基于tensorflow的神经网络搭建,用张量表示数据,用计算图搭建神经网,用回话执行计算图,优化参数获取模型。
张量:多维数组
数据类型:tf.float32 , tf.int32等
import tensorflow as tfa=tf.constant([1.0,2.0])b=tf.constant([3.0,4.0])result=a+bprint result<< Tensor ("add:0", shape=(2,),dtype=float32)
计算图(graph)搭建神经网络的计算过程,只搭建网络不计算。会画(session)执行计算图的节点运算
import tensorflow as tfa=tf.constant([1.0,2.0])b=tf.constant([3.0,4.0])y=tf.matul(a,b)with tf.Session() as sess:print sess.run(y)<< Tensor("matual:0",shape(1,1),dtype=float32)<<[[11.]]
神经网参数参数
随机生成参数函数:
w=tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1) 生成正态分布随机数,现状两行三列,标准差2,均值0,随机种子1
神经网络实现过程:
1)准备数据提取特征最为输入送进神经网络
2)搭建网络,输入到输出(先建图在执行会话)
3)大量数据特征输入神经网,迭代优化参数
4)训练好模型进行预测
前向传播
#coding:utf-8import tensorflow as tfx=tf.placeholder(tf.float32,shape=(None,2))w1=tf.Variable(tf.random_normal([2,3],stddev=2,mean=0,seed=1)w2=tf.Variable(tf.random_normal([3,1],stddev=2,mean=0,seed=1)a=tf.matmul(x,w1)y=tf.matmul(a,w2)with tf.Session() as sess:init_op=tf.global_variables_initializer()print sess.run(init_op)print sess.run(y,feed_dict={x:[[0.5,0.7],[0.4,0.5]]})
反向传播
loss=tf.reduce_mean(tf.square(y-y_))# ce=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-12,1.0))) #交叉熵train_step=tf.train.GradientDescentOptimizer(0.001).minimize(loss)
with tf .Session() as sess:init_op=tf.global_variables_initializer()sess.run(init_op)STEPS=3000for i in range(STEPS):start=(i*BATCH_SIZE)%32end=start+BATCH_SIZEsess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})if i%500==0:total_loss=sess.run(loss,feed_dict={x:X,y_:Y})print ("after %d training steps,loss on all data is %h" % (i,total_loss))
优化
学习率
learning_rate
指数衰减形式
tf.train.exponential_decay(learning_rate,global_step,decay_steps,decay_rate,staircase=False,name=None):
交叉熵
tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
