DML(data manipulation language)数据操纵语言
DDL(data definition language)数据库定义语言
mysql -h$ip -P$port -u$user -p
mysql_reset_connection 设置重置连接
rows_examined的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的
redo log(重做日志)
循环写的 write pos和checkpoint InnoDB引擎特有的 物理日志,记录的是“在某个数据页上做了什么修改”
binlog(逻辑日志)
binlog是MySQL的Server层实现的,记录的是这个语句的原始逻辑,是追加写,有row,statement ,mixed
show global variables like “innodb_log%”;
innodb_flush_log_at_trx_commit = 1 每次事务的redo log都直接持久化到磁盘
sync_binlog这个参数设置成1的时候,表示每次事务的binlog都持久化到磁盘
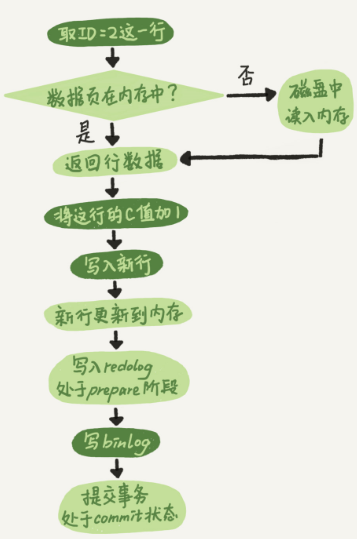
两阶段提交crash-safe
很多其他程序在日志设计方面都使用了此类方式
ACID(Atomicity、Consistency、Isolation、Durability) 脏读、不可重复读、幻读
show variables like ‘transaction_isolation’
begin 或 start transaction
commit work and chain
set autocommit=1,显示启动事务
log文件
general_log 记录所有
relay_log 中继日志 主从同步
bin_log statement, row, mixed
SET MAX_EXECUTION_TIME
show variables like ‘max_execution_time’;
innodb_trx
information_schema.Innodb_trx
sys和performance_schema
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>0.1
哈希索引
哈希索引只适合等值查询,无法排序,范围查询,不适合很多值相等的查询场景
以InnoDB的一个整数字段索引为例,这个N差不多是1200。这棵树高是4的时候,就可以存1200的3次方个值,这已经17亿了
innodb_undo_tablespaces 2
innodb_log_files_in_group和innodb_log_file_size配置日志文件数量和每个日志文件大小
重建索引,减少空洞,提高索引效率
alter table T drop index k; alter table T add index(k);
alter table T engine=InnoDB
锁
MySQL提供了一个加全局读锁的方法,命令是 Flush tables with read lock (FTWRL)
mysqldump使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图
一种是表锁,一种是元数据锁(meta data lock,MDL)
表锁的语法是 lock tables … read/write。与FTWRL类似,可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放
当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
ALTER TABLE tbl_name NOWAIT add column … ALTER TABLE tbl_name WAIT N add column …
- 一种策略是,直接进入等待,直到超时。这个超时时间可以通过参数innodb_lock_wait_timeout来设置。
