锁介绍
在 MySQL 中,通过 select … lock in share mode 和 select … for update 语法查询时,将会到命中的记录及索引记录之间加上 Next-key lock,这是由间隙锁和行锁的组合而成,本意是为了解决在可重复读的隔离级别下的幻读问题。
所谓间隙锁(gap lock)就是两个索引值之间的间隙,例如,数据库中某一列的索引上记录了 11, 17, 22 三个值,那么可产生间隙锁 (11, 17) 和 (17, 22),该间隙中不能插入新的索引叶子节点,简单来说就是禁止 SQL 的 insert / update DML 操作。
而行锁(record lock)则是索引值上的锁。还是以 11, 17, 22 三个值来举例,行锁则是在 11, 17, 22 三条上的锁,通过间隙锁和行锁组合而成的 next-key lock 则变成 (11, 17] 和 (17, 22],是一个前开后闭的区间。
值得一提的是,二级索引上加的 Next-key lock 会锁定索引值上主键对应的记录,但有个例外,就是覆盖索引中存在一种优化,就是并不会锁定索引值上主键对应的记录。如 select id from t_user where name=’zhangsan’ for update; 且假设 name 是二级索引,id 是主键索引,由于不需要用到回主表反查记录,因此也不会锁定主键索引上的记录。
锁规则
- 加锁的基本单位是 Next-key lock,由间隙锁加行锁的组合而成,前开后闭,如 (v1, v3];
2. 二级索引上访问到的数据会对主键数据加行锁,使用覆盖索引功能则例外;
