HTTP协议用于客户端和服务器端之间的通信,请求访问具体资源的一方为客户端,提供资源响应的一方为服务器端。
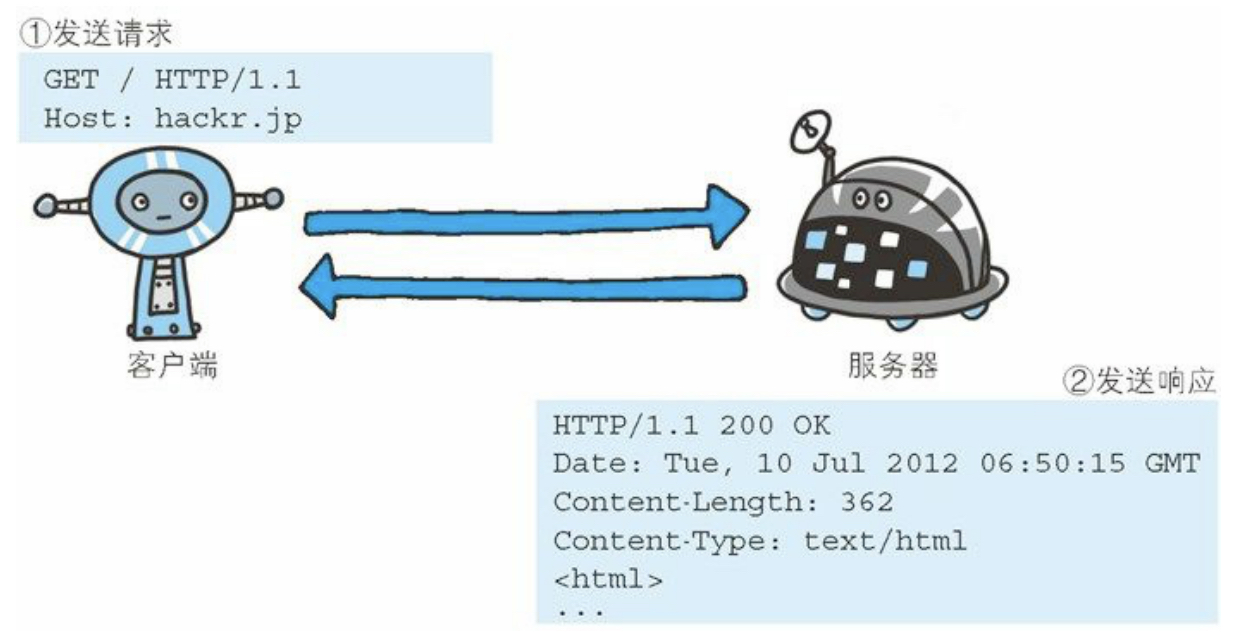
HTTP是一种不保存状态,即无状态的协议。HTTP协议自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个级别,协议对于发送过的请求或响应都不做持久化处理。每当有新的请求发送时,就会产生对应的新响应。
之所以HTTP是无状态的,是为了更快的处理大量事务,确保协议的可伸缩性。
一、HTTP客户端请求
客户端发送给服务器端的请求报文内容格式为: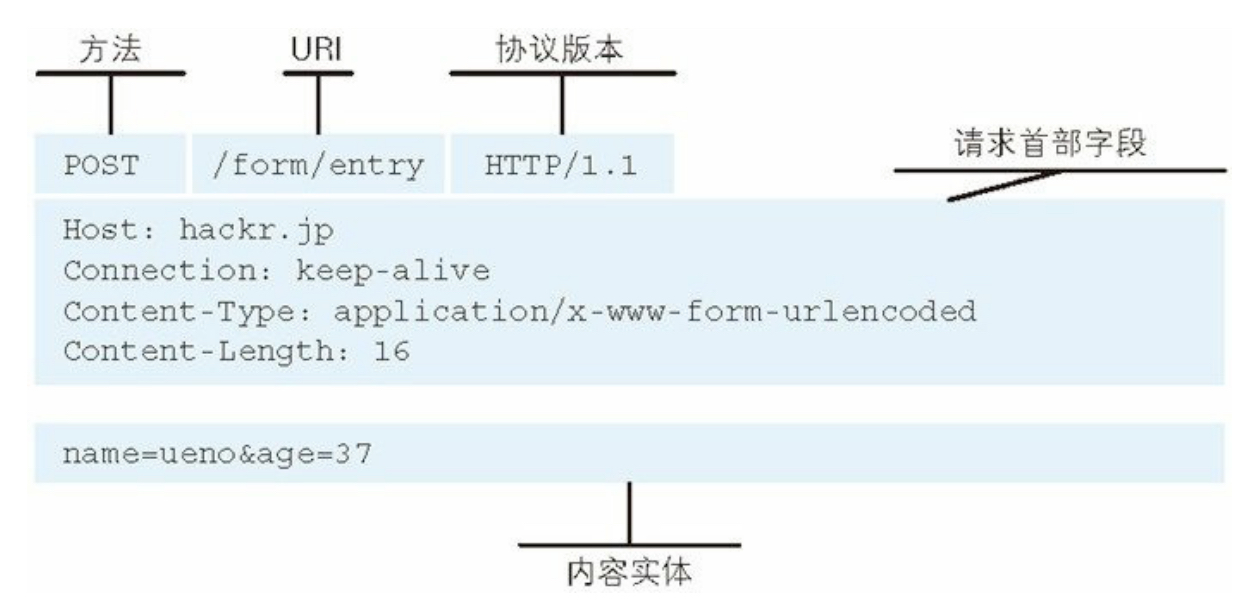
其中,起始行的GET表示请求服务器的方法,/about.html 表示请求的资源对象,也称为request-uri。最后的HTTP/1.1 表示HTTP的版本号。
请求报文由请求方法、请求URI、协议版本、可选的请求首部字段和内容实体构成。
1.1、HTTP中的请求方法
| 方法 | 简介 |
|---|---|
| GET | 获取资源 |
