1. 绪论
1.1 前言
在计算机科学里,树的遍历是指通过一种方法按照一定的顺序访问一棵树的过程。
对于二叉树,树的遍历通常有四种:先序遍历、中序遍历、后序遍历、广度优先遍历(Breadth FiRST Search)(层序遍历)。(前三种亦统称为深度优先遍历(Depth First Search))
对于多叉树,树的遍历通常有两种:深度优先遍历、广度优先遍历。因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历容易理解而且代码简洁。
而对于树的遍历若采用非递归的方法,就是采用栈去模拟实现。在三种遍历中,前序和中序的非递归算法都容易实现,非递归后续遍历实现起来相对来说要难一点。
总之:其实对于二叉树的遍历,有三种方式:一是DFS(又可根据访问位置不同分为前中和后);二是分治(其实就是DFS的后续遍历);三是层级遍历(BFS)。对于前两种都是递归的方式,当然你也可以用非递归实现。
本章节最重要的是分治:对于二叉树的题目,80-90%都可以用分治解决。因此遇到二叉树的题目,先想分治,然后再想traversal(遍历)
但是推荐分治,80-90%的二叉树问题都可以用分治解决,但遍历未必通用!!!!!
1.2 二叉树的遍历框架
void traverse(TreeNode root) {// 前序遍历traverse(root.left);// 中序遍历tarverse(root.right);// 后续遍历}
递归解法应该是最简单,最容易理解的才对,行云流水地写递归代码是学好算法的基本功,而二叉树相关的题目就是最练习递归基本功,最练习框架思维的。
1.3 二叉树的重要性
举个例子,比如说我们的经典算法「快速排序」和「归并排序」,对于这两个算法,你有什么理解?如果你告诉我,快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后续遍历,那么我就知道你是个算法高手了。
为什么快速排序和归并排序能和二叉树扯上关系?我们来简单分析一下他们的算法思想和代码框架:
快速排序的逻辑是:若要对nums[lo..hi]进行排序,我们先找一个分界点p,通过交换元素使得nums[lo..p-1]都小于等于nums[p],且nums[p+1..hi]都大于nums[p],然后递归地去nums[lo..p-1]和nums[p+1..hi]中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
void sort(int[] nums, int lo, int hi) {/****** 前序遍历位置 ******/// 通过交换元素构建分界点 pint p = partition(nums, lo, hi);/************************/sort(nums, lo, p - 1);sort(nums, p + 1, hi);}
先构造分界点,然后去左右子数组构造分界点,你看这不就是一个二叉树的前序遍历吗?
再说说归并排序的逻辑:若要对nums[lo..hi]进行排序,我们先对nums[lo..mid]排序,再对nums[mid+1..hi]排序,最后把这两个有序的子数组合并,整个数组就排好序了。
归并排序的代码框架如下:
void sort(int[] nums, int lo, int hi) {int mid = (lo + hi) / 2;sort(nums, lo, mid);sort(nums, mid + 1, hi);/****** 后序遍历位置 ******/// 合并两个排好序的子数组merge(nums, lo, mid, hi);/************************/}
先对左右子数组排序,然后合并(类似合并有序链表的逻辑),你看这是不是二叉树的后序遍历框架?另外,这不就是传说中的分治算法嘛,不过如此呀。
如果你一眼就识破这些排序算法的底细,还需要背这些算法代码吗?这不是手到擒来,从框架慢慢扩展就能写出算法了。
说了这么多,旨在说明,二叉树的算法思想的运用广泛,甚至可以说,只要涉及递归,都可以抽象成二叉树的问题。
1.4 写递归算法的秘籍
写递归算法的关键是要明确函数的「定义」是什么,然后相信这个定义,利用这个定义推导最终结果,绝不要试图跳入递归。
怎么理解呢,我们用一个具体的例子来说,比如说让你计算一棵二叉树共有几个节点:
// 定义:count(root) 返回以 root 为根的树有多少节点
int count(TreeNode root) {
// base case
if (root == null) return 0;
// 自己加上子树的节点数就是整棵树的节点数
return 1 + count(root.left) + count(root.right);
}
这个问题非常简单,大家应该都会写这段代码,root本身就是一个节点,加上左右子树的节点数就是以root为根的树的节点总数。
左右子树的节点数怎么算?其实就是计算根为root.left和root.right两棵树的节点数呗,按照定义,递归调用count函数即可算出来。
写树相关的算法,简单说就是,先搞清楚当前**root**节点该做什么,然后根据函数定义递归调用子节点,递归调用会让孩子节点做相同的事情。
我们接下来看几道算法题目实操一下。
1.5 二叉树的递归、非递归遍历
1.5.1 前序遍历
/*
* 在计算机科学里,树的遍历是指通过一种方法按照一定的顺序访问一颗树的过程。
* 对于二叉树,树的遍历通常有四种:先序遍历、中序遍历、后序遍历、广度优先遍历(Breadth Frist Search)(层次遍历)。
* (前三种亦统称深度优先遍历(Depth First Search))对于多叉树,树的遍历通常有两种:深度优先遍历、广度优先遍历。
* 因为树的定义本身就是递归定义,因此采用递归的方法去实现树的三种遍历不仅容易理解而且代码很简洁。而对于树的遍历若采用非递归的方法,就要采用栈去模拟实现。
* 在三种遍历中,前序和中序遍历的非递归算法都很容易实现,非递归后序遍历实现起来相对来说要难一点。
* */
/*
* 前序遍历
* */
/*
* 根据前序遍历访问的顺序,优先访问根结点,然后再分别访问左孩子和右孩子。即对于任一结点,其可看做是根结点,因此可以直接访问,访问完之后,若其左孩子不为空,按相同规则访问它的左子树;当访问其左子树时,再访问它的右子树。因此其处理过程如下:
* 对于任一结点P:
* 1)访问结点P,并将结点P入栈;
* 2)判断结点P的左孩子是否为空,若为空,则取栈顶结点并进行出栈操作,并将栈顶结点的右孩子置为当前的结点P,循环至1);若不为空,则将P的左孩子置为当前的结点P;
* 3)直到P为NULL并且栈为空,则遍历结束。
* */
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
public class 二叉树前序遍历_递归_非递归
{
void preOrderWithRecoursion(TreeNode root) {
if (root == null) {
return;
}
System.out.println(root.val);
preOrderWithRecoursion(root.left);
preOrderWithRecoursion(root.right);
}
List<Integer> preOrderWithoutRecoursion(TreeNode root) {
Stack<TreeNode> stack = new Stack<TreeNode>();
List<Integer> list = new ArrayList<Integer>();
TreeNode p = root;
while (p != null || !stack.empty()) {
list.add(p.val);
stack.push(p);
p = p.left;
}
// 到这一步的话,p一定是null,而栈一定有数据,即!null
if (!stack.empty()) {
TreeNode pop = stack.pop();
p = p.right;
}
return list;
}
}
1.5.2 中序遍历
*
*
* 中序遍历按照“左孩子-根结点-右孩子”的顺序进行访问。
*
* 根据中序遍历的顺序,对于任一结点,优先访问其左孩子,而左孩子结点又可以看做一根结点,然后继续访问其左孩子结点,直到遇到左孩子结点为空的结点才进行访问,然后按相同的规则访问其右子树。因此其处理过程如下:
* 对于任一结点P,
* 1)若其左孩子不为空,则将P入栈并将P的左孩子置为当前的P,然后对当前结点P再进行相同的处理;
* 2)若其左孩子为空,则取栈顶元素并进行出栈操作,访问该栈顶结点,然后将当前的P置为栈顶结点的右孩子;
* 3)直到P为NULL并且栈为空则遍历结束
* */
public class 二叉树中序遍历_递归_非递归
{
List<Integer> InOrderReverseWithoutRecoursion(TreeNode root) {
Stack<TreeNode> stack = new Stack<TreeNode>();
List<Integer> preOrder = new ArrayList<Integer>();
TreeNode p = root;
// 这里p != null就是为了保证,对于该节点开始不停的往左下角走。我觉得该条件可以省略
// !stack.empty()是为了从栈中pop出
while (p != null || !stack.empty()) { // 只要是栈或者节点不为null,就说明还没有处理完。
// 一直遍历到左子树最下边,边遍历边保存根节点到栈中
while (p != null) {
stack.push(p);
p = p.left;
}
// 当p为空时,说明已经到达左子树最下边,这时需要我们出栈了,其实就是回退
if (!stack.empty()) {
TreeNode pop = stack.pop();
preOrder.add(pop.val);
//进入右子树,开始新的一轮左子树遍历(这是递归的自我实现)
p = pop.right;
}
}
return preOrder;
}
void InOrderReverseWithoutRecoursion_演示版(TreeNode root) {
Stack<TreeNode> stack = new Stack<TreeNode>();
List<Integer> preOrder = new ArrayList<Integer>();
while (root != null) {
stack.push(root);
root = root.left;
}
TreeNode pop = stack.pop();
preOrder.add(pop.val);
pop = stack.pop();
preOrder.add(pop.val);
pop = stack.pop();
preOrder.add(pop.val);
preOrder.add(pop.right.val);
pop = stack.pop();
preOrder.add(pop.val);
// 此时栈已空,到达了右子树,再操作一次
root = root.right;
while (root != null) { // 放进去3和6
stack.push(root);
root = root.left;
}
pop = stack.pop();
preOrder.add(pop.val); // 出来6
pop = stack.pop();
preOrder.add(pop.val); // 出来3
preOrder.add(pop.right.val);
}
}
1.5.3 后序遍历
思维导图
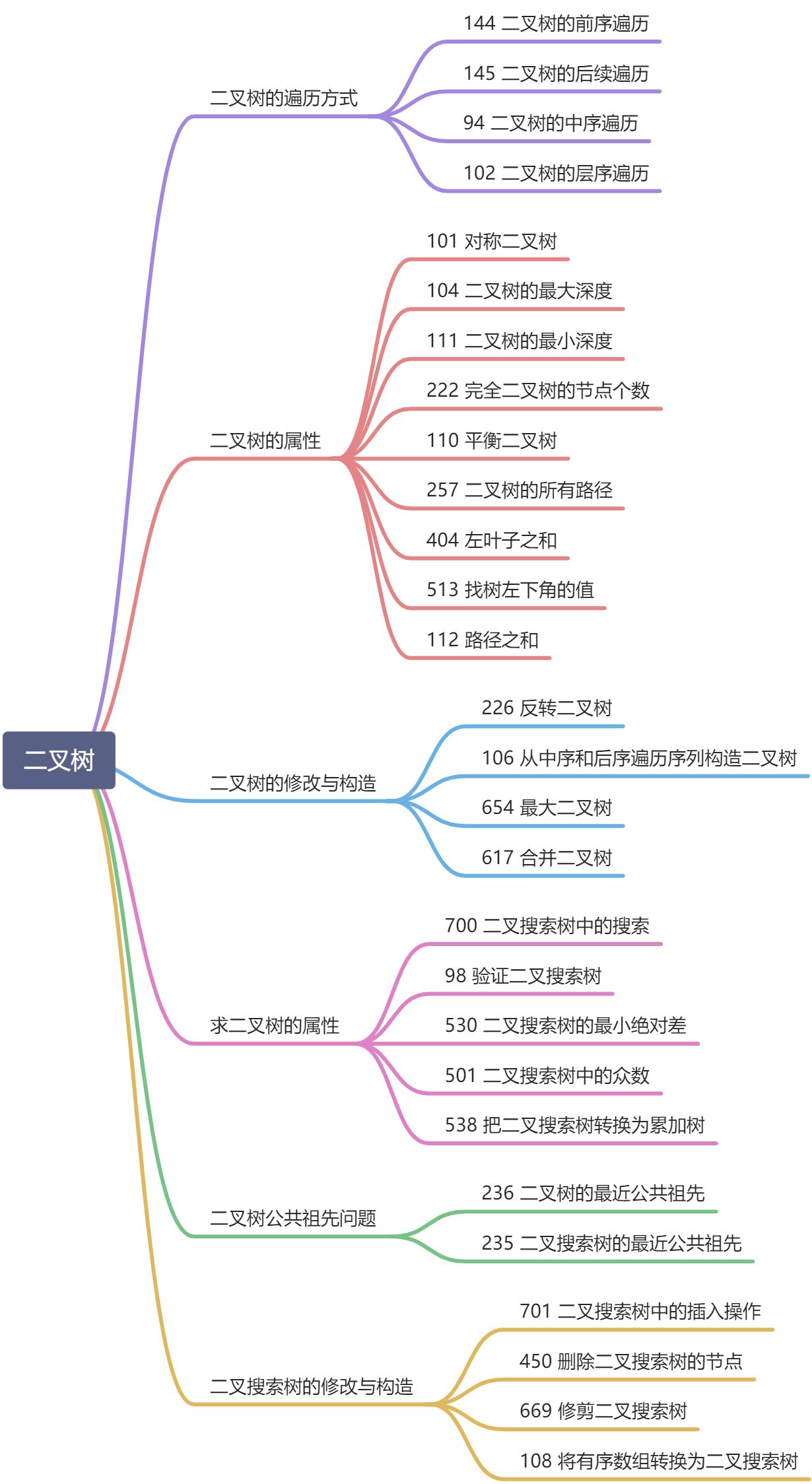
2. 刷题宝典
2.1 二叉树
