-4.1 排序
(1)A1025
编程能力测试(PAT)由浙江大学计算机科学与技术学院组织。 每个测试应该在几个考场同时运行,并且排名列表将在测试后立即合并。 现在你的工作是编写一个程序来正确地合并所有排名表并生成最终排名。
输入规格:
每个输入文件包含一个测试用例。 对于每种情况,第一行包含一个正数 N (≤100),即测试位置的数量。 然后是 N 个排名表,每个排名表以包含正整数 K(≤300)的行、被试人数、然后是 K 行包含学号(13 位数字)和每个考生的总分的行开头。 一行中的所有数字都用空格分隔。
输出规格:
对于每个测试用例,首先在一行中打印测试者的总数。 然后按以下格式打印最终排名表:
id 总排名 考场号 考场排名
位置从 1 到 N 编号。输出必须按最终排名的非递减顺序排序。 相同分数的被试必须具有相同的排名,并且输出必须按注册号的非递减顺序排序。
Sample Input:
2
5
1234567890001 95
1234567890005 100
1234567890003 95
1234567890002 77
1234567890004 85
4
1234567890013 65
1234567890011 25
1234567890014 100
1234567890012 85
Sample Output:
9
1234567890005 1 1 1
1234567890014 1 2 1
1234567890001 3 1 2
1234567890003 3 1 2
1234567890004 5 1 4
1234567890012 5 2 2
1234567890002 7 1 5
1234567890013 8 2 3
1234567890011 9 2 4
题解:
(1)在排序时按照一定的原则(分数不同按分数由高到低,分数相同排名相同,顺序按字典序由小到大),因此sort函数的第三个参数cmp一定要设计好。(也可以运算符重载)
bool cmp(student a,student b){if(a.grade!=b.grade)return a.grade>b.grade;elsereturn strcmp(a.id,b.id)<0;}
(2)思路是在每个考场的循环时,对考场内部学生进行处理,将结构体内的local_rank(考场排名)和test_location(考场号)赋好值,然后再对整体排序,这样不会乱,因为每个考生一个结构体,结构体内的考场排名和考场号已经记录下了,最后直接带着总体排名输出一下就OK了
(3)需要注意的小细节:
a)下面代码的循环 i 可以直接作为考场号,因此从1开始
b) 设计结构体数组,用num控制下标,第二重循环(每个考场内部)每输入一个考生信息,就赋值下标为num的考生结构体信息,然后num++,非常巧妙。
c)为考生赋总排名时也很巧妙,单独设计变量p,分数相同p就不动,分数不同p直接更新为下标+1,亦为妙哉 !
for(int i=0;i<num;++i){if(Stu[i].grade!=Stu[i-1].grade){p = i+1;printf("%s %d %d %d\n",Stu[i].id,p,Stu[i].test_location,Stu[i].local_rank);}elseprintf("%s %d %d %d\n",Stu[i].id,p,Stu[i].test_location,Stu[i].local_rank);}
代码:
//// Created by 23011 on 23/1/2022.//#include <cstdio>#include <algorithm>#include <cstring>using namespace std;struct student {char id[20];int grade;int local_rank;int test_location;}Stu[100000];bool cmp(student a,student b){if(a.grade!=b.grade)return a.grade>b.grade;elsereturn strcmp(a.id,b.id)<0;}int main(){int n;int num=0;scanf("%d",&n);for(int i=1;i<=n;++i){ // i作为考场号,因此从1开始int k;scanf("%d",&k); //k是考场人数,之后作为下标for(int j=0;j<k;++j){scanf("%s%d",Stu[num].id,&Stu[num].grade);Stu[num].test_location = i;++num;}sort(Stu+num-k,Stu+num,cmp);Stu[num-k].local_rank = 1; //把这个考场排名第一的考生的考场排名置1for(int r=num-k+1;r<num;++r){if(Stu[r].grade==Stu[r-1].grade){Stu[r].local_rank = Stu[r-1].local_rank;}else{Stu[r].local_rank = r-(num-k)+1; //r-(num-k)是此考场在该生前面的人数}}}printf("%d\n",num);sort(Stu,Stu+num,cmp);int p=1;for(int i=0;i<num;++i){if(Stu[i].grade!=Stu[i-1].grade){p = i+1;printf("%s %d %d %d\n",Stu[i].id,p,Stu[i].test_location,Stu[i].local_rank);}elseprintf("%s %d %d %d\n",Stu[i].id,p,Stu[i].test_location,Stu[i].local_rank);}return 0;}
补充:
对结构体数组排序,调用sort时必须写cmp函数(即使是默认的升序的对某一元素排序也不行),否则会因为不知道对结构体内哪个元素排序而ERROR.
