知识图谱
背景提要
今天在和团队内部进行对一个接口数量众多,代码量冗余的服务进行微服务的架构改造。在讨论如何进行服务拆分的时候,遇到了一个门槛(其实在做微服务的时候一定会遇到的问题),对老数据库进行垂直分库,根据不同的子服务,将数据库拆分为不通过的子服务库。
这时候就会遇到问题了,在开始微服务改造前,我们老系统的一些订单列表所需要的数据是通过 SQL Join 来完成的,但是在我们做微服务架构拆分后,每个服务背后的数据都被拆分到不同的数据库实例中了,我们已经不能继续开心的使用 SQL Join 来实现了,这时候讨论的焦点就是如何解决 ”跨库的Join“了。
今天晚上心血来潮上网查询资料的时候,看到了一篇由DHH编写的《The Majestic Monolith》博文,里面采用了以下几个思路,在此记录下,为以后实践做准备。
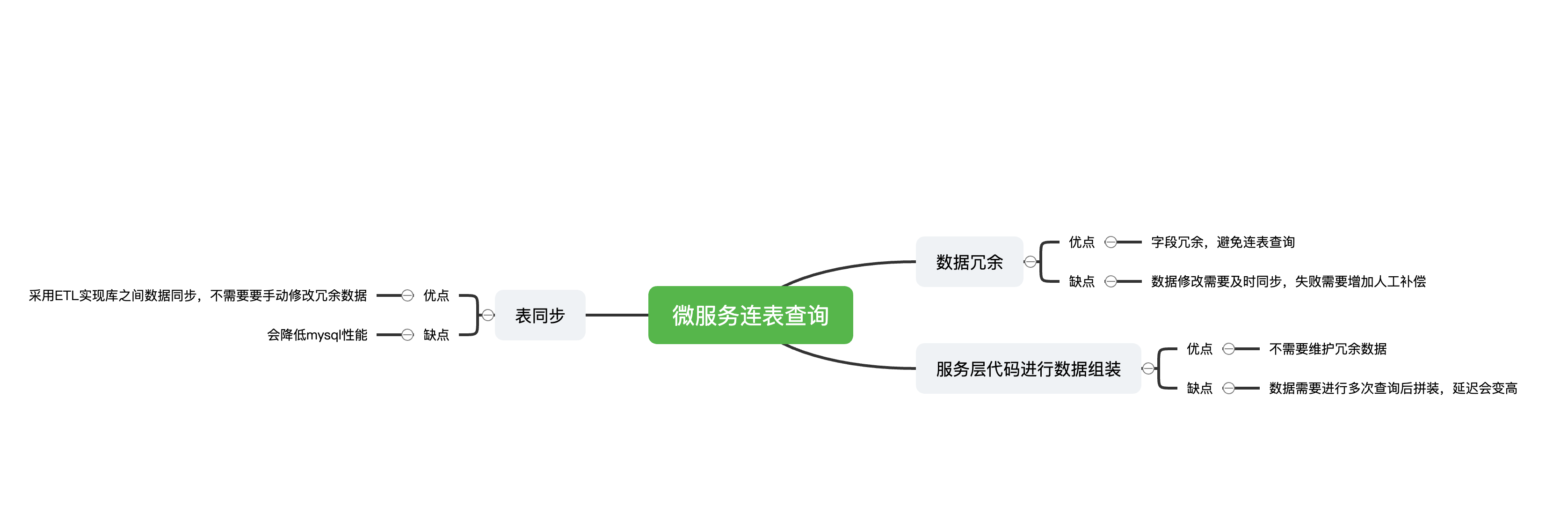
字段冗余
例子:当A库中的 Order 表需要关联查询 B库的 User 表中的字段 username ,我们就将字段 username 冗余到 A 库的 Order 表中,那么查询的时候就不需要将连个表进行关联就可以解决问题。
适用场景:依赖字段较少
优点:不需要进行关联查询,直接获取结果
缺点:当 B 库字段 username 进行修改,则需要同步 A 库修改,如果修改失败需要进行人工补偿
表同步
例子:当 A 库中的 Order 表需要关联查询 B 库的 User 表非常多的数据的时候,则冗余字段就无法使用了,这时候我们可以在 A 库创建 User 表,通过 ETL 中间件实现跨库的表同步。
适用场景:依赖字段较多
优点:字段修改不需要代码层面进行同步
缺点:如果同步实时性设置过高,会对数据库性能造成影响
服务层进行数据封装
例子:当 A 库中的 Order 表需要关联查询 B 库的 User 表非常多的数据的时候,则冗余字段就无法使用了,并且对数据的实时性要求较高,可以通过服务查询一个数据集,然后通过代码进行二次组装返回。
适用场景:依赖字段较多,对实时性要求高
优点:实时性高,字段修改不需要代码层面进行同步
缺点:接口延迟增加,逻辑变得复杂
总结
当服务间连表查询的需求非常多的时候,根据微服务拆分原则,每个服务上下文之间并未独立,此时不建议强行拆分。
如果真的没办法,可以采用以上3个方法

若有收获,就点个赞吧
0 人点赞
