Redis内置数据结构
说明: Redis数据库里每个键值对都是由对象构成。其中键总是字符串对象,值可以为字符串对象(string),列表对象(list),集合对象(set),有序集合对象(sortSet),Hash对象(hash)。那这些对象在Redis中所使用的底层数据结构是什么,本章重点去阐述Redis内置数据结构。
简单动态字符串
Redis没有直接使用C语言传统的字符串,而是自己构建了一种名为简单动态字符串的抽象类型。以下简称SDS。 举个栗子,客户端执行以下命令:
redis> SET msg hello
Redis数据库中会存两个字符串对象,底层分别是保存的字符串”msg”,”hello”的两个SDS。
SDS的定义
struct sdshdr {// sds的长度int len;// buf[]中未使用空间int free;// 字节数组,用于保存字符串char buf[];}复制代码
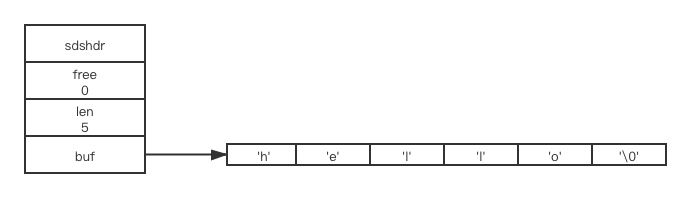
SDS与普通C语言字符串
C语言字符串使用长度为N+1的字符串数组来表示长度为N的字符串,并且字符串最后一个元素总为 ‘/0’;SDS在C字符串基础上加了free和len属性,下文便分析SDS相较于C字符串的优势。
常数复杂度获取字符串长度
普通C字符串获取字符长度,需要从字符数组遍历到队尾,时间复杂度为O(N)。SDS因为有len属性,获取字符长度只需读取len的值就可,时间复杂度为O(1)。所以,客户端使用STRLEN命令获取字符串的长度,不会对性能造成任何影响。
杜绝缓存溢出
C语言字符串S1在修改字符串值时,若没有为S1分配足够的空间,会造成缓存溢出。 如S1,S2在内存中紧邻着,S1保存着”yes”字符串,S2保存着”no”字符串。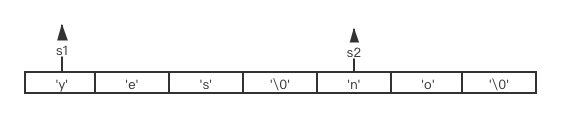
现将S1字符串修改为”yessss”,若此时程序猿之前没有为S1分配足够的空间,那木就会出现如下情况。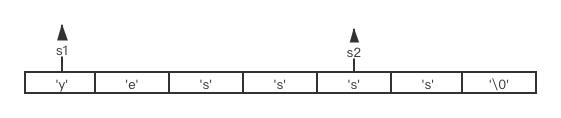
s1的内容溢出到S2的位置了。但SDS不会出现这种情况,SDS在扩容时,会去检查free的容量是否支撑此次扩容操作。若不支持,则会先进行内存分配,自动扩充到所需大小。
减少修改字符串时带来的内存重分配次数
正如上文说的,C语言每次对字符串进行修改操作,都会涉及到内存重分配。但Redis作为数据库,经常被用于数据频繁修改,若每一次修改都需要进行内存重分配,会大大影响性能。而SDS通过引入free这一属性,来解决这个问题。
空间预分配
当对SDS进行修改操作,新的字符串长度n大于原来字符串数组长度,且小于1mb。那木在修改后,新的SDS的字符数组长度为2*n。此时,SDS字符串数组中有len的长度未使用,则free = len,len = n; 举个栗子: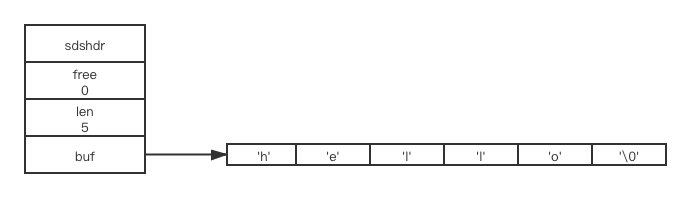 现要将”hello”修改为”hello-world”,此时SDS进行一次内存重分配。按照上面的规则,修改后的字符串为11个字节,那木会分配22字节(此时不考虑后面的‘\0’),额外预留了11字节。
