innodb为聚簇索引中每条记录添加额外两个字段,最大事务id和回滚段指针,历史记录通过回滚段指针连接起来,通过视图实现不同隔离级别以及一致性读,也就是mvcc
对于 InnoDB ,聚簇索引记录中包含 3 个隐藏的列:
- ROW ID:隐藏的自增 ID,如果表没有主键,InnoDB 会自动按 ROW ID 产生一个聚集索引树。
- 事务 ID:记录最后一次修改该记录的事务 ID。
- 回滚指针:指向这条记录的上一个版本。
我们拿上面的例子,对应解释下 MVCC 的实现原理,如下图: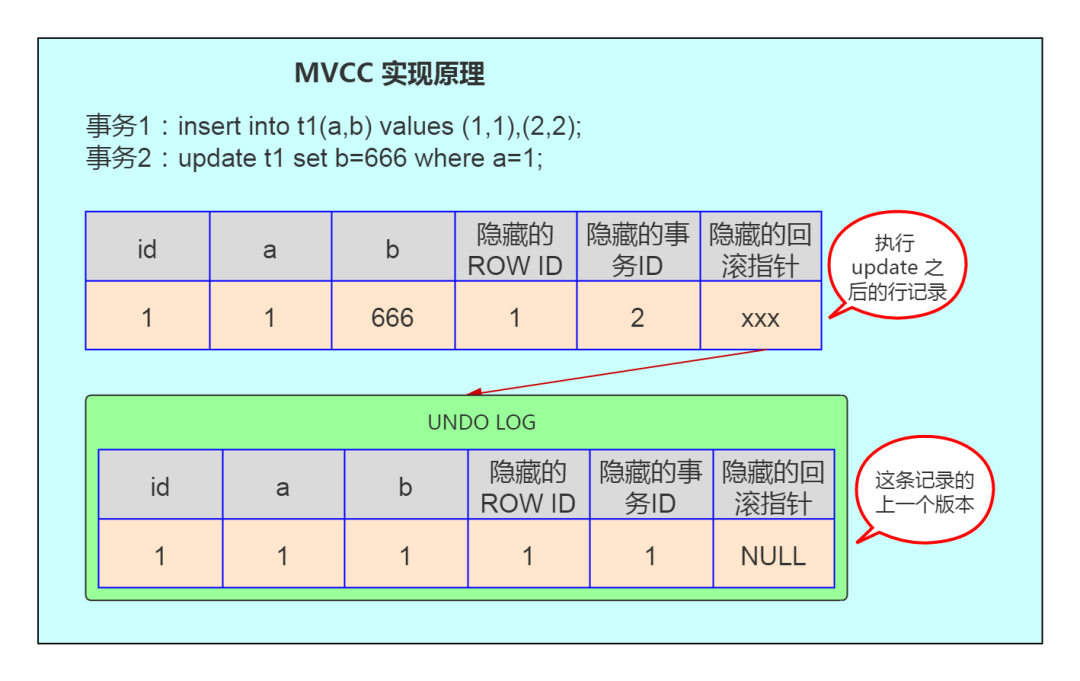
如图,首先 insert 语句向表 t1 中插入了一条数据,a 字段为 1,b 字段为 1, ROW ID 也为 1 ,事务 ID 假设为 1,回滚指针假设为 null。当执行 update t1 set b=666 where a=1 时,大致步骤如下:
- 数据库会先对满足 a=1 的行加排他锁;
- 然后将原记录复制到 undo 表空间中;
- 修改 b 字段的值为 666,修改事务 ID 为 2;
- 并通过隐藏的回滚指针指向 undo log 中的历史记录;
- 事务提交,释放前面对满足 a=1 的行所加的排他锁。
在前面实验的第 6 步中,session2 查询的结果是 session1 修改之前的记录,这个记录就是来自 undolog 中。
因此可以总结出 MVCC 实现的原理大致是:
InnoDB 每一行数据都有一个隐藏的回滚指针,用于指向该行修改前的最后一个历史版本。这个历史版本存放在undolog中。如果要执行更新操作,会将原记录放入 undo log 中,并通过隐藏的回滚指针指向 undo log 中的原记录。其它事务此时需要查询时,就是查询 undo log 中这行数据的最后一个历史版本。
MVCC 最大的好处是读不加锁,读写不冲突,极大地增加了 MySQL 的并发性。通过 MVCC,保证了事务 ACID 中的隔离性特性。
mvcc作用就是降低读写冲突带来的消耗,体现就是读数据的时候如果读不了最新值可以去读以前版本的。根据隐藏的列来判断当前事务的可见性,如果事务id不可见,通过undolog读取上一个版本数据,直到有一个版本数据记录的事务id<当前事务id即可见。然后判断的时候其实是用快照,rc和rr的区别就是生成快照的规则不同。
主要靠ReadView和Undo log。
RC和RR隔离级别是利用consistent read view方式支持的。在某一时刻(比如一次查询)给事务系统trx_sys打snapshot,把当时trx_sys状态记下来,之后的所有读操作根据其事务ID(即trx_id)与snapshot中的trx_sys的状态表作比较,以此判断read view对于事务的可见性。
关键的几个状态low_limit_id,up_limit_id,low_limit_no,控制事物对于View的可见性和能否被purge。
Undolog没啥好说的,存储老版本数据,从数据行的回滚指针找到第一条数据,当一个旧的事务需要读取数据时,顺着undolog链找到满足其可见性的记录。

若有收获,就点个赞吧
0 人点赞
