本页讨论以分布式方式在各种部署模式下运行Dgraph,并涉及在集群中的多个服务器上运行Dgraph的多个实例。
提示 对于单个服务器设置,建议新用户使用,请参阅快速开始页。
安装Dgraph
Docker
docker pull dgraph/dgraph:latest# 测试它运行是否良好,运行:docker run -it dgraph/dgraph:latest dgraph
自动下载
执行
curl https://get.dgraph.io -sSf | bash# 测试它运行是否良好,运行:dgraph
将dgraph二进制文件安装到您的系统中。
手动下载[可选]
如果您不想遵循自动安装方法,可以从 Dgraph releases 手动下载适用于您平台的tar包。 从Github下载适用于您的平台的tar包后,将二进制文件解压缩到/usr/local/bin目录下。
# 对于Linux系统$ sudo tar -C /usr/local/bin -xzf dgraph-linux-amd64-VERSION.tar.gz# 对于Mac系统$ sudo tar -C /usr/local/bin -xzf dgraph-darwin-amd64-VERSION.tar.gz# 测试它运行是否良好,运行:dgraph
从源码构建
注意 Ratel UI现在是闭源的,因此您无法从源代码构建它。但您可以通过使用上面列出的任何方法安装的Ratel UI连接到Dgraph实例。
Make sure you have Go (version >= 1.8) installed. 确保安装了Go(版本> = 1.8)。
安装Go后,运行
# 你的$GOPATH/bin中安装dgraph二进制文件。go get -u -v github.com/dgraph-io/dgraph/dgraph
If you get errors related to grpc while building them, your go-grpc version might be outdated. We don’t vendor in go-grpc(because it causes issues while using the Go client). Update your go-grpc by running.
如果在构建它们时遇到与grpc相关的错误,那么你的go-grpc版本可能已经过时了。 我们不在go-grpc中供应(因为它在使用Go客户端时会引起问题)。通过运行一下命令更新你的go-grpc。
go get -u -v google.golang.org/grpc
配置
可以通过使用 --help 标志调用dgraph来查看dgraph的配置选项的完整集合(以及简要描述)。例如,为了查看dgraph alpha可用的选项,运行dgraph alpha --help。
可以通过多种方式配置选项(从最高优先级到最低优先级):
使用命令行标志(如帮助输出中所述)。
使用环境变量。
使用配置文件。
如果没有使用选项的配置,--help输出默认值。
可以同时使用多种配置方法。例如,可以在配置文件中设置一组核心选项,同时使用环境变量或命令行标志设置特定于实例的选项。
环境变量名称与标志名称相同,如--help输出中所示。
它们是DGRAPH连接,调用的子命令(ALPHA,ZERO,LIVE或BULK),然后是标志的名称(大写)。 例如,您可以使用DGRAPH_ALPHA_LRU_MB = 8096 dgraph alpha代替dgraph alpha --lru_mb = 8096。
支持的配置文件格式是JSON,TOML,YAML,HCL和Java properties(通过文件扩展名检测)。
可以使用--config标志或环境变量指定配置文件。例如。 dgraph zero --config my_config.json或DGRAPH_ZERO_CONFIG = my_config.json dgraph zero。
配置文件结构只是简单的键值对(与标志名称相同)。 例如。一个JSON配置文件,设置--idx,--peer和--replicas:
{"idx": 42,"peer": 192.168.0.55:9080,"replicas": 2}
集群设置
了解Dgraph集群
Dgraph是一个真正的分布式图形数据库 - 而不是通用数据集的主从复制。 它通过谓词进行分片并在群集中复制谓词,查询可以在任何节点上运行,连接通过分布式数据进行处理。对于节点存储的谓词本地解析查询,并通过分布式连接解析存储在其他节点上的谓词。
为了有效地运行Dgraph集群,了解分片,复制和重新平衡的工作原理非常重要。
分片
Dgraph为每个谓词编写数据( P ,在RDF术语中),因此最小的数据单位是一个谓词。要对graph进行分片,请将一个或多个谓词分配为一组。群集中的每个Alpha节点都服务于一个组。 Dgraph Zero为每个Alpha节点分配一个组。
重新平衡分片
Dgraph Zero尝试根据每个组中的磁盘使用情况重新平衡群集。如果Zero节点检测到不平衡,它将尝试将谓词与索引和反向边一起移动到具有最小磁盘使用量的组。这使谓词暂时不可用。
Zero节点会不断尝试保持每台服务器上的数据量,通常以10分钟的频率运行此检查。因此,每个额外的Dgraph Alpha实例将允许Zero进一步从组中拆分谓词并将它们移动到新节点。
相合复制
如果--replicas标志设置为大于1的值,则Zero节点会将同一组分配给多个节点。 然后,这些节点将形成一个Raft组,即quorum。每次写入都会相合复制到quorum。 为了达成共识,quorum的数量要是奇数。 因此,我们建议将--replicas设置为1,3或5(不是2或4)。这允许服务于同一组的0,1或2个节点分别关闭,而不会影响该组的整体健康状况。
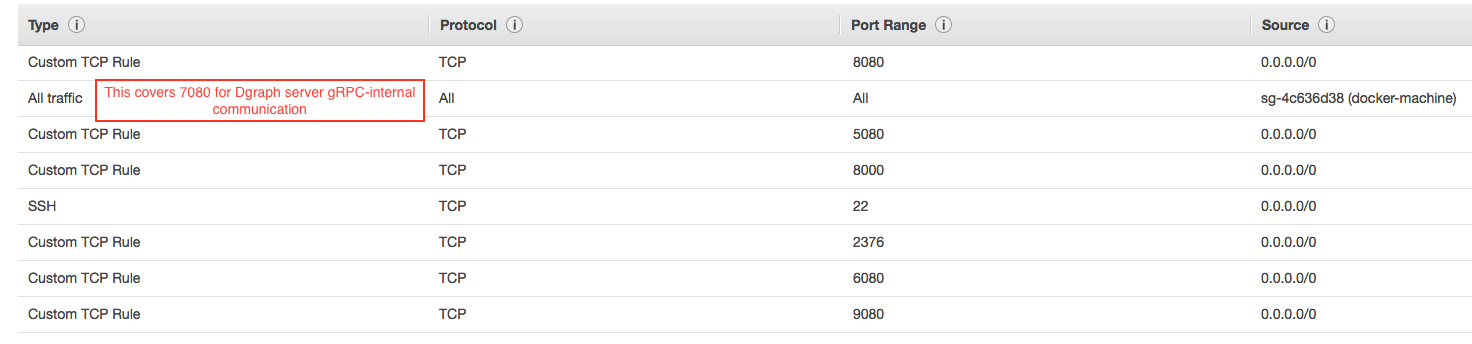
端口使用
Dgraph集群节点使用不同的端口通过GRPC和HTTP进行通信。由于每个端口需要不同的访问安全规则或防火墙,因此用户在选择这些端口时必须注意它们的拓扑结构和部署模式。
端口类型
- gRPC-internal: 在集群节点之间用于内部通信和消息交换的端口。
- gRPC-external: Dgraph客户端,Dgraph Live Loader和Dgraph Bulk loader用于通过gRPC访问API的端口。
- http-external: 客户端用于通过HTTP与其他监控和管理任务访问API的端口。
不同节点使用的端口
| Dgraph节点类型 | gRPC-内部 | gRPC-外部 | HTTP-外部 |
|---|---|---|---|
| zero | —Not Used— | 5080 | 6080 |
| alpha | 7080 | 9080 | 8080 |
| ratel | —Not Used— | —Not Used— | 8000 |
用户必须根据其底层网络修改安全规则或打开防火墙,以允许群集节点之间以及服务器和客户端之间的通信。 在开发期间,一般*-external(gRPC/HTTP)端口规则可以是公开的,gRPC-internal端口在集群节点内是开放的。
Ratel UI 访问http-external端口上的Dgraph Alpha 节点(默认localhost:8080),并且可以配置为与远程Dgraph集群通信。这样,您可以在本地计算机上运行Ratel并指向远程群集。但是如果你要将Ratel和Dgraph集群一起部署,那么你可能不得不向公众公开8000。
Port Offset 为了方便用户设置集群,Dgraph各节点使用默认的端口,并允许用户提供偏移量(通过命令选项--port_offset)来定义节点使用的实际端口。 在高可用集群设置中启动多个zero节点时也可以使用偏移。
例如,当用户通过设置--port_offset 2运行Dgraph Alpha 节点时,Alpha节点分别绑定到7082(gRPC-internal),8082(http-external)和9092(gRPC-external)。
Ratel UI 默认情况下监听端口8000.您可以使用-port标志配置为监听任何其他端口。
提示
对于Dgraph v1.0.2 (或这之后版本)
Zero 节点的默认端口为7080和8080.当按照以下不同设置指南的说明操作时,使用--port_offset覆盖Zero端口以匹配当前的默认端口。
# 使用端口5080和6080运行Zerodgraph zero --idx=1 --port_offset -2000# 使用端口5081和6081运行Zerodgraph zero --idx=2 --port_offset -1999
同样,Ratel的默认端口是8081,因此使用--port将其覆盖到当前默认端口。
dgraph-ratel --port 8080
高可用集群设置
在高可用设置中,我们需要为Zero节点运行3或5个副本,同样地,为Alpha节点运行3或5个副本。
注意 如果副本数量为2K+1,则最多 K个服务器 可以关闭而不会对读取或写入产生任何影响。 避免将副本保持为2K(偶数)。 如果K个服务器出现故障,由于缺乏共识,这会阻止读写操作。
Dgraph Zero 节点
运行三个Zero实例,通过--idx标志为每个实例分配一个唯一的ID(整数),并通过--peer标志传递健康的Zero实例的地址。