| POST | 传输实体主体 |
| PUT | 传输文件 |
| HEAD | 获得报文头部 |
| DELETE | 删除文件 |
| OPTIONS | 询问支持的方法 |
HTTP请求方法中,最常用的是GET和POST。
其中:
GET为从指定的资源请求数据
POST为向指定的资源请求要被处理的数据
至于其他的方法,一般用的不多:
HEAD:与GET类似,但只返回HTTP报头,不返回响应主体;
PUT:用来传输文件,但是PUT方法本身不带验证机制,存在安全性问题,一般不会放开该方法。但是如果使用RESTful风格设计请求,那么可能会放开该方法;
DELETE:删除指定资源,和PUT类似,由于本身不带验证机制,存在安全性问题。
二、持久连接keep-alive
当打开一个页面时,会请求多个资源,HTTP会发送多个请求,重复建立TCP连接,产生大量的通信开销。为了解决TCP连接问题,在HTTP1.1和一部分HTTP1.0中引入了持久连接的机制,即keep-alive。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持TCP连接状态。持久连接的好处在于减少了TCP连接的重复建立和断开所造成的额外开销,减轻了服务器的负载。这样HTTP请求和响应都能更快的完成,提高页面的响应速度。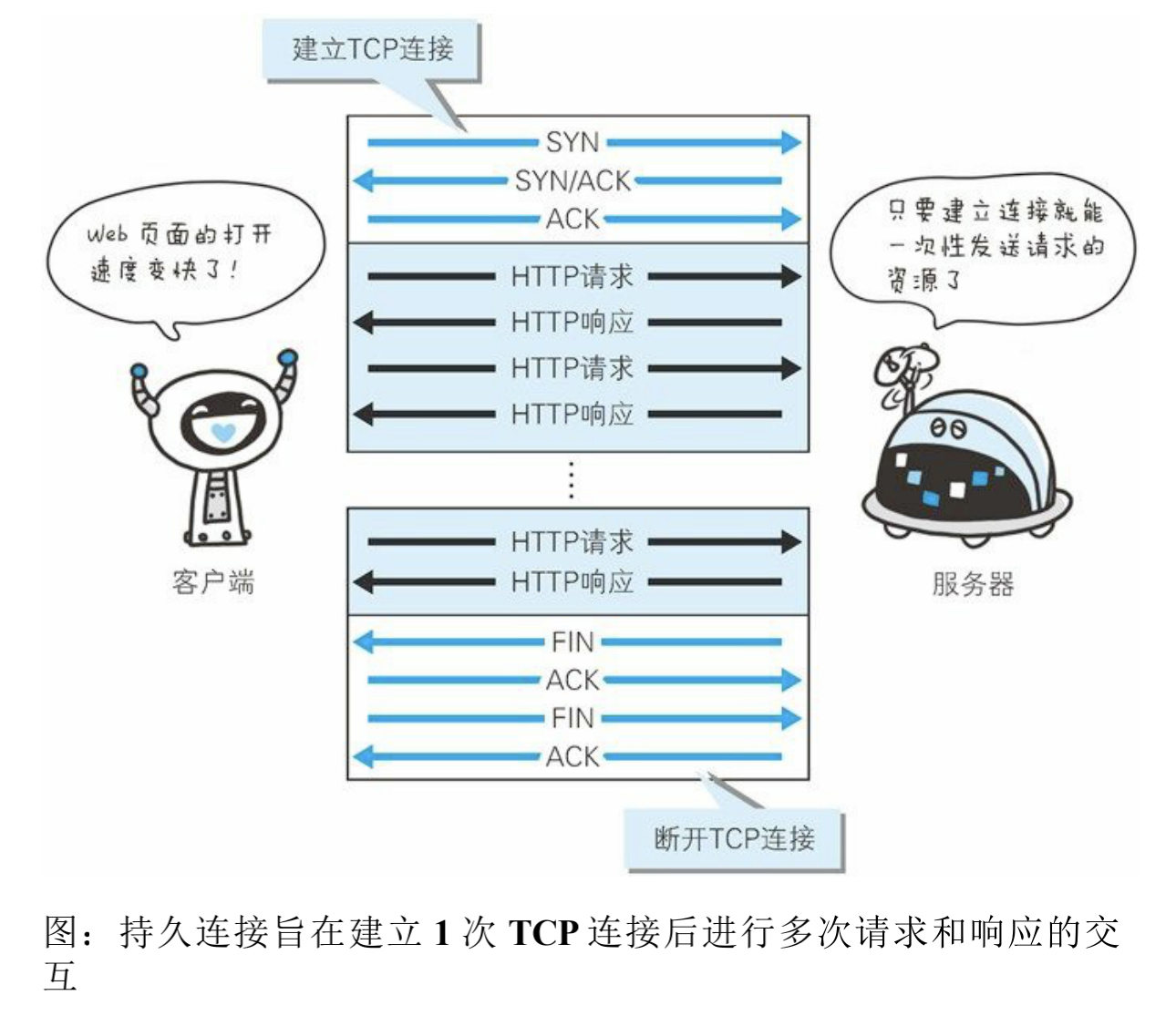
这里需要注意两点:
1、HTTP的keep-alive和TCP的keepalive是两个概念:
TCP的keepalive指的是TCP保活计时器(keepalive timer)。服务器每收到一次客户端的数据,就重新设置保活计时器,若到了设置的时间(默认2小时)没有收到客户端的数据,则服务器会间隔75s(默认75秒)持续向客户端发送探测报文段,共发送10次,若客户端持续无响应,则服务器会关闭连接。
2、http的keep-alive不是一直保持连接,且也需要客户端和服务器支持才能正常使用该特性。一般服务器会何止keep-alive的超时时间,超过指定的时间间隔,服务器就会主动关闭连接。同时,服务器端还会设置一个keep-alive最大请求数来避免请求量过大阻塞响应。
三、Cookie的引入
由于HTTP是无状态的,不对之前发生过得请求和响应的状态进行管理,所以无法根据之前的请求状态来处理本次的请求。但是,无状态协议的优点在于不记录状态,减轻服务器端的CPU和内存资源的消耗。
