本文会对List的各种实现基于使用场景,时间复杂度、代码细节、注意事项等维度做分析。
Iterator 和 ListIterator
Iterator 仅仅定义了三个方法 hasNext() next() remove()
ListIterator 继承自Iterator 并新增了 hasPrevious() previous() nextIndex() previousIndex() set(E e) add(E e) 方法
这意味着List的有序性赋予了ListIterator双向遍历的能力,同时因为有序支持索引那么对索引处元素的操作也成为了可能。
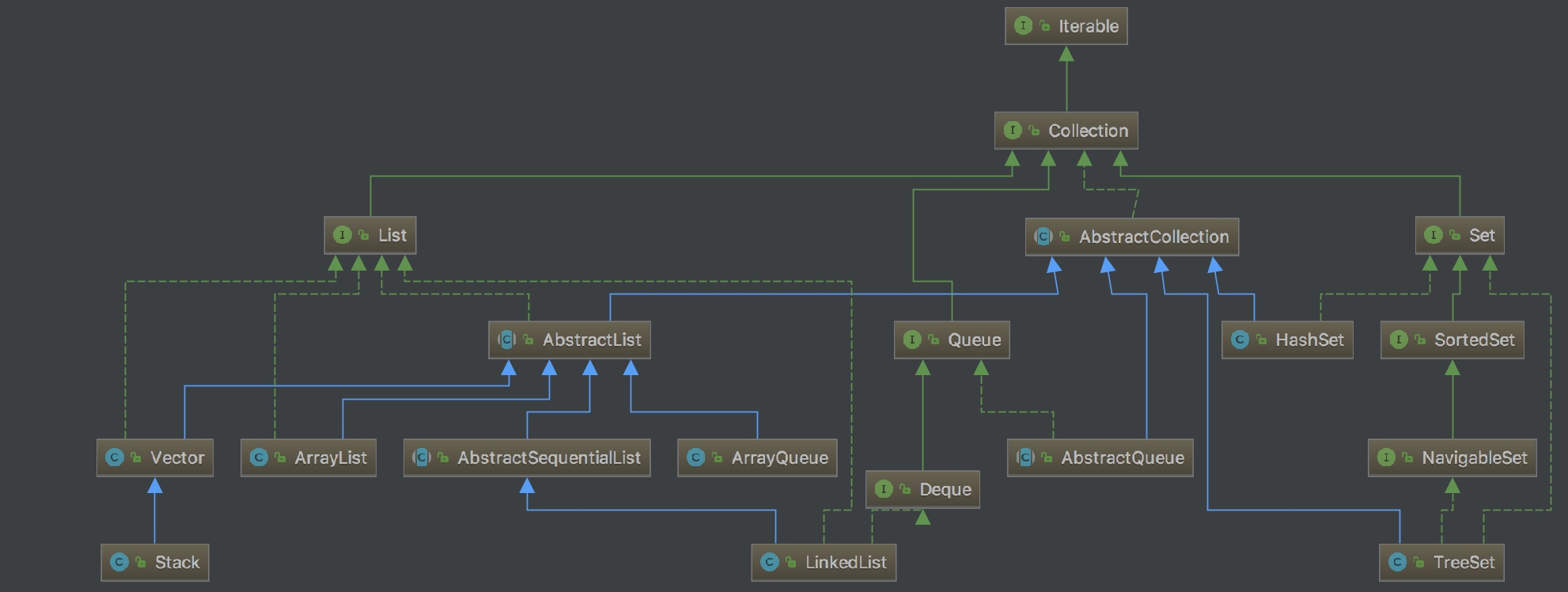
AbstractList
AbstractList 给List实现类提供了一个基本骨架。jdk里的List实现类都是通过继承它来实现的。
- 所有List的实现类按照Collection规范都应该提供一个参数为Collection的构造方法,即:
public XXXList(Collection c); - 如果需要实现一个不可修改的List,只需要继承它并且实现 get(int) 和 size() 方法即可。
- 如果需要实现一个可以修改的List,则需要重写 set(int, Object) set(int, E)方法,这里的可以修改和不可修改仅仅是指List某个index的元素的值是否可以修改。
- 如果需要一个可变长度的list则需要额外重写 add(int, Object) add(int, E) 以及 remove(int) 方法。
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {...abstract public E get(int index);public E set(int index, E element) {throw new UnsupportedOperationException();}public void add(int index, E element) {throw new UnsupportedOperationException();}public E remove(int index) {throw new UnsupportedOperationException();}...}
通过源码可知,如果尝试对一个不可变的List做出修改操作将抛出UnsupportedOperationException
AbstractList并没有定义存储数据的结构,需要由继承类自己来定义,如ArrayList是用数组来存,LinkedList是用链表来存。
下面是一个简单的基于数组的不可变list的实现
import java.util.AbstractList;import java.util.Collection;public class UnmodifiableArrayList extends AbstractList {private Object[] arr;public UnmodifiableArrayList(Collection c){if(c!=null){arr = new Object[c.size()];int i = 0;for (Object o:c){arr[i]=o;i++;}}else{arr = new Object[0];}}@Overridepublic Object get(int index) {return arr[index];}@Overridepublic int size() {return arr.length;}}
AbstractList 对subList(int,int)方法也有一个基础的实现返回的是一个SubList,LinkedList就是沿用这个方法的。需要注意的ArrayList通过subList方法获取的SubList 和 AbstractList 中返回的不是同一类型 List.SubList 和 AbstractList.SubList 是两个不同的类,不要被类名误导了。
class SubList<E> extends AbstractList<E> {private final AbstractList<E> l;private final int offset;private int size;SubList(AbstractList<E> list, int fromIndex, int toIndex) {...//checkl = list;offset = fromIndex;size = toIndex - fromIndex;this.modCount = l.modCount;}public E set(int index, E element) {...}public E get(int index) {...}public int size() {...}public void add(int index, E element) {rangeCheckForAdd(index);checkForComodification();l.add(index+offset, element);//看这里 index+offsetthis.modCount = l.modCount;size++;}public E remove(int index) {...}...}
可以看出通过subList方法返回的SubList对象仅仅是原来List的一个视图,也就是说如果原List是只读List那么这个SubList也是只读的,如果原List可修改,那么对SubList中元素的修改会直接作用于原List。
ArrayList
ArrayList 是 AbstractList 基于数组的实现,数组可以通过动态扩容来满足元素个数的持续增长。但是就是因为这个扩容的过程,原本时间复杂度为O(1)的add操作,经过扩容过程均摊后时间复杂度变为了O(n)。