要为alpha节点运行三个副本,请设置--replicas = 3。每次添加新的Dgraph Alpha 节点时,Zero 节点都会检查现有的组并将它们分配给一个没有三个副本的组。
Dgraph Alpha 节点
根据需要运行尽可能多的Dgraph Alpha 节点。您可以手动设置--idx标志,或者您可以将该标志留空,Zero节点会自动为Alpha节点分配一个ID。此ID将在写前日志中保留,因此请注意不要删除它。
新的Alpha节点将通过与Zero节点通信来自动检测彼此,并建立相互连接。
Typically, Zero would first attempt to replicate a group, by assigning a new
Dgraph alpha to run the same group as assigned to another. Once the group has
been replicated as per the --replicas flag, Zero would create a new group.
通常,Zero节点会首先尝试复制一个组,方法是指定一个新的Alpha节点去运行指定的另一个相同的组。一旦该组按照--replicas标志复制,Zero节点将创建一个新组。
随着时间的推移,数据将在所有组中均匀分配。因此,确保Dgraph alpha节点的数量是replicas设置的倍数非常重要。 例如,如果在Zero节点中设置--replicas = 3,则运行三个Dgraph alpha节点,不进行分片,而是3x复制。 运行六个Dgraph alphas,将数据分成两组,复制3次。
单主机设置
直接在主机上运行
运行 Dgraph Zero 节点
dgraph zero --my=IPADDR:5080
--my标志是alpha节点与zero节点通话的连接。因此,端口“5080”和IP地址必须对所有Dgraph alpha都可见。
对于所有其他各种标志,运行dgraph zero --help。
运行 Dgraph Alpha 节点
dgraph alpha --lru_mb=<typically one-third the RAM> --my=IPADDR:7080 --zero=localhost:5080dgraph alpha --lru_mb=<typically one-third the RAM> --my=IPADDR:7081 --zero=localhost:5080 -o=1
注意第二个Alpha使用-o来为使用的默认端口添加偏移量。Zero会自动为每个Alpha分配一个唯一ID,该ID保留在写入日志(wal)目录中,用户可以使用--idx选项指定索引。Dgraph Alphas使用两个目录来保存数据和wal日志,如果每个Alpha在同一主机上运行,则这些目录必须不同。 您可以使用-p和-w来更改数据和WAL目录的位置。
对于所有其他标志,运行dgraph alpha --help。
运行 dgraph UI
dgraph-ratel
使用Docker运行
可以将Dgraph集群设置为在单个主机上作为容器运行。首先,您需要确定主机IP地址。你通常可以通过
ip addr # Arch Linux系统上ifconfig # Ubuntu/Mac系统上
我们将通过HOSTIPADDR来引用主机IP地址。
运行 Dgraph Zero
mkdir ~/zero # 或存储数据的任何其他目录。docker run -it -p 5080:5080 -p 6080:6080 -v ~/zero:/dgraph dgraph/dgraph:latest dgraph zero --my=HOSTIPADDR:5080
运行 Dgraph Alpha
mkdir ~/server1 # 或存储数据的任何其他目录。docker run -it -p 7080:7080 -p 8080:8080 -p 9080:9080 -v ~/server1:/dgraph dgraph/dgraph:latest dgraph alpha --lru_mb=<typically one-third the RAM> --zero=HOSTIPADDR:5080 --my=HOSTIPADDR:7080mkdir ~/server2 # 或存储数据的任何其他目录。docker run -it -p 7081:7081 -p 8081:8081 -p 9081:9081 -v ~/server2:/dgraph dgraph/dgraph:latest dgraph alpha --lru_mb=<typically one-third the RAM> --zero=HOSTIPADDR:5080 --my=HOSTIPADDR:7081 -o=1
注意,server2使用-o覆盖server2的默认端口。
运行 dgraph UI
docker run -it -p 8000:8000 dgraph/dgraph:latest dgraph-ratel
使用Docker Compose运行(在单个AWS实例上)
我们将使用Docker Machine。它是一个工具,可让您在虚拟机上安装Docker引擎,并轻松部署应用程序。
- 安装 Docker Machine 在你的机器上。
注意 这些说明适用于在没有TLS配置的情况下运行Dgraph Alpha。 使用TLS运行的说明参考TLS instructions.
Here we’ll go through an example of deploying Dgraph Zero, Alpha and Ratel on an AWS instance. 在这里,我们将通过一个例子在AWS实例上部署Dgraph Zero,Alpha和Ratel。
确保按照instructions中的方式安装了Docker Machine, 在AWS上配置实例只需一步之遥。您必须配置您的AWS凭证才能以编程方式访问Amazon API。
创建一个新的 docker machine.
docker-machine create --driver amazonec2 aws01
输出应该是这样的
Running pre-create checks...Creating machine...(aws01) Launching instance.........Docker is up and running!To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env aws01
该命令将提供一个名为docker-machine的安全组的t2-micro实例(允许在2376和22上进行入站访问)。您可以编辑安全组以允许对5080, 8080, 9080(Dgraph Zero和Alpha的默认端口)的入站访问,或者您可以提供自己的安全组,允许在端口22,2376上进行入站访问(Docker Machine,5080,8080和9080要求。只有从外面运行Dgraph Live Loader或Dgraph Bulk Loader时,才需要记住端口5080
这里 是一个amazonec2驱动程序的完整选项列表,它允许您选择实例类型,安全组,AMI以及许多其他内容。
提示 Docker machine 支持 其他驱动程序,如GCE,Azure等。
- 使用docker-compose安装并运行Dgraph
Docker Compose是一个用于运行多容器Docker应用程序的工具。您可以按照此处的说明进行安装。
将以下文件复制到计算机上的目录中并命名docker-compose.yml.
version: "3.2"services:zero:image: dgraph/dgraph:latestvolumes:- /data:/dgraphports:- 5080:5080- 6080:6080restart: on-failurecommand: dgraph zero --my=zero:5080server:image: dgraph/dgraph:latestvolumes:- /data:/dgraphports:- 8080:8080- 9080:9080restart: on-failurecommand: dgraph alpha --my=server:7080 --lru_mb=2048 --zero=zero:5080ratel:image: dgraph/dgraph:latestports:- 8000:8000command: dgraph-ratel
注意 配置将实例上的/data(你可以挂载别的东西)目录挂载到容器中的/dgraph目录以持久化数据。
- 连接到机器上运行的Docker引擎。
运行docker-machine env aws01告诉我们运行以下命令进行配置我们的shell。
eval $(docker-machine env aws01)
这会将我们的Docker客户端配置为与在AWS机器上运行的Docker引擎进行通信。
最后运行以下命令启动Zero和Alpha。
docker-compose up -d
这将启动3个Docker容器在同一台机器上运行Dgraph Zero,Alpha和Ratel。如果出现任何错误,Docker会重新启动容器。
您可以使用docker-compose logs命令查看日志。
多主机设置
使用Docker Swarm
使用Docker Swarm进行群集设置
注意 这些说明适用于在没有TLS配置的情况下运行Dgraph Alpha。 使用TLS运行的说明参考TLS instructions.
