1、性能测试定义和分类
1.1定义
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。
1.2分类
1)负载测试:是通过逐步增加系统负载,测试系统性能的变化,并在满足最终确定性能指标的情况下,系统所能承受的最大负载量的测试;负载测试是正常范围的测试
2)压力测试:逐步增加系统负载,测试系统性能的变化,并最终确定在什么负载下系统性能处于失效状态,并以此来获得系统能提供的最大服务级别的测试
3)容量测试:系统的极限或苛刻的环境中系统的性能表现
负载测试和压力测试的区别:
负载测试强调系统正常工作情况下的性能指标 压力测试的目的是发现在什么条件下系统的性能变得不可接受,发现应用程序性能下降的拐点
2、为什么要做性能测试
1、响应速度:某公司分析了超过150个网站和150万个浏览页面,发现页面响应时间从2秒增长到10秒,会导致38%的页面浏览放弃率。
2、高并发:系统能承载的负荷
3、CPU使用率,过高会导致系统卡顿
4、特殊情况:电源?、网络不稳定的情况
总结就是一句话:为了确保软件(App、网站)在用户使用的过程中运行流畅。
3、性能测试指标
性能指标分为两个方面:
系统指标(与用户场景和需求相关指标)
资源指标(与硬件资源消耗相关指标)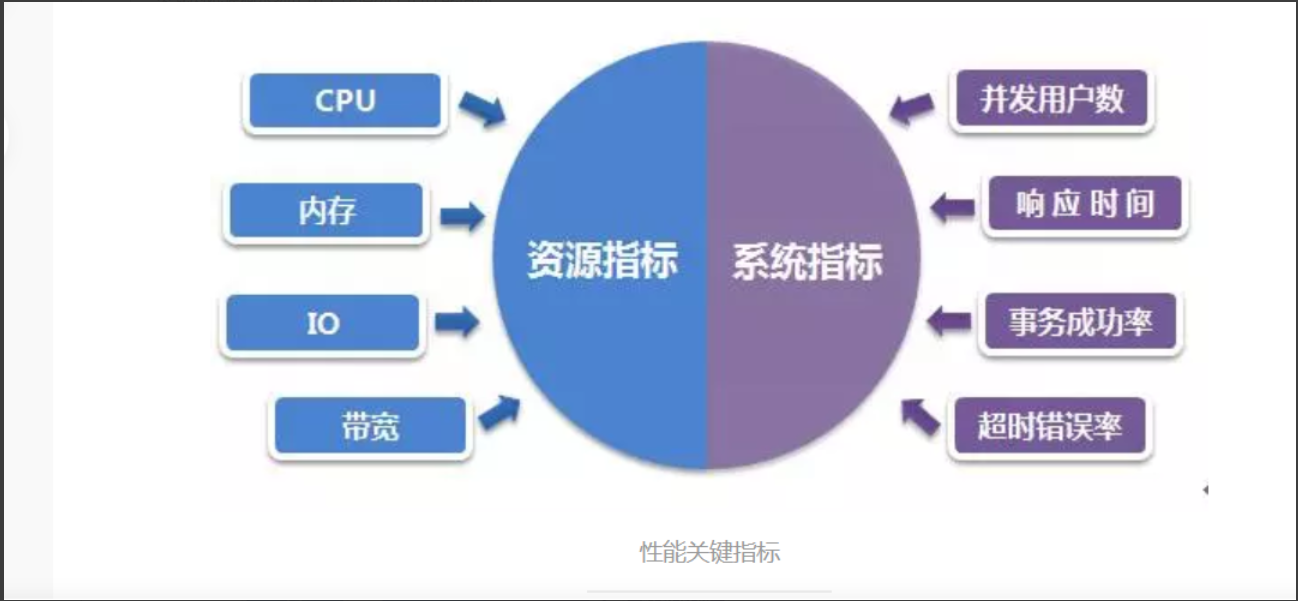
3.1系统指标说明
1)响应时间、平均响应时间
响应时间:对一个请求做出响应所需要的时间
平均响应时间:所有请求花费的平均时间
如:如果有100个请求,其中 98 个耗时为 1ms,其他两个为 100ms
平均响应时间: (98 1 + 2 100) / 100.0 = 2.98ms,但是,2.98ms并不能反映服务器的整体效率,因为98个请求耗时才1ms,引申出百分位数
百分位数:以响应时间为例,指的是 99% 的请求响应时间,都处在这个值以下,更能体现整体效率。
2)事务成功率
事务成功率:性能测试中,定义事务用于度量一个或者多个业务流程的性能指标,如用户登录、保存订单、提交订单操作均可定义为事务,如下图所示:
单位时间内系统可以成功完成多少个定义的事务,在一定程度上反应了系统的处理能力,一般以事务成功率来度量。
这里要说两个概念,TPS和QPS
QPS:Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器(比如是读写分离的架构,就是读的服务器)在规定时间内所处理流量多少的衡量标准。
TPS:TransactionsPerSecond,意思是每秒事务数,一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
3)并发数(线程数)
并发数是一个特别容易混淆的概念,因为他在各种语境下表示的含义可能并不相同,从性能测试结果的角度来看:
并发指的是在某一个时间点,服务器正在处理的请求数
举例来说:
工程师经常说1秒并发2000,其实他指的是QPS=2000。
而一个网站管理员说我们并发1000人,其实指的最大在线人数1000人。在线人数1000人并不意味每个人都同一时间在跟服务器做交互,因此服务器的并发数并未到1000.
