Scala学习笔记
Scala语言概述
Scala语言由Martin Odersky(马丁·奥德斯基)设计,其兼具面向对象和函数式编程的特性,和Java一样运行在Java虚拟机(JVM)中。Scala语言简洁,表达性强,其函数式编程的特性使其在大数据场景中得到广泛使用。
官方文档:
【Scala语言特性】
- Scala程序运行在JVM上,和Java程序一样需经过编译、解释、运行的流程,对应的指令是scalac、scala
- Scala可以直接使用Java类库,并提供特有的类库
- 相比Java,Scala更为面向对象,同时兼具函数式编程的特性
- 语言特性简洁灵活,表达力强
HelloWorld案例
- 编写HelloWorld.scala文件
- 在命令行中编译scala文件为字节码文件
scala HelloWorld.scala,在目录下会生成HelloWorld.class和HelloWorld$.class两个字节码文件- 运行Scala程序
scala HelloWorld- 引入scala库后可以使用java执行生成的字节码文件
java -cp %SCALA_HOME%/lib/scala-library.jar; HelloScala
object HelloWorld {def main(args: Array[String]): Unit = {//scala方法调用println("Hello World")//可使用Java中的方法System.out.println("Hello World")}}
注释
Scala注释包括单行注释、多行注释、文档注释,与Java特性相同
变量&常量
变量var:对象引用可以改变
var variable: String = "Hello Scala"常量val:对象引用不可改变val value: Int = 0,相当于Java中用final修饰的变量 *Scala的变量/常量在定义时必须初始化,类型可以省略,由编译器自动推断类型
标识符
- 可包含数字、字母、下划线、$,且首字符不能是数字
- 只包含操作符,如+—*/!%
- 标识符和Scala关键字相同时使用反引号包括,如
if
权限修饰符
- default:默认是public,无需声明
- protected:仅能在子类中使用,与Java可以在同一包下和子类中使用不同
- private:仅可以在本类中使用
- private[包名]:增加在指定的包下的访问权限
字符串输出格式化
- 使用
+连接字符串:_println_("hello" + " world")- 使用
*复制字符串:_println_("*" * 10)printf格式化输出:_printf_("name:%s; age:%d\n", "xiaoming", 18)- 模板字符串输出:
_println_(s"name:**$**{name}; age:**$**{age}")- 原始字符串输出(仍能使用模板,但转义无效):
_print_(raw"rowstring\t**$**{name}")- 三引号字符串输出(在字符串跨多行时保留缩进格式等)
val temp_table: String = "table0"val str: String =s"""|select A,B,C|from ${temp_table};|""".stripMargin
输入
- 导入
scala.io.StdIn类库,调用其中的方法readLine/readInt等读取键盘输入- 导入
scala.io.Source类库,调用其中的方法Source.fromFile可以获取文件输入
方法传参不可变
- Scala遵循函数式编程理念,强调函数/方法不应该有副作用,因此不能对传入的参数进行修改
- 方法传入的参数默认是val类型,在方法体内部不能改变传入的参数
//初值var variable1 = 0var variable2 = ListBuffer(0, 1, 2, 3)//数值类型的修改def func1(x: Int): Int = {//x = 1 传入的参数默认为val类型,不能修改,会报reassignment to val异常x}//引用类型的修改:def func2(x: ListBuffer[Int]): ListBuffer[Int] = {for (i <- 1 until x.length) {x(i) *= 2}x}//调用:参数默认val类型,不能修改值,但如果是引用类型,地址不变但可以修改容器中的数据println(func1(variable1))println(func2(variable2))
Scala基本语法
数据类型
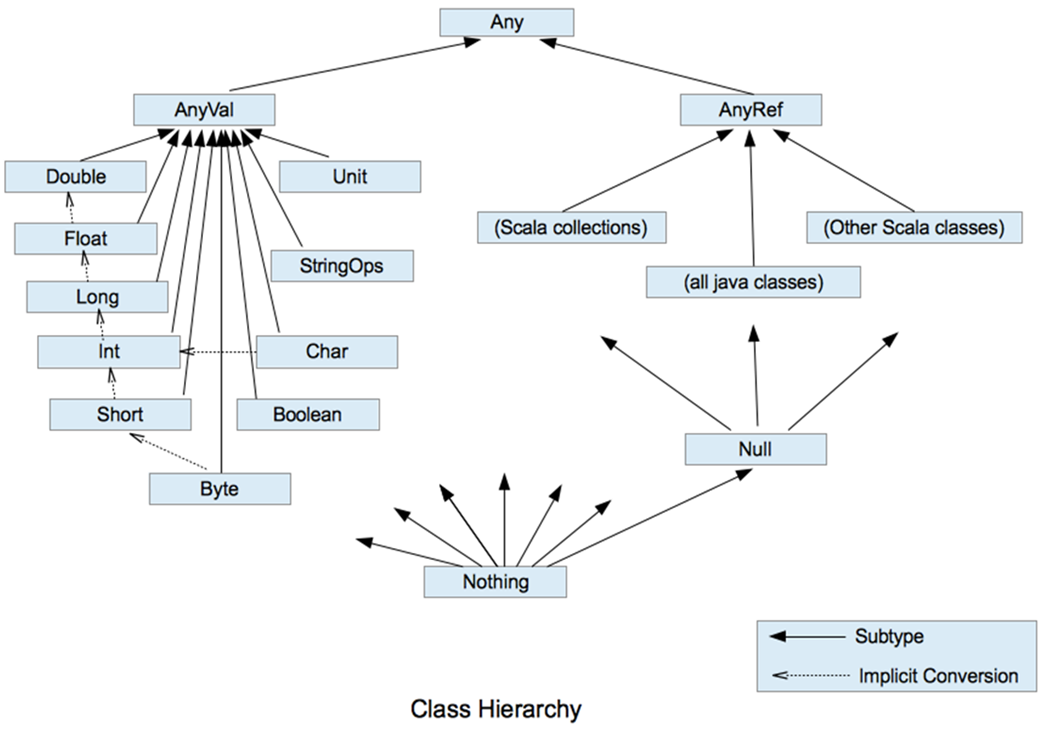
- Scala所有数据都是对象,都是Any的子类
- Any有两个子类:AnyVal数值类型、AnyRef引用类型
- 数值类型都是AnyVal的子类,包括Char、Byte、Short、Int、Long、Float、Double、Boolean、StringOps、Unit
- StringOps是Scala对Java中String类的增强;Unit对应Java关键字void,表示无返回值,仅有一个实例()
- 引用类型都是AnyRef的子类,特别的,Null是所有引用类型的子类,且Null类型仅有一个实例null
- Nothing是所有类型的子类,常用于发出终止信号
类型转换
- 低精度到高精度会自动提升类型,高精度到低精度可调用方法强制转换,但会造成精度丢失
- (byte,short)和char之间不会相互自动转换
- byte,short,char三者可以计算,在计算时会首先转换为int类型
- 数值和字符串之间的转换可以调用对象的方法
println(3.99.toInt) //浮点转整型println(130.toByte) //Int类型转Byteprintln("3.14F".toFloat) //String类型转浮点println(0.toString) //整型转String
运算符
- 算术运算符: + - * / %
- 关系运算符: < > <= >= == !=
- 逻辑运算符: && || !
