- 里程碑工作和最新进展
(1) AlexNet
AlexNet[2]卷积神经网络在计算机视觉领域中首个被广泛关注及使用的卷积神经网络,它由Alex Krizhevsky,Ilya Sutskever和Geoff Hinton实现。AlexNet在2012年的ImageNet ILSVRC 竞赛中夺冠,性能远远超出第二名(16%的top5错误率,第二名是26%的top5错误率)。这个网络的结构和LeNet非常类似,都是由基础的模块堆叠而成。但得益于大数据和GPU强大的计算力,整个网络更深更大,并且使用了层叠的卷积层来获取特征(之前通常是只用一个卷积层并且在其后马上跟着一个汇聚层),如图6
贡献或者创新点:
1. AlexNet首次将卷积神经网络应用于计算机视觉领域的海量数据集ImageNet,揭示了卷积神经网络的强大特征表达能力和学习能力。另一方面,海量数据同时也使卷积神经网络免于过拟合。自此便引发了深度学习,特别是卷积神经网络在计算机视觉中“井喷式”的研究。
2. 使用GPU实现网络训练。“工欲善其事,必先利其器,研究者可以借助GPU从而将原本需数周甚至数月的网络训练过程大大缩短为几天(目前利用分布式训练仅需要数小时)。这无疑大大缩短了深度网络和大模型开发研究的周期与时间成本。
3. 一些训练技巧的引入使得训练深层的网络变为可能。Dropout层:如图6。左侧图(a)代表传统的神经网络,右侧图(b)代表装配了随机性失活的神经网络(这里的随机性失活指的是Dropout)。此外,还有数据增广,局部相应规范化层。

图6

图7
(2)VGGNet
VGG[4]是ILSVRC 2014的第二名模型,由Karen Simonyan和 Andrew Zisserman实现。他们最好的网络包含了16个卷积/全连接层。网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的汇聚,如图8。
贡献或者创新点:
1. VGG展示出网络的深度是深度学习模型优良性能的关键成分。
2. VGG具备良好的泛化能力,其预训练的模型可以用于图片检测,图片风格化等任务中。
缺点:
VGGNet的缺点是它耗费更多计算资源,使用了更多的参数,导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。后来发现这些全连接层即使被去除,对于性能也没有什么影响。