运维人员说我设置的tomcat的并发数500,他指的是这个tomcat最多可以调用500个线程同时接受请求。也就是同一时间服务器能达到的最大并发数数是500,但是受限于CPU、OS等其他原因,并发数在实际中达不到这个数值。
性能测试人员说我在LR中设置了并发数3000,指的是他在测试工具中设置3000个并发模拟用户,只是理论上在单位时间内最多会有3000个的模拟请求到服务器上。但是从客户端角度出发,客户端有可能因为CPU、OS、等待时间等等限制,并不能达到此压力。即使客户端达到了此压力,但是从服务器的角度出发,会有排队机制以及部分请求异常溢出,并不能说服务器的并发就到了3000。
QPS(TPS)、并发数、响应时间它们三者之间的关系是:
- QPS(TPS)= 并发数 / 平均响应时间
- 并发数 = QPS * 平均响应时间
- 并发用户峰值=并发数 + 3*根号 并发数
4)错误率
主要指事务由于超时或系统内部其它错误导致失败占总事务的比率。
3.2资源指标说明
CPU使用率:指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
内存利用率:内存利用率=(1-空闲内存/总内存大小)100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
*网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
4、如何严谨地做性能测试
一般来说,性能测试要统一考虑这么几个因素:Thoughput吞吐量,Latency响应时间,资源利用(CPU/MEM/IO/Bandwidth…),成功率,系统稳定性。
一,你得定义一个系统的响应时间latency,建议是TP99,以及成功率。比如路透的定义:99.9%的响应时间必需在1ms之内,平均响应时间在1ms以内,100%的请求成功。
二,在这个响应时间的限制下,找到最高的吞吐量。测试用的数据,需要有大中小各种尺寸的数据,并可以混合。最好使用生产线上的测试数据。
三,在这个吞吐量做Soak Test,比如:使用第二步测试得到的吞吐量连续7天的不间断的压测系统。然后收集CPU,内存,硬盘/网络IO,等指标,查看系统是否稳定,比如,CPU是平稳的,内存使用也是平稳的。那么,这个值就是系统的性能
四,找到系统的极限值。比如:在成功率100%的情况下(不考虑响应时间的长短),系统能坚持10分钟的吞吐量。
五,做Burst Test。用第二步得到的吞吐量执行5分钟,然后在第四步得到的极限值执行1分钟,再回到第二步的吞吐量执行5钟,再到第四步的权限值执行1分钟,如此往复个一段时间,比如2天。收集系统数据:CPU、内存、硬盘/网络IO等,观察他们的曲线,以及相应的响应时间,确保系统是稳定的。