- 赋值运算符: += -= *= /= =
- 位运算符: << >> >>> & | ~ ^异或
【注意】
- Scala中的
==和equal方法都是比较值是否相等,而eq方法则是比较地址值- Scala没有
++自增、--自减、? :三元运算符Scala的运算符本质是对象的方法,在Scala中的方法调用有两种形式:
对象.方法名(参数值,...)对象 方法名 (参数值,...),如果方法只有一个参数,括号可以省略
流程控制
块表达式
- 由一对花括号
{}包裹的一段代码就是块表达式- 块表达式有返回值,其返回值是
{}中最后一个表达式的结果值
分支结构
Scala的分支控制仅有
if分支判断结构,没有switch结构
if分支有三种主要的用法:
- 单分支:
if(...){...}- 双分支:
if(...){...} else {...}- 多分支:
if(...){...} else if(...) {...} .. else{...}
//分支结构有返回值,返回值为符合条件的分支块表达式的结果值def main(args: Array[String]): Unit = {print("Please input your age:")val age = StdIn.readInt()val res: String = if (age < 18) {"年龄小于18岁"} else if (age < 60) {"年龄大于18小于60岁"} else {"年龄大于60岁"}println(res)}
循环结构
for循环控制
范围遍历
//to和until实际是一个方法调用,返回一个range对象val inclusive: Range.Inclusive = 0.to(5)for (i <- inclusive) println(i)//直接使用range类for (i <- new Range(1, 5, 1)) println(i)//to返回的是左右闭合的集合for (i <- 0 to (5)) println(i) //默认步长为1for (i <- 0 to(5, 2)) println(i) //指定步长为2//倒序打印for (i <- 0 to 5 reverse) println(i)//until返回的是左闭右开的集合for (i <- 0 until (5)) println(i)for (i <- 0 until (5) by 1) println(i) //可用by指定步长//遍历集合对象for (i <- Array(1, 2, 3, 4, 5)) println(i)
循环守卫
在for循环中引入条件判断表达式,如果判断表达式为true进入循环体内部,否则跳过
//循环守卫for(i <- collection if condition) {...}//等价形式:但会进入循环体,但有所区别if (i <- collection) {if (condition) {...}}
嵌套循环
//嵌套循环for (i <- 1 to 5; j <- 1 to 5) {println(s"i:${i};j:${j}")}//等价形式for (i <- 1 to 5) {for (j <- 1 to 5) {println(s"i:${i};j:${j}")}}
引入变量
//引入变量for (i <- 1 to 5; j = i * i) {println(s"i:${i};i^2:${j}")}//for结构可写为多行的形式for {i <- 1 to 5j = i * i} {println(s"i:${i};i^2:${j}")}
yield获取for结构返回值
//for循环默认没有返回值,此时可以使用yield表达式返回数据val ints: immutable.IndexedSeq[Int] = for (i <- 0 to 5 if i % 2 == 0) yield i * i
while循环控制
while和do-while循环结构使用和Java一样,但循环中断没有关键字break和continue,且返回类型是Unit。可以使用抛出异常并捕获的方式实现循环中断,在循环体外捕获可以实现break方式,在循环体内捕获则实现continue方式,Scala也提供了封装的Breaks.breakable方法
def main(args: Array[String]): Unit = {//抛出异常方式:实现breaktry {for (i <- 1 to 10) {print(i + ";")if (i == 5)throw new RuntimeException("break")}} catch {case e => println("break结束循环")}//抛出异常方式:实现continuefor (i <- 1 to 10) {try {if (i == 5)throw new RuntimeException("continue")print(i + ";")} catch {case e => println("continue继续循环")}}//使用Scala封装的函数:实现breakbreakable {for (i <- 1 to 10) {if (i == 5) breakprintln(i)}}//使用Scala封装的函数:实现continuefor (i <- 1 to 10) {breakable {if (i == 5) breakprintln(i)}}}
模式匹配
模式匹配语法使用match关键字声明,每个分支采用case关键字进行声明。匹配从第一个分支开始,如果匹配成功,执行对应的逻辑;如果匹配不成功,继续对下一个分支进行判断;如果所有case都不匹配,那么会执行
case _默认分支。可以在模式匹配中增加条件守卫
模式匹配的使用对象
- 匹配常量
- 匹配类型
- 匹配数组
- 匹配列表
- 匹配元组
- 匹配对象/样例类 ```scala //模式匹配:匹配常量 def func0(x: Any): String = { x match { case 0 => “This is a number zero!” case ‘0’ => “This is a char \’0\’!” case “0” => “This is a string \”0\”!” } } //调用 println(func0(0)) println(func0(‘0’)) println(func0(“0”))
//模式匹配:匹配类型 def func1(x: Any): String = { x match { case i: Int => “整数” case c: Char => “字符” case str: String => “字符串” case _ => “其它类型” } } //调用 println(func1(0)) println(func1(‘ ‘)) println(func1(“string”)) println(func1(0.0))
//模式匹配:匹配数组 def matchfun0(x: Any): String = { x match { case Array(0, ) => “This is a Array of two elements and the first element is zero!” case Array(0, *) => “This is a Array of three or more elements and the first element is zero!” case arr: Array[] => “This is a Array!” case => “This is not a Array!” } } //调用 println(matchfun0(Array(0, 1))) println(matchfun0(Array(0, 1, ‘A’, “Scala”))) println(matchfun0(Array(1, 2, 3))) println(matchfun0(List(0, 1, 2)))
//模式匹配:匹配列表 def matchfun1(x: Any): String = { x match { case List(0, ) => “This is a List of two elements and the first element is zero!” case first :: second :: rest if first == 0 => “This is a List of three or more elements and the first element is zero!” case first :: second :: rest if second == 0 => “This is a List of three or more elements and the second element is zero!” case List => “This is a List!” case => “This is not a List!” } } //调用 println(matchfun1(List(0, 1))) println(matchfun1(List(0, 1, 2))) println(matchfun1(List(-1, 0, 1))) println(matchfun1(List(0, 1, 2, 3))) println(matchfun1(Array(0, 1, 2)))
//模式匹配:匹配元组 val tuple = (“xiaoming”, 27, true, “shenzhen”) println(tuple match { case (name, age, ismale, address) => s”$name is in $address” }) //模式匹配:匹配元组(简化) println(tuple match { case (name, , , address) => s”$name is in $address” }) //对列表中的元组进行匹配 val list = List(“xiaoming 27 shenzhen”, “xiaohong 27 guangzhou”, “xiaotang 28 shanghai”, “xiaoqiang 29 beijing”, “xiaohuang 45 guangzhou”, “xiaoli 27 shenzhen”, “Bob 35 beijing”) //不使用模式匹配 val tuplelist = list.map(x => { val temp = x.split(“ “) (temp(0), temp(1).toInt, temp(2)) }) //使用模式匹配:匹配元组 tuplelist.foreach(x => { println(x match { case (name, age, address) => s”$name is in $address” }) }) //模式匹配:偏函数 tuplelist.map({ case (name, age, address) => s”$name is in $address” }).foreach(println) println(“==================”) //简化 tuplelist.map { case (name, age, address) => s”$name is in $address” }.foreach(println)