在这里,我们将通过一个例子使用Docker Swarm在复制因子为3的三个不同AWS实例上部署3个Dgraph Alpha节点和1个Zero。
- .确保按照instructions中的方式安装了Docker Machine。
docker-machine --version
- 在AWS上创建3个实例,并在其上安装安装Docker Engine。可以手动完成或使用
docker-machine完成。
您必须配置您的AWS凭证才能使用Docker Machine创建实例。
考虑到您已设置AWS凭据,您可以使用以下命令启动安装了Docker Engine的3个AWSt2-micro实例。
docker-machine create --driver amazonec2 aws01docker-machine create --driver amazonec2 aws02docker-machine create --driver amazonec2 aws03
输出应该是这样的
Running pre-create checks...Creating machine...(aws01) Launching instance.........Docker is up and running!To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env aws01
该命令将提供一个名为docker-machine的安全组的t2-micro实例(允许在2376和22上进行入站访问)。
您需要编辑docker-machine安全组以打开以下端口上的入站流量。
允许源为“docker machine”安全端口的所有端口上的所有入站流量,以便轻松进行与docker相关的通信。
还可以在dgraph要求的以下端口上打开入站TCP流量:
5080、6080、8000、808[0-2]、908[0-2]。请记住,只有从外部运行dgraph live loader或dgraph bulk loader时才需要端口5080。如果您没有打开1中的所有端口,则需要打开“7080”以启用Alpha-to-Alpha的通信。
如果您在AWS上,则在进行必要的更改后,安全组(docker-machine)如下。
这里是一个amazonec2驱动程序的完整选项列表,它允许您选择实例类型,安全组,AMI以及许多其他内容。
提示 Docker machine 支持 其他驱动程序,如GCE,Azure等。
运行docker-machine ps显示我们启动的所有AWS EC2实例。
➜ ~ docker-machine lsNAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORSaws01 - amazonec2 Running tcp://34.200.239.30:2376 v17.11.0-ceaws02 - amazonec2 Running tcp://54.236.58.120:2376 v17.11.0-ceaws03 - amazonec2 Running tcp://34.201.22.2:2376 v17.11.0-ce
- 启动Swarm
Docker Swarm有manager和worker节点。可以在manager节点上启动和更新Swarm。我们将aws01设置为swarm manager。您可以先运行以下命令来初始化swarm。
我们将使用AWS提供的内部IP地址。运行以下命令获取aws01的内部IP。
docker-machine ssh aws01 ifconfig eth0
现在我们有了内部IP,让我们假设172.31.64.18是这种情况下的内部IP。让我们启动Swarm。
# 这会将我们的Docker客户端配置为与在aws01主机上运行的Docker引擎进行通信。eval $(docker-machine env aws01)docker swarm init --advertise-addr 172.31.64.18
输出:
Swarm initialized: current node (w9mpjhuju7nyewmg8043ypctf) is now a manager.To add a worker to this swarm, run the following command:docker swarm join \--token SWMTKN-1-1y7lba98i5jv9oscf10sscbvkmttccdqtkxg478g3qahy8dqvg-5r5cbsntc1aamsw3s4h3thvgk \172.31.64.18:2377To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
现在我们将使其他节点加入swarm。
eval $(docker-machine env aws02)docker swarm join \--token SWMTKN-1-1y7lba98i5jv9oscf10sscbvkmttccdqtkxg478g3qahy8dqvg-5r5cbsntc1aamsw3s4h3thvgk \172.31.64.18:2377
输出:
This node joined a swarm as a worker.
aws03也一样
eval $(docker-machine env aws03)docker swarm join \--token SWMTKN-1-1y7lba98i5jv9oscf10sscbvkmttccdqtkxg478g3qahy8dqvg-5r5cbsntc1aamsw3s4h3thvgk \172.31.64.18:2377
在Swarm manageraws01上,验证你的swarm是否正在运行。
docker node ls
输出:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUSghzapjsto20c6d6l3n0m91zev aws02 Ready Activerb39d5lgv66it1yi4rto0gn6a aws03 Ready Activewaqdyimp8llvca9i09k4202x5 * aws01 Ready Active Leader
- 启动Dgraph集群
将以下文件复制到计算机上的目录中并命名docker-compose.yml
version: "3"networks:dgraph:services:zero:image: dgraph/dgraph:latestvolumes:- data-volume:/dgraphports:- 5080:5080- 6080:6080networks:- dgraphdeploy:placement:constraints:- node.hostname == aws01command: dgraph zero --my=zero:5080 --replicas 3alpha_1:image: dgraph/dgraph:latesthostname: "alpha_1"volumes:- data-volume:/dgraphports:- 8080:8080- 9080:9080networks:- dgraphdeploy:placement:constraints:- node.hostname == aws01command: dgraph alpha --my=alpha_1:7080 --lru_mb=2048 --zero=zero:5080alpha_2:image: dgraph/dgraph:latesthostname: "alpha_2"volumes:- data-volume:/dgraphports:- 8081:8081- 9081:9081networks:- dgraphdeploy:placement:constraints:- node.hostname == aws02command: dgraph alpha --my=alpha_2:7081 --lru_mb=2048 --zero=zero:5080 -o 1alpha_3:image: dgraph/dgraph:latesthostname: "alpha_3"volumes:- data-volume:/dgraphports:- 8082:8082- 9082:9082networks:- dgraphdeploy:placement:constraints:- node.hostname == aws03command: dgraph alpha --my=alpha_3:7082 --lru_mb=2048 --zero=zero:5080 -o 2ratel:image: dgraph/dgraph:latesthostname: "ratel"ports:- 8000:8000networks:- dgraphcommand: dgraph-ratelvolumes:data-volume:
在Swarm leader上运行以下命令以部署Dgraph Cluster。
eval $(docker-machine env aws01)docker stack deploy -c docker-compose.yml dgraph
这样会运行三个Dgraph Alpha服务(由于我们的约束,每个VM上有一个),aws01上有一个Dgraph Zero服务和一个Dgraph Ratel。
这些约束(如compose文件中所示)非常重要,以便在重新启动任何容器时,swarm将相应的Dgraph Alpha或Zero容器放置在同一主机上以重新使用卷。 此外,如果运行的主机少于三台,请确保使用不同的卷或使用-p p1 -w w1选项运行Dgraph Alpha。
注意
此设置将在实例上创建并使用名为dgraph_data-volume的本地卷。如果您计划替换实例,则应使用如cloudstore等远程存储而不是本地磁盘。
您可以通过运行以下命令来验证是否已成功创建所有服务:
docker service ls
输出:
ID NAME MODE REPLICAS IMAGE PORTSvp5bpwzwawoe dgraph_ratel replicated 1/1 dgraph/dgraph:latest *:8000->8000/tcp69oge03y0koz dgraph_alpha_2 replicated 1/1 dgraph/dgraph:latest *:8081->8081/tcp,*:9081->9081/tcpkq5yks92mnk6 dgraph_alpha_3 replicated 1/1 dgraph/dgraph:latest *:8082->8082/tcp,*:9082->9082/tcpuild5cqp44dz dgraph_zero replicated 1/1 dgraph/dgraph:latest *:5080->5080/tcp,*:6080->6080/tcpv9jlw00iz2gg dgraph_alpha_1 replicated 1/1 dgraph/dgraph:latest *:8080->8080/tcp,*:9080->9080/tcp
停止群集运行
docker stack rm dgraph
使用Docker Swarm建立高可用集群
下面是一个示例swarm配置,用于在6个不同的ec2实例上运行6个Dgraph Alpha节点和3个Zero节点。 类似于使用Docker Swarm进行群集设置 除了几处不同。 此设置将确保使用分片数据进行复制。 该文件假定有六个主机可用作docker-machine。 此外,如果您在少于六台主机上运行,请确保使用不同的卷或使用-p p1 -w w1选项运行Dgraph Alpha。
您需要编辑docker-machine安全组以打开以下端口上的入站流量。
允许源为“docker machine”安全端口的所有端口上的所有入站流量,以便轻松进行与docker相关的通信。
还可以在dgraph要求的以下端口上打开入站TCP流量:
5080、8000、808[0-5]、908[0-5]。请记住,只有从外部运行dgraph live loader或dgraph bulk loader时才需要端口5080。如果您没有打开#1中的所有端口,则需要打开“7080”以启用Alpha到Alpha的通信。
如果您在AWS上,下面是经过必要更改后的安全组(docker machine)。
在主机上复制以下文件,并将其命名为docker-compose.yml
version: "3"networks:dgraph:services:zero_1:image: dgraph/dgraph:latestvolumes:- data-volume:/dgraphports:- 5080:5080- 6080:6080networks:- dgraphdeploy:placement:constraints:- node.hostname == aws01command: dgraph zero --my=zero_1:5080 --replicas 3 --idx 1zero_2:image: dgraph/dgraph:latestvolumes:- data-volume:/dgraphports:- 5081:5081- 6081:6081networks:- dgraphdeploy:placement:constraints:- node.hostname == aws02command: dgraph zero -o 1 --my=zero_2:5081 --replicas 3 --peer zero_1:5080 --idx 2zero_3:image: dgraph/dgraph:latestvolumes:- data-volume:/dgraphports:- 5082:5082- 6082:6082networks:- dgraphdeploy:placement:constraints:- node.hostname == aws03command: dgraph zero -o 2 --my=zero_3:5082 --replicas 3 --peer zero_1:5080 --idx 3alpha_1:image: dgraph/dgraph:latesthostname: "alpha_1"volumes:- data-volume:/dgraphports:- 8080:8080- 9080:9080networks:- dgraphdeploy:replicas: 1placement:constraints:- node.hostname == aws01command: dgraph alpha --my=alpha_1:7080 --lru_mb=2048 --zero=zero_1:5080alpha_2:image: dgraph/dgraph:latesthostname: "alpha_2"volumes:- data-volume:/dgraphports:- 8081:8081- 9081:9081networks:- dgraphdeploy:replicas: 1placement:constraints:- node.hostname == aws02command: dgraph alpha --my=alpha_2:7081 --lru_mb=2048 --zero=zero_1:5080 -o 1alpha_3:image: dgraph/dgraph:latesthostname: "alpha_3"volumes:- data-volume:/dgraphports:- 8082:8082- 9082:9082networks:- dgraphdeploy:replicas: 1placement:constraints:- node.hostname == aws03command: dgraph alpha --my=alpha_3:7082 --lru_mb=2048 --zero=zero_1:5080 -o 2alpha_4:image: dgraph/dgraph:latesthostname: "alpha_4"volumes:- data-volume:/dgraphports:- 8083:8083- 9083:9083networks:- dgraphdeploy:placement:constraints:- node.hostname == aws04command: dgraph alpha --my=alpha_4:7083 --lru_mb=2048 --zero=zero_1:5080 -o 3alpha_5:image: dgraph/dgraph:latesthostname: "alpha_5"volumes:- data-volume:/dgraphports:- 8084:8084- 9084:9084networks:- dgraphdeploy:placement:constraints:- node.hostname == aws05command: dgraph alpha --my=alpha_5:7084 --lru_mb=2048 --zero=zero_1:5080 -o 4alpha_6:image: dgraph/dgraph:latesthostname: "alpha_6"volumes:- data-volume:/dgraphports:- 8085:8085- 9085:9085networks:- dgraphdeploy:placement:constraints:- node.hostname == aws06command: dgraph alpha --my=alpha_6:7085 --lru_mb=2048 --zero=zero_1:5080 -o 5ratel:image: dgraph/dgraph:latesthostname: "ratel"ports:- 8000:8000networks:- dgraphcommand: dgraph-ratelvolumes:data-volume:
注意
1. 此设置假定您使用的是6台主机,但如果运行的主机少于6台,则必须在Dgraph alpha之间使用不同的卷,或使用-p和-w配置数据目录。
2. 此设置将在实例上创建并使用名为“dgraph_data-volume”的本地卷。 如果您计划替换实例,则应使用cloudstore等远程存储而不是本地磁盘。
使用 Kubernetes (v1.8.4)
注意 这些说明适用于在没有TLS配置的情况下运行Dgraph Alpha。 使用TLS运行的说明参考TLS指令.
安装kubectl,用于在kubernetes上部署和管理应用程序。
获取kubernetes群集并在您选择的云提供商上运行。您可以使用kops在AWS上进行设置。Kops默认在AWS上进行自动扩展,并为您创建卷和实例。
使用kubectl get nodes验证您的群集已启动并正在运行。 如果您使用带有默认选项的kops,则应准备好主节点和两个工作节点。
➜ kubernetes git:(master) ✗ kubectl get nodesNAME STATUS ROLES AGE VERSIONip-172-20-42-118.us-west-2.compute.internal Ready node 1h v1.8.4ip-172-20-61-179.us-west-2.compute.internal Ready master 2h v1.8.4ip-172-20-61-73.us-west-2.compute.internal Ready node 2h v1.8.4
单服务器
一旦你的Kubernetes集群启动,你可以使用dgraph-single.yaml来启动Zero和Alpha。
- 在您的计算机上,运行以下命令以启动StatefulSet,该StatefulSet创建一个在其中运行Zero和Alpha的Pod。
kubectl create -f https://raw.githubusercontent.com/dgraph-io/dgraph/master/contrib/config/kubernetes/dgraph-single.yaml
输出:
service "dgraph-public" createdstatefulset "dgraph" created
- 确认已成功创建pod。
