1、创建一个Series对象
import numpy as npimport pandas as pdscore = pd.Series(data=[90,95,85,78,np.NAN,96,94,np.NAN,80,87,86,83],index=range(1,13),name='score')score.index.name = "class"score
class1 90.02 95.03 85.04 78.05 NaN6 96.07 94.08 NaN9 80.010 87.011 86.012 83.0Name: score, dtype: float64
2、查看1-5班的成绩
score[1:5]
class2 95.03 85.04 78.05 NaNName: score, dtype: float64
3、查看哪个班级的成绩没有录入
score[score.isnull()]
class5 NaN8 NaNName: score, dtype: float64
4、获取11班的成绩
score[11]
86.0
5、在每个人的成绩加5分
score + 5
class1 95.02 100.03 90.04 83.05 NaN6 101.07 99.08 NaN9 85.010 92.011 91.012 88.0Name: score, dtype: float64
6、找出成绩在90分以上的班级
score[score > 90]
class2 95.06 96.07 94.0Name: score, dtype: float64
1、创建一个DataFrame
DataFrame:
data = {"姓名":['张三','李四','王五','小明','小红','小刚','小亮'],"语文":[89,78,79,89,90,87,83],"数学":[59,83,85,92,67,81,77],"英语":[84,97,88,83,67,73,71],"体育":[0,0,0,0,0,0,0]}df = pd.DataFrame(data)df
2、进行转置
df.T
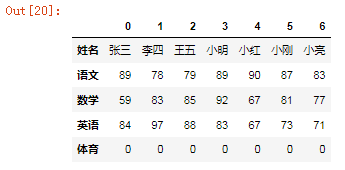
df.transpose()
a = df.transform() #用来干什么的?怎么用
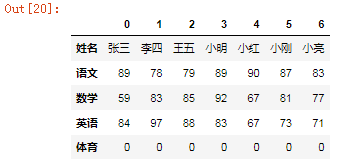
3、删除掉体育成绩
df.drop(['体育'],axis=1)
df.T.drop(['体育'])
del(df['体育'])df
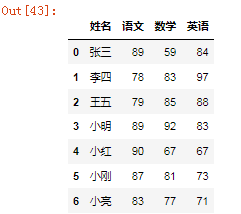
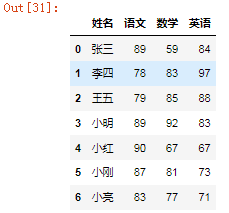
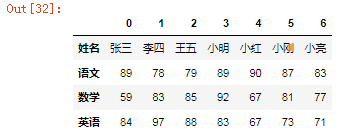
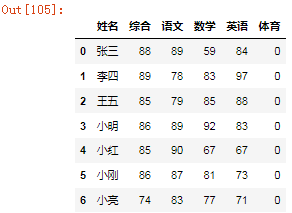
4、新增综合成绩
s = pd.DataFrame({"综合":[88,89,85,86,85,86,74]})s
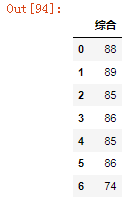
df.T.append(s.T) #这个虽然实现了但是有疑问还需要详细分析
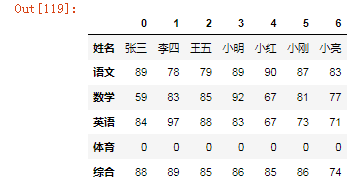
df["综合"]=[88,89,85,86,85,86,74]df
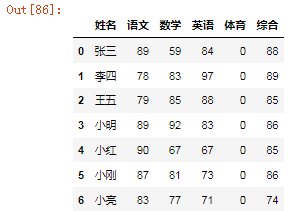
df1 = df.Tdf1
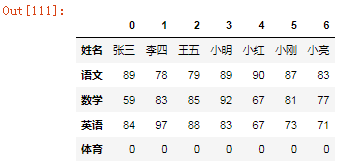
df1.loc["综合"]=[88,89,85,86,85,86,74]df1
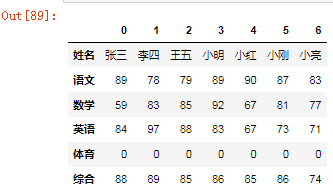
df.insert(1,'综合',[88,89,85,86,85,86,74], allow_duplicates=False)df

若有收获,就点个赞吧
0 人点赞

{kind=link}