```scalaobject matchtest2 {def main(args: Array[String]): Unit = {//匹配对象:匹配对象则对应的对象要实现apply和unapply方法val p = Person("xiaoxia", 27)//val p = nullprintln(p match {case Person("xiaohong", i) => s"* xiaohong is ${i} years old."case Person("xiaoming", i) => s"* xiaoming is ${i} years old."case Person(str, i) => s"${str} is ${i} years old."case _ => "Error"})//匹配对象:使用了样例类val h = Human("xiaoqiang", 35)println(h match {case Human("xiaohong", i) => s"* xiaohong is ${i} years old."case Human("xiaoming", i) => s"* xiaoming is ${i} years old."case Human(name, age) => s"${name} is ${age} years old."case _ => "Error"})}}//手动实现可以使用模式匹配的类要实现伴生类和伴生对象,且在伴生对象中要定义apply和unapply方法//伴生类class Person(val name: String, val age: Int)//伴生对象object Person {//apply方法:传入参数新建对象def apply(name: String, age: Int): Person = {new Person(name, age)}//unapply方法[提取器]:从对象中提取属性def unapply(p: Person): Option[(String, Int)] = {if (p == null) Noneelse Some(p.name, p.age)}}//使用样例类case,自动生成伴生对象,且提供常用方法包含apply和unapply//样例类不用指定val,默认即是valcase class Human(name: String, age: Int)
模式匹配的应用场景
- 变量声明
- for推导式
- 偏函数
//变量声明的模式匹配val (name, age) = ("xiaoming", 25) //取出元组中的值println(name)println(age)val List(first, second, _ *) = List(0, 1, 2, 3, 4) //取出列表中的值println(first)println(second)val firstvalue :: rest = List(0, 1, 2, 3, 4)println(firstvalue)//for推导式val map = Map("A" -> 1, "B" -> 2, "C" -> 3, "D" -> 4, "E" -> 5)for ((k, v) <- map) println(s"key:${k};value:${v}") //推导式形式for ((k, v) <- map if v % 2 == 0) println(s"key:${k};value:${v}") //添加过滤条件
【偏函数:对符合条件的输入参数进行处理,不符合条件的输入参数调用回调函数处理】
- orElse:用于多个偏函数的组合使用
- andThen:用于多个函数的连续调用
- applyorElse:符合条件调用偏函数,否则调用默认的回调函数
val list1: List[Int] = List(-3, -2, -1, 0, 1, 2, 3, 4, 5, 6)//将数组中的int类型的值乘2,负数则乘2后取绝对值//定义偏函数:同时其中使用模式守卫def pfun: PartialFunction[Int, Int] = {case x: Int if x > 0 => 2 * x}def nfun: PartialFunction[Int, Int] = {case x: Int if x < 0 => 2 * -x}def zfun: PartialFunction[Int, Int] = {case x: Int if x == 0 => x}//orElse:组合使用println(list1.map(pfun orElse nfun orElse zfun))//定义偏函数def dfun1: PartialFunction[Int, Int] = {case x: Int => x * x}def dfun2: PartialFunction[Int, Int] = {case x: Int if x > 0 => Random.nextInt(x)case _ => 0}//andThen:连续调用println(list1.map(dfun1 andThen dfun2))//定义偏函数def dfun3: PartialFunction[Int, String] = {case x: Int if x > 0 => s"The positive number is $x"}//applyorElse:符合条件调用偏函数,否则调用默认的回调函数list1.map(x => dfun3.applyOrElse(x, (x: Int) => s"The number $x is negative or zero")).foreach(println)//偏函数用于过滤val list2: List[Any] = List(1, 2, 3, 4, 5, 6, "test")list2.collect({ case x if x.isInstanceOf[Int] => x }).map(x => x.asInstanceOf[Int] + 1).foreach(x => print("~" + x))
下划线的使用(luanru)
- 用于类中的var属性变量的赋初值,使用默认值
- 用于将方法转换为函数
- 匿名函数化简,用下划线代替变量
- 导入包下的所有内容
- 导包时重命名为
_,则表示丢弃/不导入该类或对象- 模式匹配中表示任意数据
函数式编程
- 指令式编程:关注计算机的执行步骤,如C++、Java
- 声明式编程:以数据结构形式表达程序执行的逻辑,如SQL
- 函数式编程:关注数据之间的映射,如Scala、其它语言提供的lambda表示式和闭包
函数基本使用
- 函数的定义
函数定义包括:关键字def,函数名,参数名,参数类型,函数返回值类型,函数体
- 定义在class/object中的函数其实就是方法,可以重载
- 定义在方法中的函数则不能在其作用域内声明同名不同参的其它函数,不可以重载
- 方法保存在方法区中,函数本质是对象,保存在堆中
- 函数调用底层是调用函数对象的apply方法,apply方法名可以省略
- 方法可以手动转换为函数:
方法名 _
//定义函数def func(arg: String): Unit = {println(arg)}//调用函数func("Hello Function!")
- 函数参数
【函数参数的多种形式】
- 可变参数:参数个数不确定,置于参数列表最后
- 参数默认值:指定参数默认值,一般置于参数列表后面
- 带名参数:调用函数时指定参数名称
可变参数不能直接传递集合,如果需要将集合的元素传递给可变参数,可以通过
数组名:_*传递
//可变参数def func2(id: Int, hobbies: String*): Unit = {println(s"ID:${id};Hobbies:${hobbies.mkString(",")}")}//可变参数函数调用func2(0, "hiking", "shopping", "swimming")func2(id = 0, Array("hiking", "shopping", "swimming"): _*)//参数默认值def func3(id: Int = 0, name: String = "xiaoming") = {println(s"id:${id};Name:${name}")}//带默认参数的函数的调用func3(1)//带名参数调用func3(name = "xiaohong", id = 18)
- 函数定义简化
- return可以省略,Scala会使用函数体的最后一行代码作为返回值
- 如果函数体只有一行代码,可以省略花括号
- 返回值类型如果能够推断出来,那么可以省略(
:和返回值类型一同省略) - 如果存在return,则不能省略返回值类型,必须指定
- 如果函数明确声明Unit,那么即使函数体中使用return关键字也不起作用
- 如果期望无返回值类型,可以省略等号,但等号和花括号不能同时省略
- 如果函数无参但声明了参数列表,那么调用时小括号可加可不加
- 如果函数没有声明参数列表,那么调用时小括号必须省略
- 如果不关心名称,只关心逻辑处理,那么函数名(以及def关键字)可以省略
//函数标准写法def func1(str: String): Unit = {println(str)}//仅有一行语句,省略花括号def func2(str: String): Unit = println(str)//返回值类型自动推断,省略返回值类型def func3(str: String) = println(str)//无返回值可以省略等号,但等号和花括号不能同时省略def func4(str: String) {println(str)}//调用func4("Hello World!")//无参但声明了参数列表,调用时括号可加可不加def func5() = println("Hello World!")//调用func5() //调用加括号func5 //调用不加括号//无参且没有声明参数列表,调用时必须省略小括号def func6 = println("Hello Scala!")//调用func6//只关心逻辑,不关心函数名val func7 = (str: String) => println(str)func7("Hello lambda!")