2.1.1 刷题第一站 traverse
对于traverse不要想那么多,要不要上递归上靠,如果你想靠,可以看看本文小结。当然这个说的是递归
144. 二叉树的前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<Integer>();
if (root != null) {
Stack<TreeNode> stack = new Stack<TreeNode>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode head = stack.pop();
list.add(head.val);
if (head.right != null) {
stack.push(head.right);
}
if (head.left != null) {
stack.push(head.left);
}
}
}
return list;
}
}
LeetCode 94 二叉树中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<Integer>();
if (root != null) {
Stack<TreeNode> stack = new Stack<TreeNode>();
while (!stack.isEmpty() || root != null) {
if (root != null) {
stack.push(root);
root = root.left;
} else {
root= stack.pop();
list.add(root.val);
root = root.right;
}
}
}
return list;
}
}
145. 二叉树的后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> list = new ArrayList<Integer>();
if (root != null) {
Stack<TreeNode> s1 = new Stack<TreeNode>();
Stack<TreeNode> s2 = new Stack<TreeNode>();
s1.push(root);
while (!s1.isEmpty()) {
root = s1.pop();
s2.push(root);
if (root.left != null) {
s1.push(root.left);
}
if (root.right != null) {
s1.push(root.right);
}
}
while (!s2.isEmpty()) {
list.add(s2.pop().val);
}
}
return list;
}
}
2.1.1 刷题第一站 分治算法 (N题)
注意:分治可以解决解决二叉树80%-90%的题目。因此见到二叉树脑子就别乱想,就想分治。当然遍历也可以解决一定的题目,不要忘了(其实分治也算是遍历中的一种,准确说是BFS中的后序遍历)。
分治算法模板
public Object method(TreeNode root) {
// base case
// 两个小问题用一个黑匣子解决,并有了结果
obj1 = method(left);
obj2 = method(right);
// 后续遍历位置(分治其实就是DFS中的后序遍历)
return 0bj1 ... 0bj2; // 这一行锁写的代码是整棵树和上面两个结果的联系。
}
做题步骤:
1.思考这棵树为空怎么办?这个其实就是base case。为什么又这一步,了解递归的都知道要写base case。但是这只是表面,我想说的是,为什么要写base case。因为我们这个方法是递归,即对该树的任意节点,这个方法都应该是适用的。因此要考虑这种树为空的情况。其实我想base case应该不止这一点。
2.思考树非空时,该怎么解决,怎么将大问题和小问题联系上。
LeetCode 173
LeetCode 104 二叉树的最大深度
class Solution {
public int maxDepth(TreeNode root) {
// 如果这是一棵空树
if (root == null) {
return 0;
}
// 这棵树不是空树
// 小问题是,我们可以解决一棵树的最大深度(树可为null)
// 大问题和小问题的联系
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}
上面这个解法并不是完全的分值算法写法。我写个完整的分治吧!
class Solution {
public int maxDepth(TreeNode root) {
// 如果这是一棵空树
if (root == null) {
return 0;
}
// 两个小问题用一个黑匣子解决,并有了结果。
int left = maxDepth(root.left);
int right = maxDepth(root.right);
// 大问题和小问题的联系
return Math.max(left, right) + 1;
}
}
Leetcode 111 二叉树的最小深度
// 和上一题一样
class Solution {
public int minDepth(TreeNode root) {
if (root == null) {
return 0;
}
// 大问题和小问题的联系
// 此时,树已非空。该树的最小深度 = 左右子树的最小深度 + 1(根节点)
return 1 + Math.min(minDepth(root.left), minDepth(root.right));
}
}
但是这个解法竟然没有通过,错误实例:[2,null,3,null,4,null,5,null,6],该方法返回1,而实际是5.
为何出现这种情况呢?大问题和小问题的联系:该树的最小深度 = 左右子树的最小深度 + 1(根节点)。当在一棵树为空时,不成立。
/**
* 修正大问题和小问题的关系
* 当左子树为空,则返回1 + minDepth(root.right); 当右子树为空,返回1 + minDepth(root.left);
* 当都不为空时:return 1 + Math.min(minDepth(root.left), minDepth(root.right));
*/
class Solution {
public int minDepth(TreeNode root) {
if (root == null) {
return 0;
}
if (root.left == null) {
return 1 + minDepth(root.right);
}
if (root.right == null) {
return 1 + minDepth(root.left);
}
return 1 + Math.min(minDepth(root.left), minDepth(root.right));
}
}
LeetCode 559 N叉树的最大深度(有一点疑问)
尔等大佬合并惊慌,N叉树的最大深度不是和二叉树一模一样吗?
base case: root == null return 0;
大小问题联系:
二叉树:1 + Math.max(maxDepth(root.left), maxDepth(root.right));
N叉树:1 + 变脸N分支得到最大值
class Solution {
public int maxDepth(Node root) {
if (root == null) return 0;
int max = 0;
for (Node child : root.children)
{
max = Math.max(maxDepth(child), max);
}
return 1 + max;
}
}
暂时略:这道题我有一个很大的疑问,时间太紧,暂时不解决。就是int max = 0;我让max赋值为-1,或-2
或Interger.MIN_VAL都不行。
LeetCode 110 平衡二叉树
平衡二叉树定义:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
大小问题之间的联系:左子树是不是平衡树,右子树是不是平衡树;整棵树是不是平衡树。
假设两个小问题都返回true,此时要想判断整棵树都是平衡树,还是需要知道左右子树的高度差。
因此,这道题对于小问题的返回值定义就有如下要求,如果是平衡二叉树,则返回最大高度;如果不是,则返回-1.
这样大问题和小问题之间的联系就更容易了:
class Solution {
public boolean isBalanced(TreeNode root) {
return helper(root) != -1;
}
int helper(TreeNode root) {
// 如果是空树
if (root == null) {
return 0;
}
// 如果不是空树
// 此时,如果左右子树任意一个返回值是-1,则返回-1(整棵树不是平衡树)
// 如果都不是-1,则看两个高度差判断返回-1,还是其他
int left = helper(root.left);
int right = helper(root.right);
if (left == -1 || right == -1 || Math.abs(left - right) > 1) {
return -1;
}
return Math.max(left, right) + 1;
}
}
222. 完全二叉树的节点个数
class Solution {
public int countNodes(TreeNode root) {
if (root == null) return 0;
int leftLevel = calculateLevel(root);
int rightLevel = calculateLevel(root.right);
if (leftLevel - 1 == rightLevel) {
return 1 + (1 << rightLevel) - 1 + countNodes(root.right);
} else {
return 1 + (1 << rightLevel) - 1 + countNodes(root.left);
}
}
private int calculateLevel(TreeNode root) {
int level = 0;
while (root != null) {
level++;
root = root.left;
}
return level;
}
}
513. 找树左下角的值
求树的最后一行找到最左边的值 = 求 左右子树深度最大的数 的最后一行找到最左边的值
class Solution {
public int findBottomLeftValue(TreeNode root) {
if (root.left == null && root.right == null) {
return root.val;
}
root = maxDepth(root.left) >= maxDepth(root.right) ? root.left : root.right;
return findBottomLeftValue(root);
}
private int maxDepth(TreeNode root) {
if (root == null) return 0;
return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));
}
}
趁热打铁
上面学了分治法,现在趁热打铁把两个和分治相关的排序算法讲解一下
归并排序 Merge Sorted Array 左边排序,右边排序,左右两边合并 === 归并排序需要额外的空间用于合并(要倒腾出来,再倒腾回去)。归并排序的本质就是后续排列!即分治!