现要将”hello”修改为”hello-world”,此时SDS进行一次内存重分配。按照上面的规则,修改后的字符串为11个字节,那木会分配22字节(此时不考虑后面的‘\0’),额外预留了11字节。 如果接下来,将”hello-world”修改为”hello-world11”,则此时可以直接使用预留的空间,从而不用去重新内存分配。
如果接下来,将”hello-world”修改为”hello-world11”,则此时可以直接使用预留的空间,从而不用去重新内存分配。
惰性空间释放
当将”hello-world”修改为”hello”时,Redis不会主动去释放多余的内存空间,将多余的内存空间的大小写到free属性中。这样做的原因是释放内存空间也需要性能消耗,并且下次可能还会对字符串进行扩容操作。尽管如此,Redis也提供了相应的API对惰性空间进行释放。
链表
Redis没有使用C语言内置的链表数据结构,构建了自己的链表实现。
链表节点实现如下:
struct listNode{// 前置节点struct listNode *prev;// 后置节点struct listNode *next;// 节点值void *value;}listNode;
链表实现如下:**
struct list{// 表头节点listNode *head;// 表尾节点listNode *tail;// 节点数量long len;......}list;
可以看出,Redis内置的链表结构是一个包含链表长度,拥有双端的双向链表。因为双向链表过于常见,所以总结如下:
字典
字典作为一种数据结构,Redis构建了自己的字典实现。 举个栗子,执行如下命令:
在数据库中创建一个键值对,这个键值对就是保存在代表数据库的字典里面。除了数据库外,字典也是Hash键(Redis对外提供的数据结构)的底层实现。 字典底层是用Hash表实现,数据结构如下:
struct dict{// 类型特定函数dictType *type;// 私有数据void *privdata;// 2张hash表dictht ht[2];...}dict;
重点关注hash表,是存放数据的数据结构,如下,是一个普通的字典,存了两个键值对: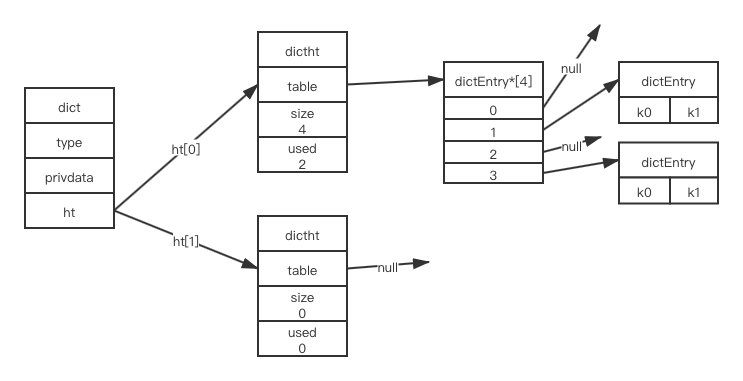
此处解释一下,字典中包含了两个hash表,但字典只会使用其中一个ht[0],ht[1]只会在ht[0]进行rehash时使用。hash表结构简单介绍下:
struct dictht{// 哈希表数组dictEntry **table;// 哈希表大小long size;// 哈希表大小掩码,用于计算索引long sizemask;// 哈希表节点数long used;}dictht;
当发生hash冲突时,hash表使用链地址法解决。若在来一个键k3,计算索引,发现位于位置1,但此时位置1已有数据k1,则放置在k1后。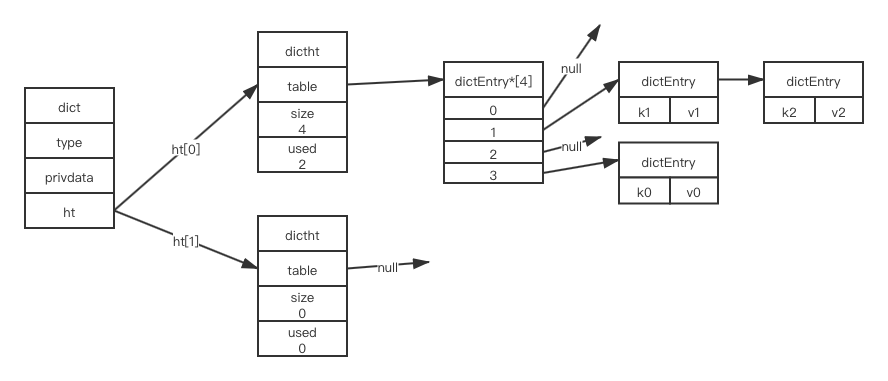
跳跃表
跳跃表是很重要的数据结构,在大部分情况下,可以和平衡树相媲美。Redis使用跳跃表作为有序集合键(对外提供的sortSet数据结构)的底层实现。 举个栗子,客户端执行如下命令