函数高级特性
- 高阶函数
函数的使用除了定义和调用外,还有更高阶的用法:
- 将函数作为值进行传递
- 将函数作为参数进行传递
- 将函数作为返回值进行传递
//函数作为值进行传递val func1 = (a: Int, b: Int) => a + b//调用println(func1(1, 1))//函数作为参数进行传递def func2(array: Array[Int], op: Int => Int) = {for (i <- array) yield op(i)}//调用:将匿名函数作为参数传递val arr = func2(Array(1, 2, 3), 2 * _)//打印返回的值println(arr.mkString(","))//函数作为返回值进行传递def func3(para1: Int): Int => Int = {(para2: Int) => para1 * para2}//调用:返回函数val mutiplyTwo = func3(2)println(mutiplyTwo(5))
- 匿名函数
匿名函数即定义时省略名称的函数,也称为lambda表达式。匿名函数可以按以下原则简化:
- 参数类型可以省略,会根据形参自动推导
- 类型省略后仅有一个参数,可以省略括号;没有参数或参数个数超过一个的不能省略
- 匿名函数仅有一行,可以省略花括号
- 参数只出现一次,且出现顺序和形参列表顺序一致的可以用
_代替 - 简化后仅剩下一个
_,或者简化后的函数存在嵌套,则不能用下划线简化
//匿名函数简化//类型省略val f1: (Int, Int) => Int = (a, b) => {a + b}//调用println(f1(1, 2))//类型省略后仅剩一个参数,可以省略括号val f2: Int => Int = a => {a * a}//调用println(f2(2))//匿名函数仅有一行,花括号可省略val f3: Int => Int = a => a * a//调用println(f3(2))//参数仅出现一次,且按形参列表顺序出现,简化后不会只剩下一个_或是出现嵌套val f4: (Int, Int) => Int = _ + _//调用println(f4(1, 2))
- 闭包Closure&柯里化Currying
闭包:一个函数和与其相关的引用环境(变量)组合的一个整体。当外层函数从栈内存里面释放了,内层函数可以通过打包保存的整体访问到外层函数的变量 柯里化:将函数的一个参数列表的多个参数,变成多个参数列表的过程,在只允许单一参数的框架中使用
//闭包def add1(a: Int): Int => (Int => (Int)) = {def add2(b: Int): Int => Int = {def add3(c: Int): Int = {a + b + c}add3}add2}//调用println(add1(1)(2)(3))//柯里化函数定义def add(a: Int)(b: Int)(c: Int) = a + b + c//调用println(add(1)(2)(3))//另一种调用val f = add(1)(2) _println(f(3))
- 递归
函数在函数体内又调用了本身,称为递归调用
//递归:求阶乘def factorial(n: Int): Int = {if (n <= 0) return 1n * factorial(n - 1)}//调用println(factorial(5))//尾递归优化
- 控制抽象
- 值调用:按值传递参数,计算值后再传递,多次调用的结果相同
- 名调用:按名称传递参数,直接用实参替换函数中使用形参的地方,多次调用会产生不同的结果
def f = (math.random() * 10).toInt//值调用 [传入类型x:Int]def func1(x: Int): Unit = {println("x第一次的值:" + x)println("x第二次的值:" + x)}//调用函数func1(f)//名调用 [传入类型x:=>Int]def func2(x: =>Int): Unit = {println("x第一次的值:" + x)println("x第二次的值:" + x)}//调用函数func2(f)
- 惰性加载
当函数返回值被声明为
lazy时,函数的执行将被推迟,直到首次取值时该函数才会执行,注意lazy不能修饰var类型的变量
def main(args: Array[String]): Unit = {//惰性加载lazydef add(a: Int, b: Int): Int = {println("执行add函数")a + b}//调用lazy val res = add(1, 2)println("before lazy load")println(s"res:${res}")}
- 利用函数递归、控制抽象实现的while循环
面向对象
包package
【Scala包管理方式】
- 包名之间使用
.分隔表示包的层级关系,如com.org.example- 通过嵌套的风格表示层级关系:一个源文件中可以声明多个包,父包访问子包需要导包,子包可以直接访问父包的内容
package com {package lys {//父包中访问子包中的对象需要导包import com.lys.scalatest.packageObject.valueobject parentObject {val parentvalue:String = "parentvalue"println(value) //父包使用子包内的变量,要导入子包}//定义包对象:定义在包对象中的成员,作为对应包下的共享变量package object scalatest {val title: String = "Package Test"}//包对象与包声明在同一作用域中package scalatest {object packageObject {val value: String = "Package content"def main(args: Array[String]): Unit = {println(title) //包对象中的共享变量println(parentObject.parentvalue) //子包直接访问父包中的变量,无需导包}}}}}
【导包方式】
- Java风格:文件首行使用import导入,文件中的所有类都可以使用
- 局部导入:什么时候使用什么时候导入,在其作用范围内都可以使用
【包导入的通配符/限制等】
import com.org.example._:导入所有成员import com.org.example.{A,B}:导入指定成员import com.org.example.{A=>AnotherName}:导入指定成员并重命名import com.org.example.{A=>_,_}:导入所有成员但屏蔽A
类Class
类的基本使用
- 定义类:
class 类名(){...}- 创建对象:
new 类名(参数值,...)- 定义属性:
[修饰符] val/var 属性名:类型 = 值,var修饰的属性可以使用_初始化- 定义方法:
[修饰符] def 方法名(参数名:类型,...):返回值类型 = {方法体}- 封装:Scala为兼容Java API的使用提供了
@BeanProperty注解,该注解能够自动生成属性的setter和getter方法,@BeanProperty注解不能用在private修饰的属性上。Scala的属性默认相当于public,但其底层实现为private,对外通过对象.属性的方式直接进行操作(底层为setter和getter方法),所以一般不将属性设置为private- 构造器:
- 主构造器:定义在类名后面以
()形式表示,语法为class 类名([修饰符] [val/var] 属性名:类型[=默认值],...),主构造器中val/var修饰的非private属性在class内部/外部都能使用,不用val/var修饰的变量是局部变量,只能在class内部使用- 辅助构造器:定义在class内部,语法为
def this(参数名:类型,...){this(...);其它语句}
object test01 {def main(args: Array[String]): Unit = {//创建类的实例:对象val test1 = new ClassTest1//对象的属性和方法调用test1.variable1 = "xiaoming"test1.setVariable1("xiaohong")println(test1.toString)//类的构造器val test2 = new ClassTest1("xiaoming", 18)println(test2.toString)val test3 = new ClassTest1("xiaohong", 18, false)println(test3.toString)}}//类的定义:定义语法/封装/访问权限/构造器//类的访问权限默认为public,对整个工程可见class ClassTest1 { //主构造器无参数,省略了小括号//属性//该注解会生成getter和setter方法@BeanPropertyvar variable1: String = _@BeanPropertyvar variable2: Int = _private var variable3: Boolean = true//常量不能赋默认值,需显式指定private val value1: String = "test"//方法override def toString: String = {s"variable1:${variable1};variable2:${variable2};variable3:${variable3};value1:${value1}"}//辅助构造器def this(name: String, age: Int) {this() //辅助构造器首行必须调用主构造器或其它辅助构造器variable1 = namevariable2 = age}//辅助构造器可以定义多个def this(name: String, age: Int, ismale: Boolean) {this(name, age)variable3 = ismale}}
类的继承
- 类的继承:
class 子类名 extends 父类名 { 类体 }- Scala继承和Java相同点:子类继承父类的属性和方法,且只能是单继承,构造器按父类到子类顺序调用
- Scala继承和Java不同点:Scala中属性和方法都是动态绑定,而Java中只有方法为动态绑定