快速排序 ==任取一个数target,将数组分成两部分,左边的<= target, 右边的 > target。然后左右两边再quick sort。复杂的在最坏的情况下是o(n2) 平均复杂度O(nlgn)。快排的本质是前序排列。
整体来说快拍优于归并排序,因为归并排序,需要额外的空间,然后将两个排序数组倒腾进去,然后再倒腾回去。。工程上常用快排
但是归并排序有个很好的地方,就是,其是稳定排序,而快拍不稳定
归并和快排
总结
上面对于深搜,你还要考虑用D-C还是用遍历,当然80-90%是D-C。
LeetCode 112 路径之和
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null) return false;
return hasPathSumHelper(root, targetSum);
}
public boolean hasPathSumHelper(TreeNode root, int targetSum) {
if (root == null) {
return targetSum == 0;
}
boolean left = hasPathSumHelper(root.left, targetSum - root.val);
boolean right = hasPathSumHelper(root.right, targetSum - root.val);
return left || right;
}
}
这个代码非常简单,但是上面这个代码过不了这个例子[1,2]。
该怎么纠正呢?将递归出口修改为:如果是空节点怎么办?如果是叶子节点有如何?
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
if (root == null) return false;
return hasPathSumHelper(root, targetSum);
}
public boolean hasPathSumHelper(TreeNode root, int targetSum) {
if (root == null) {
return false;
}
if (root.left == null && root.right == null) {
return targetSum == root.val;
}
boolean left = hasPathSumHelper(root.left, targetSum - root.val);
boolean right = hasPathSumHelper(root.right, targetSum - root.val);
return left || right;
}
}
LeetCode 113 路径之和 II
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
List<List<Integer>> result= new ArrayList<>();
List<Integer> list = new ArrayList<>();
pathSumHelper(root, targetSum, result, list);
return result;
}
// 此时该函数定义为:获得非空树的路径和为sum的路径
void pathSumHelper(TreeNode root, int targetSum, List<List<Integer>> result, List<Integer> list) {
if (root == null) {
return;
}
if (root.left == null && root.right == null) { // 如果是叶子节点
if (root.val == targetSum) {
list.add(root.val);
result.add(new ArrayList<Integer>(list));
list.remove(list.size() - 1);
}
return;
}
list.add(root.val);
pathSumHelper(root.left, targetSum - root.val, result, list);
list.remove(list.size() - 1);
list.add(root.val);
pathSumHelper(root.right, targetSum - root.val, result, list);
list.remove(list.size() - 1);
}
}
这道题我们好好思考一下,如下情况:
情况一:少些从左子树结束后的remove和add
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
List<List<Integer>> result= new ArrayList<>();
List<Integer> list = new ArrayList<>();
pathSumHelper(root, targetSum, result, list);
return result;
}
// 此时该函数定义为:获得非空树的路径和为sum的路径
void pathSumHelper(TreeNode root, int targetSum, List<List<Integer>> result, List<Integer> list) {
if (root == null) {
return;
}
if (root.left == null && root.right == null) { // 如果是叶子节点
if (root.val == targetSum) {
list.add(root.val);
result.add(new ArrayList<Integer>(list));
list.remove(list.size() - 1);
}
return;
}
list.add(root.val);
pathSumHelper(root.left, targetSum - root.val, result, list);
/*list.remove(list.size() - 1); 少些这两行,是否可行呢?答案是可行,自行体会
list.add(root.val);*/
pathSumHelper(root.right, targetSum - root.val, result, list);
list.remove(list.size() - 1);
}
}
情况二:递归出口不写null这种情况
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
List<List<Integer>> result= new ArrayList<>();
List<Integer> list = new ArrayList<>();
pathSumHelper(root, targetSum, result, list);
return result;
}
// 此时该函数定义为:获得非空树的路径和为sum的路径
void pathSumHelper(TreeNode root, int targetSum, List<List<Integer>> result, List<Integer> list) {
/*if (root == null) {
return;
}*/
if (root.left == null && root.right == null) { // 如果是叶子节点
if (root.val == targetSum) {
list.add(root.val);
result.add(new ArrayList<Integer>(list));
list.remove(list.size() - 1);
}
return;
}
list.add(root.val);
pathSumHelper(root.left, targetSum - root.val, result, list);
pathSumHelper(root.right, targetSum - root.val, result, list);
list.remove(list.size() - 1);
}
}
这种情况下,会报空指针异常,如[5,4,2,null,null,2],为什么,比如我们此刻来到了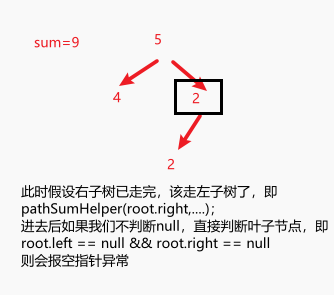
情况三:递归出口不写叶子节点,而是直接用null这个条件return(并且此时添加list到result),即
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
List<List<Integer>> result= new ArrayList<>();
List<Integer> list = new ArrayList<>();
pathSumHelper(root, targetSum, result, list);
return result;
}
// 此时该函数定义为:获得非空树的路径和为sum的路径
void pathSumHelper(TreeNode root, int targetSum, List<List<Integer>> result, List<Integer> list) {
if (root == null) {
if (targetSum == 0) {
result.add(new ArrayList<Integer>(list));
}
return;
}
list.add(root.val);
pathSumHelper(root.left, targetSum - root.val, result, list);
pathSumHelper(root.right, targetSum - root.val, result, list);
list.remove(list.size() - 1);
}
}
这个错误是会出现重复数据,比如树[5],sum=5,则返回结果中会有[[5],[5]];[5,4,8,11,null,13,4,7,2,null,null,5,1]输出结果是:[[5,4,11,2],[5,4,11,2],[5,8,4,5],[5,8,4,5]]。这是因为当为null时,任何叶子节点的左右子树都是null,则会重复两次。
LeetCode 235 二叉搜索树的最近公共祖先
小问题:寻找以root为根的可空树上p与q的公共祖先,如果没有,则返回null。
联系:如果左子树不为空,则返回左子树结果,如果右子树不为空,则返回右子树结果。否则,此时不能直接返回root,要看root是否能遍历到这两个节点,如果可以则返回root,否则,还是返回null。
这道题我做的想必一不是最优解法,看以后机缘再修订了。
此外,这道题目打着二叉搜索树的牌子,我想应该有用到二叉搜索树的性质吧,我这个解法显然没有。
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) {
/*if (p == q && q == null) {
return null;
}*/
return null;
}
if (root.left == null && root.right == null) {
if (root == p && q == p) {
return root;
} else {
return null;
}
}
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if (left != null) return left;
if (right != null) return right;
if (findNode(root, p) && findNode(root, q)) {
return root;
}else {
return null;
}
}
boolean findNode(TreeNode root, TreeNode p) {
if (root == null) {
return p == null;
}
return findNode(root.left, p) || findNode(root.right, p) || root == p;
}
}
这道题还可以用二叉搜索树的性质解决!
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) {
return null;
}
if (root.val > p.val && root.val > q.val) {
return lowestCommonAncestor(root.left, p, q);
}
if (root.val < p.val && root.val < q.val) {
return lowestCommonAncestor(root.right, p, q);
}
return root;
/**
* 最后这个return是什么意思?包含什么?