redis 127.0.0.1:6379> ZADD skip 1 key1(integer) 1redis 127.0.0.1:6379> ZADD skip 2 key2(integer) 1redis 127.0.0.1:6379> ZADD skip 3 key3(integer) 1
那木数据库会生成一个跳跃表来存放上述的数据(skip 是字符串键,所以不存在跳跃表里)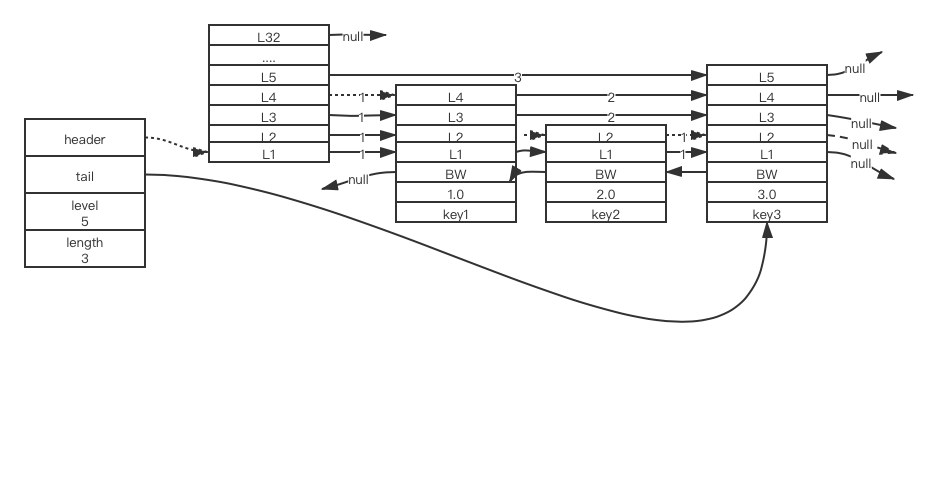
跳跃表结构如上图,拥有头尾节点,节点数量,节点的最高层数(除去头节点),节点按从小到大排列。下文变分析其中的结构。
跳跃表节点
struct zskiplistNode{// 后退指针struct zskiplistNode *backward;// 分值double score;// 成员对象robj *obj;// 层结构struct zskiplistLevel{// 前进指针struct zskiplistNode *forward;// 跨度unsigned int span;} level[]}zskiplistNode复制代码
层
每次存入一个带有分值的值时,会创建一个跳跃表节点。创建跳跃表节点时,程序会根据幂次定律随机生成一个1-32间的值作为level数组的大小,这个大小就是层的高度。上图分别展示了3个高度为4层,2层,5层的节点(头节点32层,不存任何数据)
前进指针
每个层都有一个指向表尾方向的前进指针(level[i].forward),用于从表头向表尾方向访问节点。 上图虚线表示访问跳跃表所以节点的过程。
- 先访问表头节点,然后从第四层的前进指针移动到表中的第二个节点。
- 在第二个节点时,程序沿着第二层的前进指针移动到表中第三个节点。
- 在第三个节点时,程序同样沿着第二层的前进指针移动到表中第四个节点。
- 当程序沿着第四个节点的前进指针访问,碰到NULL,代表已经访问结束,结束遍历。
跨度
层的跨度用于记录两个节点之间的距离。两个节点之间跨度越大,他们就相距越远。跨度是用来干嘛的了?是用来计算排位的:在查找某个节点的过程中,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳跃表中的排位。 举个栗子,还是上图,要找key3在跳跃表中的排位(即排在第几位)那木在头节点中的第5层前进指针直接指向key3,只经过一个层就可以得到了。跨度为3,则代表key3在跳跃表中的位数是第三位。后退指针
节点可以通过后退指针反向遍历跳跃表。但后退指针只能访问它的前节点。这点与前进指针不同。分值和成员
节点的分值是一个double型的浮点数。跳跃表所有节点都按照从小到大排列。在同一个跳跃表中,各个节点保存的成员对象必须唯一,但分值可以想同。结语
Redis内置了很多的数据结构,本文只是介绍了平常经常使用的类型。后续想把更多的篇幅留给Redis数据库的实现。任重而道远,还是想写好这个系列。 如果对mybatis感兴趣可以移步我的github,觉得好的话麻烦点个赞。
作者:小冰超人
链接:https://juejin.cn/post/6895276182049128456
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