object test02 {def main(args: Array[String]): Unit = {//父类val test1 = new ClassTest2("xiaoming", 18, true, "Hello xiaoming!")println(test1.toString)println(test1.getVariable1)println(test1.getValue2)//子类val test2 = new ClassTest3(Array("Playing Game", "Study", "Sport", "Work"), "xiaoming", 27, true, "Day Day Up!")println(test2.toString)test2.printhobbies//动态绑定特性//java中的动态绑定只对方法有效,对属性无效/scala中的动态绑定对方法和属性均有效val classop: ClassTest2 = test2classop.func //输出为"This is in ClassTest3!"println(classop.getValue2)}}//主构造器中的形参类型:1.不使用任何修饰符修饰的为局部变量/2.var修饰的为类的可修改的成员属性//3.val修饰的为类的不可修改的成员属性class ClassTest2(@BeanProperty var variable1: String, var variable2: Int, ismale: Boolean, private val value1: String) {//属性private var variable3: Boolean = ismale//方法override def toString: String = {s"variable1:${variable1};variable2:${variable2};variable3:${variable3};value1:${value1}"}@BeanProperty//方法:用于动态绑定测试def func = println("This is in ClassTest2!")//属性:用于动态绑定测试@BeanPropertyval value2: String = "make living!"}//定义继承ClassTest2的子类ClassTest3class ClassTest3(@BeanProperty var hobbies: Array[String], variable1: String, variable2: Int,ismale: Boolean, value1: String) extends ClassTest2(variable1, variable2, ismale, value1) {def printhobbies: Unit = {println(s"$variable1:${hobbies.mkString(",")}")}//方法:动态绑定override def func: Unit = println("This is in ClassTest3!")//属性:动态绑定@beanGetteroverride val value2: String = "earn big money!"}
抽象类
- 定义抽象类:通过abstract关键字标记抽象类,其中可以包含抽象属性和抽象方法
- 抽象属性:属性没有初始化,就是抽象属性
- 抽象方法:只声明而没有实现的方法,就是抽象方法
抽象类使用的要点:
- 父类为抽象类,子类需要将抽象的属性和方法实现,否则子类也需声明为抽象类
- 重写非抽象方法和属性需要用override修饰,重写抽象方法和属性则可以不加override
- 子类中调用父类的方法使用super关键字
子类对非抽象属性重写,父类该非抽象属性只能是val 类型,因为var可变类型直接修改值即可,无需重写
object test03 {def main(args: Array[String]): Unit = {val oneperson = new OnePerson("xiaoming")oneperson.func1(oneperson.name)oneperson.func2()//匿名子类new Person {override var name: String = "xiaohong"override def func1(str: String = this.name): Unit = println(s"${str} love China!")}.func1()}//抽象类abstract class Person {//抽象属性:没有初始化var name: String//抽象方法:没有定义函数体def func1(str: String): Unit//普通属性val country: String = "China"val province: String = "Beijing"//普通方法def func2(): Unit = println("I am Chinese!")}//继承class OnePerson(override var name: String) extends Person { //初始化属性//重写抽象方法:可不加overridedef func1(str: String): Unit = println(s"${str} love China!")//var非抽象变量不能重写,val常量可重写override val province: String = "GuangDong"override def func2(): Unit = {super.func2() //使用super调用父类方法println("I am Cantonese!")}}}
伴生类&伴生对象
Scala是完全面向对象的语言,没有静态属性/方法的概念,但可以用单例对象实现与静态类似的功能。单例对象名和类名一致,则称该单例对象为类的伴生对象。类的所有“静态”内容都可以在它的伴生对象中声明
- 伴生对象采用object关键字声明
- 伴生对象对应的类称为伴生类,伴生对象和伴生类名称一致,且两者必须定义在同一个源文件中
- 属性和方法可以通过伴生对象名直接调用访问
- 使用new关键字构建对象时,调用类的构造方法;直接使用类名构建对象时,调用伴生对象的apply方法
- 若伴生类主构造器
()前加上private修饰符,则只能通过伴生对象的apply方法创建对象,因编译器底层对apply方法的支持,可以省略为类名(参数)的形式调用 - apply方法可以重载,对应调用类不同的构造器
object test04 {def main(args: Array[String]): Unit = {//属性方法可直接通过伴生对象名调用println(Companion.getCountry)Companion.func1//伴生类的使用:未将伴生类构造器声明为私有可以new创建对象//new Companion().func0()//利用伴生对象提供的饿汉式单例模式返回Companion对象,但要屏蔽掉apply方法Companion.getInstance.func0()//apply方法:编译器底层支持,可以省略apply方法名Companion.apply().func0()Companion.apply("GuangDong").func0()//省略后的形式Companion().func0()Companion("GuangDong").func0()}}//伴生对象object Companion {//静态属性@BeanPropertyvar country: String = "China"var name: String = "xiaoming"//静态方法def func1(): Unit = println(s"I am ${name}")//返回单例对象private val instance: Companion = new Companion()def getInstance = instance//applydef apply(): Companion = new Companion()def apply(pro: String): Companion = new Companion(pro)}//伴生类class Companion private(pro: String = "Beijing") {var province: String = pro//可访问伴生对象中的属性/方法def func0(): Unit = {println(country + ":" + province)func1()}}
特质
- Scala语言中的特质Trait相当于接口,Trait中可以有抽象属性和方法,也可以有具体的属性和方法
- 一个类可以混入(mixin)多个特质,Trait是对类单继承机制的补充
- 没有继承父类添加特质:
class 类名 extends 特质 1 with 特质 2 with 特质 3 …- 继承父类同时混入特质:
class 类名 extends 父类 with 特质 1 with 特质 2 with 特质 3…- 动态混入:创建对象时混入trait,无需在类声明时混入,提高类使用的灵活性
- 依赖注入:在声明特质的首行添加
_: 依赖的特质/类 =>引入方法和属性
object test05 {def main(args: Array[String]): Unit = {//动态混入:按需混(luan)入新的特质val p = new implement("A example") with trait2 {}println(p.basevar0)p.display()}}trait trait0 {//特质0@BeanPropertyval value0: String = "value0"}trait trait1 {//特质1@BeanPropertyval value1: String = "value1"}trait trait2 {//依赖注入_: trait1 =>//特质2@BeanPropertyval value2: String = "value2"//依赖trait1部分def display(): Unit = println(s"value1:$value1;value2:$value2")}abstract class base {var basevar0: Stringdef func(): Unit}class implement(override var basevar0: String) extends base with trait0 with trait1 {override def func(): Unit = println("实现类混入特质0/特质1")}
类型检查