图8
(3) ResNet
残差网络(Residual Network)[3]是ILSVRC 2015的冠军模型,由何恺明等实现,。理论和实验已经证明,神经网络的深度和宽度是表征网络复杂度的两个核心因素,不过深度相比宽度在增加网络的复杂性方面更加有效,这也正是为何VGG网络想法设法增加网络深度的一个原因。然而,随着深度的增加,训练会变得愈加困难。主要原因在基于随机梯度下降的网络训练过程中,误差信后的多层反向传播非常容易引发梯度“弥散”(梯度过小会使回传的训练误差及其微弱)或者“爆炸”(梯度过大会大致模型训练出现“NaN”)现象。基于此发现和动机,经过作者的大量实验提出了残差模块,如图9(a),它使得高层的梯度能够直接回传,并且学习一个残差使得学习变得更简单。在网络结构设计上,除了残差模块其余基本和VGG类似,如图9(b)。
贡献或者创新点:
- 提出了残差模块使得训练几百层的神经网络变为可能。之后的提出的升级版Pre-Activate Resnet 甚至能够训练上千层的网络。
- 提出了bottleneck的1x1的卷积层,对输入的数据体在深度维度上进行降维,大大减少了计算量以及减少过拟合的可能性。
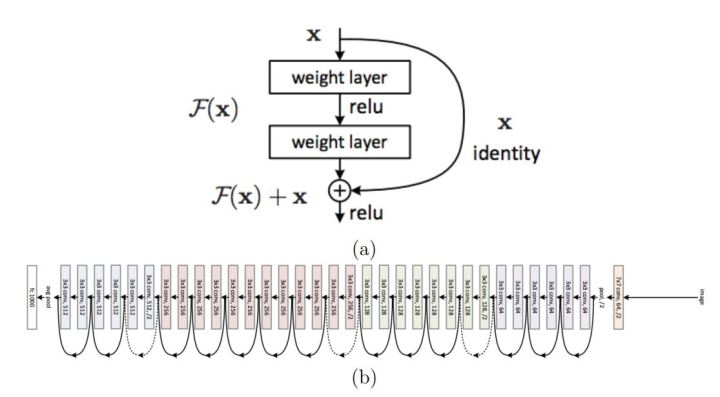
图9
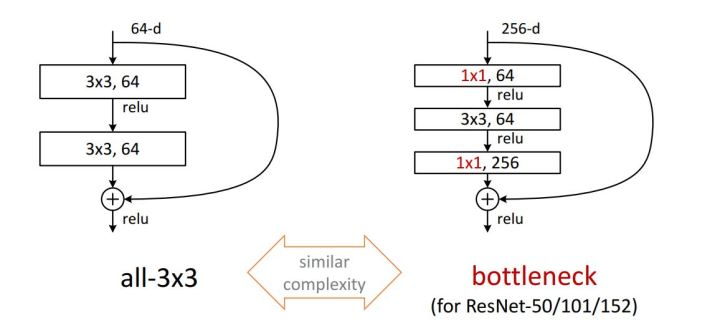
图10
(4)InceptionV1-V4
以上提及的网络结构有个共性,基本上相邻两层数据体是通过单路的非线性映射来完成特征进一步抽象的。然而,google团队开创性的提出Inception结构,通过多路的非线性映射增加模型的表达能力(相当于多个模型的Ensemble),并与此同时,减轻物体多尺度对最终任务的影响。
InceptionV1[5]即GoogleNet,是ILSVRC 2014的冠军模型,如图11。基本InceptionV1模块结构如图12。左图是文章提及的最原始的版本,所有的卷积都直接在上一层的输出上操作,导致5×5的卷积核所需的计算量过于庞大增加了参数量,同时造成了concat后的数据体深度过大增加了计算代价。为了避免这一现象,文章进一步提出了右图的InceptionV1模块结构:在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低数据体深度的作用,效果和ResNet的bottleneck是一致的。
InceptionV2[6]一方面了加入了BN(Batch Normalization)层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯。值得注意的是,BN的提出,使得训练大大加快模型更容易收敛,同时起到正则化的作用;另一方面用2个3x3的conv替代inception模块中的5x5,如图12的最左图,既降低了参数数量也增加了模型的非线性表达能力。
InceptionV3[7]一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),如图12的中间图。这样的好处在于既可以加速计算(多余的计算能力可以用来加深网络),又可以使得网络深度进一步增加,增加了网络的非线性。此外值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8对应的模块。
InceptionV4[8]研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet V2网络,如图12的最右图。同时还设计了一个更深更优化的InceptionV4模型,能达到与Inception-ResNet v2相媲美的性能。


图11
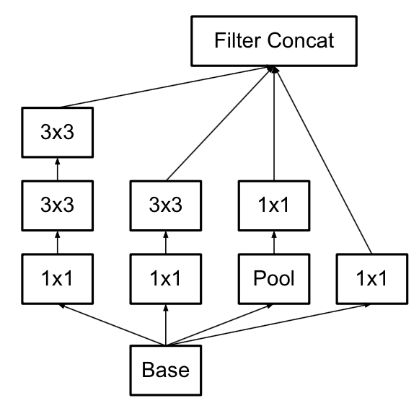
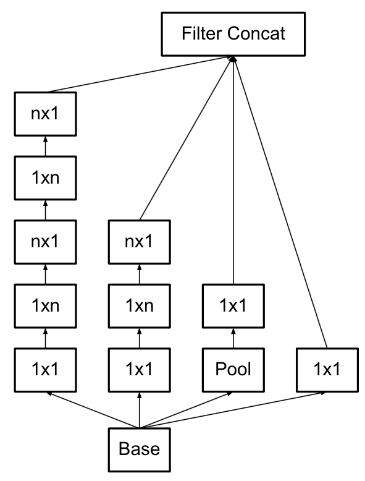