if (root == p || root == q) {
return root;
}
如果p和q分别在左右子树上,则return root
*/
}
}
LeetCode 257 二叉树的所有路径
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
List<String> result = new ArrayList<>();
List<String> list = new ArrayList<>();
binaryTreePathsHelper(root, result, list);
return result;
}
void binaryTreePathsHelper(TreeNode root, List<String> result, List<String> list) {
if (root == null) {
return;
}
if (root.left == null && root.right == null) {
StringBuilder sb = new StringBuilder();
for (String s: list) {
sb.append(s).append("->");
}
result.add(sb.append(root.val).toString());
}
list.add(root.val+"");
binaryTreePathsHelper(root.left, result, list);
binaryTreePathsHelper(root.right, result, list);
list.remove(list.size() - 1);
}
}
我们思考,递归出口为什么要判断null,这是因为如果不判断,首先null这个特殊例子过不去;其次,结果中会出现重复,因为你叶子节点的左右null都走了一遍,因此要在遇到null的时候就要return
但是你先过没有,我们递归出口不设置null,即只让递归走到叶子节点就出来,这个可以吗?感觉很不错,是吧!答案是不可以的!!因为会出现空指针异常。比如树[2,3]
LeetCode 404 左子树之和
一棵树的左子树之和 = 左子树的左子树之和 + 右子树的左子树之和
但是前提是:左子树不为空,并且左子树不为叶子节点
1.左子树为空,则返回右子树的左子树之和
2.左子树不为空
如果左子树是叶子节点:返回root.left.val + 右子树左子树之和
如果左子树不是叶子节点:返回左子树的左子树之和 + 右子树的左子树之和
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) {
return 0;
}
int left = sumOfLeftLeaves(root.left);
int right = sumOfLeftLeaves(root.right);
if (root.left != null) {
if (root.left.left == null && root.left.right == null) {
return left + right + root.left.val;
} else {
return left + right;
}
} else {
return right;
}
}
}
上面这个做法自然可以通过,但是思路不清晰明了。下面这个解法是按照上面分析的情况进行的,大问题和小问题之间的联系一目了然。
class Solution {
public int sumOfLeftLeaves(TreeNode root) {
if (root == null) {
return 0;
}
int left = sumOfLeftLeaves(root.left);
int right = sumOfLeftLeaves(root.right);
if (root.left == null) {
return right;
} else {
if (root.left.left == null && root.left.right == null) {
return root.left.val + right;
} else {
return left + right;
}
}
}
}
LeetCode 563 二叉树的坡度
class Solution {
// 二叉树的坡度 = 左子树的坡度 + 右子树的坡度 + 左右子树的节点和之差
public int findTilt(TreeNode root) {
if (root == null) return 0;
return findTilt(root.left) + findTilt(root.right) + Math.abs(getSum(root.left) - getSum(root.right));
}
// 以root为首的树的节点和 = 左子树节点和 + 右子树节点和 + root.val
int getSum(TreeNode root) {
if (root == null) return 0;
return getSum(root.left) + getSum(root.right) + root.val;
}
}
2.1.3 刷题第三站 递归
这里的一些题目仍然可以归于分治,但是其实也没必要了。我们知道分治其实就是递归,甚至可以说是递归中思路最简单的一个。
对于递归:我们要讨论和所有情况,即大问题和小问题之间的联系。
base case:其实做多了,就知道base case不用特意想,将大问题和小问题的联系想清楚了,base case即自然出来了。一般而言,base case就是null和叶子结点这两种。
小问题:
大问题和小问题的联系:
LeetCode 572 另一个树的子树
class Solution {
// 树A是否包含树B = 树A的左子树是否包含树B || 树A的右子树是否包含树B || A是否和B完全一样
public boolean isSubtree(TreeNode s, TreeNode t) {
if (s == null) {
return t == null;
}
return isSubtree(s.left, t) || isSubtree(s.right, t) || isSame(s, t);
}
// 两棵树是否相同 = 两棵树的左子树是否相同 && 两棵树的右子树是否相同 && s.val == t.val
boolean isSame(TreeNode s, TreeNode t) {
if (s == null) {
return t == null;
}
if (t == null) {
return s == null;
}
return s.val == t.val && isSame(s.left, t.left) && isSame(s.right, t.right);
}
}
LeetCode 606 根据二叉树创建字符串
这道题关于大问题和小问题的联系:开始根本没有考虑完,是测试后慢慢补充的
class Solution {
// 我们姑且叫这道题为:给二叉树编码吧
// 二叉树编码 = root.val + (左子树编码) + (右子树编码)
// 思考base case;其实对于上面的公式大部分都能通过,但当右子树返回是()时,就要舍弃掉 + (右子树编码)
// 另一个基本的base case就是null 返回()
public String tree2str(TreeNode t) {
if (t == null) {
return "";
}
return tree2strHelper(t);
}
public String tree2strHelper(TreeNode t) {
if (t == null) {
return "()";
}
if (t.left == null && t.right == null) { // 这是测试后又加的条件
return t.val + "";
}
String left = tree2strHelper(t.left);
String right = tree2strHelper(t.right);
if (t.left == null) { // 这个也是测试后又加的条件
return t.val + "()" + "(" + right + ")";
}
if (right.equals("()")) {
return t.val + "(" + left + ")";
} else {
return t.val + "(" + left + ")" + "(" + right + ")";
}
}
}
2.1.2 刷题第二站 宽搜 (N题)
但是对于款搜,没有那些讨论,只要你把款搜背熟了,这些题套路都一样。 因此BFS实在是简单太多了,所有题都是一个做法 宽搜的辅助数据结构是好队列
二叉树层序遍历模板
二叉树层序遍历模板
public class Solution {
public ArrayList<ArrayList<Integer>> levelOrder(TreeNode root) {
ArrayList result = new ArrayList();
if (root == null)
return result;
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(root);
while (!queue.isEmpty()) {
ArrayList<Integer> level = new ArrayList<Integer>();
int size = queue.size(); // 这个size是该层所有节点的个数(都在队列中)
// 将这一层节点一一弹出,并记录,此外,将每个节点的子节点都放进去。
for (int i = 0; i < size; i++) {
TreeNode head = queue.poll();
level.add(head.val);
if (head.left != null)
queue.offer(head.left);
if (head.right != null)
queue.offer(head.right);
}
result.add(level); // 当一个循环完成,这一层节点的使命也就结束了。
}
// 整个循环结束,则所以层节点的使命都结束了!
return result;
}
}
LeetCode 102 二叉树的层序遍历
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
List<Integer> level = new ArrayList<>();
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode head = queue.poll();
level.add(head.val);
if (head.left != null) {
queue.offer(head.left);
}
if (head.right != null) {
queue.offer(head.right);
}
}
result.add(level);
}
return result;
}
}
LeetCode 107 二叉树的层序遍历 II
这道题没啥讲的
// 给定一个二叉树,返回其节点值自底向上的层序遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
class Solution {
public List<List<Integer>> levelOrderBottom(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
List<Integer> level = new ArrayList<>();
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode head = queue.poll();
level.add(head.val);
if (head.left != null) {
queue.offer(head.left);
}
if (head.right != null) {
queue.offer(head.right);
}
}
result.add(0, level);
}
return result;
}
}
LeetCode 103 二叉树的锯齿形层序遍历
这道题只是设置一个flag。在队列中放每层元素不变,但是对于取每层元素并放入到该层List中时,要判断flag。
然后flag再每层结束后反置。
class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<List<Integer>>();
if (root == null){
return result;
}
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(root);
boolean flag = true;
while (!queue.isEmpty()) {
List<Integer> level = new ArrayList<Integer>();
int size = queue.size();
for (int i = 0; i < size; i++)
{
TreeNode head = queue.poll();
if (flag) {
level.add(head.val);
} else {
level.add(0, head.val);
}
if (head.left != null) {
queue.add(head.left);
}
if (head.right != null) {
queue.add(head.right);
}
}
flag = !flag;
result.add(level);
}
return result;
}
}
LeetCode 637 二叉树的层平均数
class Solution {
public List<Double> averageOfLevels(TreeNode root) {
List<Double> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
Double sum = 0d;
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode head = queue.poll();
sum += head.val;
if (head.left != null) {
queue.offer(head.left);
}
if (head.right != null) {
queue.offer(head.right);
}
}
result.add(sum / size);
}
return result;
}
}
2.1.3 刷题第四站 两个节点
LeetCode 116
填充完美二叉树中每个节点的next指针,使其指向下一个右侧节点。如果找不到下一个右侧节点。则将next指针设置为null。结果如图: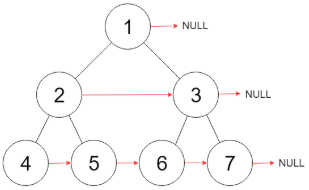
思路: 要想让每一层的节点穿起来,是不是只要把每个节点的左右子节点都穿起来即可。
Node connect(Node root) {
// base case
if (root == null || root.left == null) {
return root;
}
// 前序遍历位置
root.left.next = root.right;
// 左右子节点做同样的事情
connect(root.left);
conncet(root.right);
return root;
}
上面的代码并不能完成本题,其结果是:如图所示,该做法不能使根节点的左右两子树之间相互连接起来。至于原因嘛:当你遍历到任意一个节点时:你像让这个节点为首(1)的树每层节点连接起来。根据递归,你肯定是像借助子树已完成该操作,即(2)节点已完成,(3)节点也已完成。此时你又让节点(2)和(3)连接,这是一个关键地方,这个地方没有办法让两个本来孤立的树相连,因为无法到达。这里的解释并不好,见谅。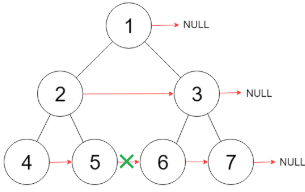
回想刚才说的,二叉树的问题难点在于,如何把题目的要求细化成每个节点需要做的事情,但是如果只依赖一个节点的话,肯定是没办法连接「跨父节点」的两个相邻节点的。
我们这里将该题化成每个节点做的事情是:每个节点的左右节点链接(前序遍历位置)。如果只依赖一个节点,显然无法满足题目。因为你通过任何节点,都无法将5链接6这种可能链接上。
那么,我们的做法就是增加函数参数,一个节点做不到,我们就给安排两个节点,[将每一层二叉树节点连接起来]可以细化成[将两个节点形成的二叉树的同层链接起来]
class Solution {
public Node connect(Node root) {
if (root == null || root.left == null) {
return root;
}
connectTwoNode(root.left, root.right);
return root;
}
//
private void connectTwoNode(Node left, Node right)
{
if(left == null) {
return;
}
connectTwoNode(left.left, left.right);
connectTwoNode(right.left, right.right);
// 后序遍历位置
// 让传入的两个节点为首的子树的左树右侧和右树左侧相连
while (left != null) {
left.next = right;
left = left.right;
right = right.left;
}
}
}
上面这个递归函数就是这个意思。下面我们只需要考虑两件事:base case;在已知2和3节点的树的同层已经相连情况下,如何让整棵树相连。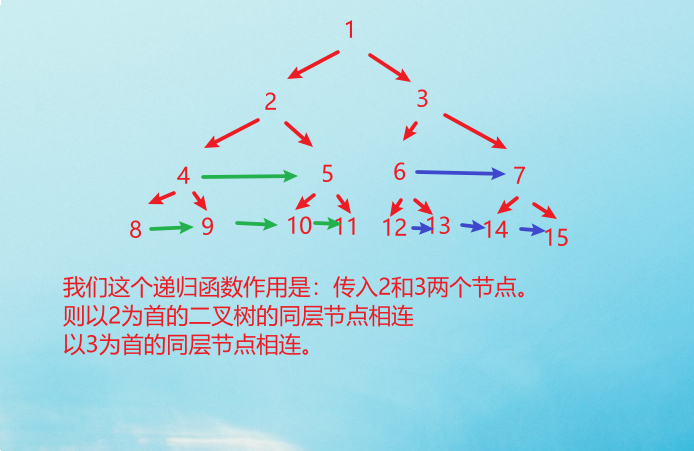
LeetCode 101 对称二叉树
这里的小问题是:判断两个以root为根的树是否是镜像,是则返回true,不是则false。
class Solution {
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return isSymmetricHelper(root.left, root.right);
}
boolean isSymmetricHelper(TreeNode t1, TreeNode t2) {
if (t1 == null && t2 == null) return true;
if (t1 == null || t2 == null) return false;
if (t1.val != t2.val) {
return false;
} else {
return isSymmetricHelper(t1.left, t2.right) && isSymmetricHelper(t1.right, t2.left);
}
}
}
LeetCode 617 合并二叉树
这道题适合在递归题都讲差不多后讲。
class Solution {
// 将两棵树合并
// 小问题:返回两棵树合并后的根节点
// 如果两棵树都非空:合并后,root.left = 两棵树左子树合并后的根节点 + 两棵树右子树合并后的根节点
// 最终返回合并后的结果
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
if (root1 == null) {
return root2;
}
if (root2 == null) {
return root1;
}
root1.val += root2.val;
root1.left = mergeTrees(root1.left, root2.left);
root1.right = mergeTrees(root1.right, root2.right);
return root1;
}
}
2.2 二叉搜索树
左子树的值都小于根节点;右子树的值都大于根节点;且左右子树都是二叉搜索树。当然空树也是二叉搜索树。
二叉搜索树(Binary Search Tree,后文简写 BST),其特征是:
1、对于 BST 的每一个节点node,左子树节点的值都比node的值要小,右子树节点的值都比node的值大。
2、对于 BST 的每一个节点node,它的左侧子树和右侧子树都是 BST。
二叉搜索树并不算复杂,但我觉得它构建起了数据结构领域的半壁江山,直接基于 BST 的数据结构有 AVL 树,红黑树等等,拥有了自平衡性质,可以提供 logN 级别的增删查改效率;还有 B+ 树,线段树等结构都是基于 BST 的思想来设计的。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)。
也就是说,如果输入一棵 BST,以下代码可以将 BST 中每个节点的值升序打印出来:
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
// 中序遍历代码位置
print(root.val);
traverse(root.right);
}
2.2.1 刷题第一站 分治 (N题)
虽然这里是二叉搜索树,但是这里的题目还是应该归属于”刷题第一站”分治算法。还记得分治算法思考的步骤吗?准确的说这应该是递归的思路。
1.base case:一般是这棵树是空怎么办?