object test06 {def main(args: Array[String]): Unit = {//多态val b: A = new B()//isinstanceof判断是否是该类对象println(b.isInstanceOf[A])println(b.isInstanceOf[B])//类的信息println(classOf[B]) //获取类的信息println(b.getClass) //获取对象的类//对象类的转换println(b.asInstanceOf[B])}}class Aclass B extends A
集合
- Java集合类型:列表List、集合Set、映射Map;Scala集合类型:序列Seq,集合Set,映射Map
- 不可变集合(scala.collection.immutable):集合长度不可修改,每次修改都会返回新对象而不会修改原对象
- 可变集合(scala.collection.mutable):可以直接对原对象进行修改,而不会返回新的对象
可变集合
可变数组ArrayBuffer
- 通过apply方法创建:
ArrayBuffer[元素类型](初始元素,...) - 使用new形式创建:
new ArrayBuffer[元素类型]() - 获取指定角标元素:
数组名(角标) - 修改指定角标元素:
数组名(角标) = 值
- 通过apply方法创建:
可变列表ListBuffer
- 通过apply方法创建:
ListBuffer[元素类型](初始元素,...) - 使用new形式创建:
new ListBuffer[元素类型]() - 获取指定角标元素:
集合名(角标) - 修改指定角标元素:
集合名(角标) = 值
- 通过apply方法创建:
可变集合mutable.Set
- 通过apply方法创建:
mutale.Set[元素类型](初始元素,...) - 可变集合特征:有序不可重复
- 通过apply方法创建:
可变映射mutable.Map
- 通过apply方法创建:
mutable.Map[K的类型,V的类型](K->V,K->V,...) - 获取所有的键key:keyset、keys、keysIterator方法
- 获取所有的值value:values、valuesIterator方法
- 根据键获取值:
getOrElse(key,默认值)存在返回对应值,不存在返回默认值 - 修改指定键的值:
集合名(key)=value
- 通过apply方法创建:
不可变集合
不可变数组Array
- 通过apply方法创建:
Array[元素类型](初始元素,...) - 使用new形式创建:
new Array[元素类型](数组的长度) - 获取指定角标元素:
数组名(角标) - 修改指定角标元素:
数组名(角标) = 值
- 通过apply方法创建:
不可变列表List
- 通过apply方法创建:
List[元素类型](初始元素,...) - 特殊的添加元素方式:
::代表添加单个元素到集合最前面,类似+:,用::连接多个值时,最后一个::的右边必须是不可变的List或Nil,Nil是空列表 - 特殊的添加元素方式:
:::代表添加指定不可变List集合中所有元素到集合最前面,类似++: - 获取指定角标元素:
集合名(角标) - 修改指定角标元素:
集合名.updated(角标,值)
- 通过apply方法创建:
不可变集合Set
- 通过apply方法创建:
Set[元素类型](初始元素,...) - 不可变集合特征:无序不可重复
- 通过apply方法创建:
不可变映射Map
- 通过apply方法创建:
Map[K的类型,V的类型]( K->V, K->V,...) - 获取所有的键key:keyset、keys、keysIterator方法
- 获取所有的值value:values、valuesIterator方法
- 根据键获取值:
getOrElse(key,默认值)存在返回对应值,不存在返回默认值 - 修改指定键的值:
集合名.updated(key,value)
- 通过apply方法创建:
元组tuple
- 通过
()方式创建:(初始元素,...) - 通过
->方式创建(二元):K -> V - 元组一旦定义就不能修改、添加、删除元素
- 元组最多只能存放22个元素
- 元组获取元素:
元组名._N
- 通过
集合的通用操作
- 添加:
+、+:、:+、+=、+=:、++、++:、++=、++=: - 删除:
-、-=、--、--= - 修改:
update、updated- 带
+与带-方法的区别:带+是添加元素,带-是删除元素 - 一个与两个
+/-的区别:一个+/-是添加/删除单个元素,两个+/-是添加/删除指定集合所有元素 - 冒号在前后以及不带冒号的区别:冒号在前/不带冒号是将元素添加在集合最后面,冒号在后是将元素添加在集合最前面
- 带
=与不带=的区别:带=是在原集合中添加/删除元素,不带=是添加/删除元素生成新集合,原集合没有改变 - update与updated的区别:update是修改原集合的元素,updated是生成新的集合,原集合没有改变
- 带
集合操作demon
数组
//不可变数组//创建//创建方式1:新建对象val arr1 = new Array[Int](3)arr1(0) = 0arr1(1) = 1arr1(2) = 2println(arr1.mkString(","))//创建方式2:apply方法val arr2 = Array(0, 1, 2)println(arr2.mkString(","))//遍历//for循环遍历for (i <- arr1) println(i)//迭代器遍历:仅一次使用val it = arr1.iteratorwhile (it.hasNext) {println(it.next)}//迭代器遍历:可多次使用val itor = arr1.toIterableitor.foreach(println)//foreach遍历arr1.foreach(println)arr1.foreach(i => println("The number is " + i))//增改:部分操作会生成新的arrayprintln(arr1.++(Array(3, 4, 5)).mkString(",")) //增加集合:默认添加的集合放在array最后面println(arr1.++:(Array(-3, -2, -1)).mkString(",")) //增加集合:添加的集合放在array最前面println(arr1.+:(-1).mkString(",")) //增加单个元素:增加的元素放在array最前面println((-1 +: arr1).mkString("_")) //省略的写法println(arr1.:+(3).mkString(",")) //增加单个元素:增加的元素放在array最后面println((arr1 :+ 3).mkString("_")) //省略的写法arr1.update(0, 100) //更新索引处的元素,直接修改原数组println(arr1.mkString(","))arr1(0) = 0 //编译器对update方法做了支持,可以省略方法名println(arr1.mkString(","))println("========================================")//可变数组//创建val arraybuffer1 = ArrayBuffer(1, 2, 3) //使用伴生对象的apply方法生成val arraybuffer2 = new ArrayBuffer[Int]() //手动new创建对象//增删改:在原集合上修改arraybuffer2.append(0) //在数组最后面添加元素arraybuffer2.appendAll(Array(1, 2)) //在数组最后面添加集合元素arraybuffer2.insert(0, -1) //insert可以在指定索引处插入元素arraybuffer2.insertAll(0, Array(-3, -2)) //insertall可以在指定索引处插入集合元素arraybuffer2.+=(3) //带等号=表示改变原数组arraybuffer2.+=:(-4) //:指代原数组的元素//符号操作的简化arraybuffer2 += 4-5 +=: arraybuffer2arraybuffer2.update(0, -100) //更新数组的元素值arraybuffer2(0) = -5arraybuffer2.remove(0) //删除元素println(arraybuffer2.mkString(","))//修改并生成新的数组println((arraybuffer1.+:(0)).mkString(","))println((arraybuffer1.:+(4)).mkString(","))println((0 +: arraybuffer1 :+ 4 :+ 5).toString())println("=====================================")//可变数组与不可变数组的转换val arr1_buffer = arr1.toBuffer //不可变数组转换为可变数组println(arr1_buffer.getClass) //打印类型val arraybuffer1_toarr = arraybuffer1.toArray //可变数组转换为不可变数组println(arraybuffer1_toarr.getClass) //打印类型//多维数组val arr = Array.ofDim[String](2, 3) //2行3列的数组for (i <- 0 until 2; j <- 0 until 3) arr(i)(j) = s"($i,$j)"arr.flatten.foreach(println)
列表
//不可变列表val list1: List[Int] = List[Int](0, 1, 2) //List为抽象类不能使用new方式创建对象,仅可用伴生对象的apply方法生成val list2: List[Int] = List.apply(0, 1, 2) //显式调用apply方法生成val list3: List[Int] = Array(0, 1, 2).toList //其它集合转变为列表//增删改:会生成新的集合对象println(list1.:+(3).mkString(",")) //:表示集合原数据位置println(list1.+:(-1).mkString(","))println(list1 ++ Array(3, 4, 5))println(Array(-3, -2, -1) ++: list1)val temp: List[Int] = (-1 +: list1) ++ (Array(3, 4) :+ 5)println(temp)//::即在集合前面加上元素println(-2 :: -1 :: list1)println(list1.::(-1))//空集合为Nilprintln((0 :: 1 :: 2 :: 3 :: Nil).mkString(","))//合并集合println(list2 ++ list3)println(list2 ::: list3)println(list3.:::(list2))//可变列表val listbuffer1: ListBuffer[Int] = ListBuffer(1, 2, 3) //使用伴生对象apply生成val listbuffer2: ListBuffer[Int] = new ListBuffer[Int]()//增删改listbuffer1.prepend(0) //列表最开始位置加入元素listbuffer2.append(0) //列表最后位置加入元素listbuffer2.appendAll(Array(1, 2)) //列表最后位置加入集合元素listbuffer2.insert(0, -1) //指定位置插入listbuffer2.remove(0) //删除//带=号均表示在原来的集合对象上做修改listbuffer2.+=:(-1) //元素添加在最前listbuffer2.+=(3) //元素添加在最后println(listbuffer1)