import tensorflow as tfimport numpy as npdef sigmoid(x):return 1.0/(1+np.exp(-x))# 5个样本三分类问题,且一个样本可以同时拥有多类y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])y_pred = sigmoid(logits)E1 = -y*np.log(y_pred)-(1-y)*np.log(1-y_pred)print(E1) # 按计算公式计算的结果sess =tf.Session()y = np.array(y).astype(np.float64) # labels是float64的数据类型E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))print(E2)
过拟合 正则化
1-增加数据量
2-正规化y=Wx,W为各种参数,在W变化得太大时,将误差也变得更大,作为一种惩罚机制
L1正规化 cost=(Wx-real_y)^2+abs(W))
L2正规化 cost=(Wx-real_y)^2+W^2
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))loss=cem+tf.add_n(tf.get_collection('losses'))
正则化项
当在前向传播过程中即 forward.py 文件中,设置正则化参数 regularization 为1 时,则表明在反向传播过程中优化模型参数时,需要在损失函数中加入正则化项。
forward.py 文件中加入 if regularizer != None:tf.addto_collection(‘losses’,tf.contrib.layers.l2_regularizer(regularizer)(w))
反向传播过程即 backword.py 文件中加入
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y, 1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection(‘losses’))
3-Dropout正规化,每次训练后随机忽略一些神经元,使得神经网络不完整,这样得出的结果不会依赖于某一部分特定的神经元
滑动平均 :在模型训练时引入滑动平均可以使模型在测试数据上表现的更加健壮
#coding:utf-8#滑动平均:记录一段时间内权值和偏置的平均值,提高泛化能力import tensorflow as tf#1.定义变量及滑动平均类#定义一个32位浮点变量,初始值为0.0 这个代码就是不断更新w1参数,优化w1参数,滑动平均做了个w1的影子w1 = tf.Variable(0, dtype=tf.float32)#定义num_updates (NN的迭代轮数),初始值为0,不可被优化(训练),这个参数不训练global_step = tf.Variable(0, trainable=False)#实例化滑动平均类,给删减率为0.99,当前轮数global_stepMOVING_AVERAGE_DECAY = 0.99ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)#ema.apply后的括号里是更新列表,每次运行sess.run(ema_op)时,对更新列表中的元素求滑动平均值#在实际应用中会使用tf.trainable_variables()自动将所有待训练的参数汇总为列表#ema_op = ema.appply([w1])ema_op = ema.apply(tf.trainable_variables())#2.查看不同迭代中变量取值的变化with tf.Session() as sess:#初始化init_op = tf.global_variables_initializer()sess.run(init_op)#用ema.average(w1)获取w1滑动平均值(要运行多个节点,作为列表中的元素列出,写在sess.run中)#打印出当前参数w1和w1滑动平均值print sess.run([w1, ema.average(w1)])#参数w1赋值为1sess.run(tf.assign(w1, 1))sess.run(ema_op)print