4.2 散列
Introduction:
1. 整数散列
我们先来看一个例子,给N个整数,再给M个整数,分别判断这M个整数是否出现在N个数中。没学过算法的同学,肯定会首选二重循环,对M中每个元素在N个数中遍历,这样会导致复杂度为 O(M*N),数据量大则不可行。那怎么办呢?👇
开辟一个很大很大的数组(N个大小也行),初值全为0,循环N次,每输入一个数,就置1。然后循环M次,每输入一个数,就直接寻址看下对应下标是不是为1,是就有,不是就没有。当然,如果题目想知道出现了几次的话,就不是每次都赋为1,而是++,一样的道理。复杂度O(M+N)
那么现在,散列我们知道是什么了,“散”就是不按顺序存储,以空间换时间,比如开始输入3,10,就是a[3],a[10]是1,其他位置还是0.(其他形式及知识点数据结构都学过,在此不赘述)
2. 字符串Hash
如果key不是整数,那我们应该如何映射成散列函数呢?
For example, 如何将一个二维整点P的坐标映射为一个整数,使得P可以由该整数唯一的代表。
我们假设P(x,y),其中≤x,y≤Range,那么可以令hash函数为H(P) = x*Range+y,这样对数据范围内的任意两个整点P1和P2,H(P1)都不会等于H(P2),即可以唯一的代表。
接下来,我们就能理解字符串Hash了,首先,我们先假设字符串都是大写字母A~Z,类比上面的例子,据相当于字母最多26个,就相当于Range,每个字母和A的距离,就是y。代码如下:
//假设字母全为大写(A~Z)int hashFunc (char S[], int len) //将字符串整数转换为唯一的整数{int id = 0;for(int i=0;i<len;++i){id = id*26 + (S[i]-'A'); // 将26进制转换为十进制}return id;}
当然,举一反三,如果存在小写字母的话,也没问题啦~ 0~25表示大写,26~51表示小写,这样就变成了52进制转换为十进制的问题,代码如下:
int hashFunc (char S[], int len) //将字符串整数转换为唯一的整数{int id = 0;for(int i=0;i<len;++i){if(S[i]>='A' && S[i]<='Z'){id = id*26 + (S[i]-'A');}else if(S[i]>='a' && S[i]<='z'){id = id*52 + (S[i]-'a') + 26;}}return id;}
**当然啦,聪明的读者肯定就会明白,当字符串中除了大小写字母,还含有数字的话,也很简单,增大进制数到62即可。**
(1)P110
**
#include <cstdio>const int maxn = 100;char S[maxn][5],temp[5];int hashTable[25*26*26+10];int hashFunc (char S[], int len){int id = 0;for(int i=0;i<len;++i){id = id*26+(S[i]-'A');}return id;}int main(){int m,n;scanf("%d%d",&n,&m);for(int i=0;i<n;++i){scanf("%s",S[i]);int id = hashFunc(S[i],3);hashTable[id]++;}for(int i=0;i<m;++i){scanf("%s",temp);int id = hashFunc(temp,3);printf("%d\n",hashTable[id]);}return 0;}
(2)B029 & A1084
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现。现在给出应该输入的一段文字、以及实际被输入的文字,请你列出肯定坏掉的那些键。
输入格式:
输入在 2 行中分别给出应该输入的文字、以及实际被输入的文字。每段文字是不超过 80 个字符的串,由字母 A-Z(包括大、小写)、数字 0-9、以及下划线 _(代表空格)组成。题目保证 2 个字符串均非空。
输出格式:
按照发现顺序,在一行中输出坏掉的键。其中英文字母只输出大写,每个坏键只输出一次。题目保证至少有 1 个坏键。
输入样例:
输出样例:
题解:
(1)不能像之前那样把每个字符转换成整数,把每个字符转换成对应的整数储存,因为最多80个字符,26+10+1≈40个数,40的80次方~~~~ 直接炸掉内存吧 。 所以这道题采用的hashTable[128]里面只存储每种字符键盘上是不是坏的,初始值为false, 从头到尾遍历标准字符串中每个字符,再二重循环遍历键盘字符串输出的字符,遇到相等,则终止第二重循环,继续从标准字符串下一位开始。如果遍历到键盘串的最后还没有相等的,那就输出,并把hashTable置为true
(2)下面代码中c1!=c2也可以换成j==len2,当然这样的话,j就不能在for里面定义了。等价是因为当你刚出j的循环的时候,你执行到c1!=c2说明j循环里没有break,没有和标准的c1相等,此时c2就是最后一个字符。嗯嗯,懂了吧
代码:
#include <cstdio>#include <cstring>char s1[100];char s2[100];bool hashTable [128] = {false};int main(){scanf("%s",s1);scanf("%s",s2);int len1 = strlen(s1);int len2 = strlen(s2);char c1,c2;for(int i=0;i<len1;++i){for(int j=0;j<len2;++j){c1 = s1[i];c2 = s2[j];if(c1>='a'&&c1<='z'){c1-=32;}if(c2>='a'&&c2<='z'){c2-=32;}if(c1==c2) break;}if(c1!=c2 && hashTable[c1]== false){printf("%c",c1);hashTable[c1] = true;}}return 0;}
4.3 递归
全排列(按字典序)
// P115 全排列(以n=3为例)#include <cstdio>const int maxn = 11;// P为当前排列,hashTable记录整数x是否已经在P中int n, P[maxn];bool hashTable[maxn] = {false};//当前处理排列的第index号位void generateP (int index){if(index==n+1){for(int i=1;i<=n;++i){printf("%d",P[i]);}printf("\n");return;}for(int j=1;j<=n;++j){if(hashTable[j]== false){P[index] = j;hashTable[j] = true;generateP(index+1);hashTable[j] = false;}}}int main(){n = 3;generateP(1);return 0;}
N皇后(递归+哈希)

// N皇后问题 (全排列)#include <cstdio>#include <cmath>const int maxn = 10;bool hashTable[maxn] = {false};int n,count = 0,P[maxn];void generateP (int index){if(index==n+1){bool flag = true;for(int i=1;i<=n;++i){for(int j=i+1;j<=n;++j){if(abs(i-j)== abs(P[i]-P[j])){flag = false;break;}}}if(flag){count++;}return;}for(int j=1;j<=n;++j){if(hashTable[j]== false){P[index] = j;hashTable[j] = true;generateP(index+1);hashTable[j] = false;}}}int main(){n = 8;generateP(1);printf("%d",count);return 0;}
N皇后 (回溯+哈希)

// 回溯法#include <cstdio>#include <cmath>const int maxn = 10;int n,P[maxn],count=0;bool hashTable[11];//一列一列放void generateP (int index){if(index == n+1) //递归边界,生成合理的方案,当条件成立,一定合法,否则早就回溯了{count++;return;}for (int x = 1;x<=n;++x) //x是当前列的皇后放在第几行,遍历一遍,不行直接回溯{if (hashTable[x] == false){bool flag = true;for(int pre=1;pre<index;++pre) //遍历之前的皇后{if(abs(index-pre)== abs(x-P[pre])){flag = false;break;}}if(flag){ // 如果可以的话P[index] = x; // 把Index列的皇后放到第x行hashTable[x] = true; //第x行已被占用generateP(index+1);hashTable[x] = false;}}}}int main(){n = 8;generateP(1);printf("%d",count);return 0;}
(1)4-3-D
题目描述
会下国际象棋的人都很清楚:皇后可以在横、竖、斜线上不限步数地吃掉其他棋子。如何将8个皇后放在棋盘上(有8 * 8个方格),使它们谁也不能被吃掉!这就是著名的八皇后问题。
对于某个满足要求的8皇后的摆放方法,定义一个皇后串a与之对应,即a=b1b2…b8,其中bi为相应摆法中第i行皇后所处的列数。已经知道8皇后问题一共有92组解(即92个不同的皇后串)。
给出一个数b,要求输出第b个串。串的比较是这样的:皇后串x置于皇后串y之前,当且仅当将x视为整数时比y小。
输入
第1行是测试数据的组数n,后面跟着n行输入。每组测试数据占1行,包括一个正整数b(1 <= b <= 92)
输出
输出有n行,每行输出对应一个输入。输出应是一个正整数,是对应于b的皇后串。
样例输入
样例输出
题解:
(1)照搬N皇后全排列算法,但是下面的代码是错误的,我们必须新开辟一个int ans[100]数组(因为8皇后92个解<100),每个元素是int型,能存8位数。下面的代码为什么不行呢?因为,其实这段代码的本质可以理解为回溯,比如当index=6(第六列)时找到解,此时会接着从index=5继续判断,但是cnt已经++了,下一行数组的前几位没赋值,会出现前导0.