kubectl get pods
输出:
NAME READY STATUS RESTARTS AGEdgraph-0 3/3 Running 0 1m
注意
您可以使用kubectl logs -f dgraph-0 <container_name>检查容器中容器的日志。例如,尝试使用kubectl logs -f dgraph-0 alpha得到服务器日志。
- 测试设置
从本地机器向pod转发端口
kubectl port-forward dgraph-0 8080kubectl port-forward dgraph-0 8000
转到http://localhost:8000并验证Dgraph是否按预期工作。
注意 您还可以在其外部IP地址上访问该服务。
- 停止群集
删除所有资源
kubectl delete pods,statefulsets,services,persistentvolumeclaims,persistentvolumes -l app=dgraph
停止群集。如果您使用kops,则可以运行以下命令。
kops delete cluster ${NAME} --yes
使用Kubernets进行高可用群集安装
此设置允许您运行3个dgraph alphas和3个dgraph zero。我们用--replicas3标志从zero启动,所有数据都将复制到3个alphas上,形成1个alpha组。
注意 理想情况下,作为kubernetes集群的一部分,您应该至少有三个工作节点,以便每个dgraph alpha运行在单独的节点上。
- 检查属于kubernetes集群的节点。
kubectl get nodes
输出:
NAME STATUS ROLES AGE VERSIONip-172-20-34-90.us-west-2.compute.internal Ready master 6m v1.8.4ip-172-20-51-1.us-west-2.compute.internal Ready node 4m v1.8.4ip-172-20-59-116.us-west-2.compute.internal Ready node 4m v1.8.4ip-172-20-61-88.us-west-2.compute.internal Ready node 5m v1.8.4
一旦您的kubernetes集群启动,就可以使用dgraph-ha.yaml启动集群。
- 在你的机器上,运行以下命令启动集群。
kubectl create -f https://raw.githubusercontent.com/dgraph-io/dgraph/master/contrib/config/kubernetes/dgraph-ha.yaml
输出:
service "dgraph-zero-public" createdservice "dgraph-alpha-public" createdservice "dgraph-alpha-0-http-public" createdservice "dgraph-ratel-public" createdservice "dgraph-zero" createdservice "dgraph-alpha" createdstatefulset "dgraph-zero" createdstatefulset "dgraph-alpha" createddeployment "dgraph-ratel" created
- 确认已成功创建pods。
kubectl get pods
输出:
NAME READY STATUS RESTARTS AGEdgraph-ratel-<pod-id> 1/1 Running 0 9sdgraph-alpha-0 1/1 Running 0 2mdgraph-alpha-1 1/1 Running 0 2mdgraph-alpha-2 1/1 Running 0 2mdgraph-zero-0 1/1 Running 0 2mdgraph-zero-1 1/1 Running 0 2mdgraph-zero-2 1/1 Running 0 2m
提示 您可以使用kubectl logs -f dgraph-alpha-0 和 kubectl logs -f dgraph-zero-0检查容器中容器的日志。
- 测试安装
从本地机器向pod转发端口
kubectl port-forward dgraph-alpha-0 8080kubectl port-forward dgraph-ratel-<pod-id> 8000
转到http://localhost:8000,验证dgraph是否按预期工作。
注意 您还可以在其外部IP地址上访问该服务。
- 停止集群
删除所有资源
kubectl delete pods,statefulsets,services,persistentvolumeclaims,persistentvolumes -l app=dgraph-zerokubectl delete pods,statefulsets,services,persistentvolumeclaims,persistentvolumes -l app=dgraph-alphakubectl delete pods,replicasets,services,persistentvolumeclaims,persistentvolumes -l app=dgraph-ratel
停止集群。如果你使用kops,你可以运行下一个命令。
kops delete cluster ${NAME} --yes
有关dgraph的详细信息
在其HTTP端口上,dgraph alpha公开了许多管理端点。
- 如果工作进程正在运行,则
/health返回HTTP状态代码200和“OK”消息,否则返回HTTP 503。 /admin/shutdown启动alpha正确的 关闭。/admin/export启动数据导出。
默认情况下,alpha在“localhost”上侦听管理操作(loopback地址只能从同一台计算机访问)。--bindall=true选项绑定到“0.0.0.0”,因此允许外部连接。
注意 如果要加载大量数据,请将max文件描述符设置为10000这样的高值。
有关Dgraph Zero的详细信息
dgraph zero控制dgraph集群。它根据每个alpha实例提供的数据大小自动在不同的dgraph alpha实例之间移动数据。
在运行任何dgraph alpha之前,必须至少运行一个dgraph zero节点。运行dgraph zero --help可以看到dgraph zero的选项。
- Zero存储关于集群的信息。
--replicas是控制复制因子的选项。(即每个数据碎片的副本数,包括原始碎片)- 当一个新的alpha加入集群时,它将根据复制因子分配一个组。如果复制因子为1,则每个alpha节点将服务于不同的组。如果复制因子为2,并且您启动了4个alphas,那么前两个alphas将服务于组1,后两个机器将服务于组2。
- Zero还监视每个组中谓词占用的空间,并移动它们以重新平衡集群。
和alpha一样,zero也在6080(+任何--port_offset)上公开HTTP。您可以查询它以查看有用的信息,如下所示:
/state有关作为集群一部分的节点的信息。还包含有关谓词及其所属组的大小的信息。/assignIds?num=100将分配num个id并返回包含startId和endId的JSON映射,两者都包含在内。在数据接收期间,可以将此ID范围安全地分配给外部的新节点。/removeNode?id=3&group=2如果一个复制副本出现故障并且无法恢复,您可以将其删除,并将一个新节点添加到仲裁中。此端点可用于删除死点零或dgraph alpha节点。要删除死掉的零节点,只需传递“group=0”和零节点的ID。
注意 在使用API之前,请确保节点已关闭,并且不会再次恢复。
不应使用与先前删除的节点相同的idx。
/moveTablet?tablet=name&group=2此端点可用于将片到组。Zero已经每8分钟进行一次碎片重新平衡,这个端点可以用来强制移动片。
TLS 配置
注意 本节引用了v1.0.9中引入的 dgraph cert 命令。有关早期版本,请参阅早期的TLS配置文档.
客户端和服务器之间的连接可以通过TLS进行保护。受密码保护的私钥not supported。
注意 如果使用openssl生成加密私钥,请确保显式指定加密算法(如-aes256)。这将强制openssl在私钥中包含DEK-Info头,这是用dgraph解密密钥所必需的。使用默认加密时,openssl不会写入头,无法解密密钥。
自签名证书
dgraph cert程序使用生成的dgraph根CA创建和管理自签名证书。cert命令简化了证书管理。
# 查看可用标志。$ dgraph cert --help# 创建dgraph根CA,用于签署所有其他证书。$ dgraph cert# 创建节点证书(使用tls的dgraph live loader时需要)$ dgraph cert -n live# 创建客户端证书$ dgraph cert -c dgraphuser# 合并一体命令$ dgraph cert -n live -c dgraphuser# 列出所有证书和密钥$ dgraph cert ls
文件命名约定
要启用TLS,必须指定目录路径以查找证书和密钥。cert命令存储证书(和密钥)的默认位置是dgraph工作目录下的tls;在该目录下可以找到数据文件。可以使用--dir选项重写默认的dir路径。
dgraph cert --dir ~/mycerts
dgraph使用以下文件命名约定来正确设置tls。
| 文件名 | 描述 | 使用 |
|---|---|---|
| ca.crt | Dgraph根CA证书 | 验证所有证书 |
| ca.key | Dgraph CA私钥 | 验证CA证书 |
| node.crt | Dgraph节点证书 | 由所有节点共享以接受TLS连接 |
| node.key | Dgraph节点私钥 | 验证节点证书 |
| client.name.crt | Dgraph客户端证书 | 验证客户端 name |