3. 非唯一索引的等值查询
3.1. 存在查询的值,则向右匹配到第一个不满足条件为止,退化为间隙锁
3.2. 若不存在查询的值,Next-key lock 退化为间隙锁
4. 唯一索引的等值查询
4.1. 存在查询的值,退化为行锁
4.2. 若不存在查询的值,Next-key lock 退化为间隙锁
5. 索引的范围查询的向右匹配 Next-key lock 不会退化为其他锁
锁案例分析
B+Tree 索引叶子节点
简单提一下 B+Tree 索引的数据结构中数据存在于的叶子节点,且通过双向链表的方式关联起来,参考下图,v1 / v2 / v3 / v4 / v5 都是数据节点,每个节点之间就是他们的间隙,这也是间隙锁的命名来由。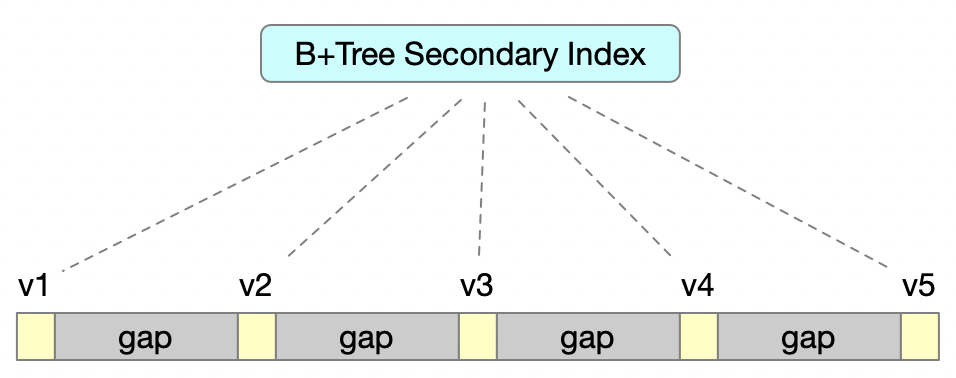
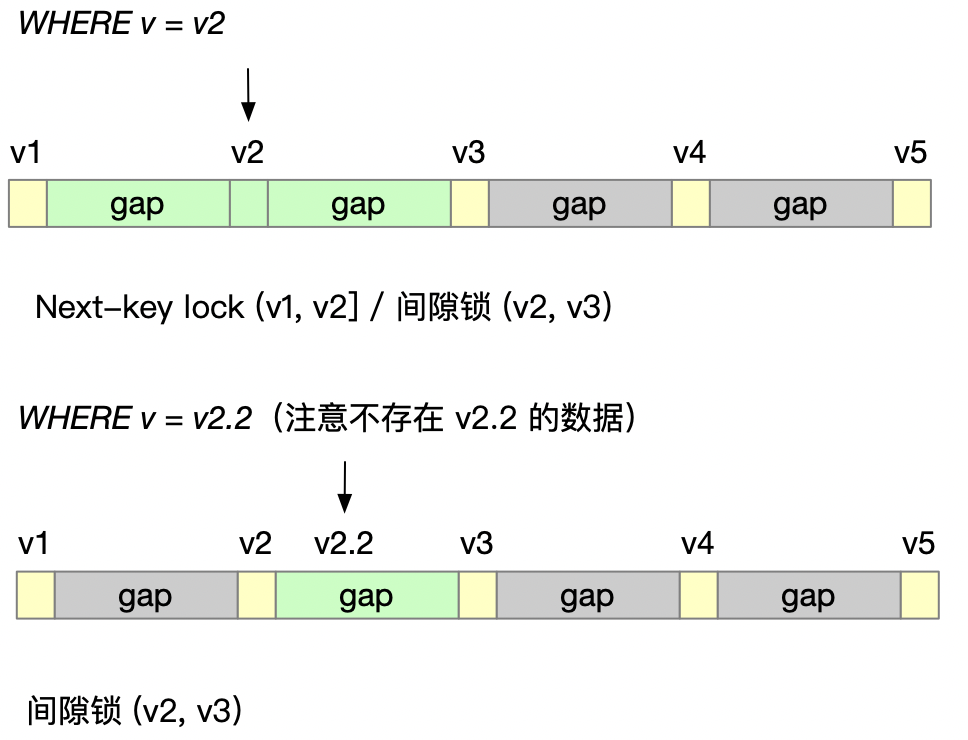
非唯一索引的等值查询_
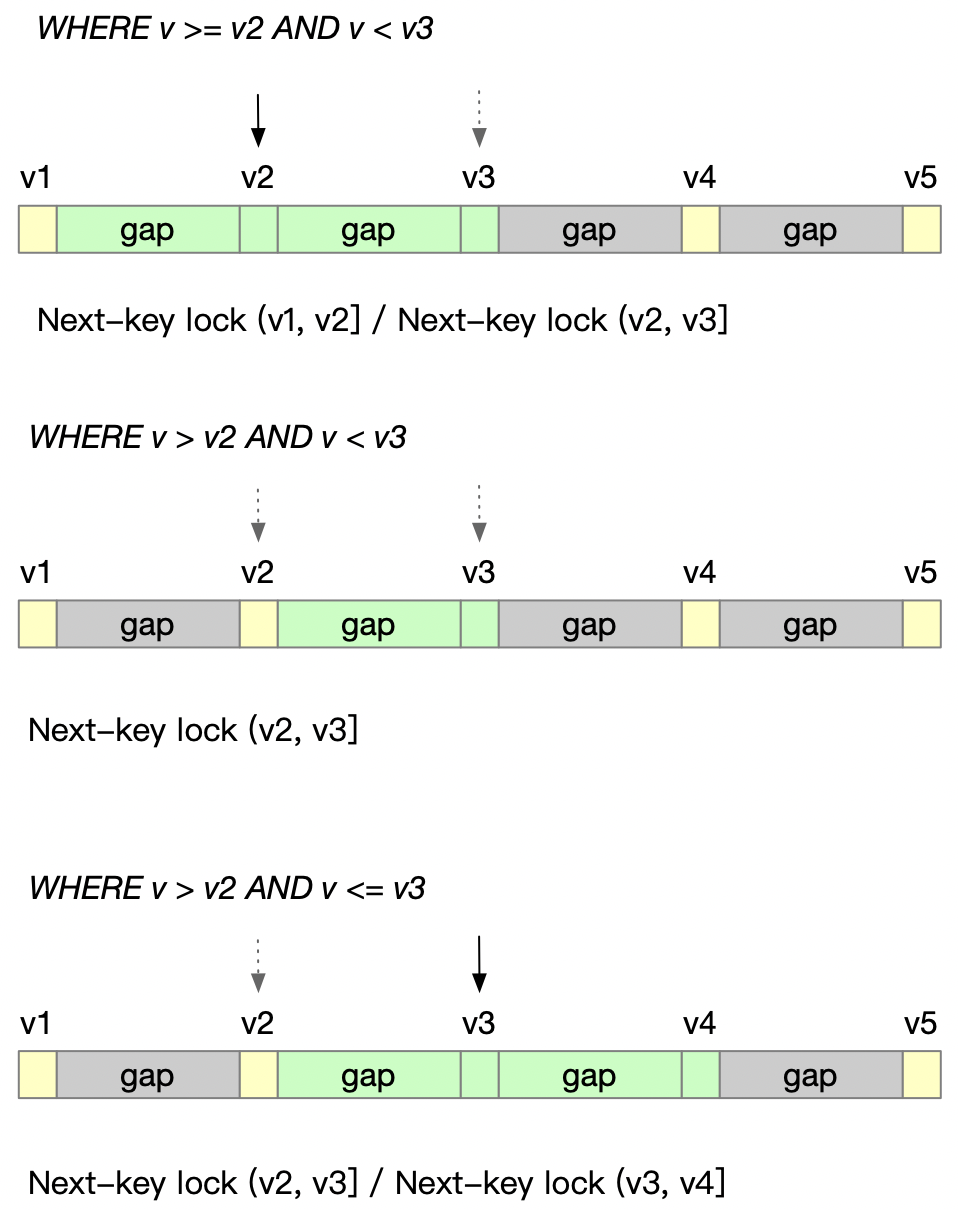
非唯一索引的范围查询
唯一索引的等值查询

唯一索引的范围查询
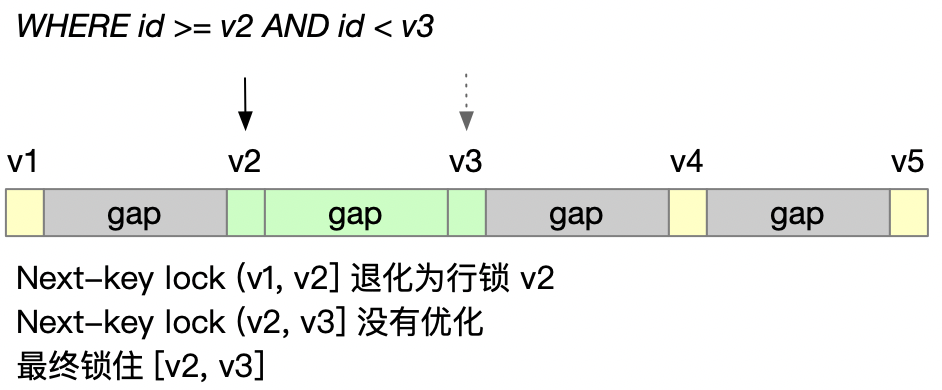
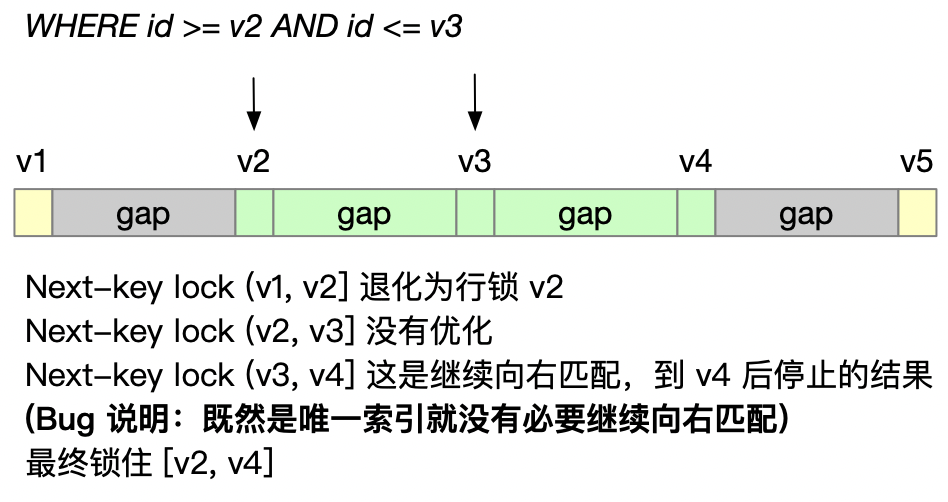
唯一索引的范围查询 BUG (MySQL 8.0.18 已修复)
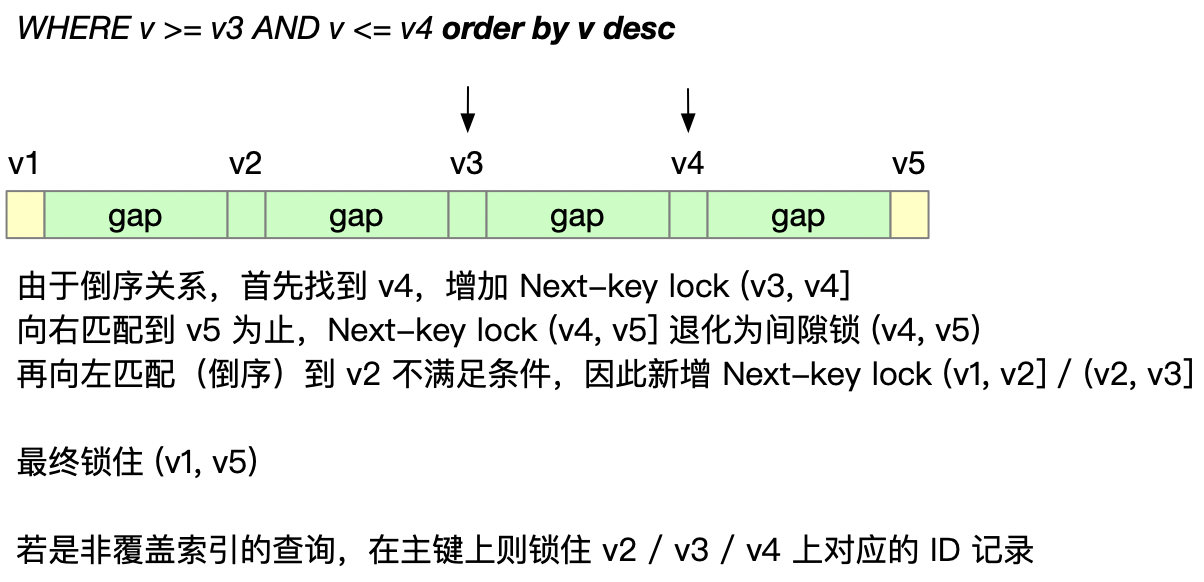
索引的范围倒序查询
应用场景
select … lock in share mode
1. 说明