**
LeetCode 98 验证二叉搜索树 分治
base case:当树是空时,是二叉搜索树。
小问题(黑匣子):判断以root(可以是空)为根的树是否是二叉搜索树,如果是,则返回false;否则返回true。
联系:如果树不为空:如果左子树不是搜索树,则返回false;如果右子树不是搜索树,则返回false;此时两个子树都是所搜树,如果根节点比左子树最大值小,则返回false;如果比右子树最小值大,则返回false,否则返回true。
class Solution {
public boolean isValidBST(TreeNode root) {
if (root == null || (root.left == null && root.right == null)) {
return true;
}
if (!isValidBST(root.left)) {
return false;
}
if (!isValidBST(root.right)) {
return false;
}
// 后序遍历位置
// 判断根节点是否比左子树的最大值大,比右子树的最小值小
TreeNode maxInLeftNode = root.left;
if (maxInLeftNode != null) {
while (maxInLeftNode.right != null) {
maxInLeftNode = maxInLeftNode.right;
}
}
if (root.left != null && root.val <= maxInLeftNode.val) {
return false;
}
TreeNode minInRightNode = root.right;
if (root.right != null) {
while (minInRightNode.left != null) {
minInRightNode = minInRightNode.left;
}
}
if (root.right != null && root.val >= minInRightNode.val) {
return false;
}
return true;
}
}
这个可是标准的分治(后序遍历哈),大家可是要能看出来的。只是后序遍历位置内容多了些。
700. 二叉搜索树中的搜索
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if (root == null) {
return null;
}
if (root.val == val) {
return root;
}
return root.val > val ? searchBST(root.left, val) : searchBST(root.right, val);
}
}
669. 修剪二叉搜索树

class Solution {
public TreeNode trimBST(TreeNode root, int low, int high) {
if (root == null) return root;
if (root.val > high) return trimBST(root.left, low, high);
if (root.val < low) return trimBST(root.right, low, high);
root.left = trimBST(root.left, low, high);
root.right = trimBST(root.right, low, high);
return root;
}
}
2.2.2 刷题第二站 插入和删除 (N题)
还记得分治算法思考的步骤吗?准确的说这应该是递归的思路。
1.base case:一般是这棵树是空怎么办?
2.大问题和小问题之间的联系。
其实对于下面的题:此时说分治有一点点牵强了。更应该说是递归。但是说分治也不错,总之不管说什么,其实无非就是你站在root节点,面临着选择(两条路),到底该怎么选择。此时就出现了一些选择的条件,其实这些条件就是将大问题和小问题之间的联系彻底考虑完。
LeetCode 701 二叉搜索树中的插入操作 分治
base case:当树为空时,直接return new Node(val);
小问题:将val插入到以root为首的树中形成新的二叉搜索树,并返回新的root
联系:此时树已分空,如何将所有情况分清楚就很重要了。当val < root.val;则向左子树递归;反之,向右子树递归。
class Solution {
// 小问题:将val插入到以root为根的树(可为null)上;并返回根节点
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (root.val > val) {
root.left = insertIntoBST(root.left, val);
}
if (root.val < val) {
root.right = insertIntoBST(root.right, val);
}
return root;
}
}
LeetCode 450 删除二叉搜索树中的节点
base case:当树是空的时候,返回null,因为这时候你在这棵树上根本没有找到该点。
小问题:删除以root为根的二叉树上的一点,并返回删除后的根节点。
联系:此时树已非空。如果当前点就是要删除的点,此时分左或右子树为空,两个都非空(此时找到右子树最小值取代root,并对右子树递归);如果当前点并非要删除的点,则根据大小进行左右选择。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
// 这是第一种情况:没有找到删除的节点,遍历到空节点直接返回
if (root == null) {
return root;
}
// 第二种情况,当前节点正是要删除的节点
if (root.val == key) {
// 1. 如果左右子树都为空,即叶子节点
// 2. 左子树为空,右子树不为空,返回右子树根节点
if (root.left == null) {
return root.right;
} else if (root.right == null) { // 3. 左子树不为空,右子树为空
return root.left;
} else { // 4. 左右子树都不为空
TreeNode temp = root.right;
while (temp.left != null) {
temp = temp.left;
}
root.val = temp.val;
root.right = deleteNode(root.right, root.val);
}
}else if (root.val > key) { // 要删除的节点在左子树位置
root.left = deleteNode(root.left, key);
} else { // 在右子树上
root.right = deleteNode(root.right, key);
}
return root;
}
}
2.2.3 刷题第三站 中序遍历是升序 (N题)
LeetCode 173 二叉搜索树迭代器(未完成)
LeetCode 501 二叉搜索树中的众数 (未完成)
根据中序遍历是升序进行做题。
遍历过程中,维护一个全局变量count记录出现相同数最长的长度;

class Solution {
List<Integer> answer = new ArrayList<Integer>();
int base, count, maxCount;
public int[] findMode(TreeNode root) {
dfs(root);
int[] mode = new int[answer.size()];
for (int i = 0; i < answer.size(); ++i) {
mode[i] = answer.get(i);
}
return mode;
}
private void dfs(TreeNode root) {
if (root != null) {
dfs(root.left);
update(root.val);
dfs(root.right);
}
}
private void update(int x) {
if (x == base) {
count++;
} else {
count = 1;
base = x;
}
if (count == maxCount) {
answer.add(base);
} else if (count > maxCount) {
answer.clear();
maxCount = count;
answer.add(x);
}
}
}

暂时还不会Morris遍历!
530. 二叉搜索树的最小绝对差

class Solution {
int pre;
int ans;
public int getMinimumDifference(TreeNode root) {
ans = Integer.MAX_VALUE;
pre = -1;
dfs(root);
return ans;
}
private void dfs(TreeNode root) {
if (root == null) return;
dfs(root.left);
if(pre == -1) {
pre = root.val;
} else {
ans = Math.min(ans, root.val - pre);
pre = root.val;
}
dfs(root.right);
}
}
3. 总结
1.对于二叉树的题目,我们学过DFS(又分为前序、中序和后序)、Divide & Conquer(其实就是后序)和层序遍历。但其实解题80-90%都是分治。但是对于稍微有一点复杂的问题,就是递归思想了,说白了,分治也是递归。然后还有一部分题是层序遍历。当然还有一部分是用递归即可解决的。
2.递归的做题步骤:1.base case;2.小问题;3.大问题和小问题的联系
3.二叉搜索树的定义及中序遍历是升序。
4.如何用递归理解遍历
对于前序遍历,可以这么理解。
base case:当树为空时,做??