六、低吞吐量和网络小包的测试。有时候,在低吞吐量的时候,可能会导致latency上升,而网络小包会导致带宽用不满也会导致性能上不去,所以,性能测试还需要根据实际情况有选择的测试一下这两咱场景
5、引入Jmeter
5.1 Jmeter的优点
jmeter 为性能测试提供了一下特色:
jmeter 可以对测试静态资源(例如 js、html 等)以及动态资源(例如 php、jsp、ajax 等等)进行性能测试
jmeter 可以挖掘出系统最大能处理的并发用户数
jmeter 提供了一系列各种形式的性能分析报告
5.2 基本过程

5.3准备脚本
5.3.1新增线程组
右键点击“测试计划” -> “添加” -> “Threads(Users)” -> “线程组” ,这里可以配置线程组名称,线程数,准备时长(Ramp-Up Period(in seconds))循环次数,调度器等参数:
线程组参数详解:
1. 线程数:虚拟用户数。一个虚拟用户占用一个进程或线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
2. Ramp-Up Period(in seconds)准备时长:设置的虚拟用户数需要多长时间全部启动。如果线程数为10,准备时长为2,那么需要2秒钟启动10个线程,也就是每秒钟启动5个线程。
3. 循环次数:每个线程发送请求的次数。如果线程数为10,循环次数为100,那么每个线程发送100次请求。总请求数为10*100=1000 。如果勾选了“永远”,那么所有线程会一直发送请求,一到选择停止运行脚本。
4. Delay Thread creation until needed:直到需要时延迟线程的创建。
5. 调度器:设置线程组启动的开始时间和结束时间
持续时间(秒):测试持续时间,会覆盖结束时间
启动延迟(秒):测试延迟启动时间,会覆盖启动时间
启动时间:测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
结束时间:测试结束时间,持续时间会覆盖它。
5.3.2新增JMeter元组
5.3.3 新增监听器
A:聚合报告
Label:请求的名称,就是我们在进行测试的httprequest sampler的名称
Samples:总共发给服务器的请求数量,如果模拟10个用户,每个用户迭代10次,那么总的请求数为:1010 =100次;
Average:默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,以Transaction 为单位显示平均响应时间 ,单位是毫秒