| client.name.key | Dgraph客户端私钥 | 验证 name 客户端证书 |
根CA证书用于验证节点和客户端证书,如果更改,则必须重新生成所有证书。
对于客户端身份验证,每个客户端必须拥有自己的证书和密钥。 然后将它们用于连接到Dgraph节点。
节点证书node.crt可以使用多个主机名和/或IP地址支持多个节点名。 在生成证书时,只需用逗号分隔名称即可。
dgraph cert -n localhost,104.25.165.23,dgraph.io,2400:cb00:2048:1::6819:a417
注意 您必须先删除旧节点证书和密钥,然后才能生成新对。
注意 使用节点证书的主机名(包括localhost)时,客户端必须连接到匹配的主机名 - 例如localhost而不是127.0.0.1。 如果需要使用IP地址,请将它们添加到节点证书中。
证书检查
命令dgraph cert ls列出-dir目录中的所有证书和密钥(默认’tls’),以及检查和验证证书/密钥对的详细信息。
命令输出示例:
-rw-r--r-- ca.crt - Dgraph Root CA certificateIssuer: Dgraph Labs, Inc.S/N: 3e468ac77ecd5017Expiration: 23 Sep 28 19:10 UTCMD5 hash: 85B533D86B0DD689B9DBDAD6755B702F-r-------- ca.key - Dgraph Root CA keyMD5 hash: 85B533D86B0DD689B9DBDAD6755B702F-rw-r--r-- client.srfrog.crt - Dgraph client certificate: srfrogIssuer: Dgraph Labs, Inc.CA Verify: PASSEDS/N: 55cedf3c8606d98eExpiration: 25 Sep 23 19:25 UTCMD5 hash: 445DCB276E29FA1000F79CAC376569BA-rw------- client.srfrog.key - Dgraph Client keyMD5 hash: 445DCB276E29FA1000F79CAC376569BA-rw-r--r-- node.crt - Dgraph Node certificateIssuer: Dgraph Labs, Inc.CA Verify: PASSEDS/N: 75aeb1ccd9a6f3fdExpiration: 25 Sep 23 19:39 UTCHosts: localhostMD5 hash: FA0FFC88F7AA654575CD48A493C3D65A-rw------- node.key - Dgraph Node keyMD5 hash: FA0FFC88F7AA654575CD48A493C3D65A
重点:
- 证书/密钥对应始终具有匹配的MD5哈希值。 否则,必须重新生成证书。 如果根CA对不同,则必须重新生成所有证书/密钥; 标志
--force可以提供帮助。 - 所有证书必须通过Dgraph CA验证。
- 所有密钥文件应具有最少的访问权限,特别是
ca.key,但是必须可读。 - 如果密钥文件的访问权限有限,则不会覆盖密钥文件,即使使用
--force也是如此。 - 节点证书仅对列出的主机有效。
- 客户端证书仅对指定的客户端/用户有效。
TLS选项
Alpha提供以下配置选项:
--tls_dir string- TLS目录路径; 这启用了TLS连接(通常是’tls’)。--tls_use_system_ca- 包含带有Dgraph根CA的系统CA。--tls_client_auth string- 用于验证客户端连接的TLS客户端身份验证。有关详细信息,请参阅客户端身份验证。
# 默认用于启用TLS服务器(生成证书后)$ dgraph alpha --tls_dir tls
Dgraph Live Loader可以配置以下选项:
--tls_dir string- TLS目录路径; 这启用了TLS连接(通常是’tls’)。--tls_use_system_ca- 包含带有Dgraph根CA的系统CA。--tls_server_name string- 服务器名称,用于验证服务器的TLS主机名。
# 首先,为live loader创建客户端证书。 将创建'tls/client.live.crt'文件$ dgraph cert -c live# 现在,使用TLS连接到服务器$ dgraph live --tls_dir tls -s 21million.schema -r 21million.rdf.gz
客户端验证
server选项--tls client auth接受不同的值,这些值会更改客户端证书验证的安全策略。
| 值 | 描述 |
|---|---|
| REQUEST | 服务器接受任何证书,无效和未验证(最不安全) |
| REQUIREANY | 服务器需要任何有效和未经验证的证书 |
| VERIFYIFGIVEN | 如果提供,则验证客户端证书(默认) |
| REQUIREANDVERIFY | 始终需要有效证书(最安全) |
注意 REQUIREANDVERIF是最安全但也是最难配置的远程客户端。 使用此值时,--tls_server_name的值将与证书SAN值和连接主机匹配。
群集检查表
在设置群集时,请确保检查以下各项。
- 是否至少有一个dgraph zero节点正在运行?
- 集群中的每个dgraph alpha实例设置是否正确?
- 7080(+任何端口偏移)上的所有对等端是否都可以访问每个dgraph alpha实例?
- 启动时每个实例都有唯一的ID吗?
- 是否为网络通信设置了
--bindall=true?
快速数据加载
有两种不同的工具可用于快速数据加载:
dgraph live运行 Dgraph Live Loaderdgraph bulk运行 Dgraph Bulk Loader
注意 两种工具都只接受plain或gzipped格式的RDF nQuad/Triple Data。必须转换其他格式的数据。
Live Loader
dgraph live loader(通过dgraph live运行)是一个小的助手程序,它从gzipped文件中读取RDF NQUAD,将其批处理,创建mutation(使用go客户端),然后发送到dgraph。
dgraph live loader可以正确地处理跨多个文件向空节点分配唯一ID的问题,并且可以选择将它们保存到磁盘以节省内存,以防重新运行加载程序。
注意 dgraph live loader可以选择将xid->uid映射写入使用-x标志指定的目录,如果live loader在上一次运行中成功完成,则可以重复使用该标志。
$ dgraph live --help # 查看可用标志。# 从传递的文件中读取RDF,并将它们发送到本地主机9080上的dgraph。$ dgraph live -r <path-to-rdf-gzipped-file># 读取RDF和模式文件并发送到在给定地址运行的dgraph$ dgraph live -r <path-to-rdf-gzipped-file> -s <path-to-schema-file> -d <dgraph-alpha-address:grpc_port> -z <dgraph-zero-address:grpc_port>
Bulk Loader
注意 调优Bulk Loader的标志以获得良好的性能是至关重要的。有关详细信息,请参阅下面的部分。
Dgraph Bulk Loader serves a similar purpose to the Dgraph Live Loader, but can only be used to load data into a new cluster. It cannot be run on an existing live Dgraph cluster. Dgraph Bulk Loader is considerably faster than the Dgraph Live Loader and is the recommended way to perform the initial import of large datasets into Dgraph. Dgraph Bulk Loader的用途与Dgraph live loader类似,但只能用于将数据加载到新集群中。它不能在现有的活动dgraph集群上运行。Dgraph Bulk Loader比Dgraph live loader快得多,是将大型数据集初始导入到Dgraph的推荐方法。
对于批量加载,只应运行一个或多个dgraph zero。稍后将启动dgraph alphas。
警告 在dgraph集群启动并运行后,不要使用批量加载程序。使用它将现有数据导入新群集。
您可以在博客上阅读一些关于bulk loader的技术细节。
有关预期的N-Quads格式的更多信息,请参见快速数据加载。
reduce shards: Before running the bulk load, you need to decide how many Alpha groups will be running when the cluster starts. The number of Alpha groups will be the same number of reduce shards you set with the --reduce_shards flag. For example, if your cluster will run 3 Alpha with 3 replicas per group, then there is 1 group and --reduce_shards should be set to 1. If your cluster will run 6 Alphas with 3 replicas per group, then there are 2 groups and --reduce_shards should be set to 2.