小问题:拿着当前根节点的树,我啥也不做,我就是走一遍,看一看,什么也不返回。
联系:要想把整棵树看个遍,要先看根节点,再看左节点,再看右节点。
对于中、后序遍历,跟人认为无需理解,这只是某个人闲着没事做相出的名字,你就记住位置就好了。当然其也是有点作用的,比如根据前序和中序恢复二叉树;再比如二叉搜索树中序遍历是升序;再比如根据后序遍历可以联想到分治(但是其实后续可以用递归理解的。)
2. 二叉树
2.1. 刷题第一期
LeetCode 226
翻转二叉树。
思路: 利用前序遍历,翻转每个节点的左右子节点
class Solution {
// 翻转以root为根的二叉树,并返回根节点
public TreeNode invertTree(TreeNode root) {
// base case
if (root == null) {
return root;
}
// 前序遍历位置
// root 节点需要交换它的左右子节点
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
// 让左右子节点继续翻转它们的子节点
invertTree(root.left);
invertTree(root.right);
return root;
}
}
小结: 使用后序遍历一样可以实现,但是中序遍历不行。
首先讲这道题目是想告诉你,二叉树题目的一个难点就是,如何把题目的要求细化成每个节点需要做的事情。
LeetCode 116
填充完美二叉树中每个节点的next指针,使其指向下一个右侧节点。如果找不到下一个右侧节点。则将next指针设置为null。结果如图:
思路: 要想让每一层的节点穿起来,是不是只要把每个节点的左右子节点都穿起来即可。
Node connect(Node root) {
// base case
if (root == null || root.left == null) {
return root;
}
// 前序遍历位置
root.left.next = root.right;
// 左右子节点做同样的事情
connect(root.left);
conncet(root.right);
return root;
}
上面的代码并不能完成本题,其结果是:如图所示,该做法不能使根节点的左右两子树之间相互连接起来。至于原因嘛:当你遍历到任意一个节点时:你像让这个节点为首(1)的树每层节点连接起来。根据递归,你肯定是像借助子树已完成该操作,即(2)节点已完成,(3)节点也已完成。此时你又让节点(2)和(3)连接,这是一个关键地方,这个地方没有办法让两个本来孤立的树相连,因为无法到达。这里的解释并不好,见谅。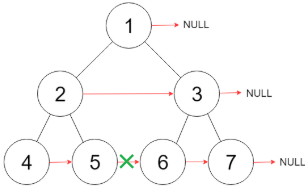
回想刚才说的,二叉树的问题难点在于,如何把题目的要求细化成每个节点需要做的事情,但是如果只依赖一个节点的话,肯定是没办法连接「跨父节点」的两个相邻节点的。
我们这里将该题化成每个节点做的事情是:每个节点的左右节点链接(前序遍历位置)。如果只依赖一个节点,显然无法满足题目。因为你通过任何节点,都无法将5链接6这种可能链接上。
那么,我们的做法就是增加函数参数,一个节点做不到,我们就给安排两个节点,[将每一层二叉树节点连接起来]可以细化成[将两个节点形成的二叉树的同层链接起来]
class Solution {
public Node connect(Node root) {
if (root == null || root.left == null) {
return root;
}
connectTwoNode(root.left, root.right);
return root;
}
//
private void connectTwoNode(Node left, Node right)
{
if(left == null) {
return;
}
connectTwoNode(left.left, left.right);
connectTwoNode(right.left, right.right);
// 后序遍历位置
// 让传入的两个节点为首的子树的左树右侧和右树左侧相连
while (left != null) {
left.next = right;
left = left.right;
right = right.left;
}
}
}
上面这个递归函数就是这个意思。下面我们只需要考虑两件事:base case;在已知2和3节点的树的同层已经相连情况下,如何让整棵树相连。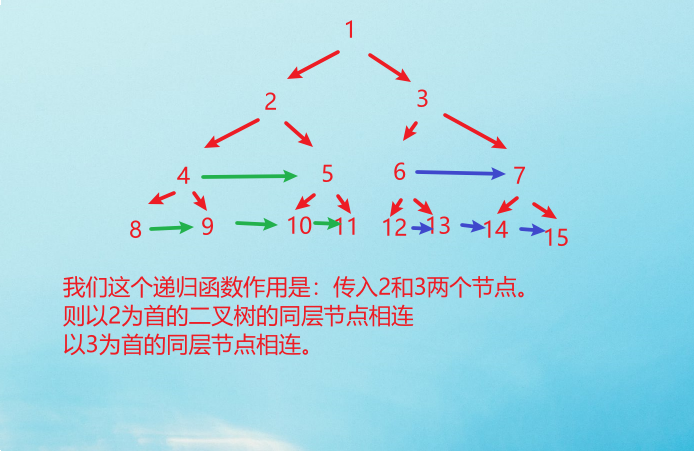
LeetCode 114
给定一个二叉树,原地将它展开为一个单链表。如图: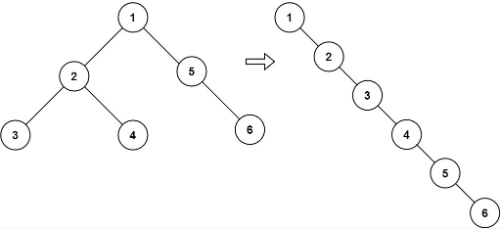
思路: 将左子树展开为单链表,右子树展开为单链表。最后将两个单链表和根节点相连(注意:根节点的左子树要置为null)。
// 定义:将以 root 为根的树拉平为链表
void flatten(TreeNode root) {
// base case
if (root == null) return;
flatten(root.left);
flatten(root.right);
/**** 后序遍历位置 ****/
// 1、左右子树已经被拉平成一条链表
TreeNode left = root.left;
TreeNode right = root.right;
// 2、将左子树作为右子树
root.left = null;
root.right = left;
// 3、将原先的右子树接到当前右子树的末端
TreeNode p = root;
while (p.right != null) {
p = p.right;
}
p.right = right;
}
你看,这就是递归的魅力,你说flatten函数是怎么把左右子树拉平的?不容易说清楚,但是只要知道**flatten**的定义如此,相信这个定义,让**root**做它该做的事情,然后**flatten**函数就会按照定义工作。
总结
递归算法的关键要明确函数的定义,相信这个定义,而不要跳进递归细节。如果涉及到一个节点无法完成的事情,就要定义两个节点了,对于116题,显然一个节点是无法完成跨树的操作的。
写二叉树的算法题,都是基于递归框架的,我们先要搞清楚**root**节点它自己要做什么,然后根据题目要求选择使用前序,中序,后续的递归框架。
二叉树题目的难点在于如何通过题目的要求思考出每一个节点需要做什么,这个只能通过多刷题进行练习了。
个人想法:上面这三道题都是用后序遍历解决的,也可以说是分治。当然第一题就是遍历,可以用前序,也可以用后续。
2.2. 刷题第二期
leetCode 654
给定一个不含重复元素的整数数组 nums 。一个以此数组直接递归构建的 最大二叉树 定义如下:
- 二叉树的根是数组 nums 中的最大元素。
- 左子树是通过数组中 最大值左边部分 递归构造出的最大二叉树。
- 右子树是通过数组中 最大值右边部分 递归构造出的最大二叉树。
返回有给定数组 nums 构建的 最大二叉树,并输出这个树的根节点 。
思路: 这道题太简单,定义就是递归。先找到该数组的最大值max的位置p,然后从0-(p-1)位置递归,(p+1)-(nums.length-1)位置递归。该递归函数的定义就是这道题目的定义,将该数组转换成最大二叉树并返回根节点。
class Solution {
public TreeNode constructMaximumBinaryTree(int[] nums) {
if (nums == null || nums.length == 0) {
return null;
}
return helper(nums, 0, nums.length - 1);
}
private TreeNode helper(int[] nums, int left, int right)
{
// base case
if (nums == null || nums.length == 0) {
return null;
}
// 前序遍历位置
// 寻找最大值位置
int maxPosition = findMaxNumPosition(nums, left, right);
TreeNode leftMaxNode = null;
TreeNode rightMaxNode = null;
if (maxPosition != left) {
leftMaxNode = helper(nums, left, maxPosition - 1);
}
if (maxPosition != right) {
rightMaxNode = helper(nums, maxPosition + 1, right);
}
// 后续遍历位置
// 将根节点和上面的两个子树相连
TreeNode root = new TreeNode(nums[maxPosition]);
root.left = leftMaxNode;
root.right = rightMaxNode;
return root;
}
private int findMaxNumPosition(int[] nums, int left, int right)
{
int maxPosition = left;
for (int i = left; i <= right; i++)
{
if (nums[i] > nums[maxPosition]) {
maxPosition = i;
}
}
return maxPosition;
}
}
个人想法:其实解决二叉树的题目就是:寻找定义和以某个节点为首的树要做的事情(这个事情可能和题目要一样,也可能有区别),然后再和题目要求的用这个事情关联起来。 其实就是:本来你是解决一棵树的大事情的,但是呢?你先默认可与解决小一点的树的事情,然后再和这个大事情关联起来。至于这个小事情和大事情是否一样,一般一样,单页可能会有些区别。
LeetCode 105
根据前序遍历和中序遍历的数组构造二叉树。注意,你可以假设树中没有重复元素。如图:
思路: 实话说,这道题对以前的我来说,可能很难,单现在看来实在是简单。其实我们可以把这道题理解成递归的思想。 对于上面两个数组,其中一个是一棵树的前序遍历,另一个是一棵树的后序遍历。怎么做呢? 拿到第一个数组,我们就知道第一个数字3就是根节点,然后其左右子树是谁呢?根据第二个数组,就知道左子树的中序遍历是9,根据第一个数组,知道左子树的前序遍历是9;根据第二个数组知道,右子树的中序遍历是15,20,7,根据第一个数组,知道右子树的前序遍历是20,15,7。重头戏来了:着你不就是将一个大问题(知道前序遍历和中序遍历的两个数组,转化成一棵树),化成了两个小问题(知道四个数组,其中两个是一棵树的前序遍历和中序遍历,另两个则是另一棵树的前序遍历和中序遍历)。 那么现在本题的解法就是:…看代码吧。 小问题:给定两个数组,分别是一棵树的前序遍历和中序遍历,构造该树返回该二叉树的根节点。
class Solution {
// 小问题:给定两个数组(要求数组必须至少有一个值),分别是一棵树的前序遍历和中序遍历,构造该树返回该二叉树的根节点。
public static TreeNode buildTree(int[] preorder, int[] inorder) {
// 如果长度为null或者长度为0,或者两个数组长度不同,则返回null。
// 注:其实我没有判断这两个数组是否真的符合一棵树的前序遍历和中序遍历,按道理,是要判断的
if (preorder == null || preorder.length == 0 || inorder == null || preorder.length != inorder.length) {
return null;
}
return helper(preorder, 0, preorder.length - 1, inorder, 0, inorder.length - 1);
}
private static TreeNode helper(int[] preorder, int preorderLeft, int preorderRight, int[] inorder, int inorderLeft, int inorderRight)
{
// base case
if (preorderLeft == preorderRight) {
return new TreeNode(preorder[preorderLeft]);
}
int rootVal = preorder[preorderLeft];
int position = inorderLeft;
for (; position <= inorderRight; position++)
{
if (inorder[position] == rootVal) {
break;
}
}
TreeNode root = new TreeNode(preorder[preorderLeft]);
if (preorderLeft + 1 <= preorderLeft + 1 + (position - 1 - inorderLeft))
{
root.left = helper(preorder, preorderLeft + 1, preorderLeft + 1 + (position - 1 - inorderLeft), inorder, inorderLeft, position - 1);
}
if (preorderLeft + 1 + (position - 1 - inorderLeft) + 1 <= preorderRight) {
root.right = helper(preorder, preorderLeft + 1 + (position - 1 - inorderLeft) + 1, preorderRight, inorder, position + 1, inorderRight);
}
return root;
}
}
个人想法:这道题思路这么简单,还是花了我一些时间。那原因出在哪里了呢?是边界条件。上面的两个if判断上,如果没有的花,对于{2,1};{1,2}这样的数组没有办法解决。我们上面定义了一个小问题: 给定两个数组,分别是一棵树的前序遍历和中序遍历,构造该树返回该二叉树的根节点。 可是问题是:什么样才算数组,你可能说这是废话,错了,在递归中定义都是非常明确的。我们这道题的定义应该是长度不小于1的数组才能被这里称为“数组”。 这道题,让我们知道了对于小问题的定义一定要非常清晰,减少在边界上的灰头土脸。
LeetCode 106
根据一棵树的中序遍历和后序遍历构造二叉树。你可以假设没有重复元素。
思路: 小问题:根据两个数组,其是中序和后序,返回二叉树的根节点。(该数组长度不小于1,这个条件是我们在做题时加上的,其实刚开始应该想不到).