最典型的就是登录问题,无法记录登录状态使得需要登录才能访问的请求无法顺利执行。
为了保留无状态特征而又能解决类似的问题,就引入Cookie技术去处理状态问题。
Cookie会根据服务器端发送的响应报文内Set-Cookie字段信息,通知客户端保存Cookie。当下次客户端再往该服务器发送请求时,会自动在请求报文中携带Cookie信息。
服务器在获取到客户端携带的Cookie信息时,会检查客户端来源,然后对比服务器记录以得到该客户端之前请求的状态信息。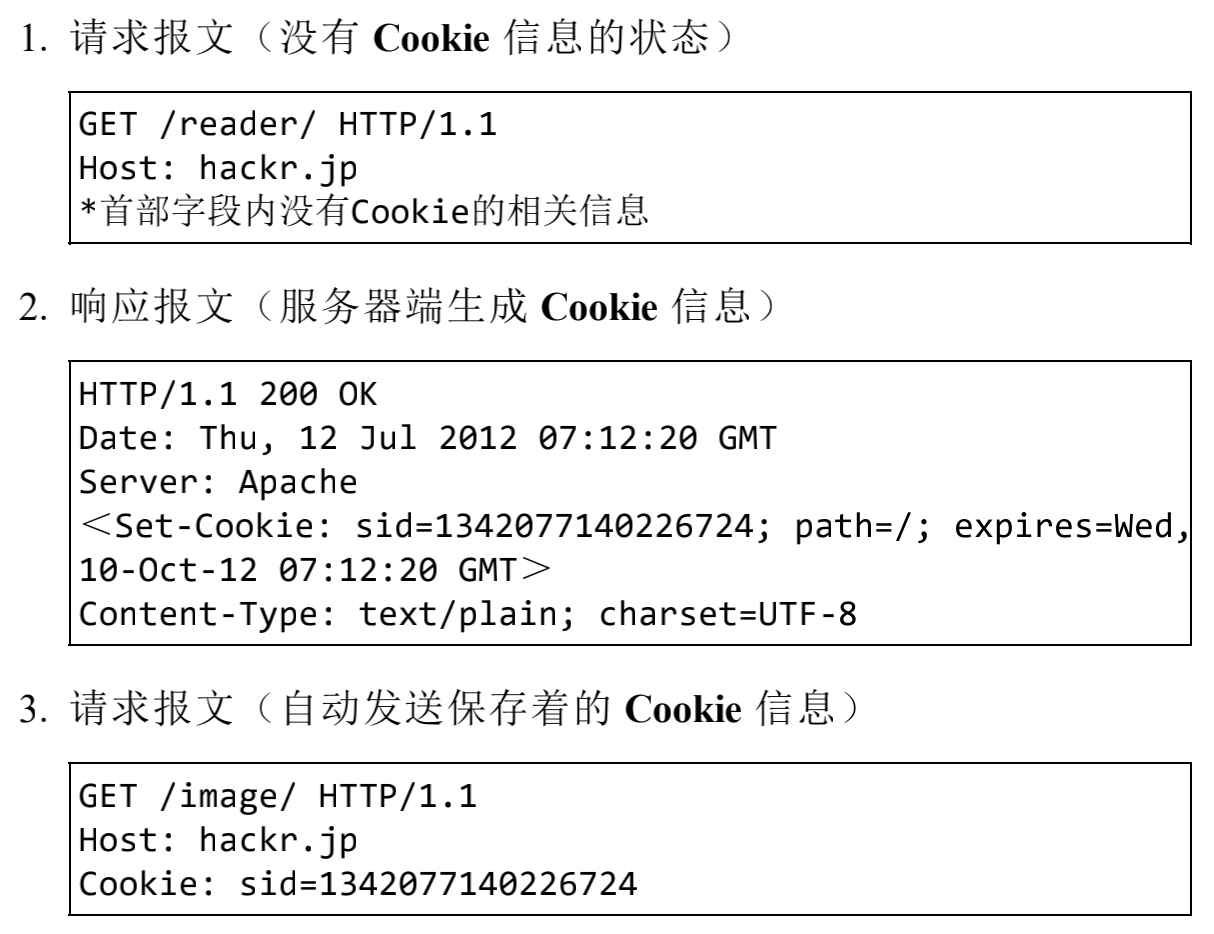
四、总结
HTTP协议和TCP/IP协议族内其他众多协议相同,用户客户端和服务器之间的通信。
不同的请求方法可以告知服务器不同的请求意图,最常用的是GET和POST方法。
为了节省服务器的不必要开销,提升访问效率,HTTP协议设计的是无状态的协议,且引入keep-alive来保持TCP连接状态。
为了处理类似登录的状态问题,引入Cookie来记录客户端的请求状态。
参考书籍:《图解HTTP》

若有收获,就点个赞吧
0 人点赞
