二、实时数仓典型架构
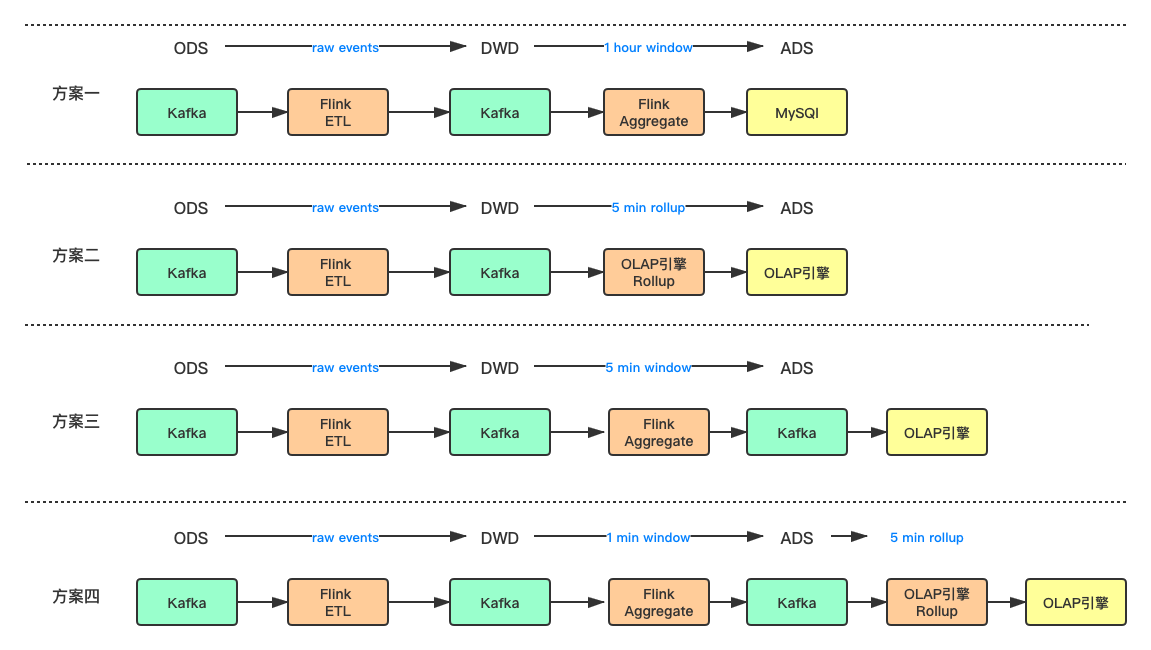
- 方案一:第一种方案的架构最为简单,ODS层的Kafka数据经过Flink的ETL处理后写入DWD层的Kafka,再通过Flink聚合写入ADS层的MySQL中,做这样一个实时报表展示。
- 缺点:由于MySQL存储数据有限,所以聚合的时间粒度不能太细,维度组合不能太多。
- 方案二:第二种方案相对于第一种引入了OLAP引擎,同时也不用Flink来做聚合运算,通过OLAP引擎自身的Rollup来做聚合。
- 缺点:因为OLAP引擎主要是用于存储和查询,不属于计算引擎,当数据量巨大时,比如每天上百亿、千亿的数据量,会加剧Druid的导入压力。
- 方案三:第三种架构是在第二种基础上,采用Flink来做聚合计算写入Kafka,最终写入OLAP引擎。
- 缺点:当窗口粒度比较长时,结果输出会有延迟。
- 方案四:第四种架构是在第三种基础上,结合了Flink聚合和OLAP引擎的Rollup。Flink可以做轻度的聚合,OLAP引擎做Rollup的汇总。好处是Druid可以实时看到Flink的聚合结果。

若有收获,就点个赞吧
0 人点赞