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
// 如果长度为null或者长度为0,或者两个数组长度不同,则返回null。
// 注:其实我没有判断这两个数组是否真的符合一棵树的前序遍历和中序遍历,按道理,是要判断的
if (inorder == null || inorder.length == 0 || postorder == null || inorder.length != postorder.length) {
return null;
}
return helper(inorder, 0, inorder.length - 1, postorder, 0, postorder.length - 1);
}
// 保证传入的数组!=null 且 长度不小于1
private TreeNode helper(int[] inorder, int inorderLeft, int inorderRight, int[] postorder, int postorderLeft, int postorderRight)
{
// base case : 长度为1时直接可以返回
if (inorderLeft == inorderRight) {
return new TreeNode(inorder[inorderLeft]);
}
int rootVal = postorder[postorderRight];
int position = inorderLeft;
for (; inorder[position] != rootVal; position++) {
}
// 定义根节点
TreeNode root = new TreeNode(postorder[postorderRight]);
if (inorderLeft <= position - 1) {
root.left = helper(inorder, inorderLeft, position - 1, postorder,postorderLeft, postorderLeft + (position - inorderLeft - 1));
}
if (position + 1 <= inorderRight) {
root.right = helper(inorder, position + 1, inorderRight, postorder, postorderLeft + (position - inorderLeft - 1) + 1, postorderRight - 1);
}
return root;
}
}
个人想法:本题已无需多言
总结
最后呼应下前文,做二叉树的问题,关键是把题目的要求细化,搞清楚根节点应该做什么,然后剩下的事情抛给前/中/后序的遍历框架就行了。此外,就是要对小问题(每个节点的本事)明确,这样可以减少边界情况的错误。
2.3. 刷题第三期
根据前两期,大家还是能够通过二叉树学习到 框架思维 的。但还是有不少读者有一些问题,比如如何判断我们应该用前序还是中序还是后序遍历的框架?
那么本文就针对这个问题,不贪多,给你掰开揉碎只讲一道题。
还是那句话,根据题意,思考一个二叉树节点需要做什么,到底用什么遍历顺序就清楚了。
LeetCode 652
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。如图:
这题咋做呢?还是老套路,先思考,对于某一个节点,它应该做什么。
3. 二叉搜索树
3.1 刷题第一期
二叉搜索树(Binary Search Tree,后文简写 BST),其特征是:
1、对于 BST 的每一个节点node,左子树节点的值都比node的值要小,右子树节点的值都比node的值大。
2、对于 BST 的每一个节点node,它的左侧子树和右侧子树都是 BST。
二叉搜索树并不算复杂,但我觉得它构建起了数据结构领域的半壁江山,直接基于 BST 的数据结构有 AVL 树,红黑树等等,拥有了自平衡性质,可以提供 logN 级别的增删查改效率;还有 B+ 树,线段树等结构都是基于 BST 的思想来设计的。
从做算法题的角度来看 BST,除了它的定义,还有一个重要的性质:BST 的中序遍历结果是有序的(升序)。
也就是说,如果输入一棵 BST,以下代码可以将 BST 中每个节点的值升序打印出来:
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
// 中序遍历代码位置
print(root.val);
traverse(root.right);
}
LeetCode 230
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
思路: 中序遍历,并计数(遍历的是第一个);当等于k时,返回遍历到的值。
class Solution {
public int kthSmallest(TreeNode root, int k) {
helper(root, k);
return res;
}
// 记录结果
int res = 0;
// 记录当前元素的排名
int rank = 0;
private void helper(TreeNode root, int k)
{
if (root == null) {
return;
}
helper(root.left, k);
rank++;
if (k == rank) {
res = root.val;
return;
}
helper(root.right, k);
}
}
个人想法:这道题我竟然不会,我没有借助全局变量,竟然没有做出来。
这道题就做完了,不过呢,还是要多说几句,因为这个解法并不是最高效的解法,而是仅仅适用于这道题。
高效做法:后续补充。
LeetCode 538
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
思路: 这道题想下去其实是有一点难度的,感觉没有思路。但是呢?
我们知道二叉搜索树的中序遍历是从左到右依次上升的序列。
void traverse(TreeNode root) {
if (root == null) return;
traverse(root.left);
// 中序遍历代码位置
print(root.val);
traverse(root.right);
}
那有没有方式可以让其降序排列呢?当然有:而且很简单
void traverse(TreeNode root) {
if (root == null) return;
// 先递归遍历右子树
traverse(root.right);
// 中序遍历代码位置
print(root.val);
// 后递归遍历左子树
traverse(root.left);
}
这段代码可以从大到小降序打印 BST 节点的值,如果维护一个外部累加变量**sum**,然后把**sum**赋值给 BST 中的每一个节点,不就将 BST 转化成累加树了吗?
class Solution {
public TreeNode convertBST(TreeNode root) {
helper(root);
return root;
}
int sum = 0;
void helper(TreeNode root) {
if (root == null) {
return;
}
helper(root.right);
sum += root.val;
root.val = sum;
helper(root.left);
}
}
小结
借助二叉树中序遍历,可以得到升序或降序的性质接替。此外,注意借助全局变量。
3.2 刷题第二期
上一期主要是利用二叉搜索树「中序遍历有序」的特性来解决了几道题目,本文来实现 BST 的基础操作:判断 BST 的合法性、增、删、查。其中「删」和「判断合法性」略微复杂。
LeetCode 98
思路: 小问题:一棵二叉树是否是二叉搜索树。如果是,则返回true;如果不是,则返回false。 然后:就可以根据这个小问题解决大问题了。
class Solution {
public boolean isValidBST(TreeNode root) {
if (root == null || (root.left == null && root.right == null)) {
return true;
}
if (!isValidBST(root.left)) {
return false;
}
if (!isValidBST(root.right)) {
return false;
}
// 后序遍历位置
// 判断根节点是否比左子树的最大值大,比右子树的最小值小
TreeNode maxInLeftNode = root.left;
if (maxInLeftNode != null) {
while (maxInLeftNode.right != null) {
maxInLeftNode = maxInLeftNode.right;
}
}
if (root.left != null && root.val <= maxInLeftNode.val) {
return false;
}
TreeNode minInRightNode = root.right;
if (root.right != null) {
while (minInRightNode.left != null) {
minInRightNode = minInRightNode.left;
}
}
if (root.right != null && root.val >= minInRightNode.val) {
return false;
}
return true;
}
}
个人想法:就是这么简单。其实吧,二叉树就是递归,大问题化成小问题。小问题可能和大问题一致,页可能稍微有一点区别。重要的除了要定义好小问题,还要找到大问题和小问题间的联系。
LeetCode 701
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果
思路: 当将 val 插入到以 root 为根的子树上时,根据val 与 root.val 的大小关系,就可以确定要将val 插入到哪个子树中。
如果该子树不为空,则问题转化成了将 \textit{val}val 插入到对应子树上。 否则,在此处新建一个以 \textit{val}val 为值的节点,并链接到其父节点 \textit{root}root 上。 小问题: 将 val 插入到以 root 为根的树 ( 不可为 null) 上;并返回根节点
class Solution {
// 小问题:将val插入到以root为根的树(不可为null)上;并返回根节点
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (root.val > val) {
if (root.left == null) {
root.left = new TreeNode(val);
return root;
} else {
insertIntoBST(root.left, val);
}
}
if (root.val < val) {
if (root.right == null) {
root.right = new TreeNode(val);
return root;
} else {
insertIntoBST(root.right, val);
}
}
return root;
}
}
个人想法:这道题我们将这个大问题和小问题联系起来相对有一点难度,这个就需要经验的积累了。 这里id小问题是非空的,因此下面在分了是去哪颗树后,就判断空这种情况,那我们的子问题能否定位为空树也可以呢?
下面就出现了这个答案:我想这个大问题如何化成小问题呢?