在运行bulk load之前,需要决定集群启动时将运行多少Alpha组。alpha组的数量将与使用--reduce_shards标志设置的reduce shards的数量相同。例如,如果集群将运行3个alpha,每组3个副本,那么有1个组,那--reduce_shards应设置为1。如果集群将运行6个alphas,每组3个副本,那么有2个组,那--reduce_shards应该设置为2。
Map shards: --map_shards选项必须至少设置为--reduce_shards的设置。 较大的数字有助于批量加载程序在reduce分片之间均匀分布谓词。
$ dgraph bulk -r goldendata.rdf.gz -s goldendata.schema --map_shards=4 --reduce_shards=2 --http localhost:8000 --zero=localhost:5080{"RDFDir": "goldendata.rdf.gz","SchemaFile": "goldendata.schema","DgraphsDir": "out","TmpDir": "tmp","NumGoroutines": 4,"MapBufSize": 67108864,"ExpandEdges": true,"SkipMapPhase": false,"CleanupTmp": true,"NumShufflers": 1,"Version": false,"StoreXids": false,"ZeroAddr": "localhost:5080","HttpAddr": "localhost:8000","MapShards": 4,"ReduceShards": 2}The bulk loader needs to open many files at once. This number depends on the size of the data set loaded, the map file output size, and the level of indexing. 100,000 is adequate for most data set sizes. See `man ulimit` for details of how to change the limit.Current max open files limit: 1024MAP 01s rdf_count:176.0 rdf_speed:174.4/sec edge_count:564.0 edge_speed:558.8/secMAP 02s rdf_count:399.0 rdf_speed:198.5/sec edge_count:1.291k edge_speed:642.4/secMAP 03s rdf_count:666.0 rdf_speed:221.3/sec edge_count:2.164k edge_speed:718.9/secMAP 04s rdf_count:952.0 rdf_speed:237.4/sec edge_count:3.014k edge_speed:751.5/secMAP 05s rdf_count:1.327k rdf_speed:264.8/sec edge_count:4.243k edge_speed:846.7/secMAP 06s rdf_count:1.774k rdf_speed:295.1/sec edge_count:5.720k edge_speed:951.5/secMAP 07s rdf_count:2.375k rdf_speed:338.7/sec edge_count:7.607k edge_speed:1.085k/secMAP 08s rdf_count:3.697k rdf_speed:461.4/sec edge_count:11.89k edge_speed:1.484k/secMAP 09s rdf_count:71.98k rdf_speed:7.987k/sec edge_count:225.4k edge_speed:25.01k/secMAP 10s rdf_count:354.8k rdf_speed:35.44k/sec edge_count:1.132M edge_speed:113.1k/secMAP 11s rdf_count:610.5k rdf_speed:55.39k/sec edge_count:1.985M edge_speed:180.1k/secMAP 12s rdf_count:883.9k rdf_speed:73.52k/sec edge_count:2.907M edge_speed:241.8k/secMAP 13s rdf_count:1.108M rdf_speed:85.10k/sec edge_count:3.653M edge_speed:280.5k/secMAP 14s rdf_count:1.121M rdf_speed:79.93k/sec edge_count:3.695M edge_speed:263.5k/secMAP 15s rdf_count:1.121M rdf_speed:74.61k/sec edge_count:3.695M edge_speed:246.0k/secREDUCE 16s [1.69%] edge_count:62.61k edge_speed:62.61k/sec plist_count:29.98k plist_speed:29.98k/secREDUCE 17s [18.43%] edge_count:681.2k edge_speed:651.7k/sec plist_count:328.1k plist_speed:313.9k/secREDUCE 18s [33.28%] edge_count:1.230M edge_speed:601.1k/sec plist_count:678.9k plist_speed:331.8k/secREDUCE 19s [45.70%] edge_count:1.689M edge_speed:554.4k/sec plist_count:905.9k plist_speed:297.4k/secREDUCE 20s [60.94%] edge_count:2.252M edge_speed:556.5k/sec plist_count:1.278M plist_speed:315.9k/secREDUCE 21s [93.21%] edge_count:3.444M edge_speed:681.5k/sec plist_count:1.555M plist_speed:307.7k/secREDUCE 22s [100.00%] edge_count:3.695M edge_speed:610.4k/sec plist_count:1.778M plist_speed:293.8k/secREDUCE 22s [100.00%] edge_count:3.695M edge_speed:584.4k/sec plist_count:1.778M plist_speed:281.3k/secTotal: 22s
默认情况下,输出将在out目录中生成。 以下是上述示例的bulk load输出:
$ tree ./out./out├── 0│ └── p│ ├── 000000.vlog│ ├── 000002.sst│ └── MANIFEST└── 1└── p├── 000000.vlog├── 000002.sst└── MANIFEST4 directories, 6 files
因为--reduce_shards设置为2,所以有两组p目录:一个在./out/0目录中,另一个在./out/1目录中。
创建输出后,可以将它们复制到将运行Dgraph Alphas的所有服务器。 每个Dgraph Alpha必须有自己的组的p目录输出的副本。 第一组的每个副本都应该有自己的./out/0/p副本,第二组的每个副本都应该有自己的副本./out/1/p,依此类推。
调优和监控
性能调优
注意 我们强烈建议您在运行Bulk Loader时使用禁用交换空间。最好修复参数以减少内存使用量,而不是将交换空间用完。
标记可用于控制批量加载程序的行为和性能特征。您可以通过运行dgraph bulk --help来查看完整的列表。特别是,标记应该被调优,这样批量加载程序使用的内存不会超过可用的RAM。如果它开始使用交换空间,它将变得异常缓慢。
在map阶段, 调整以下标志可以减少内存使用:
--num-go-u routines标志控制工作线程的数量。降低内存消耗。--mapoutput_mb标志控制map输出文件的大小。可降低内存消耗。
对于具有多个内核的更大数据集和机器,gzip解码可能是映射阶段的瓶颈。通过首先将RDF分成许多.rdf.gz文件(例如每个256MB),可以获得性能改进。 这对内存使用的影响可以忽略不计。
在reduce阶段, 虽然仍然可以使用很多,但是比map阶段的内存更重 可能会增加一些标志以提高性能,但前提是您有大量RAM:
--reduce_shards标志控制Dgraph alpha实例结果的数量。增加这会增加内存消耗,但在交换中允许更高的CPU利用率。--map_shards标志控制单独映射输出碎片的数量。增加这会增加内存消耗,但会更均匀地平衡生成的dgraph alpha实例结果。--shufflers控制shuffle/reduce阶段的并行度。增加这会增加内存消耗。
监控
Dgraph通过json格式的/debug/vars端点和Prometheus基于文本的格式的/debug/prometheus_metrics端点公开指标。Dgraph不存储指标,只显示该时刻指标的价值。您可以轮询此端点以获取监控系统中的数据,也可以安装Prometheus。使用Dgraph实例的ip替换下面配置文件中的相应的ip,并使用命令prometheus -config.file my_config.yaml运行prometheus。
scrape_configs:- job_name: "dgraph"metrics_path: "/debug/prometheus_metrics"scrape_interval: "2s"static_configs:- targets:- 172.31.9.133:6080 #For Dgraph zero, 6080 is the http endpoint exposing metrics.- 172.31.15.230:8080- 172.31.0.170:8080- 172.31.8.118:8080
注意 Prometheus导出的原始数据可通过Dgraph alphas上的/debug/prometheus_metrics端点获得。
安装Grafana绘制指标。Grafana在默认设置下在端口3000运行。按照这些步骤创建prometheus数据源。按照link导入grafana_dashboard.json。
指标
Dgraph指标遵循Prometheus的指标和标签约定。
磁盘指标
通过磁盘指标,您可以跟踪Dgraph流程的磁盘活动。Dgraph不直接与文件系统交互。相反,它依赖于Badger来读取和写入磁盘。
| 指标 | 描述 |
|---|---|
badger_disk_reads_total |
Badger中的磁盘读取总数。 |
badger_disk_writes_total |
Badger中磁盘写入的总数。 |
badger_gets_total |
调用Badger的get的总次数。 |
badger_memtable_gets_total |
对Badger的“get”的记忆访问总数。 |
badger_puts_total |
对Badger的put的调用总数。 |
badger_read_bytes |
从Badger读取的总字节数。 |
badger_written_bytes |
写入Badger的总字节数。 |
内存指标
内存指标可让您跟踪Dgraph流程的内存使用情况。空闲和使用指标使您可以更好地了解Dgraph进程的活动内存使用情况。进程内存度量标准显示操作系统测量的内存使用情况。
通过查看所有三个指标,您可以看到Dgraph流程从操作系统中保留了多少内存以及正在使用多少内存。
| 指标 | 描述 |
|---|---|
dgraph_memory_idle_bytes |
可以由操作系统回收的估计空闲内存量。 |
dgraph_memory_inuse_bytes |
总内存使用量(堆使用量和堆栈使用量之和)以字节为单位。 |
dgraph_memory_proc_bytes |
Dgraph进程的总内存使用量(以字节为单位)。在Linux/macOS上,此度量标准等同于驻留集大小。在Windows上,此度量标准等同于Go的runtime.ReadMemStats。 |
LRU 缓存指标
通过LRU缓存指标,您可以跟踪发布列表缓存的使用情况。
You can track dgraph_lru_capacity_bytes, dgraph_lru_evicted_total, and dgraph_max_list_bytes (see the Data Metrics) to determine if the cache size should be adjusted. A high number of evictions can indicate a large posting list that repeatedly is inserted and evicted from the cache due to insufficient sizing. The LRU cache size can be tuned with the option --lru_mb.
