储过程执行是否成功。里面可以只是一个操作,也可以包括多个。
执行:execute/exec 存储过程名 参数列表(多个参数,以逗号隔开)
优点:1、提高应用程序的通用性和可移植性。多次调用,而不必重新再去编写,维护人员可以随时修改。
2、可以更有效的管理数据库权限。
3、提高执行SQL的速度。——一次编译多次调用
4、减轻服务器负担。
缺点:专门维护它,占用数据库空间。
--语法create proc 存储过程名@userId int,@userName varchar(50)asBEGIN--T-SQL语句ENDGO
脚本创建存储过程
脚本创建存储过程语法
create/alter procedure/proc proName--参数列表asbegin--sql语句集合end--创建一个无参数的存储过程create proc SearchUserInfoNew--修改将create改成alter就行asbeginselect UserId,UserName,Age from UserInfo --也可以从视图查select * from DeptInfosendgo--调用执行exec SearchUserInfoNew--删除存储过程drop proc SearchUserInfoNew--创建带参数的存储过程create proc AddUserInfo@UserName varchar(50),--注意参数一定要带@@UserPwd varchar(50),@Age int,@DeptId intasbegindeclare @time datetime --定义变量set @time=getdate() --变量赋值insert into UserInfos(UserName,UserPwd,CreateTime,Age,DeptId)values(@UserName,@UserPwd,@time,@Age,@DeptId);delete from UserInfos where UserId=17,select * from UserInfosendgo--调用exec AddUserInfo 'lingli','1234',25,3

若有收获,就点个赞吧
0 人点赞