小问题:将val插入到以root为根的树(可为null)上;并返回根节点。对于小问题,我们知道,我们会这个技能,其虽然少个黑匣子,但是我们就是会了。
base case:当树为null时,就返回new TreeNode(val);当然如果你不是空的,你一定会被分到这一步的,因为每次递归都是root.left和root.right。自然这个base case没有问题。
大问题与小问题的联系:当root.val > val,我们知道要将val安排到左子树,不管此时左子树是否为空,我们都会安排,其实就是insertIntoBST(root.left, val);对于右子树,亦是如此。
因此,就出现了下面的答案,但是很可惜,这个是错误的,其无法解决题目。这是为什么呢?
class Solution {
// 小问题:将val插入到以root为根的树(可为null)上;并返回根节点
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (root.val > val) {
insertIntoBST(root.left, val);
}
if (root.val < val) {
insertIntoBST(root.right, val);
}
return root;
}
}
大问题与小问题的联系:当root.val > val,我们知道要将val安排到左子树,不管此时左子树是否为空,我们都会安排,其实就是insertIntoBST(root.left, val);对于右子树,亦是如此。但是这样就结束了吗?没有,因为你并没有把这个大问题和这个小问题联系起来。比如以左子树为例,你是可以通过黑匣子将val放到root.left的子树上,但是你没有将大问题和小问题之间建立任何关系(桥梁)。这个桥梁就是root.left = insertIntoBST(root.left, val);我们定义的就是返回插入值后返回根节点,我们的黑匣子你只知道是返回根节点,但是这个根节点是谁你已经不知了,更不知道是不是还是原本的root.left。
class Solution {
// 小问题:将val插入到以root为根的树(可为null)上;并返回根节点
public TreeNode insertIntoBST(TreeNode root, int val) {
if (root == null) {
return new TreeNode(val);
}
if (root.val > val) {
root.left = insertIntoBST(root.left, val);
}
if (root.val < val) {
root.right = insertIntoBST(root.right, val);
}
return root;
}
}
LeetCode 450
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
- 首先找到需要删除的节点;
- 如果找到了,删除它。
思路 对于要删除的节点,考虑四种情况:
- 这个节点是叶子节点,直接返回null
2.这个节点只有左子树,返回它的左子树 3.这个节点只有右子树,返回它的右子树 4.这个节点左右子树都不为空,查找它的右子树中的最小值,也就是右子树中最左边的那个节点,将它与当前节点值替换,然后递归删除右子树
本题删除有五种情况: 第一种情况:没找到删除的节点,遍历到空节点直接返回了 (找到删除的节点) 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
// 这是第一种情况:没有找到删除的节点,遍历到空节点直接返回
if (root == null) {
return root;
}
// 第二种情况,当前节点正是要删除的节点
if (root.val == key) {
// 1. 如果左右子树都为空,即叶子节点
// 2. 左子树为空,右子树不为空,返回右子树根节点
if (root.left == null) {
return root.right;
} else if (root.right == null) { // 3. 左子树不为空,右子树为空
return root.left;
} else { // 4. 左右子树都不为空
TreeNode temp = root.right;
while (temp.left != null) {
temp = temp.left;
}
root.val = temp.val;
root.right = deleteNode(root.right, root.val);
}
}else if (root.val > key) { // 要删除的节点在左子树位置
root.left = deleteNode(root.left, key);
} else { // 在右子树上
root.right = deleteNode(root.right, key);
}
return root;
}
}
个人想法,这道题非常值得思考。大家有没有想过,如果我们不要这个base case会是什么样的结果呢?即:
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
// 这是第一种情况:没有找到删除的节点,遍历到空节点直接返回
// 第二种情况,当前节点正是要删除的节点
if (root.val == key) {
// 1. 如果左右子树都为空,即叶子节点
// 2. 左子树为空,右子树不为空,返回右子树根节点
if (root.left == null) {
return root.right;
} else if (root.right == null) { // 3. 左子树不为空,右子树为空
return root.left;
} else { // 4. 左右子树都不为空
TreeNode temp = root.right;
while (temp.left != null) {
temp = temp.left;
}
root.val = temp.val;
root.right = deleteNode(root.right, root.val);
}
}else if (root.val > key) { // 要删除的节点在左子树位置
root.left = deleteNode(root.left, key);
} else { // 在右子树上
root.right = deleteNode(root.right, key);
}
return root;
}
}
上述代码一样能通过一些实例(只要这棵二叉搜索树含有要删除的数)。这就意味深长了,首先我们知道这个方法体内的程序是针对这整棵树任意节点为首的树的,因此这棵树可能是任何情况,包括null。因此这里就必须考虑,如果是null树,怎么办?当然,你不考虑也能过一些实例,而没有报错,这是为什么呢?因为我们知道这些实例包含要删除的节点,这个递归走不到null节点即可完成使命(删除操作)。
因此这道题就分如下情况,准确的说这棵要被删除的树分哪些情况。
1.如果这是一棵空树(你可以保证这棵不可能是空树的情况下不写,包括两种,1是本来这个root就不是null;2是递归后不可能到空树就结束了)。
2.如果不是空树
2.1当前节点root就是val值,这时再分四种情况。
2.1 当前节点不是val值,分两种情况。
为了将子问题和父问题相连,因此这个方法体(对于任何树都试用)要返回删除后的根节点,这样可以和root相连。
小结
在二叉树递归框架之上,扩展出一套 BST 代码框架:
void BST(TreeNode root, int target) {
if (root.val == target)
// 找到目标,做点什么
if (root.val < target)
BST(root.right, target);
if (root.val > target)
BST(root.left, target);
}
4. 序列化与反序列化二叉树
JSON 的运用非常广泛,比如我们经常将变成语言中的结构体序列化成 JSON 字符串,存入缓存或者通过网络发送给远端服务,消费者接受 JSON 字符串然后进行反序列化,就可以得到原始数据了。这就是「序列化」和「反序列化」的目的,以某种固定格式组织字符串,使得数据可以独立于编程语言。
LeetCode 297
前序遍历解法
前序遍历框架
void traverse(TreeNode root) {
if (root == null) return;
// 前序遍历的代码
traverse(root.left);
traverse(root.right);
}
真的很简单,在递归遍历两棵子树之前写的代码就是前序遍历代码,那么请你看一看如下伪代码:
LinkedList<Integer> res;
void tarverse(TreeNode root) {
if (root == null) {
// 暂且用数字 -1 代表空指针 null
res.addLast(-1); // 当然这个是有问题的,万一节点就是-1
return;
}
// 前序遍历位置
res.addLast(root.val);
tarverse(root.left);
tarverse(root.right);
}
调用 traverse 函数之后,你是否可以立即想出这个 res 列表中元素的顺序是怎样的?比如如下二叉树(# 代表空指针 null),可以直观看出前序遍历做的事情: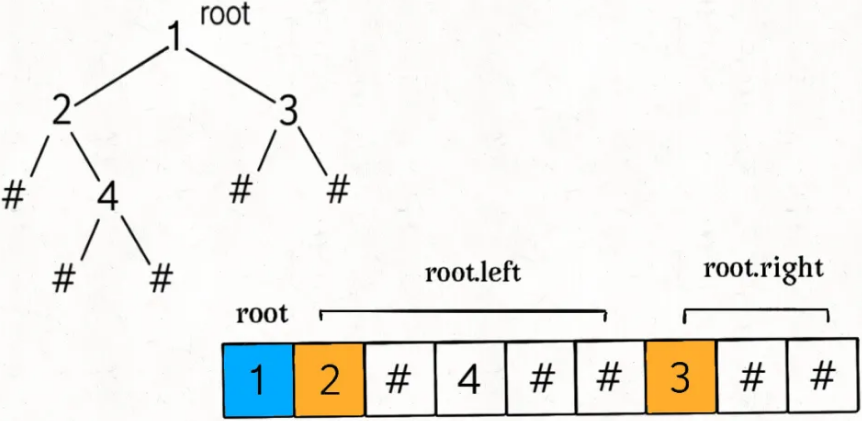
那么 res = [1,2,-1,4,-1,-1,3,-1,-1],这就是将二叉树「打平」到了一个列表中,其中 -1 代表 null。
那么,将二叉树打平到一个字符串中也是完全一样的:
// 代表分隔符的字符
String SEP = ",";
// 代表 null 空指针的字符
String NULL = "#";
// 用于拼接字符串
StringBuilder sb = new StringBuilder();
/* 将二叉树打平为字符串 */
void traverse(TreeNode root, StringBuilder sb) {
if (root == null) {
sb.append(NULL).append(SEP);
return;
}
/****** 前序遍历位置 ******/
sb.append(root.val).append(SEP);
/***********************/
traverse(root.left, sb);
traverse(root.right, sb);
}
StringBuilder 可以用于高效拼接字符串,所以也可以认为是一个列表,用 ,作为分隔符,用 # 表示空指针 null,调用完 traverse 函数后,StringBuilder 中的字符串应该是 1,2,#,4,#,#,3,#,#,。
至此,我们已经可以写出序列化函数 serialize 的代码了:
String SEP = ",";
String NULL = "#";
/* 主函数,将二叉树序列化为字符串 */
String serialize(TreeNode root) {
StringBuilder sb = new StringBuilder();
serialize(root, sb);
return sb.toString();
}
/* 辅助函数,将二叉树存入 StringBuilder */
void serialize(TreeNode root, StringBuilder sb) {
if (root == null) {
sb.append(NULL).append(SEP);
return;
}
/****** 前序遍历位置 ******/
sb.append(root.val).append(SEP);
/***********************/
serialize(root.left, sb);
serialize(root.right, sb);
}
现在,思考一下如何写 deserialize 函数,将字符串反过来构造二叉树。
首先我们可以把字符串转化成列表:
String data = "1,2,#,4,#,#,3,#,#,";
String[] nodes = data.split(",");
这样,nodes 列表就是二叉树的前序遍历结果,问题转化为:如何通过二叉树的前序遍历结果还原一棵二叉树?
PS:一般语境下,单单前序遍历结果是不能还原二叉树结构的,因为缺少空指针的信息,至少要得到前、中、后序遍历中的两种才能还原二叉树。但是这里的 node列表包含空指针的信息,所以只使用 node 列表就可以还原二叉树。
根据我们刚才的分析,nodes 列表就是一棵打平的二叉树:

若有收获,就点个赞吧
0 人点赞