表示共享查询同一条数据,且不能进行更新及删除操作,例如,分别通过两个独立的 session 执行 SQL 语句 select name, age from t_user where name=’张三’ lock in share mode; 都能正常返回数据。
2. 应用场景
譬如,存在一个机构表,通过机构ID(id)及父机构ID(pid)维持一个机构树,如果需要向 P 机构下新增一个 C 子机构,为了确保这个时候的 P 机构不会被删除,此时使用 select from org where pid=’xxx’ lock in share mode; 查询出 P 机构,将 C 子机构插入数据库后提交事务表示锁释放,但如果*并发对 P 机构新增子机构,就会出现死锁异常,错误信息如下所示。
[40001][1213] Deadlock found when trying to get lock; try restarting transaction
3. 并发重现死锁
| Session A | Session B |
|---|---|
| select * from org where pid=’P’ lock in share mode; | |
| select * from org where pid=’P’ lock in share mode; | |
| insert into org (pid,id) values (‘P’, ‘01’); (Blocking) |
|
| insert into org (pid,id) values (‘P’, ‘02’); [40001][1213] Deadlock found when trying to get lock; try restarting transaction |
|
| insert into org (pid,id) values (‘P’, ‘01’); (Continue and Success) |
select … for update
1. 说明
表示互斥查询同一条数据,例如,分别通过两个独立的 session 执行 SQL 语句 select name, age from t_user where name=’张三’ for update; 后一个 session 必须等待前一个 session 的事务结束(commit / rollback)才能正常查询出数据。
2. 应用场景
既然 select … lock in share mode; 会产生死锁异常,那么使用 select … for update; 就能够很好的解决这个问题,当然这是以降低并发能力换取的结果,反观同一个节点下并发同时新增多个子节点,只要保证足够短的事务也是一种折中的方法。
3. 并发验证
| Session A | Session B |
|---|---|
| select * from org where pid=’P’ for update; | |
| select from org where pid=’P’ for update; *(Blocking) |
|
| insert into org (pid,id) values (‘P’, ‘01’); | |
| Commit; | |
| insert into org (pid,id) values (‘P’, ‘02’); | |
| Commit; |

若有收获,就点个赞吧
0 人点赞