图12
(5) DenseNet
DenseNet[9]是CVPR 2017年的best paper.虽然DenseNet的影响不及ResNet那么大,但是也提出了一种很有意义的观点. DenseNet的最大优势在于优化梯度流.早在ResNet之后,就有工作指出在ResNet训练过程中,梯度的主要来源是shortcut分支。总所周知,在训练CNN的过程中,保持梯度流的有效性,防止梯度爆炸/消失时是最重要的事情,关系到模型是否收敛。既然shortcut如此有效,那么为什么不多加点呢?这就是 DenseNet 的核心思想:对之前每一层都加一个单独的 shortcut,使得任意两层之间都可以直接”沟通”,如图13。需要注意的是,由于DenseNet在ImageNet数据集上不如Inception或者ResNet-like的模型,因此,它在工业界的收关注程度不如其他的模型。
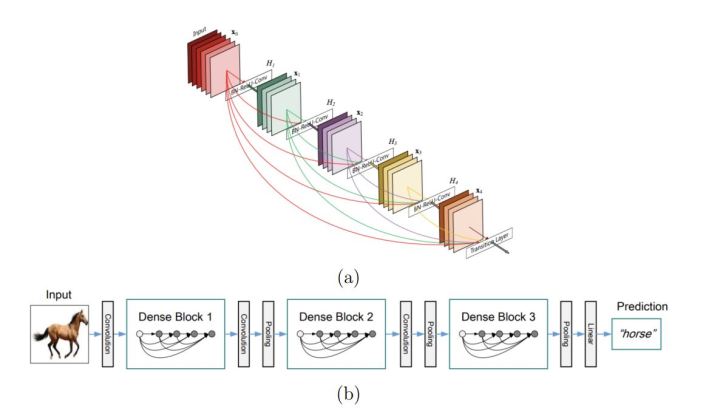
图13
(6) ResNeXt
ResNeXt[10]其实是一种多分支的卷积神经网络。多分支网络最初可见于之前提及的Inception结构。ResNeXt首先验证了图14中三种结构的一致性,然后提出除了深度和宽度以外,”基数”也是影响网络性能的一个重要因素。注意图(c)是利用了group convolution来模拟多分支的normal convolution。

图14
(7)Squeeze-and-Excitation block
Sequeeze-and-Excitation(SE) block[11]并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中。作者采用该SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。SENet的核心思想在于通过网络根据loss去学习特征图的权重,使得有效的特征图权重大,无效或效果小的特征图权重小,这种方式训练模型能够达到更好的结果同时仅增加了可接受的少量计算代价。其实,换言之,该网络结构就是在channel维度的attention机制,如图15。
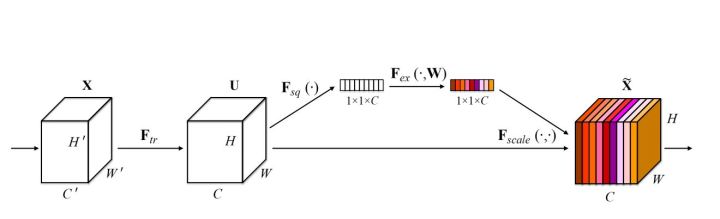
图15
(8)MobileNet/ShuffleNet
为了获得更好的性能,卷积神经网络层数不断增加,从 7 层 AlexNet 到 16 层 VGG,再从 16 层 VGG 到 GoogLeNet 的 22 层,再到 152 层 ResNet,更有上千层的 ResNet 和 DenseNet。虽然网络性能得到了提高,但随之而来的就是效率问题。效率问题主要是模型的存储问题和模型进行预测的速度问题(以下简称速度问题)
1. 存储问题。数百层网络有着大量的权值参数,保存大量权值参数对设备的内存要求很高。
2. 速度问题。在实际应用中,往往是毫秒级别,为了达到实际应用标准,要么提高处理器性能,要么就减少计算量。
只有解决卷积神经网络的效率问题,才能让卷积神经网络走出实验室,更广泛的应用于移动端。对于效率问题,通常的方法是进行模型压缩(Model Compression),即在已经训练好的模型上进行压缩,使得网络携带更少的网络参数,从而解决内存问题,同时可以解决速度问题,但篇幅有限,这个暂不介绍。
相比于在已经训练好的模型上进行模型压缩,轻量化模型模型设计则是另辟蹊径。轻量化模型设计主要思想在于设计更高效的网络结构,从而使网络参数减少的同时,不损失网络性能。本文就近年提出的两个轻量化模型进行简要的介绍,分别是为Google的MobileNet[12]以及Face++的ShuffleNet[13]。
MobileNet核心思想是采用 depth-wise convolution(group convolution的特例, group_number = channel_num),在相同的输入输出维度的情况下,相较于 standard convolution 操作,可以减少数倍的计算量和参数量。同时,为解决depth-wise convolution的信息不流畅的问题,增加了如point-wise convolution取融合每个channel上的信息。传统的卷积和mobilenet模块的比较请见如图16的右侧。depth-wise convolution和point-wise convolution的具体操作请见图16的左侧。
ShuffleNet核心思想是采用 group convolution,在相同的输入输出维度的情况下,相较于 standard convolution 操作,同样可以减少数倍的计算量和参数量(没有depth-wise convolution明显),从而达到轻量化网络的目的。同样的,group convolution 存在信息不流畅的问题,但ShuffleNet不是依赖额外的1x1 convolution,而是通过一个随机打乱(shuffle)特征图的channel,使得各组之间的信息可以互相流通,同时不带来任何额外的计算代价,如图17。
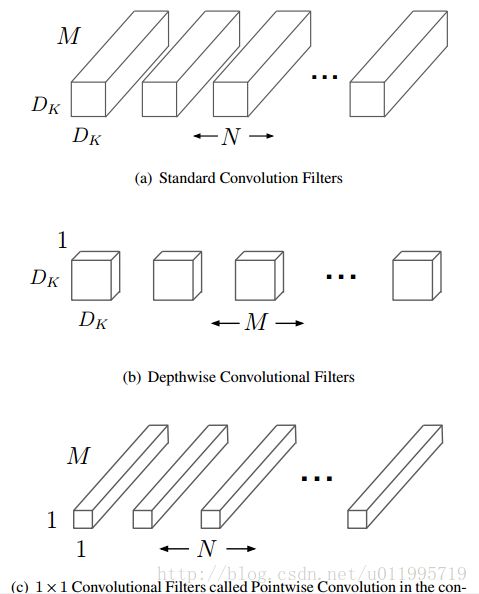
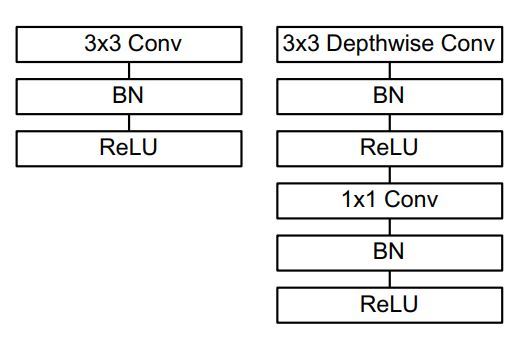
图16