Median: 50%用户的请求的响应时间,中位数
90%Line:90%的请求的响应时间
95%Line:95%的请求的响应时间
99%Line:99%的请求的响应时间
Min:最小的响应时间
Max:最大的响应时间
Error%:错误率=错误的请求的数量/请求的总数
Throughput: 默认情况下表示每秒完成的请求数(Request per Second)
B:查看结果树 C:Transactions per Second
C:Transactions per Second
监听动态TPS,用来分析吞吐量。其中横坐标是运行时间,纵坐标是TPS值。红色表示通过的TPS,绿色表示失败的。
最大TPS大约在140左右,从1分26秒左右,开始有未通过的事物
C:Hits per Second
动态监听单位时间的点击率,也就是触发的请求数。其中横坐标是运行时间,纵坐标是HPS值。
点击率波动较大,且不能持续上升。说明性能很不稳定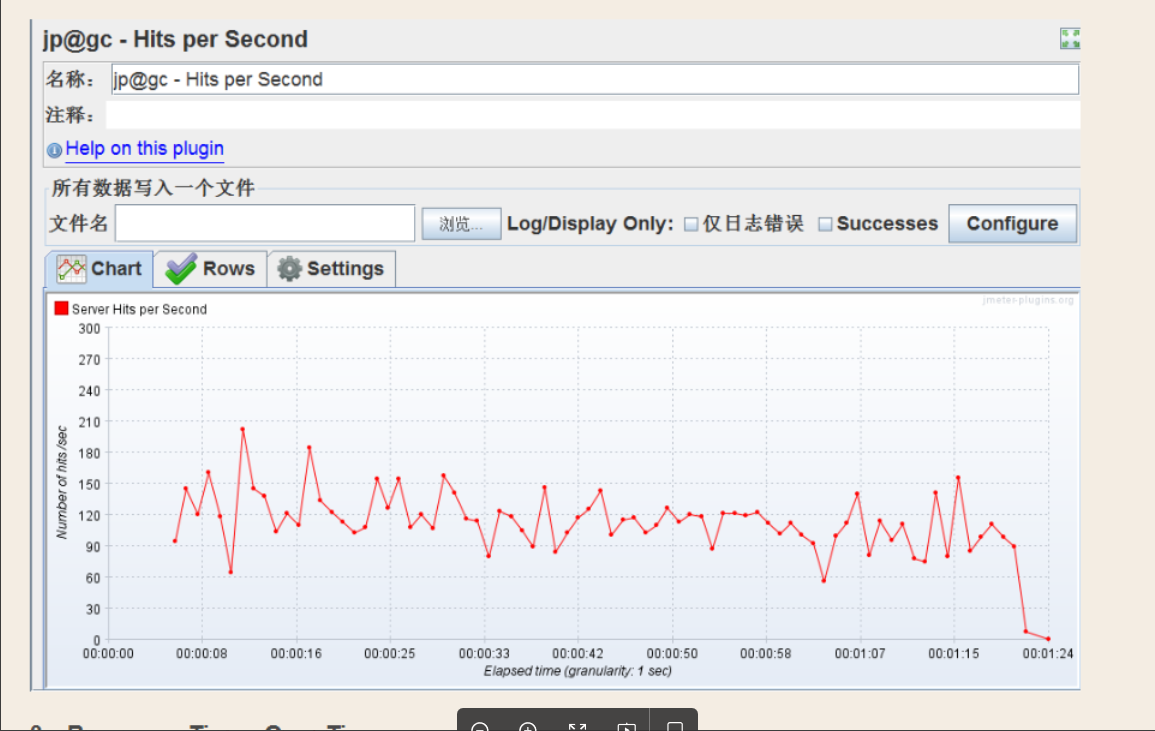
D:Response Times Over Time
监听整个事物运行期间的响应时间。其中横坐标是运行时间,纵坐标是响应时间(单位是毫秒)
响应时间在4950ms左右开始稳定下来,后续又经历一次大的波动
E:Response Times vs Threads
线程活动期间的响应时间监听。其中横坐标是活动的线程数(也就是并发数),纵坐标是响应时间(单位是毫秒)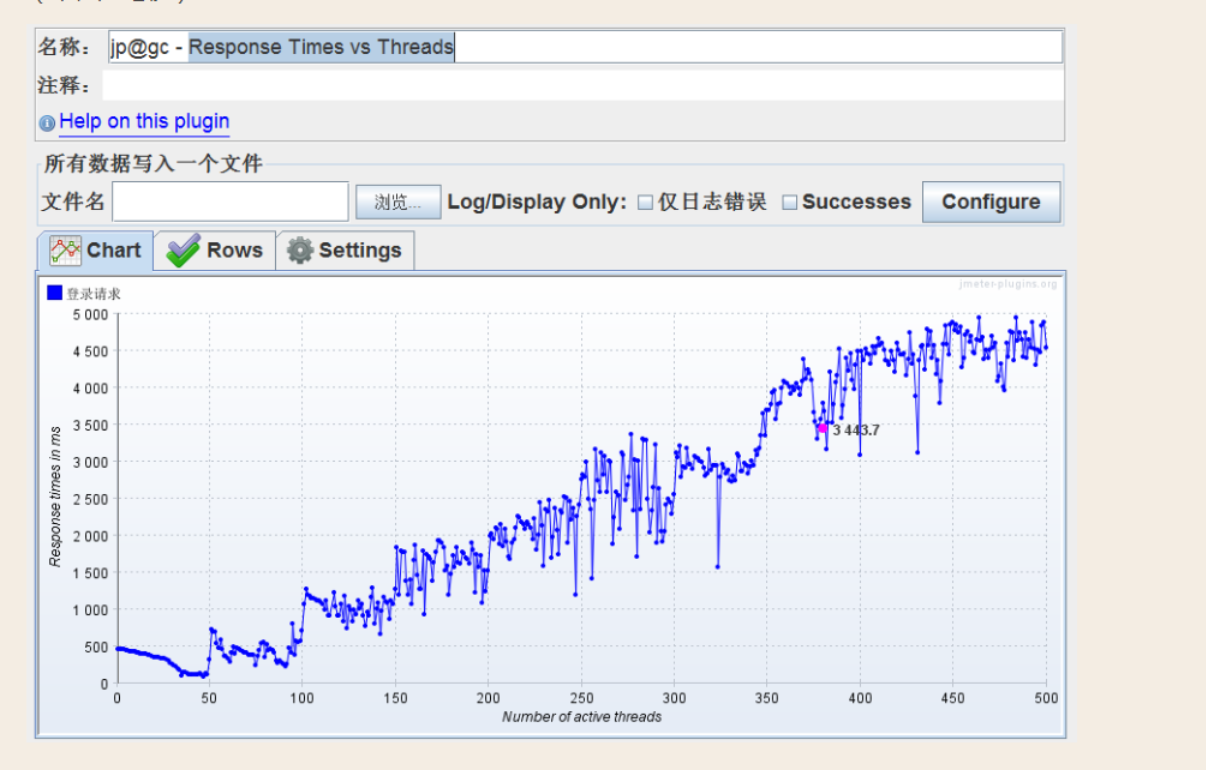
F:Active Threads Over Time
监听单位时间内活动的线程数。其中横坐标是单位时间(单位是毫秒),纵坐标是活动线程数(也就是并发数)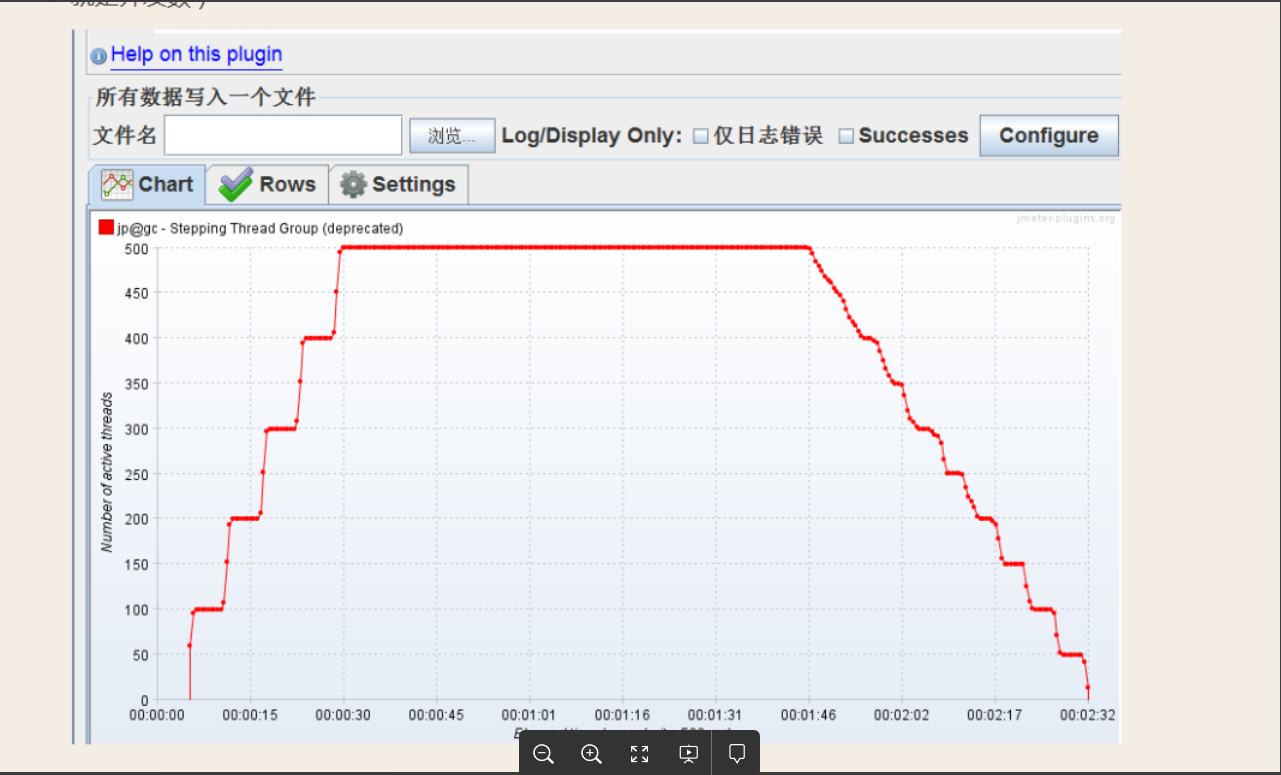
G:Response Times Percentiles
监听响应时间分布的百分比。其中横坐标是请求数的百分比,纵坐标是响应时间。此图表示有99.7%的请求响应时间在5s以内。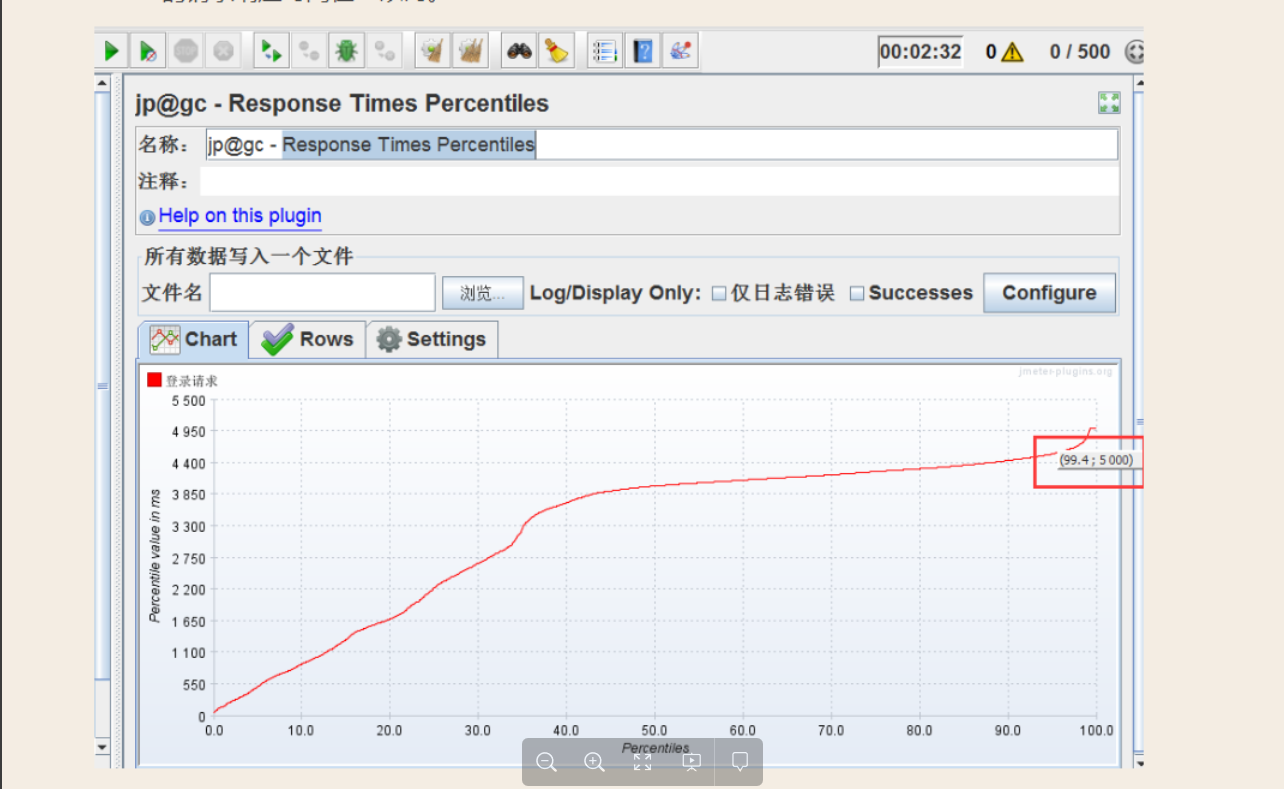
H:Response Times Distribution
响应时间分布的柱状图。其中横坐标是柱状分布图,纵坐标是响应时间。此图表示大约有111个请求响应时间在5076ms。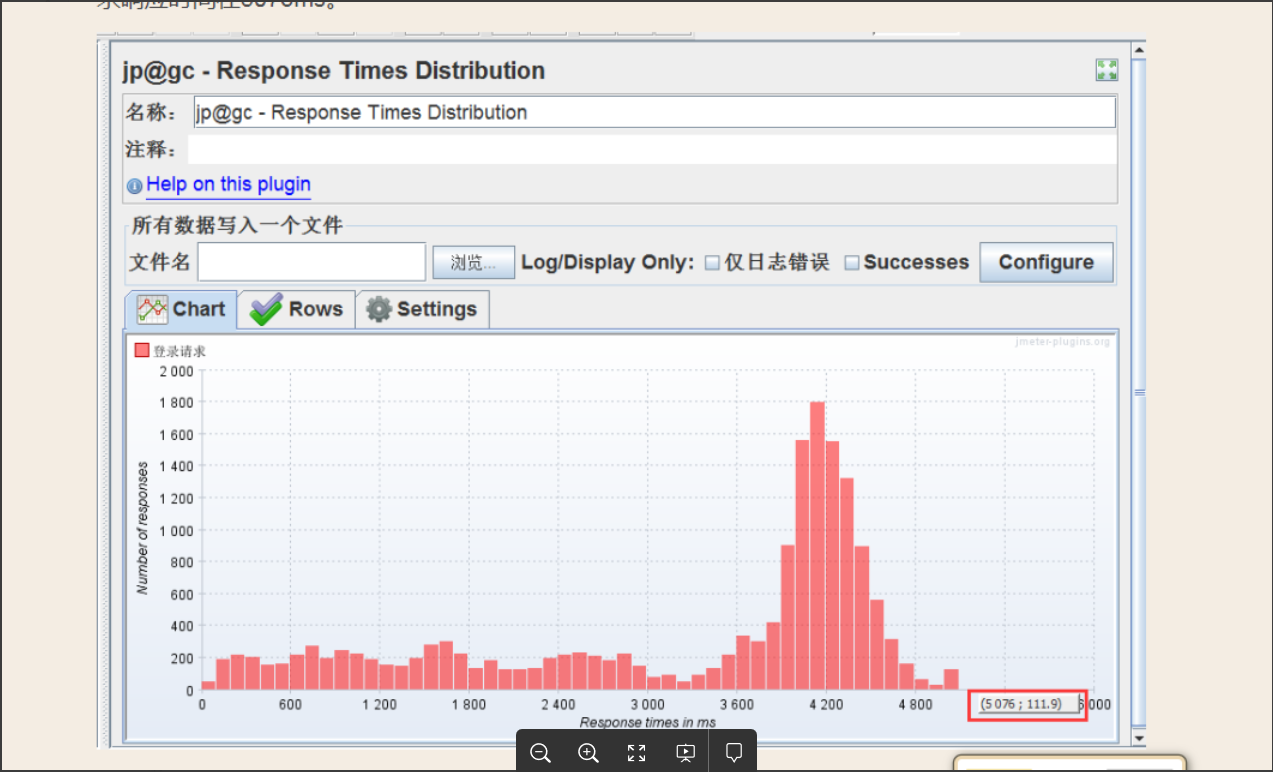
I:*Composite Graph