集合
//不可变集合set:有序不重复val set: Set[Int] = Set(1, 2, 3, 3, 4)println(set.+(5, 6, 7)) //多次相同操作输出结果一致,内部有序println(set.+(5, 6, 7)) //多次相同操作println(set + 5 + 6 + 7) //简化写法println(set.contains(0)) //判断是否包含某元素//可变集合set:无序不重复val mset: mutable.Set[Int] = mutable.Set(0, 1, 2)mset.add(3) //添加元素mset += 4mset.remove(0) //删除元素mset -= 4println(mset)
映射
//不可变mapval map1: Map[String, Int] = Map("xiaoming" -> 18, "xiaohong" -> 20)val map2: Map[String, Int] = Map(("xiaoming", 18), ("xiaohong", 20))//遍历key/valuemap1.keys.foreach(println)map1.values.foreach(println)//获取指定key对应的value值//使用 get 访问 map 集合的数据,会返回特殊类型 Option(选项): 有值(Some),无值(None)println(map1.get("xiaoming").get)println(map1.get("xiaoqiang").getOrElse("Error"))println(map1.getOrElse("xiaohong", "Error"))//可变mapval map3 = mutable.Map("xiaoming" -> 18, "xiaohong" -> 20)val map4 = mutable.Map(("xiaoming", 18), ("xiaohong", 20))map3 += ("xiaoqiang" -> 23) //增加map3 -= ("xiaoqiang") //删除map3.put("xiaoqiang", 23) //使用put添加元素map3("xiaoli") = 27map3.update("xiaoming", 25) //修改元素map3("xiaohong") = 26println(map3)//map遍历map3.foreach((kv: (String, Int)) => println(kv))map3.foreach(kv => println(s"k:${kv._1};v:${kv._2}"))map3.map { case (str, i) => s"name:$str;age:$i" }.foreach(println)
元组
//元组val tuple = ("xiaoming", 27)//访问元组._N方式println(tuple._1)println(tuple._2)//访问元组:索引方式println(tuple.productElement(0))//迭代器方式for (i <- tuple.productIterator) println(i)//模式匹配方式println(tuple match {case (name, age) => s"name:$name;age:$age"})
队列
//队列val queue = mutable.Queue(1, 2, 3)queue.enqueue(4, 5, 6) //入队操作println(queue.dequeue()) //出队操作println(queue)
集合的函数
基本属性操作
- 获取集合长度: length/size
- 判断集合是否为空: isEmpty
- 判断集合是否包含某个元素: contains
- 将集合所有元素拼接成字符串: mkString(分隔符)
- 将集合转成迭代器toIterator: 生成Iterator迭代器,一次性使用
将集合转成迭代器toIterable: 生成Iterable迭代器,可重复使用
衍生集合
去重: distinct
- 删除前N个元素,保留剩余所有元素: drop(N)
- 删除后N个元素,保留剩余所有元素: dropRight(N)
- 获取前N个元素: take(N)
- 获取后N个元素: takeRight(N)
- 获取第一个元素: head
- 获取最后一个元素: last
- 获取除开第一个元素的所有元素: tail
- 获取除开最后一个元素的所有元素: init
- 反转: reverse
- 获取指定角标范围的所有元素(不包含结束角标的元素):
slice(开始角标,结束角标) - 滑窗:
sliding(size,step=1)其中size为窗口大小,step为滑动长度 - 交集: intersect
- 差集: diff
- 并集: union
- 拉链: zip
- 反拉链: unzip ```scala val arr = Range(1, 10).toArray //集合常用属性/操作 println(“集合长度:” + arr.length) println(“集合大小:” + arr.size) arr.foreach(println) //集合遍历 for (i <- arr.iterator) println(i) println(arr.mkString(“,”)) //生成字符串 println(arr.contains(1)) //判断是否包含指定元素
//衍生集合 println(arr.head) //获取头部,即第一个元素 println(arr.tail.toList) //获取除头部外的其余元素,尾部 println(arr.last) //获取最后一个元素 println(arr.init.toList) //获取除最后一个元素外的其余元素 println(arr.reverse.toList) //反转 println(arr.drop(2).toList) //删除开始的n个元素,返回新集合 println(arr.dropRight(2).toList) //删除结尾的n个元素,返回新集合 println(arr.take(2).toList) //取开始的n个元素,返回新集合 println(arr.takeRight(2).toList) //取结尾的n个元素,返回新集合 println(arr.intersect(Array(1, 2, 3)).toList) //交集 println(arr.union(Array(1, 2, 10, 11)).toList.distinct) //并集[去重] println(arr.union(Array(1, 2, 10, 11)).toList) //并集[如果是集合的话才会去重,数组不会去重] println(Set(1, 2, 3).union(Set(2, 3, 4))) //并集 println(arr.diff(Array(1, 2, 3)).toList) //差集 println(Array(“xiaoming”, “xiaohong”, “xiaoqiang”).zip(Array(27, 28)).toList) //拉链 println(Array(“xiaoming”, “xiaohong”, “xiaoqiang”).zip(Array(27, 28,29)).unzip._1.mkString(“,”))//反拉链 arr.sliding(4, 1).foreach(x => println(x.toList)) //滑动窗口,参数为窗口大小,滑动步长 println(arr.toList) //以上操作都不会影响原集合
<a name="ctdKT"></a>### 初级计算函数1. **_获取最大值: max_**> 根据指定字段获取最大元素: `maxBy(func: 集合元素类型=> K)`,maxBy传入的函数是针对每个元素操作的,按照函数的返回值取集合中最大元素2. _**获取最小值: min**_> 根据指定字段获取最小元素: `minBy(func: 集合元素类型=> K)`,minBy传入的函数是针对每个元素操作的,按照函数的返回值取集合中最小元素3. **_求和: sum_**3. _**排序:sorted/sorBy/sortWith**_> - `sorted`: 根据集合元素直接排序(默认升序)> - `sortBy(func: 集合元素类型 => K)`: 根据指定字段排序,sortBy传入的函数是针对每个元素操作的,根据函数的返回值对集合元素排序> - `sortWith(lt: (集合元素类型,集合元素类型)=>Boolean)`: 根据规则排序,升序对应第一个参数 < 第二个参数;降序对应第一个参数 > 第二个参数```scala//集合初级函数val list = Range(1, 6).toListprintln(list.sum) //求和println(list.product) //连乘println(list.max) //最大值println(list.min) //最小值println(list.sorted) //返回排序后的集合println(list.sortBy(x => x * x - 8 * x)) //sortby按指定属性排序,可做一定的处理val p = Array("xiaoming", "xiaohong", "xiaoqiang").zip(Array(27, 28, 29)).toListprintln(p.maxBy((tuple: (String, Int)) => tuple._2)) //maxbyprintln(p.minBy((tuple: (String, Int)) => tuple._2)) //minbyprintln(p.sortBy(_._2)) //sortby按指定的属性排序println(p.sortBy(_._1))//sortedwith指定排序规则println(p.sortWith((left: (String, Int), right: (String, Int)) => left._2 > right._2))//对传入的函数进行简化println(p.sortWith(_._2 > _._2))
