深入理解 overlayfs(一、原理)_overlay fs-CSDN博客
深入理解overlayfs(二)使用与原理分析_mount -t overlay-CSDN博客
为了方便管理docker image,并且可以重用image,而不是每次都重新做完整的rootfs,docker在设计image中引入了layer的概念,也就是说,用户制作镜像的每一步操作都会生成一个层,也就是一个增量的rootfs。
这样的话,就可以重用基础镜像,并在同一个基础镜像上生成自己的镜像,而自己的镜像中实际是记录的是对基础镜像的修改。
我们知道一个基础镜像上衍生出的image实际上共用基础的rootfs,我们可以在基础image上不断的迭代,最终形成一个最终的image,这个image上应该包含在基础镜像上做的所有改动。每次改动实际上是对rootfs的修改。‘
由于这个最终镜像是分层的,容器肯定是从基础镜像开始挂载,然后一步步挂载后续的改动,但是如果后面的改动修改了同一目录下的不同文件,那么如果后续每一步都重新挂载,那么后挂载的都将覆盖前面的挂载。怎么解决这个问题呢?
答案是联合挂载。即每一次挂载的文件都合并到同一个挂载点下面,这样每次修改了不同文件,改动的文件都会出现在同一个挂载点下面。但是如果修改了相同的文件,还是会出现覆盖的问题。
overlay是liunx自带的联合文件系统,overlay文件系统模型如下:
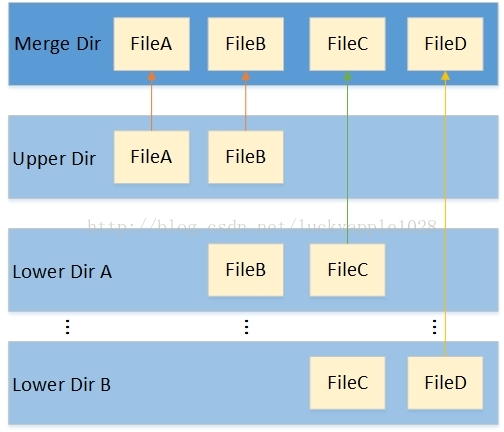
其中merge dir是用户看到的目录内容。upper dir是读写层,下面的都是lower dir,lower dir都是只读的。
merge dir由uppper dir和所有lower dir层合并而来,文件重名则上层覆盖下层,目录重名则继续合并。
当用户修改只读层的文件时,会从上往下的找到对应文件,并复制到upper dir层,后续对文件的修改都在upper dir层的复制文件中进行。(copy on write)
overlay in docker
Docker容器将镜像层(image layer)作为lower dir,将容器层(container layer)作为upper dir,最后挂载到容器merge挂载点,即容器的根目录下。遗憾的是,早期内核中的overlayfs并不支持多lower layer,在Linux-4.0以后的内核版本中才陆续支持完善。而容器中可能存在多层镜像,所以出现了两种overlayfs的挂载方式,早期的overlay不使用多lower layer的方式挂载而overlay2则使用该方式挂载。
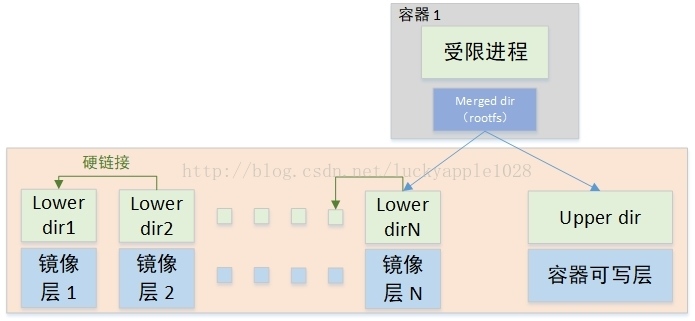
上图就是overlay挂载方式下,镜像层和容器层的组织方式。由于早期的overlay不支持多个lower layer,所以可以看到lower dir层实际上是通过硬链接连在一起的。以此类推,最终挂载overlayfs的lower dir为最上层镜像层目录imager layer N。与此同时,容器的writable dir作为upper dir,挂载成为容器的rootfs。
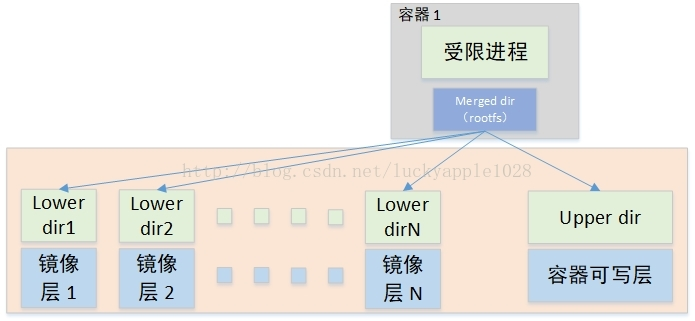
上图是overlay2下的挂载方式,已经不需要硬链接了,直接支持了多lower dir。
overlay的缺点
copy-up