- 另一种策略是,发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数innodb_deadlock_detect设置为on,表示开启这个逻辑
begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个操作InnoDB表的语句,事务才真正启动。如果你想要马上启动一个事务,可以使用start transaction with consistent snapshot 这个命令
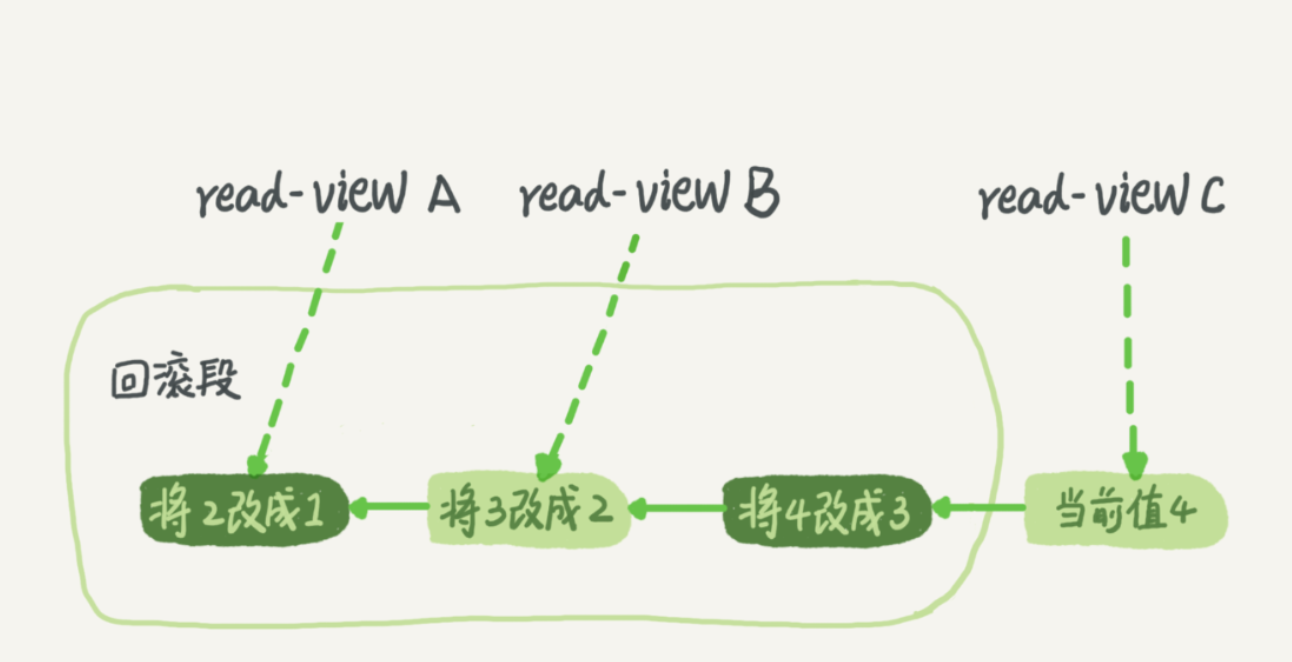
每次事务更新数据的时候,都会生成一个新的数据版本,并且把transaction id赋值给这个数据版本的事务ID,记为row trx_id
更新数据都是先读后写的,而这个读,只能读当前的值,称为“当前读”(current read)
select语句如果加锁,也是当前读
读锁(S锁,共享锁)和写锁(X锁,排他锁)。
select k from t where id=1 lock in share mode; select k from t where id=1 for update;
update 语句后面加个limit 1, 会怎么锁 先select确定需要更新的数量 再加上limit.
redo log, change buffer
innodb_change_buffer_max_size
change buffer只限于用在普通索引的场景下,而不适用于唯一索引、
redo log 主要节省的是随机写磁盘的IO消耗(转成顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗
analyze table t 命令,可以用来重新统计索引信息
force index强行选择一个索引
mysql> select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
倒序存储
select field_list from t where id_card = reverse(‘input_id_card_string’);
使用hash字段。你可以在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引
alter table t add id_card_crc int unsigned, add index(id_card_crc);
Flush
InnoDB的刷盘速度就是要参考这两个因素:一个是脏页比例,一个是redo log写盘速度。
innodb_io_capacity
这个值我建议你设置成磁盘的IOPS。磁盘的IOPS可以通过fio这个工具来测试
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest
其中,脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的,具体的命令参考下面的代码
mysql> select VARIABLE_VALUE into @a from global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_dirty’; select VARIABLE_VALUE into @b from global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_total’; select @a/@b;
表数据既可以存在共享表空间里,也可以是单独的文件。这个行为是由参数innodb_file_per_table控制的:
- 这个参数设置为OFF表示的是,表的数据放在系统共享表空间,也就是跟数据字典放在一起;
- 这个参数设置为ON表示的是,每个InnoDB表数据存储在一个以 .ibd为后缀的文件中。
Online DDL 由于日志文件记录和重放操作这个功能的存在,这个方案在重建表的过程中,允许对表A做增删改操作
如果MySQL认为排序的单行长度太大会怎么做呢?