#include <cstdio>#include <cmath>const int maxn = 10;bool hashTable[maxn] = {false};int n,count = 0,P[100][maxn];void generateP (int index){if(index==n+1){bool flag = true;for(int i=1;i<=n;++i){for(int j=i+1;j<=n;++j){if(abs(i-j)== abs(P[count][i]-P[count][j])){flag = false;break;}}}if(flag){count++;}return;}for(int j=1;j<=n;++j){if(hashTable[j]== false){P[count][index] = j;hashTable[j] = true;generateP(index+1);hashTable[j] = false;}}}int main(){n = 8;generateP(1);int k;scanf("%d",&k);for(int l=0;l<k;++l){int w;scanf("%d",&w);for(int u=0;u<8;++u){printf("%d",P[w][u]);}printf("\n");}return 0;}
(2)网上的代码在main里面还加了sort函数,不用的,因为我们就是从index=1开始一点点加上去的,所以存进去的本来就是从小到大的结果。
代码:
#include <cstdio>#include <cmath>#include <algorithm>using namespace std;const int maxn = 11;int ans[100] = {0};bool hashTable[maxn] = {false};int n,cnt = 0;int P[10];void generateP (int index){if(index==n+1){bool flag = true;for(int i=1;i<=n;++i){for(int j=i+1;j<=n;++j){if(abs(i-j)== abs(P[i]-P[j])){flag = false;break;}}}if(flag){for(int i=1;i<=8;i++){ans[cnt]=ans[cnt]*10+P[i];//将结果数组转化为整数}cnt++;}return;}for(int j=1;j<=n;++j){if(hashTable[j] == false){P[index] = j;hashTable[j] = true;generateP(index+1);hashTable[j] = false;}}}int main(){n = 8;generateP(1);int t;scanf("%d",&t);for(int i=0;i<t;++i){int n;scanf("%d",&n);printf("%d\n",ans[n-1]);}return 0;}
4.4 贪心
(1)B1020
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
输入格式:
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
输出格式:
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
输入样例:
输出样例:
题解:
这道题非常简单,但是以下几点需要注意:
(1)下面代码中的profit,need一定都设为double,因为store和sell题目只说了是正数,没说是整数,因此要设为double ,而这几个变量之间存在比较、运算的步骤,因此数据类型要相同,否则很可能导致WA 。
(2)记得每次循环后更新需求量,循环内部一旦发现库存量>=需求量,那求下现在的利润后马上break; !!