Overlayfs的lower layer文件写时复制机制让某一个用户在修改来自lower层的文件不会影响到其他用户(容器),但是这个文件的复制动作会显得比较慢,后面我们会看到为了保证文件系统的一致性,这个copy-up实现包含了很多步骤,其中最为耗时的就是文件数据块的复制和fsync同步。用户在修改文件时,如果文件较小那可能不一定能够感受出来,但是当文件比较大或一次对大量的小文件进行修改,那耗时将非常可观。虽然自Linux-4.11起内核引入了“concurrent copy up”特性来提高copy-up的并行性,但是对于大文件也还是没有明显的效果。不过幸运的是,如果底层的文件系统支持reflink这样的延时拷贝技术(例如xfs)那就不存在这个问题了。
Rename directory(POSIX标准支持问题)
如果Overlayfs的某一个目录是单纯来自lower layer或是lower layer和upper layer合并的,那默认情况下,用户无法对该目录执行rename系统调用,否则会返回-EXDEV错误。不过你会发现通过mv命令重命名该目录依然可以成功,那是因为mv命令的实现对rename系统调用的-EXDEV错误进行规避(这当然是有缺点的,先暂不展开)。在Linux-4.10起内核引入了“redirect dir”特性来修复这个问题,为此引入了一个内核选项:CONFIG_OVERLAY_FS_REDIRECT_DIR,用户想要支持该特性可以在内核中开启这个选项,否则就应避免对这两类目录使用rename系统调用。
Hard link break(POSIX标准支持问题)
该问题源自copy-up机制,当lower dir目录中某个文件拥有多个硬链接时,若用户在merge layer对其中一个写入了一些数据,那将触发copy-up,由此该文件将拷贝到upper dir,那么和原始文件的hard link也就断开了,变成了一个单独的文件,用户在merge layer通过stat和ls命令能够直接看到这个变化。在Linux-4.13起内核引入了“index feature”来修复这个问题,同样引入了一个内核选项:CONFIG_OVERLAY_FS_INDEX,用户想要修复该问题可以打开这个选项,不过该选项不具有向前兼容性,请谨慎使用。
Unconstant st_dev&st_ino(POSIX标准支持问题)
该问题同样源自copy-up机制,当原来在lower dir中的文件触发了copy-up以后,那用户在merge layer见到了将是来自upper dir的新文件,那也就意味着它俩的inode是不同的,虽然inode中很多的attr和xattr是可以copy的,但是st_dev和st_ino这两个字段却具有唯一性,是不可以复制的,所以用户可以通过ls和stat命令看到的该字段将发生变化。在Linux-4.12和Linux-4.13分别进行了部分的修复,目前在lower dir和upper dir都在同一个文件系统挂载点的场景下,问题已经修复,但lower dir和upper dir若来自不同的文件系统,问题依然存在。
File descriptor change(POSIX标准支持问题)
该问题也同样源自copy-up机制,用户在文件发生copy-up之前以只读方式open文件(这操作不会触发copy-up)得到的文件描述符fd1和copy-up之后open文件得到的文件描述符fd2指向不同的文件,用户通过fd2写入的新数据,将无法从fd1中获取到,只能重新open一个新的fd。该问题目前社区主线内核依然存在,暂未修复。
以上这6点列出了目前Overlayfs的主要问题和限制,将在后文中陆续展开。社区为了让Overlayfs能够更加向支持Posix标准的文件系统靠拢,做出了很多的努力,后续将进一步修复上面提到且未修复的问题,还会增加对NFS Export、freeze snapshots、overlayfs snapshots等的支持,进一步完善overlayfs。
小结

若有收获,就点个赞吧
0 人点赞