组合式的监听器。其中横坐标是运行时间,纵坐标是各性能数据的汇总值(其中有一些数据需要除以10)。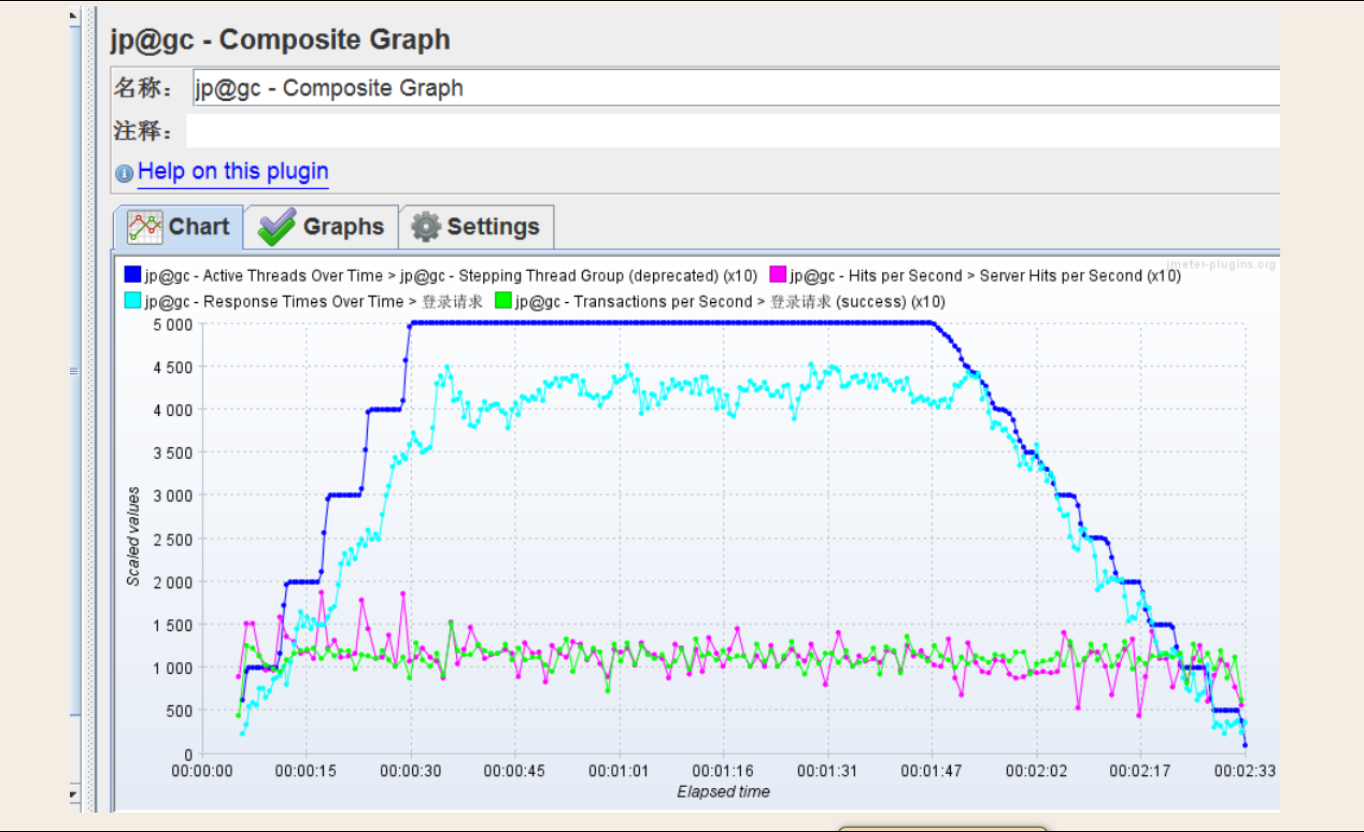
不同的监听器可以监听不同的性能数据,但是想要在图表中直观的分析出性能的瓶颈,就需要组合式的监听器。例如通过响应时间和吞吐量的分布得出吞吐量的拐点。
5.4其他相关元件
5.4.1定时器-Constant Throughput Timer
这是一个吞吐量定时器,它可以控制我们的TPS。
如图,我设定了目标吞吐量是2400/min,也就是40/s。
5.4.2逻辑控制器-吞吐量控制器
这个控制器里的吞吐量,指的是请求比例。
比如我们总共发出9000个请求,这个控制器下的接口只会发送3000个,比例控制在30%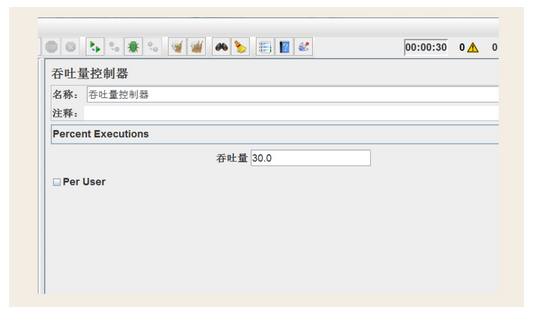
下面这张图更直观的说明了请求的比例分配
login1的控制器分配的比例是30%,剩余的70%都分给了login2的控制器
5.4.3 Throughput Shaping Timer
再来看一下 Throughput Shaping Timer
下图可以很明显看到它是用来控制RPS的,也就是每秒请求数。
start=1 end=100,持续时间是60。表示我们需要在60s内将RPS(每秒请求数)均匀的从1提升到100。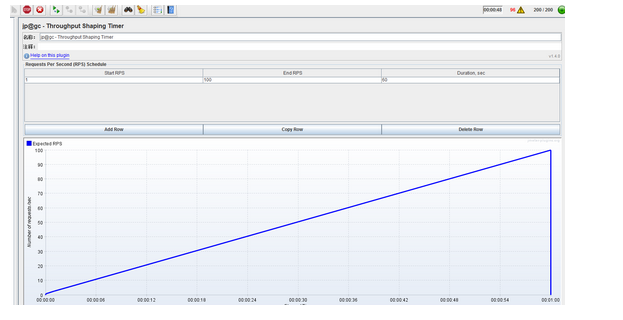
5.4.4集合点(定时器-Synchronizing Timer)
集合点作用:阻塞线程,直到指定的线程数量到达后,再一起释放,可以瞬间产生很大的压力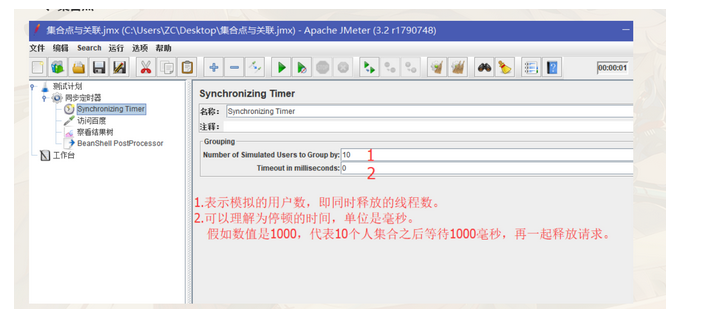
5.4.5 阶梯加压线程组
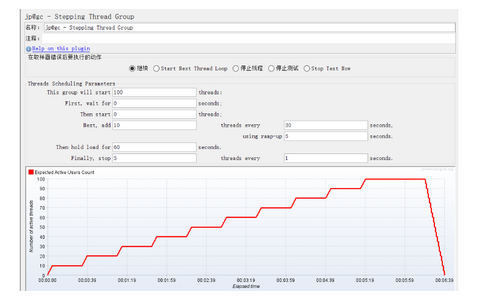
功能如下:
This group will start 100 threads:设置线程组启动的线程总数为100个;
First,wait for N seconds:启动第一个线程之前,需要等待N秒;
Then start N threads:设置最开始时启动N个线程;
Next,add 10 threads every 30 seconds,using ramp-up 5 seconds:每隔30秒,在5秒内启动10个线程;
Then hold load for 60 seconds:启动的线程总数达到最大值之后,再持续运行60秒;
Finally,stop 5 threads every 1 seconds:每秒停止5个线程;
6、服务器性能监控
6.1 安装插件
A:
下载客户端插件
https://jmeter-plugins.org/downloads/all/ 或者