接下来,我来修改一个参数,让MySQL采用另外一种算法。
SET max_length_for_sort_data = 16;
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
第二个例子是隐式类型转换,第三个例子是隐式字符编码转换,它们都跟第一个例子一样,因为要求在索引字段上做函数操作而导致了全索引扫描。
查询事务和锁情况
由于在show processlist的结果里面,session A的Command列是“Sleep”,导致查找起来很不方便。不过有了performance_schema和sys系统库以后,就方便多了。(MySQL启动时需要设置performance_schema=on)
通过查询sys.schema_table_lock_waits这张表,我们就可以直接找出造成阻塞的process id,把这个连接用kill 命令断开即可
select blocking_pid from sys.schema_table_lock_waits;
select * from information_schema.innodb_trx
query_rewrite
Rows_examined
每个线程一个,参数 binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘
bin log 写入策略
write 和fsync的时机,是由参数sync_binlog控制的:
- sync_binlog=0的时候,表示每次提交事务都只write,不fsync;
- sync_binlog=1的时候,表示每次提交事务都会执行fsync;
sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync。
redo log 写入策略
为了控制redo log的写入策略,InnoDB提供了innodb_flush_log_at_trx_commit参数,它有三种可能取值:
设置为0的时候,表示每次事务提交时都只是把redo log留在redo log buffer中;
- 设置为1的时候,表示每次事务提交时都将redo log直接持久化到磁盘;
- 设置为2的时候,表示每次事务提交时都只是把redo log写到page cache。
innodb_log_buffer_size
io性能瓶颈
第一种是“redo log写满了,要flush脏页”,这种情况是InnoDB要尽量避免的。因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住。如果你从监控上看,这时候更新数会跌为0。
第二种是“内存不够用了,要先将脏页写到磁盘”,这种情况其实是常态。InnoDB用缓冲池(buffer pool)管理内存,缓冲池中的内存页有三种状态:
- 第一种是,还没有使用的;
- 第二种是,使用了并且是干净页;
- 第三种是,使用了并且是脏页。
InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少。
而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
所以,刷脏页虽然是常态,但是出现以下这两种情况,都是会明显影响性能的:
- 一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长;
- 日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的。
所以,InnoDB需要有控制脏页比例的机制,来尽量避免上面的这两种情况
如果你的MySQL现在出现了性能瓶颈,而且瓶颈在IO上,可以通过哪些方法来提升性能呢?
针对这个问题,可以考虑以下三种方法:
- 设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count参数,减少binlog的写盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。
- 将sync_binlog 设置为大于1的值(比较常见是100~1000)。这样做的风险是,主机掉电时会丢binlog日志。
- 将innodb_flush_log_at_trx_commit设置为2。这样做的风险是,主机掉电的时候会丢数据。
我不建议你把innodb_flush_log_at_trx_commit 设置成0。因为把这个参数设置成0,表示redo log只保存在内存中,这样的话MySQL本身异常重启也会丢数据,风险太大。而redo log写到文件系统的page cache的速度也是很快的,所以将这个参数设置成2跟设置成0其实性能差不多,但这样做MySQL异常重启时就不会丢数据了,相比之下风险会更小。
mysqlbinlog -vv data/master.000001 —start-position=8900;
show slave status命令,它的返回结果里面会显示seconds_behind_master
semi-sync+
- 如果对group by语句的结果没有排序要求,要在语句后面加 order by null;
- 尽量让group by过程用上表的索引,确认方法是explain结果里没有Using temporary 和 Using filesort;
- 如果group by需要统计的数据量不大,尽量只使用内存临时表;也可以通过适当调大tmp_table_size参数,来避免用到磁盘临时表;
- 如果数据量实在太大,使用SQL_BIG_RESULT这个提示,来告诉优化器直接使用排序算法得到group by的结果。00-select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
基于上面的union、union all和group by语句的执行过程的分析,我们来回答文章开头的问题:MySQL什么时候会使用内部临时表?
- 如果语句执行过程可以一边读数据,一边直接得到结果,是不需要额外内存的,否则就需要额外的内存,来保存中间结果;
- join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构;
- 如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表。比如我们的例子中,union需要用到唯一索引约束, group by还需要用到另外一个字段来存累积计数。

若有收获,就点个赞吧
0 人点赞