sess.run([w1, ema.average(w1)])#更新step和w1的值,模拟出100轮迭代后,参数w1变为10sess.run(tf.assign(global_step, 100))sess.run(tf.assign(w1, 10))sess.run(ema_op)print sess.run([w1,ema.average(w1)])#每次sess.run会更新一次w1的滑动平均值sess.run(ema_op)print sess.run([w1, ema.average(w1)])sess.run(ema_op)print sess.run([w1, ema.average(w1)])sess.run(ema_op)print sess.run([w1, ema.average(w1)])sess.run(ema_op)print sess.run([w1, ema.average(w1)])sess.run(ema_op)print sess.run([w1, ema.average(w1)])sess.run(ema_op)print sess.run([w1, ema.average(w1)])
用 300 个符合正态分布的点 X[x0, x1]作为数据集,根据点 X[x0, x1]的不同进行标注 Y,将数据集标
注为红色和蓝色。标注规则为:当 x0^2 + x1^2 < 2 时,y=1,点 X 标注为红色;当 x0^2 + x1^2 ≥2 时,
y_=0,点 X 标注为蓝色。我们加入指数衰减学习率优化效率,加入正则化提高泛化性,并使用模块化
设计方法,把红色点和蓝色点分开。
代码总共分为三个模块:生成数据集(generateds.py)、前向传播(forward.py)、反向传播
(backward.py)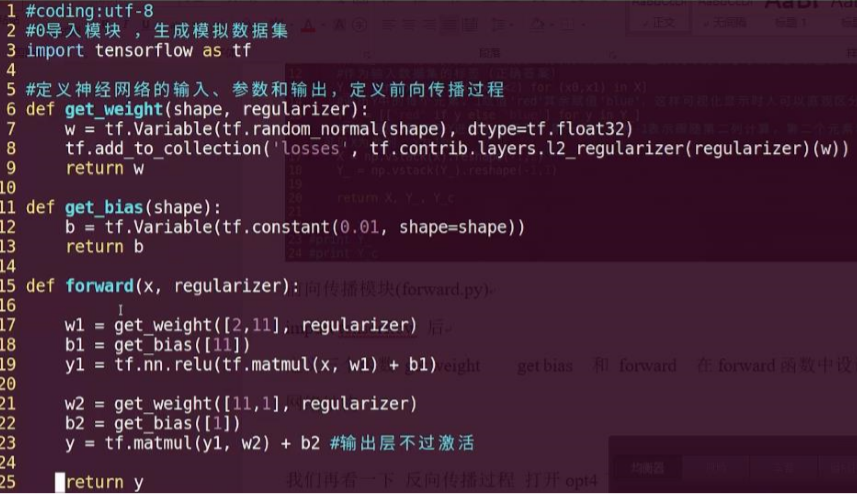
backward.py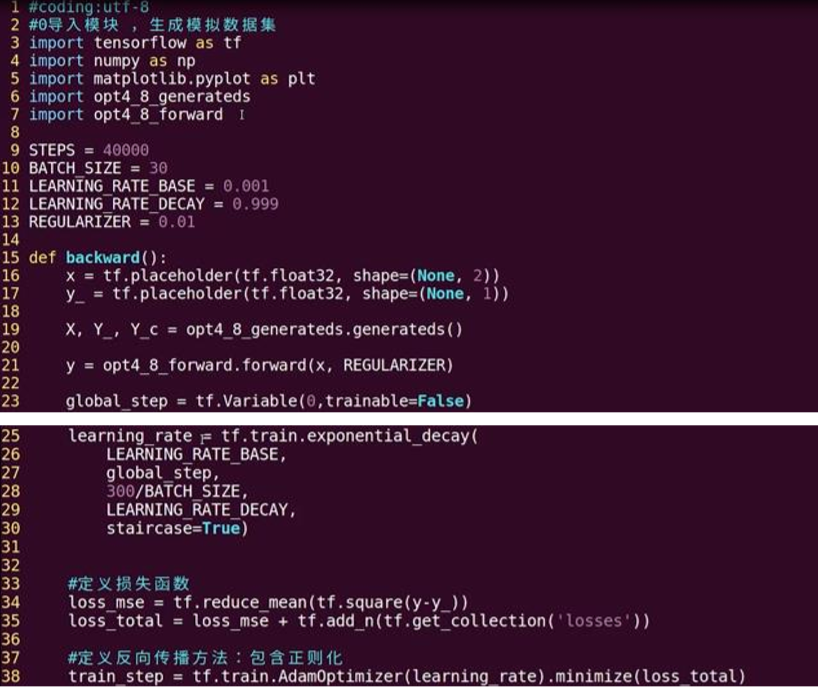
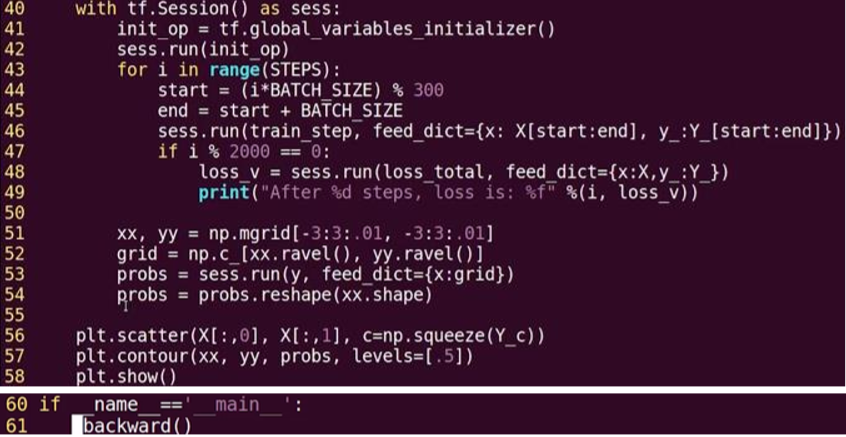
结果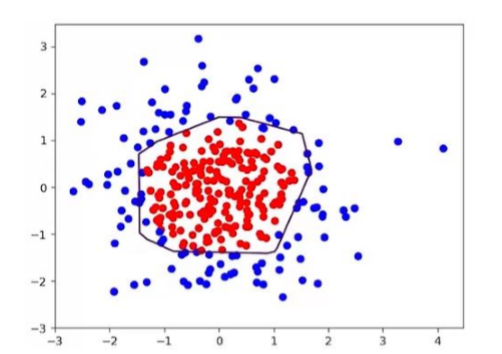
补充
tf.add( )函数表示将参数列表中对应元素相加
tf.cast(x,dtype)函数表示将参数 x 转换为指定数据类型
tf.equal( )函数表示对比两个矩阵或者向量的元素
tf.reduce_mean(x,axis)函数表示求取矩阵或张量指定维度的平均值
tf.argmax(x,axis)函数表示返回指定维度 axis 下,参数 x 中最大值索引号
tf.Graph( ).as_default( )函数表示将当前图设置成为默认图,并返回一
个上下文管理器。 该函数一般与 with 关键字搭配使用,应用于将已经定义好
的神经网络在计算图中复现
神经网络模型的保存
saver = tf.train.Saver()with tf.Session() as sess:for i in range(STEPS):if i % 轮数 == 0:saver.save(sess, os.path.join(MODEL_SAVE_PATH,MODEL_NAME), global_step=global_step)
神经网络模型的加载
with tf.Session() as sess:ckpt = tf.train.get_checkpoint_state(存储路径)if ckpt and ckpt.model_checkpoint_path:saver.restore(sess, ckpt.model_checkpoint_path)
加载模型中参数的滑动平均值
在保存模型时,若模型中采用滑动平均,则参数的滑动平均值会保存在相应文件中。
ema = tf.train.ExponentialMovingAverage(滑动平均基数)
emarestore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore)
神经网络模型准确率评估方法
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
断点续训
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)

若有收获,就点个赞吧
0 人点赞