高级计算函数
map(func: 集合元素类型=>B): 一对一映射,原集合每个元素计算得到新集合中的一个元素- 类似带有yield关键字的for循环,SQL中的select
- map传入的函数是针对每个元素操作的,元素有多少个,函数就会执行多少次
- map生成的集合元素个数 = 原集合元素个数
- map的使用场景: 一般用于数据类型/值的转换(一对一转换)
foreach(func: 集合元素类型=>B):Unit:对集合元素遍历- 类似没有yield关键字的for循环
- foreach传入的函数是针对每个元素操作的,元素有多少个,函数就会执行多少次
flatten:压平- 类似SQL中的explode
- flatten只针对集合嵌套集合的数据类型,用于将第二层集合元素放入第一层集合中保存
flatMap(func: 集合元素类型=>集合 ):即同时进行map和flatten操作,数据转换+压平- flatMap传入的函数是针对每个元素操作的,元素有多少个,函数就会执行多少次
- flatMap生成的集合元素个数一般 >= 原集合元素个数
- flatMap的使用场景:一对多
filter(func: 集合元素类型=>Boolean):按照指定条件过滤- 类似有守卫的for循环,SQL中的where
- filter传入的函数是针对每个元素操作的,元素有多少个,函数就会执行多少次
- 最终保留函数返回值为true的数据
groupBy(func: 集合元素类型=>K):按照指定字段分组- 类似SQL中的groupby
- groupBy传入的函数是针对每个元素操作的,并根据其返回值对元素分组
- groupBy生成的是Map,Key是函数的返回值,Value是一个装载key对应原集合所有元素的集合
reduce(func: (集合元素类型,集合元素类型)=>集合元素类型):从左向右对集合所有元素聚合- 传入的函数第一个参数代表上一次聚合结果,第一次聚合时,初始值 = 集合第一个元素
- 传入的函数第二个参数代表待聚合的元素
reduceRight(func: (集合元素类型,集合元素类型)=>集合元素类型):从右向左对集合所有元素聚合- 传入的函数第二个参数代表上一次聚合结果,第一次聚合时,初始值 = 集合最后一个元素
- 传入的函数第一个参数代表待聚合的元素
fold(默认值)(func: (集合元素类型,集合元素类型)=>集合元素类型):从左向右对集合所有元素聚合- 传入的函数第一个参数代表上一次聚合结果,第一次聚合时,初始值 = 默认值
- 传入的函数第二个参数代表待聚合的元素
foldRight(默认值)(func: (集合元素类型,集合元素类型)=>集合元素类型):从右向左对所有元素聚合- 传入的函数第二个参数代表上一次聚合结果,第一次聚合时,初始值 = 默认值
- 传入的函数第一个参数代表待聚合的元素
//集合高级函数//1.过滤filter:过滤不符合条件的元素,返回新的集合val list1 = Range(1, 10).toListprintln(list1.filter(_ % 2 == 0))//2.映射map:对每一个元素进行处理,返回新的集合println(list1.map(_ * 2))//3.扁平化flatten:将里层的集合拆分为单个元素val list2 = List(Array("xiaoming", "xiaohong"), Array("xiaoqiang", "xiaohuang"))println(list2.flatten)//4.映射后再进行扁平化处理flatmapval list3 = List("xiaoming 27 shenzhen", "xiaohong 27 guangzhou", "xiaotang 28 shanghai", "xiaoqiang 29 beijing","xiaohuang 45 guangzhou", "xiaoli 27 shenzhen", "Bob 35 beijing")println(list3.map(_.split(" ")).flatten) //使用map+flattenprintln(list3.flatMap(_.split(" "))) //直接使用flatmap实现相同效果//5.分组groupbyprintln(list3.groupBy(_.split(" ")(2))) //按地区分组//按年龄段分组list3.groupBy((x: String) => {val age = x.split(" ")(1).toIntif (age < 30) "30岁以下"else if (age < 40) "40岁以下"else "40岁以上"}).foreach(println)//6.规约reduce:默认从左向右规约reduceleftprintln(list1.reduce((A1, A2) => {println(s"A1:${A1};A2:${A2}")A1 + A2}))println("============================")//规约:从右向左规约reducerightprintln(list1.reduceRight((A1, A2) => {println(s"A1:${A1};A2:${A2}")A1 + A2}))println("============================")//7.折叠fold,指定初值进行规约println(list1.fold(0)((A1, A2) => {println(s"A1:${A1};A2:${A2}")A1 + A2}))println("============================")//折叠:从右向左规约foldrightprintln(list1.foldRight(0)((A1, A2) => {println(s"A1:${A1};A2:${A2}")A1 + A2}))
集合函数应用demon
merge合并映射:同key元素累加value
//集合合并//默认合并的策略是最后加入的同key元素覆盖前面的key元素val map1 = Map("A" -> 1, "B" -> 2, "C" -> 3, "D" -> 4, "E" -> 5)val map2 = Map("A" -> 3, "C" -> 5, "E" -> 9)val map3 = map1 ++ map2println(map3)//用fold实现合并策略:同key元素累加valueval initmap = mutable.Map() ++= map1 //将不可变map元素添加至可变map,转变为可变mapval map4 = map2.foldLeft(initmap)((mergedMap: mutable.Map[String, Int], kv: (String, Int)) => {mergedMap(kv._1) = mergedMap.getOrElse(kv._1, 0) + kv._2mergedMap})println(map4)println(initmap) //initmap也同时改变
worldcount词频计数
//词频计数val datas = Source.fromFile(new File("datas/worlds")).getLines().toListdatas.flatMap(_.split(" ")).groupBy(x => x).map {case (world, strings) => (world, strings.length)}.foreach(println)
异常处理
- Scala没有编译异常这个概念,异常都是在运行的时候捕获处理
- 所有异常都是Throwable的子类型,throw表达式类型是Nothing
- 可以使用
_try{...}catch{...}finally{...}_捕获处理异常 - 在获取某个表达式的值时可以使用
scala.util.Try
//try{...}catch{...}finally{...}val list = List("1\tzhagnsan\t20\tbeijing", "2\t\t30\tshenzhen", "3\twangwu\t\tbeijing")list.map(x => {val splitlist = x.split("\t")val area = splitlist(3)val age = try {splitlist(2).toInt} catch {case ex: Exception => 0 //数据处理中的异常捕获处理}(area, age)}).foreach(println)//Trylist.map(x => {val splitlist = x.split("\t")val area = splitlist(3)val age = Try(splitlist(2).toInt).getOrElse(0) //Try获取表达式值,再用getorElse取出其中的值(area, age)}).foreach(println)
隐式转换
当编译器第一次编译失败的时候,会在当前的环境中查找能让代码编译通过的方法,用于将类型进行转换,实现二次编译,拓展类的方法
object implicittest {def main(args: Array[String]): Unit = {//类的方式导入隐式函数val imutil = new implicitutil1import imutil.double2int//伴生对象导入隐式函数import implicitutil2.string2intval num1: Int = 0.1 //通过隐式函数自动转换val num2: Int = "String" //通过隐式函数自动转换println(num1)println(num2)}}class implicitutil1 {//将浮点转换为整型的隐式函数implicit def double2int(x: Double): Int = {x.toInt}}object implicitutil2 {//将字符串转换为整型的隐式函数implicit def string2int(x: String): Int = {x.length}}

若有收获,就点个赞吧
0 人点赞