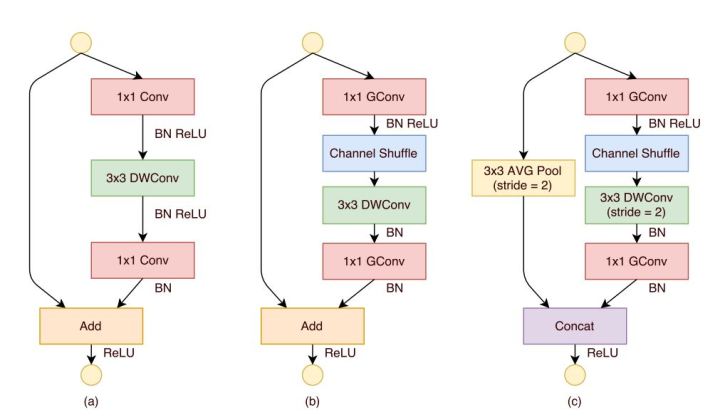
图17
- 总结和思考
以上,通过简要介绍了深度学习在图像识别的不断进展和重要工作,可以看到,目前卷积神经网络的设计思路基本上朝着更深,更宽(如Xception网络,本文未对其做出概括),更多支路,更轻量以及更有效的卷积方式等多个方向同时发展。目前。由于深度学习在图像识别的任务已经超过人类,可见卷积神经网络能够很好地从输入映射到隐层地特征表达,并且能够层级式地提取特征并通过最后通过内嵌的分类网络完成分类任务。并且卷积神经网络通过轻量话网络或者模型压缩能够在嵌入式或者移动端运行,已慢慢从实验室走向更多的商业化应用,走进寻常百姓家。
如今,由于最新的卷积神经网络在某个程度上解决了计算机视觉领域特征表达的问题,卷积神经网开始在诸多研究方向如目标检测,图像分割,实例分割,图像生成,人脸识别,车辆识别,人体姿态估计等大方光彩,取得的研究成果也是远超传统算法令人振奋。深度学习或者说卷积神经网络通过刷脸支付,交通天眼系统,无人驾驶等商业应用正在悄悄的改变着我们的生活。
参考文献:
[1] LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
[2] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
[3] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
[4] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014
[5] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
[6] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[7] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. arXiv preprint arXiv:1512.00567, 2015.
[8] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi. Inceptionv4, inception-resnet and the impact of residual connections on learning. arXiv:1602.07261, 2016.
[9] G. Huang, Z. Liu, K. Q. Weinberger, and L. Maaten. Densely connected convolutional networks. In CVPR, 2017.
[10] S. Xie, R. Girshick, P. Dollar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017.
[11] Jie Hu , Li Shen , Gang Sun. _Squeeze-and-Excitation Networks
[12] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. _arXiv preprint arXiv:1704.04861, 2017.
[13] Xiangyu Zhang_,_Xinyu Zhou, Mengxiao Lin, Jian Sun. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices

若有收获,就点个赞吧
0 人点赞