后面我们会具体分析下扩容的过程。
首先我们关注ArrayList的几个基本属性
//默认的容量,如果构造方法中没有传入第一次扩容时数组将会变为这个长度private static final int DEFAULT_CAPACITY = 10;//通过 new ArrayList() 创建时,初始化大小为0 而 elementData指向的就是EMPTY_ELEMENTDATAprivate static final Object[] EMPTY_ELEMENTDATA = {};//用于存放数据的数组private transient Object[] elementData;//ArrayList包含元素的个数,区别于 elementData.lengthprivate int size;
接下来我们来对比下三个构造方法
//带初始化容量的构造方法 数组初始化大小为 initialCapacitypublic ArrayList(int initialCapacity) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];}//不带初始容量的构造方法 数组初始化大小为 0public ArrayList() {super();this.elementData = EMPTY_ELEMENTDATA;}//传入集合的构造方法 数组初始化大小为 c.size()public ArrayList(Collection<? extends E> c) {elementData = c.toArray();size = elementData.length;if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);}
ArrayList容量伸缩
当arraylist中的数组被放满,不足以放入下一个元素的时候,arraylist会进行扩容操作,扩容的过程很简单,就是创建一个更大的数组,然后通过数组拷贝将原来的数据拷贝到新的数组中。具体的扩容方法如下
private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
可以看出 newCapacity = oldCapacity + (oldCapacity >> 1);
值得注意的细节是如果arraycopy的原数组和目标数组是同一个的话,应该将无用的坑位置空,help gc,这一点remove方法就做得很好
public E remove(int index) {rangeCheck(index);modCount++;E oldValue = elementData(index);int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its workreturn oldValue;}
ArrayList 的add 和remove 操作的时间复杂度均为O(n) 而 get 和 set 方法时间复杂度均为 O(1)
LinkedList
LinkedList是List和Deque的链表实现方式,add操作的复杂度为O(1) remove(i) get(int)和set(int)操作的复杂度为O(n)
但是LinkedList对寻找第i个Node的方法做了一个小优化
Node<E> node(int index) {if (index < (size >> 1)) {//如果index位置位于链表的前一半则从表头开始遍历Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {//如果index位置位于链表的后一半则从表尾开始遍历Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
之所以能够这样做是因为记录了头部和尾部两个位置的引用,可能有人会想如果每个node都index都被记录下那时间复杂度岂不是成O(1)了?其实如果每个Node位置都记录那就跟ArrayList没啥区别了
Vector
Vector跟ArrayList相同都是基于数组实现的,一般操作的实现方式也大致相同,下面主要讲下两者间的区别
- 扩容方式 Vector 可以设置每次容量满时容量增加多少,如果没有设置则按现有容量双倍扩容
int newCapacity = oldCapacity + ((capacityIncrement > 0) capacityIncrement :oldCapacity);
- 添加修改的方法均用synchronized修饰
- 提供更多的方法如copyInto(…) trimToSize() 等
Vertor中的每个操作元素的方法都是线程安全的,但并不代表使用过程中不会出现线程安全问题。举个例子:
if(!vector.contains(o)){vector.add(o);}
这里如果是多个线程来操作仍然可能存在vector中出现重复元素的可能,正确的做法是对这段代码加锁
总结
在List的使用过程中,我们要对读和写操作做一个考量,选择合理的数据结构。如果读操作比较频繁可以考虑使用ArrayList,因为ArrayList的get方法时间复杂度是常量级别,如果删除操作和写操作比较频繁,可以考虑使用LinkedList,因为对链表的插入删除操作远比数组拷贝效率高。
在使用ArrayList的时,我们需要对List的容量有一个比较好的评估,用来设置List的初始化大小,减少扩容带来的不必要开销。
此外在操作一个List的时候我们要确定这个List是不是只读的,这个List是不是视图List,避免程序出错。
需要线程安全的List,可以使用Vector,也可以通过Collections.synchronizedList(List list)获得,但是需要注意多个同步方法组合使用的情况。

若有收获,就点个赞吧
0 人点赞
