author: Sean Callan author_link: https://github.com/doomspork categories: general date: 2018-07-25 layout: post tags: [‘ecto’, ‘software design’] title: Ecto query composition
excerpt: Follow along as we look at how to dynamically compose Ecto queries using pattern matching and reduction.
Ecto 查询组成
Ecto 是一个神奇的工具,它为我们提供了很大程度的灵活性。
在这篇博文中,我们将看看如何动态地构建我们的 Ecto 查询,同时对我们输入的数据进行消毒。
我们计划用 3 个步骤来进入组成部分。
- 创建我们要建立的基础查询
- 根据输入条件组成我们的查询
- 执行我们的最后一个查询
在我们的例子中将使用大家最喜欢的示例项目:一个博客!
在开始之前,先来看看我们将构建代码接口的模式。
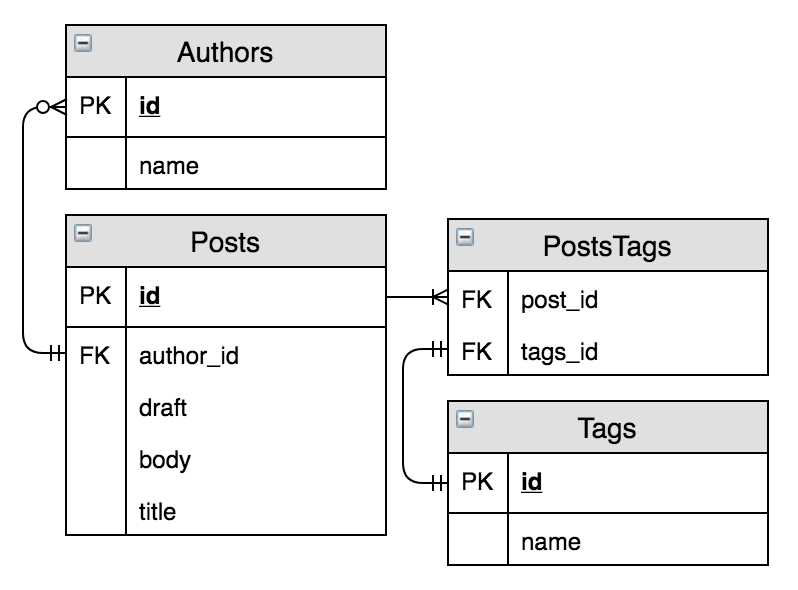
查询基础
为了保持简洁,我们将创建一个新的模块来包含访问底层模式数据的功能。
让我们继续创建我们的模块,并解决上面的第一步:基础查询。
defmodule Posts doimport Ecto.Querydefp base_query dofrom p in Postendend
足够简单。
当调用 base_query/0 时,我们将创建初始查询,作为我们标准的基础。
此时我们的查询类似于 SELECT * FROM posts。
应用我们的标准
接下来我们需要在 base_query/0 的基础上,应用我们的标准,这就是我们查询组成的神奇之处!
我们想要的查询结果很有可能不只是简单的 == 比较。
让我们考虑一下我们如何通过标题来查询一篇博客文章。
我们不太可能想要通过精确的标题来搜索,所以我们想要的不是 p.title == "Repo",而是 p.title ILIKE "%Repo%"。
考虑到这一点,就很容易理解为什么下面的做法不仅是个坏主意(因为它没有过滤标准),而且产生的查询是基本的 == 比较。
defp build_query(query, criteria) doexpr = Enum.into(criteria, [])where(query, [], expr)end
那么我们如何来避免这个问题呢?
在讨论新的方法之前,我们先确定一些 Post 查找的业务规则,看看它们在我们的方法中的应用,然后再进行讨论。
在我们的例子中,我们将假设以下内容始终为真。
- 搜索
title期望是ILIKE "%title%"。 - 包含
tags至少 需要一个。 - 可对
draft和id进行简单比较。 - 所有其他的值都被丢弃。
现在我们知道了关于查找 Post 的规则,让我们看看它们在查询组成中的应用。
defp build_query(query, criteria) doEnum.reduce(criteria, query, &compose_query/2)enddefp compose_query({"title", title}, query) dowhere(query, [p], ilike(p.title, ^"%#{title}%"))enddefp compose_query({"tags", tags}, query) doquery|> join(:left, [p], t in assoc(p, :tags))|> where([_p, t], t.name in ^tags)enddefp compose_query({key, value}, query) when key in ~w(draft id) dowhere(query, [p], ^{String.to_atom(key), value})enddefp compose_query(_unsupported_param, query) doqueryend
把它们整合在一起
有了 base_query/0 和 build_query/2,让我们定义公共 all/1 函数。
运行我们的查询没有什么特别之处,所以我们可以将我们的新函数设置为以 Repo.all/1 结束的管道。
def all(criteria) dobase_query()|> build_query(criteria)|> Repo.all()end
结果是公共函数,也就是我们模块的 API,简明扼要,在一定程度上自成体系。”获取基础查询,建立标准查询,然后获取所有记录”。
当我们把这一切结合在一起,并开始利用我们提供的灵活性时,我们开始看到通过 Ecto 提供给我们的真正力量。
defmodule Posts doimport Ecto.Querydef all(criteria) dobase_query()|> build_query(criteria)|> Repo.all()enddef drafts, do: all(%{"draft" => true})def get(id) do%{"id" => id}|> all()|> handle_get()enddefp base_query dofrom p in Postenddefp build_query(query, criteria) doEnum.reduce(criteria, query, &compose_query/2)enddefp compose_query({"title", title}, query) dowhere(query, [p], ilike(p.title, ^"%#{title}%"))enddefp compose_query({"tags", tags}, query) doquery|> join(:left, [p], t in assoc(p, :tags))|> where([_p, t], t.name in ^tags)enddefp compose_query({key, value}, query) when key in ~w(draft id) dofield = String.to_atom(key)where(query, [p], ^{field, value})enddefp compose_query(_unsupported_param, query) doqueryenddefp handle_get([]), do: {:error, "not found"}defp handle_get([post]), do: {:ok, post}end
在这里,我们封装了一个数据检索逻辑模块,分离了我们的表现层和数据层,同时提供了一个干净的接口读取我们的数据。
如果我们使用 Phoenix,我们的控制器可能看起来像这样:
defmodule Web.PostController douse Web, :controllerdef index(conn, params) doparams|> Posts.all()|> render_result(conn)enddef show(conn, %{"id" => id}) doid|> Posts.get()|> render_result(conn)enddefp render_result({:ok, post}, conn) dorender(conn, "show.json", post: post)enddefp render_result({:error, reason}, conn) dorender(conn, ErrorView, "error.json", reason: reason)enddefp render_result(posts, conn) when is_list(posts) dorender(conn, "index.json", posts: posts)endend
控制器很简洁,除了呈现数据之外没有更多的作用—因为它本该如此。
你对这种方法有什么看法? 你是如何组成你的 Ecto 查询的? 我们很想听听你的想法和建议!

若有收获,就点个赞吧
0 人点赞