https://jmeter-plugins.org/downloads/old/
下载服务端插件
https://github.com/undera/perfmon-agent/blob/master/README.md#supported-metrics 或者
https://jmeter-plugins.org/wiki/PerfMon/?utm_source=jmeter&utm_medium=helplink&utm_campaign=PerfMon
下载三个文件。其中JMeterPlugins-Standard和JMeterPlugins-Extras是客户端的,ServerAgent是服务端的。 B:前两个是jmeter扩展插件,解压后将jar拷贝包到jmeter的lib/ext目录下,最后一个是服务器监控插件,解压到服务器上
B:前两个是jmeter扩展插件,解压后将jar拷贝包到jmeter的lib/ext目录下,最后一个是服务器监控插件,解压到服务器上
C:./startAgent.sh 启动监控(配置端口和ip,端口默认4444);服务器上可以修改端口地址:./startAgent.sh —udp-port 0 —tcp-port 端口号
6.2 Jmeter客户端的监听测试
A:点击测试计划-》添加-》监听器-》jp@gc - PerfMon Metrics Collector,Permon Metrics Collector中配置被测服务器地址
在文件名处配置被测服务器日志生成地址
B:在被测服务器上运行性能脚本,结束后,将日志导入到本地
C:在Permon Metrics Collector导入该日志,就能看到性能指标的折线图了
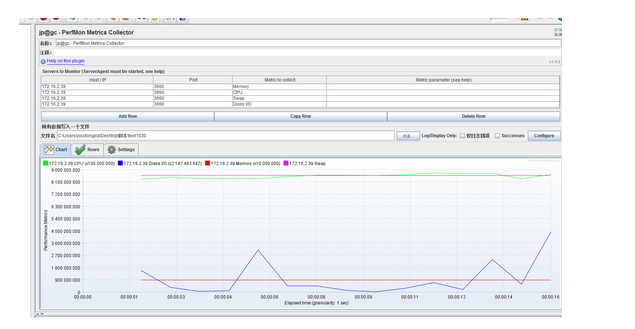
6.3 性能监控常用命令
我们在linux下,如果想要监控服务器性能。我们必须掌握以下常用的指标查看命令。
- ps
根据CPU的使用升序排序
ps -aux —sort -pcpu
根据内存使用升序排序
ps -aux —sort -pmem
上述两个命令合并一起,如下:
ps -aux —sort -pcpu,+pmem
只显示前几个进程,例如显示前十个,需要使用管道结合head命令。
ps -aux | head -n 10** - pstree
ps auxw|head -1;ps auxw|sort -rn -k3|head -10 cpu占用最高的十个进程
ps auxw|head -1;ps auxw|sort -rn -k4|head -10 内存占用最高的十个进程
