1. Flink 集群中的主要组件
这里需要提到 Flink 中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,如图 3-1 所示。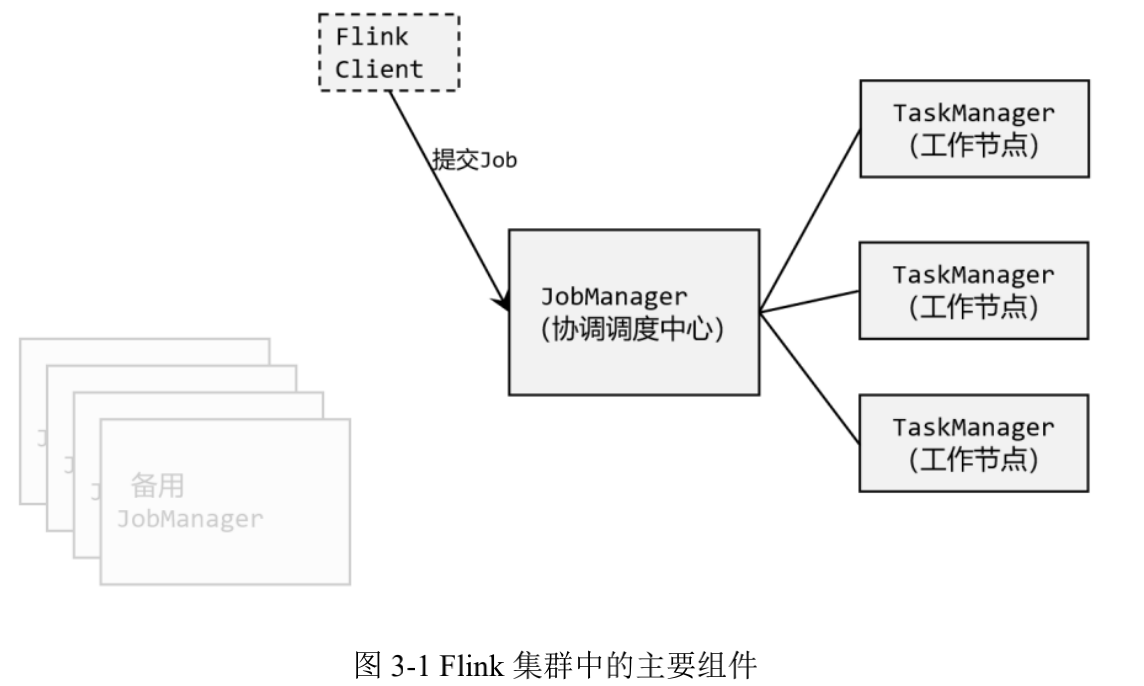
在实际项目应用中,我们当然不能使用开发环境的模拟集群,而是需要将 Flink 部署在生产集群环境中,然后在将作业提交到集群上运行。所以本章我们就来介绍 Flink 的部署及作业提交的流程。
Flink 是一个非常灵活的处理框架,它支持多种不同的部署场景,还可以和不同的资源管理平台方便地集成。所以接下来我们会先做一个简单的介绍,让大家有一个初步的认识,之后再展开讲述不同情形下的 Flink 部署。
2. 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的 main 方法到底在哪里执行——客户端(Client)还是 JobManager。
2.1 会话模式(Session Mode)
一般用这种模式,配合 YARN 或 Kubernetes
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。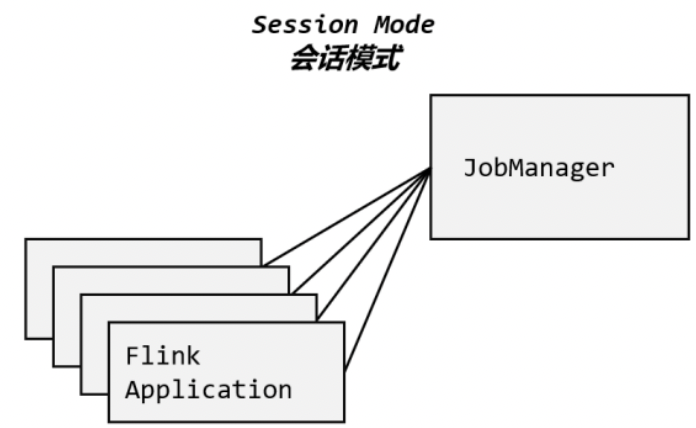
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
会话模式比较适合于单个规模小、执行时间短的大量作业。
2.2 单作业模式(Per-Job Mode)
每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。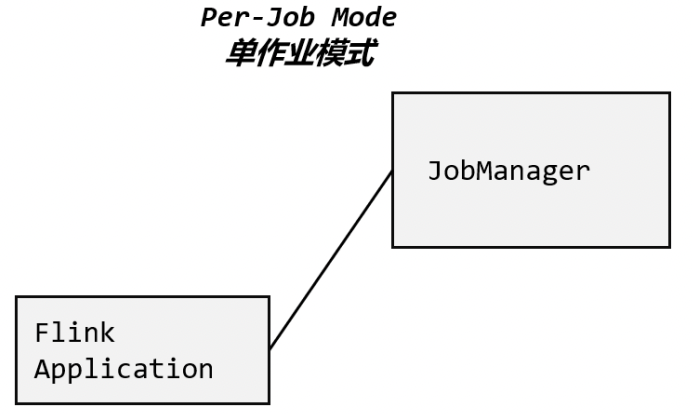
单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如 YARN、Kubernetes。
2.3 应用模式(Application Mode)
不要客户端了,直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所谓的应用模式。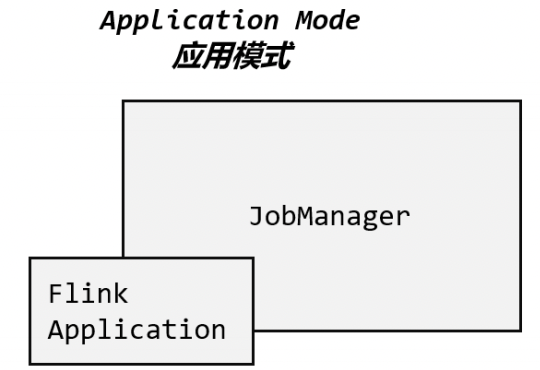
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
2.4 总结
- 会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。
- 单作业模式 为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定
- 应用模式为 每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的 main()方法。
3. 独立模式(Standalone)
独立模式包含
- 会话模式部署
- 单作业模式部署
- 应用模式部署
- 高可用(High Availability )
独立模式(Standalone)是部署 Flink 最基本也是最简单的方式:所需要的所有 Flink 组件,都只是操作系统上运行的一个 JVM 进程。
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
另外,我们也可以将独立模式的集群放在容器中运行。Flink 提供了独立模式的容器化部署方式,可以在 Docker 或者 Kubernetes 上进行部署。
4. YARN 模式
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。
而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。所以接下来我们就将学习,在强大的 YARN 平台上 Flink 是如何集成部署的。整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager, Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
5. K8S 模式
容器化部署是如今业界流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Flink 也在最近的版本中支持了 k8s 部署模式。基本原理与 YARN 是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
6. 总结
以上只是简单介绍 Flink 的单机、集群部署方式,具体的操作步骤参考最后一章“Flink 文档”中《尚硅谷大数据技术之flink(java)” 的第3节!

若有收获,就点个赞吧
0 人点赞