您可以跟踪dgraph_lru_capacity_bytes,dgraph_lru_evicted_total和dgraph_max_list_bytes(参见数据指标)以确定是否应调整缓存大小。大量驱逐可能表示由于大小不足而重复插入并从缓存中逐出的大型发布列表。可以使用选项--lru_mb调整LRU高速缓存大小。
| 指标 | 描述 |
|---|---|
dgraph_lru_hits_total |
在Dgraph中发布列表的缓存命中总数。 |
dgraph_lru_miss_total |
在Dgraph中发布列表的缓存未命中总数。 |
dgraph_lru_race_total |
在Dgraph中获取发布列表时的缓存竞赛总数。 |
dgraph_lru_evicted_total |
从LRU缓存中收回的投递列表总数。 |
dgraph_lru_capacity_bytes |
LRU缓存的当前大小。最大值应该接近--lru_mb指定的大小。 |
dgraph_lru_keys_total |
LRU缓存中的密钥总数。 |
dgraph_lru_size_bytes |
LRU缓存的大小(以字节为单位)。 |
数据指标
通过该数据,您可以跟踪投递列表存储。
| 指标 | 描述 |
|---|---|
dgraph_max_list_bytes |
最大投递列表大小(字节)。 |
dgraph_max_list_length |
到目前为止,投递列表中的投递最多数量。 |
dgraph_posting_writes_total |
投递列表写入磁盘的总数。 |
dgraph_read_bytes_total |
从Dgraph读取的总字节数。 |
活动指标
通过活动指标,您可以跟踪Dgraph实例的mutation,query和proposal。
| 指标 | 描述 |
|---|---|
dgraph_goroutines_total |
目前在Dgraph中运行的Goroutines总数。 |
dgraph_active_mutations_total |
当前正在运行的mutation总数。 |
dgraph_pending_proposals_total |
总悬而未决的Raft提案。所有待执行的Raft proposal。 |
dgraph_pending_queries_total |
正在进行的query总数。 |
dgraph_num_queries_total |
在Dgraph中运行的查询总数。 |
健康指标
通过健康指标,您可以跟踪以检查Dgraph Alpha实例的可用性。
| 指标 | 描述 |
|---|---|
dgraph_alpha_health_status |
仅适用于Dgraph Alpha。 当Alpha准备好接受请求时,值为1; 否则为0。 |
Go 指标
Go的内置指标也可用于衡量内存使用和垃圾收集时间。
| 指标 | 描述 |
|---|---|
go_memstats_gc_cpu_fraction |
自程序启动以来GC使用的该程序可用CPU时间的一小部分。 |
go_memstats_heap_idle_bytes |
等待使用的堆字节数。 |
go_memstats_heap_inuse_bytes |
正在使用的堆字节数。 |
没有过的指标
| 指标 | 描述 |
|---|---|
dgraph_dirtymap_keys_total |
没用过。 |
dgraph_posting_reads_total |
没用过。 |
Dgraph管理
每个Dgraph Alpha都通过HTTP公开管理操作以导出数据并执行干净退出。
白名单管理员操作
默认情况下,只能从运行Dgraph Alpha的计算机启动管理操作。您可以使用--whitelist选项为可以启动管理操作的主机指定列入白名单的IP地址和范围。
dgraph alpha --whitelist 172.17.0.0:172.20.0.0,192.168.1.1 --lru_mb <one-third RAM> ...
这将允许来自IP为172.17.0.0和172.20.0.0的主机以及IP地址为192.168.1.1的服务器进行管理操作。
Alter操作安全
客户端可以使用alter操作来应用架构更新,并从数据库中删除特定或所有谓词。默认情况下,允许所有客户端执行alter操作。您可以将Dgraph配置为仅在客户端提供特定令牌时允许更改操作。这可用于防止客户端进行意外或意外的架构更新或谓词丢弃。
您可以为群集中的每个Dgraph Alpha指定带有--auth_token选项的身份验证令牌。客户端必须包含相同的身份验证令牌才能生成alter请求。
dgraph alpha --lru_mb=2048 --auth_token=<authtokenstring>
$ curl -s localhost:8080/alter -d '{ "drop_all": true }'# Permission denied. No token provided.
$ curl -s -H 'X-Dgraph-AuthToken: <wrongsecret>' localhost:8180/alter -d '{ "drop_all": true }'# Permission denied. Incorrect token.
$ curl -H 'X-Dgraph-AuthToken: <authtokenstring>' localhost:8180/alter -d '{ "drop_all": true }'# Success. Token matches.
注意 要完全保护群集中的alter操作,必须为每个Alpha设置身份验证令牌。
导出数据
通过本地访问群集中任何Alpha的导出端点来启动所有节点的导出。
curl localhost:8080/admin/export
注意 默认情况下,如果从运行Dgraph Alpha的服务器外部调用,则无效。 您可以使用dgraph alpha上的--whitelist标志指定列表或列入白名单的IP地址,从中可以启动导出或其他管理操作。
这也适用于浏览器,前提是HTTP GET是从运行Dgraph alpha实例的同一服务器运行的。
注意 将仅在作为组的领导者而不是关注者的服务器上创建导出文件。
这会触发导出遍布整个群集的所有组。组的每个Alpha领导者将输出作为gzip压缩RDF文件写入由--export启动时指定的导出目录。如果任何组失败,则认为整个导出过程失败并返回错误。
注意 用户可以从群集中的Alpha中检索正确的导出文件。Dgraph不会将文件复制到启动导出的Alpha。
关掉数据库
通过在该节点上运行以下命令来启动单个Dgraph节点的干净退出。 警告 如果从运行Dgraph的服务器外部调用,则无效。
curl localhost:8080/admin/shutdown
这将停止执行命令的Alpha,而不是整个群集。
删除数据库
可以删除单个三元组,三元组和谓词的模式,如query languge docs中所述。
要删除所有数据,您可以向/alter端点发送DropAll请求。
或者,您可以:
- 停止Dgraph等待所有写入完成,然后删除(可能需要先导出)
p和w目录,然后重启Dgraph。
升级数据库
定期导出总是一个好主意。 如果您希望升级Dgraph或重新配置群集的分片,这将特别有用。以下是安全导出和重启的正确步骤。
- 开始导出
- 确保成功
- 停下集群
- 使用新数据目录运行Dgraph。
- 通过bulk loader重新加载数据。
- 如果一切看起来都不错,你可以删除旧目录(导出用作保险)
这些步骤是必要的,因为Dgraph的基础数据格式可能已更改,并且重新加载导出可避免编码不兼容性。
安装后
现在Dgraph已启动并运行,要了解如何向Dgraph添加和查询数据,请参考查询语言规范。 另外,看看常见问题。
故障排除
以下是您可能遇到的一些问题以及尝试的一些解决方案。
Running OOM (内存不足)
在bulk loading期间,由于写入量很大,Dgraph会比平时消耗更多内存。通常当你看到OOM崩溃。
台式机和笔记本电脑上推荐的最小RAM为16GB。 Dgraph最多可以占用7-8 GB,默认设置为--lru_mb设置为4096; 所以剩下8GB的桌面应用程序应该让你的机器保持嗡嗡声。
在EC2/GCEE实例上,建议的最小值为8GB。 建议将--lru_mb设置为RAM大小的三分之一。
您还可以通过设置--badger.vlog=disk来减少Dgraph的内存使用量。
Too many open files
如果您看到日志错误消息显示too many open files,则应增加每进程文件描述符限制。
在正常操作期间,Dgraph必须能够打开许多文件。默认情况下,您的操作系统可能会设置一个低于数据库(如Dgraph)所需的打开文件描述符限制。
在Linux和Mac上,您可以使用ulimit -n -H检查文件描述符限制的硬限制,并使用ulimit -n -S检查软限制。软限制应设置得足够高,以使Dgraph正常运行。软限制65535是生产设置的良好下限。您可以根据需要调整限制。
也可以看看

若有收获,就点个赞吧
0 人点赞