ps auxw —sort=rss 实际内存占用排名
ps auxw —sort=%cpu 实际cpu消耗排名 - top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。
监控整个系统的整体性能情况top 命令是我们在日常情况下使用频率最高的,可以对当前系统环境了如指掌。处理器 load 率情况,memory 消耗情况,哪个 task 消耗 cpu 、memory 最高。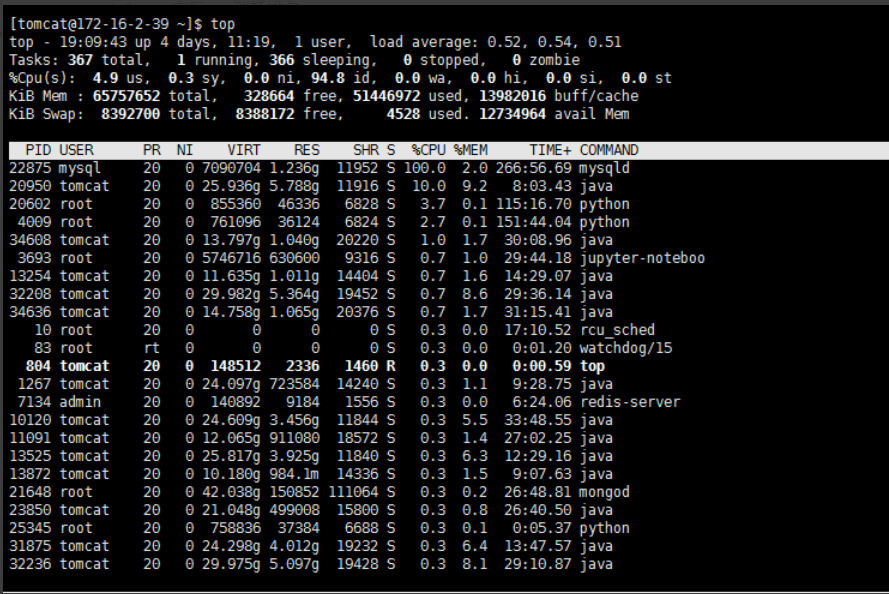
top 命令功能非常丰富,可以分别根据 %MEM、%CPU 排序。
load average 域表示 cpu load 率情况,后面三段分别表示最近1分钟、5分钟、15分钟的平均 load 率。这个值不能大于当前 cpu core(top命令按1可以查询) 数,如果大于说明 cpu load 已经严重过高。就要去查看是不是线程数设置的过高,还要考虑这些任务是不是处理时间太长。设置的线程数与任务所处理的时长有直接关系。
Tasks 域表示任务数情况,total 总的任务数,running 运行中的任务数,sleeping 休眠中的任务数,stopped 暂停中的任务数,zombie 僵尸状态任务数。
Swap 域表示系统的交换区,压测的时候关注 used 是否会持续升高,如果持续升高说明物理内存已经用完开始进行内存页的交换。
** - free
使用free -m命令,能让你清楚的了解当前系统内存消耗情况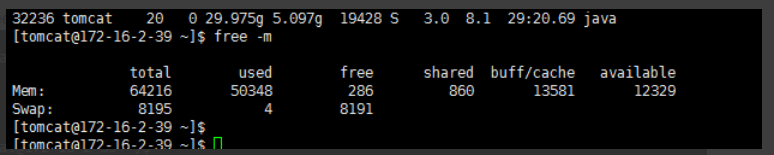
total 总内存大小,used 已经分配的内存大小,free 当前可用的内存大小,shared 任务之间的共享内存大小,buffers 系统已经分配但是还未使用的,用来存放文件 matedata 元数据内存大小,cached 系统已经分配但是还未使用的,用来存放文件的内容数据的内存大小。
-/+buffer/cache
used 要减去 buffers/cached ,也就是说并没有用掉这么多内存,而是有一部分内存用在了 buffers/cached 里。
free 要加上 buffers/cached ,也就是说还有 buffers/cached 空余内存需要加上。
Swap 交换区统计,total 交换区总大小,used 已经使用的交换区大小,free 交换区可用大小。只需要关注 used 已经使用的交换区大小,如果这里有占用说明内存已经到瓶颈。 - vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