#include <iostream>#include <cstdio>#include <algorithm>using namespace std;struct mooncake{double store;double sell;double price;};bool cmp (mooncake a,mooncake b){return a.price>b.price;}int main(){int n;scanf("%d",&n);mooncake M[n];double need;scanf("%lf",&need);for(int i=0;i<n;++i){scanf("%lf",&M[i].store);}for(int i=0;i<n;++i){scanf("%lf",&M[i].sell);}for(int i=0;i<n;++i){M[i].price = M[i].sell/M[i].store;}sort(M,M+n,cmp);double tmp1,profit=0;for(int i=0;i<n;++i){if(M[i].store>=need){profit+=need*M[i].price;break;}else{profit+=M[i].store*M[i].price;need-=M[i].store;}}printf("%.2f",profit);return 0;}
(2) P123 区间贪心

#include <cstdio>#include <algorithm>using namespace std;const int maxn = 110;struct Interval{int x;int y;}I[maxn];bool cmp (Interval a,Interval b){if(a.x!=b.x)return a.x>b.x;elsereturn a.y<b.y;}int main(){int n;scanf("%d",&n);for(int i=0;i<n;++i){scanf("%d",&I[i].x);scanf("%d",&I[i].y);}sort(I,I+n, cmp); //把区间排序// ans记录不相交区间的个数,lastX记录上一个被选中区间的左端点int ans = 1, lastX = I[0].x;for(int i=1;i<n;++i){// 区间选点问题只需要把if里面的<=改为<就OK(闭区间的话)if(I[i].y <= lastX){ //该区间右端点在lastX左边lastX = I[i].x; //以I[i]作为新选中的区间ans++; //不相交个数++}}printf("%d\n",ans);return 0;}
注:如果是区间选点问题(通常是闭区间),只需要把I[i].y<=lastX改为<即可
4.5 二分
(1)二分查找:
#include <cstdio>const int n = 10;int binaryFind (int a[],int left,int right,int key){int mid;while (left<=right){mid = (left+right)/2;if(a[mid]==key){return mid;}else if(a[mid]<key){left = mid+1;}else{right = mid-1;}}return -1;}int main(){int s[n] = {1,3,5,6,23,35,46,4,9,44};int p = binaryFind(s,0,9,23);int q = binaryFind(s,0,9,55);printf("%d\n%d\n",p,q);return 0;}
(2)找第一个大于等于x的数
int lower_bound (int A[],int left,int right,int x){int mid;while (left<right){mid = (left+right)/2;if(A[mid]>=x){right = mid;}else{left = mid+1;}}return left;}
其实上面的代码我们返回left和right是等价的,因为循环退出的条件是left==right
(3)找第一个大于x的数
int lower_bound (int A[],int left,int right,int x){int mid;while (left<right){mid = (left+right)/2;if(A[mid]>x){right = mid;}else{left = mid+1;}}return left;}
大家可以发现寻找第一个大于x的数和大于等于x的数的区别就是if判断里面的一个等号,仔细想一想就懂原因了。
通过上面几个例子,我们很容易就总结出“解决有序序列第一个满足某条件的元素的位置”模板(左闭右闭):
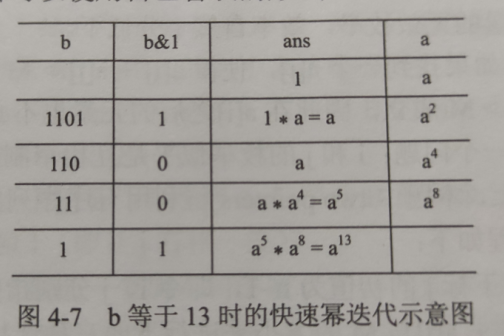
(4) 快速幂 (ab %m)
**为了求解a****b ****%m,如果数据量不大的话直接就能求出来,但是假如b很大很大,如1e18,那暴力求解肯定会爆炸,因此我们使用快速幂的办法:**<br />
typedef long long LL;//求a^b%m,递归写法LL binaryPow (LL a,LL b,LL m){if(b==0)return 1;if(b%2==0){ // 等价于if(b&1) ,这样执行速度快一些return a* binaryPow(a,b-1,m)%m;}else{ //b为偶数LL mul = binaryPow(a,b/2,m);return mul*mul%m;}}

