树莓派下paudio安装与声音监控运用
在树莓派平台上使用pyaudio实现usb麦克风的录音功能,进而可以实现人机交互,实现语音识别和语音合成。
参考pyaudio官方文档,链接地址如下:
pyaudio是python的模块,在树莓派下安装pyaudio 首先需安装portaudio.dev
安装步骤如下:
1、安装portaudio.dev : sudo apt-get install portaudio.dev
2、安装python-pyaudio: sudo apt-get install python-pyaudio
3、安装sox快速检测麦克风配置是否正确:sudo apt-get install sox
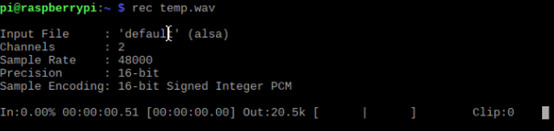
4、测试麦克风配置是否正确,树莓派终端输入以下命令:
rec temp.wav
5、测试pyaudio 代码如下:录音40s并保存为audio.wav播放。
#_*_ coding:UTF-8 _*_# @author: zdl# 测试pyaudio 使用pyaudio录音,录音完毕播放录音内容# 需要安装pyaudio 安装过程在教程中讲解# pyaudio API函数库参考: http://people.csail.mit.edu/hubert/pyaudio/docs/#pyaudio.Stream.writeimport wavefrom pyaudio import PyAudio,paInt16# 设置采样参数NUM_SAMPLES = 2000TIME = 2chunk = 1024# read wav file from filenamedef read_wave_file(filename):fp = wave.open(filename,'rb')nf = fp.getnframes() #获取采样点数量print('sampwidth:',fp.getsampwidth())print('framerate:',fp.getframerate())print('channels:',fp.getnchannels())f_len = nf*2audio_data = fp.readframes(nf)# save wav file to filenamedef save_wave_file(filename,data):wf = wave.open(filename,'wb')wf.setnchannels(1) # set channels 1 or 2wf.setsampwidth(2) # set sampwidth 1 or 2wf.setframerate(16000) # set framerate 8K or 16Kwf.writeframes(b"".join(data)) # write datawf.close()#recode audio to audio.wavdef record():pa = PyAudio() # 实例化 pyaudio# 打开输入流并设置音频采样参数 1 channel 16K frameratestream = pa.open(format = paInt16,channels=1,rate=16000,input=True,frames_per_buffer=NUM_SAMPLES)audioBuffer = [] # 录音缓存数组count = 0# 录制40s语音while count<TIME*20:string_audio_data = stream.read(NUM_SAMPLES) #一次性录音采样字节的大小audioBuffer.append(string_audio_data)count +=1print('.'), #加逗号不换行输出# 保存录制的语音文件到audio.wav中并关闭流save_wave_file('audio.wav',audioBuffer)stream.close()# 播放后缀为wav的音频文件def play():wf = wave.open(r"audio.wav",'rb') # 打开audio.wavp = PyAudio() # 实例化pyaudio# 打开流stream = p.open( format=p.get_format_from_width(wf.getsampwidth()),channels=wf.getnchannels(),rate=wf.getframerate(),output=True)# 播放音频while True:data = wf.readframes(chunk)if data == "":breakstream.write(data)# 释放IOstream.stop_stream()stream.close()p.terminate()# main函数 录制40s音频并播放if __name__ == '__main__':print('record ready...')record()print('record over!')play()
程序演示结果:

使用不同的usb摄像头会出现采样率报错的问题,解决方案参考以下博客:
https://blog.csdn.net/u013860985/article/details/79326379
https://blog.csdn.net/u013372900/article/details/80296125
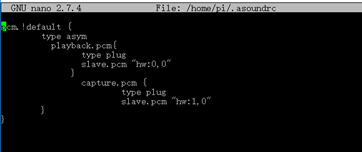
添加一个新的~/.asoundrc 到pi目录下:sudo nano ~/.asoundrc
输入以下内容:
pcm.!default {type hwcard 1}ctl.!default {type hwcard 1}
或者:
pcm.!default {type asymplayback.pcm {type plugslave.pcm "hw:0,0"}capture.pcm {type plugslave.pcm "hw:1,0"}}ctl.!default {type hwcard 1}
树莓派音频输出设置:
1、选择树莓派 audio output 为AUTO或者3.5mm sudo raspi-config 设置
2、如何调整输出音量,终端输入 alsamixer 命令然后上下键调整
3、语音合成的音频为MP3文件,pyaudio只能播放wav文件,所以需要安装MP3播放插件 mplayer。
安装 sudo apt-get install mplayer
测试 mplayer xx.mp3 (需先进入xx.mp3的文件夹下)
Python 程序播放 MP3: os.system('mplayer %s' % 'xx.mp3')
思考:如何采用pyaudio制作声音的监控装置呢?监控噪声、人或者物体运动然后提示报警?
#coding:utf-8# @author: zdl#需要安装pyaudioimport waveimport numpy as npfrom pyaudio import PyAudio,paInt16import timeNUM_SAMPLES = 2000global tchunk = 1024def play(filename):wf = wave.open(filename,'rb')p = PyAudio()stream = p.open( format=p.get_format_from_width(wf.getsampwidth()),channels=wf.getnchannels(),rate=wf.getframerate(),output=True)while True:data = wf.readframes(chunk)if data == "":breakstream.write(data)stream.stop_stream()stream.close()p.terminate()def save_wave_file(filename,data): #save data to filenamewf = wave.open(filename,'wb')wf.setnchannels(1) #set channelwf.setsampwidth(2) #采样字节 1 or 2wf.setframerate(16000) #采样频率 8K or 16Kwf.writeframes(b"".join(data))wf.close()# 声音监视函数def Monitor():pa = PyAudio() # 调用句柄stream = pa.open(format = paInt16,channels=1,rate=16000,input=True,frames_per_buffer=NUM_SAMPLES)print('开始缓存录音')audioBuffer = []rec = []audioFlag = Falset = Falsewhile True:data = stream.read(NUM_SAMPLES,exception_on_overflow = False) #add exception para#if audioFlag == True:# rec.append(data) #剪切的语音文件audioBuffer.append(data) #录音源文件audioData = np.fromstring(data,dtype=np.short) #字符串创建矩阵largeSampleCount = np.sum(audioData > 2000)temp = np.max(audioData)print tempif temp > 8000 and t == False: # 声音阈值,结合实验确定,实现声音监控t = 1 #开始录音print "检测到语音信号,开始录音"begin = time.time()print tempif t:end = time.time()if end-begin > 5:timeFlag = 1 #5s录音结束if largeSampleCount > 20:saveCount = 4else:saveCount -=1if saveCount <0:saveCount =0if saveCount >0:rec.append(data)else:if len(rec) >0 or timeFlag:save_wave_file('01.wav',rec)rec = []t = 0timeFlag = 0stream.stop_stream()stream.close()p.terminate()if __name__ == '__main__':Monitor()
可以查看我的github获取更多信息:https://github.com/dalinzhangzdl/AI_Car_Raspberry-pi

若有收获,就点个赞吧
0 人点赞