相比于top、free等命令,vmstat可以看到整个机器的CPU,内存,IO的消耗情况。
一般情况下vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如下命令:
vmstat 2 1
2表示每个两秒采集一次服务器状态,1表示只采集一次**
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如: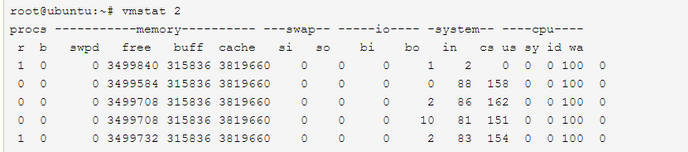
这表示vmstat每2秒采集数据,一直采集,直到我结束程序。好了,命令介绍完毕,现在开始实战讲解每个参数的意思。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
5.4 服务器瓶颈分析思路
概述:性能测试中,对服务端的指标监控也是很重要的一个环节。通过对各项服务器性能指标的监控分析,可以定位到性能瓶颈。
1、CPU定位分析
在系统的CPU分析定位过程中,当系统的CPU利用率大于50%时,我们就需要注意了;当系统的CPU利用率大于70%的时候,就需要密切关注;当系统的CPU的利用率高于90%的时候,情况就比较严重了。通过这些监控分析情况,我们可以用命令有vmstat、sar、dstat、mpstat、top、ps等命令来进行统计分析。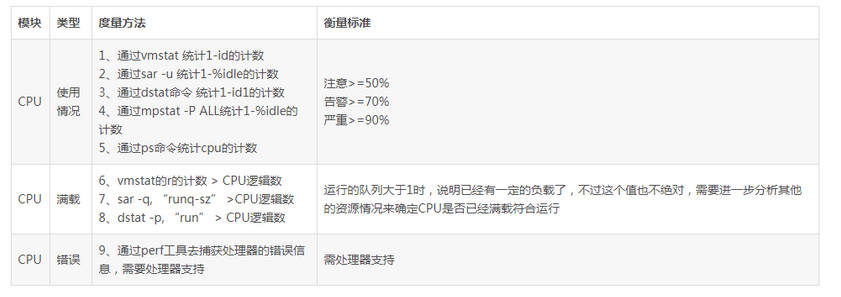 2、内存定位分析
2、内存定位分析
在系统的内存分析定位过程中,当系统内存的利用率大于50%的时候,我们就需要注意了;当系统的内存大于70%的时候,就需要密切关注;当系统的内存利用率高于80%的时候,情况就比较严重。通过这些监控分析,可以用vmstat、sar、dstat、free、top、ps等命令来进行统计分析。
3、网络定位分析
衡量系统网络的使用情况,可以使用的命令有sar、ifconfig、netstat以及查看net的dev速率,通过查看收发包的吞吐率达到网卡的最大上限(问题:网络的最大上限怎么看呢?),网络数据报文有因为这类原因而引发的丢包、阻塞等现象都证明当前网络可能存在瓶颈。在进行性能测试时,为了减小网络的影响,一般我们都是在局域网中进行测执行。
4、IO定位分析
衡量系统IO的使用情况,可以使用sar、iostat、iotop等命令进行系统级别的IO监控分析。当发现IO的利用率大于40%时候,就需要注意了;当使用率大于60%则处于告警阶段;大于80%时IO就会出现阻塞了。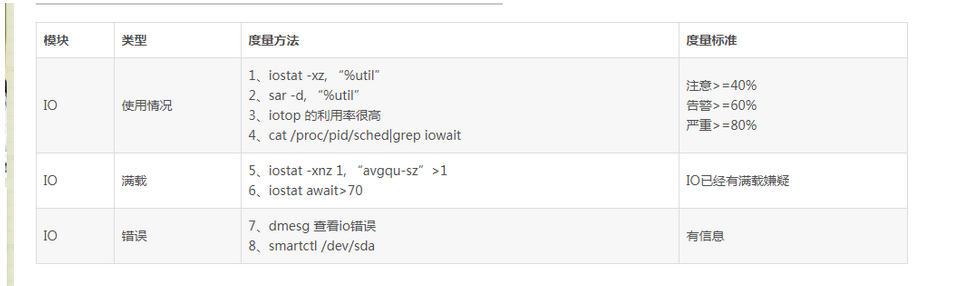
7、性能分析器-JProfiler

若有收获,就点个赞吧
0 人点赞