typedef long long LL;//求a^b%m,递归写法LL binaryPow (LL a,LL b,LL m){LL ans = 1;while (b>0){if(b&1){ans = ans*a%m;}a = a*a%m;b>>=1; // b = b >> 1 (b=b/2)}return ans;}
4.6 Two Pointers
综述:
问题1:
给定一个递增的正整数序列和一个正整数M,求序列中两个不同位置的数a和b,使得它们的和恰好为M,输出所有满足条件的方案。(不是递增的sort一下就好了)
方案1: 二重循环遍历。 (但是n在10**5**规模时是不可承受的)
方案2:蛮力遍历导致不可行是因为存在许多无效遍历。a[i]+a[j]>M了,a[i]+a[j+1]以及之后的就不用考虑了,同样a[i+1]+a[j]也不用考虑了。因此我们把i,j初始值分别设为0和n-1,分三种情况判断,并移动i,j即可(复杂度O(n))
while(i<j){if(a[i]+a[j]==m){printf("%d %d\n",i,j);i++;j--;}else if(a[i]+a[j]<m){i++;}else{j--;}}
问题2:
将两个递增序列合并为一个大的递增序列。(其实方法和有序链表的merge函数一样)
方案:i,j的初值为0,每次都比较两个序列的首元素(首元素即为最小元素)
int merge (int A[], int B[], int C[], int n, int m){int i=0,j=0,index=0; // i指向A[0],j指向B[0]while(i<n && j<m){if(A[i]<=B[j]){C[index++] = A[i++];}else{C[index++] = B[j++];}}while(i<n){C[index++] = A[i++]; // 将序列A的剩余元素加入到序列C}while(j<m){C[index++] = B[j++]; // 将序列B的剩余元素加入到序列C}return index;}
问题3:(归并排序)
递归实现:
const int maxn = 100;//将数组A的[L1,R1]与[L2,R2]区间合并为有序区间 (此处L2即为R1+1)void merge (int A[],int L1, int R1, int L2, int R2){int i = L1, j = L2;int temp[maxn], index = 0; // temp临时存放合并后的数组,index为 其下标while(i<=R1 && j<=R2){if(A[i]<=A[j]){temp[index++] = A[i++];}else{temp[index++] = A[j++];}}// 看看谁剩了,将剩余元素加入序列tempwhile(i <= R1){temp[index++] = A[i++];}while (j <= R2){temp[index++] = A[j++];}for(int i=0;i<index;++i){A[L1+i] = temp[i]; //将合并后的序列赋值回数组A}}// 将array数组当前区间[left,right]进行归并排序void mergeSort (int A[], int left, int right){if(left < right){int mid = (left+right)/2;mergeSort(A,left,mid); // 递归将左区间排序mergeSort(A,mid+1,right); // 递归将右区间排序merge(A,left,mid,mid+1,right); // 将左子区间和右子区间合并}}
非递归实现:
(1)B1040 & A1093
字符串 APPAPT 中包含了两个单词 PAT,其中第一个 PAT 是第 2 位(P),第 4 位(A),第 6 位(T);第二个 PAT 是第 3 位(P),第 4 位(A),第 6 位(T)。
现给定字符串,问一共可以形成多少个 PAT?
输入格式:
输入只有一行,包含一个字符串,长度不超过105,只包含 P、A、T 三种字母。
输出格式:
在一行中输出给定字符串中包含多少个 PAT。由于结果可能比较大,只输出对 1000000007 取余数的结果。
输入样例:
输出样例:
题解:
**世界上最蠢的做法就是三重循环遍历字符串,分别遍历P,A,T。必然会超时。**<br />** 其实,仔细分析一下,不难发现结果就是每个A的左边P的个数*右边T的个数,把这些乘积加在一起就是答案。所以,我们先遍历一遍,用数组存储一下每个下标左边的P的个数,再从右向左遍历一次,是T就把T数量++,是A就更新结果ans.(记得取余)**
代码:
#include <cstdio>
#include <cstring>
const int mod = 1000000007;
char s[100000];
int leftNum[100000]={0};
int main()
{
gets(s);
int len = strlen(s);
for(int i=0;i<len;++i){
if(i>0){
leftNum[i] = leftNum[i-1];
}
if(s[i]=='P'){
leftNum[i]++;
}
}
int rightNum = 0;
int ans = 0;
for(int j=len-1;j>=0;--j){
if(s[j]=='T'){
rightNum++;
}
else if(s[j]=='A'){
ans = (ans+leftNum[j]*rightNum)%mod;
}
}
printf("%d\n",ans);
return 0;
}

若有收获,就点个赞吧
0 人点赞
