(谢兵)
一、cache简述
所谓缓存,就是将程序或系统经常要调用的对象存在内存中,以便其使用时可以快速调用,不必再去创建新的重复的实例。这样做可以减少系统开销,提高系统效率。
以前缓存往往使用的是RAM(断电既掉的非永久存储),所以在用完后还是会把文件送到硬盘等存储器中永久存储。电脑中最大缓存就是内存条。
二、公司项目使用过的的cache以及其实现和配置解释
1).内存缓存,也就是实现一个类中静态Map,对这个Map进行常规的增删查.
基于公司现有的项目:备课平台、网盘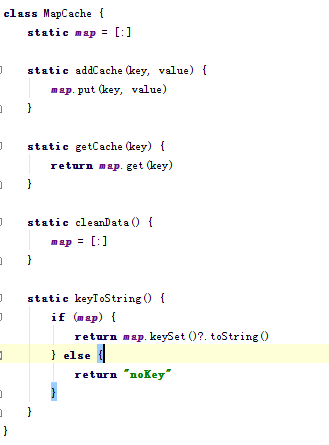
2).Ehcache是一个纯Java的进程内缓存框架,具有快速‘精干等特点。
基于公司现有的项目:oa,classboard等
下图是利用grails里面的lib实现

Java实现需要依赖jar以及xml,其实原理是一样的,配置也基本相同
ehcache.xml配置参数说明:
· name:缓存名称。
· maxElementsInMemory:缓存最大个数。
· eternal:缓存中对象是否为永久的,如果是,超时设置将被忽略,对象从不过期。
· timeToIdleSeconds:置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
· timeToLiveSeconds:缓存数据的生存时间(TTL),也就是一个元素从构建到消亡的最大时间间隔值,这只能在元素不是永久驻留时有效,如果该值是0就意味着元素可以停顿无穷长的时间。
· maxEntriesLocalDisk:当内存中对象数量达到maxElementsInMemory时,Ehcache将会对象写到磁盘中。
· overflowToDisk:内存不足时,是否启用磁盘缓存。
· diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
· maxElementsOnDisk:硬盘最大缓存个数。
· diskPersistent:是否在VM重启时存储硬盘的缓存数据。默认值是false。
· diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
· memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
· clearOnFlush:内存数量最大时是否清除。
3)..redis
基于公司现有项目:springboot项目
Springframework.data.redis 整合
代码实现片段
配置
当然也可以不利用整合
具体可参考:https://www.cnblogs.com/wojiaochuichui/p/8662005.html
三、常见的缓存策略
1)、基于访问的时间:此类算法按各缓存项被访问时间来组织缓存队列,决定替换对象。如 LRU;
2)、基于访问频率:此类算法用缓存项的被访问频率来组织缓存。如 LFU、LRU2、2Q、LIRS;
一句话解释:访问次数越大,排在队头,越不容易淘汰,当有新的访问对象进来的时候,末尾的将被淘汰。
资源地址:https://blog.csdn.net/xzengwei1313/article/details/83376219
四、缓存一些常见问题:
1).数据不一致问题
先操作缓存,再写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致。在分布式环境下,数据的读写都是并发的,一个服务多机器部署,对同一个数据进行读写,在数据库层面并不能保证完成顺序,就有可能后读的操作先完成(读取到的是脏数据),如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
场景:用户中心更新用户信息,其他项目获取用户的时候需要获取更新后的用户信息。
2).缓存穿透
缓存穿透是说收到一个请求,但是该请求缓存中不存在,只能去数据库中查询,然后放进缓存。但当有好多请求同时访问同一个数据时,业务系统把这些请求全发到了数据库;或者恶意构造一个逻辑上不存在的数据,然后大量发送这个请求,这样每次都会被发送到数据库,最终导致数据库挂掉。
场景:暂没实际遇到过,解决方法只能做参数校验或者参数加密,明文参数被攻击纯属必然
3)缓存击穿
上面提到的某个数据没有,然后好多请求查询数据库,可以归为缓存击穿的范畴:对于热点数据,当缓存失效的一瞬间,所有的请求都被下放到数据库去请求更新缓存,数据库被压垮。
场景:比如报名表单或者选课,其实这种情况,事先提前通过后台程序缓存起来
4)缓存雪崩
缓存雪崩是指当我们给所有的缓存设置了同样的过期时间,当某一时刻,整个缓存的数据全部过期了,然后瞬间所有的请求都被抛向了数据库,数据库就崩掉了。
场景:暂没实际遇到过,抄了一场景如下
对于 Redis 挂掉了,请求全部走数据库,也属于缓存雪崩,我们可以有以下思路进行解决:
事发前:实现 Redis 的高可用(主从架构+Sentinel 或者 Redis Cluster),尽可能避免 Redis 挂掉这种情况。
事发中:万一 Redis 真的挂了,我们可以设置本地缓存(ehcache)+ 限流(hystrix),尽量避免我们的数据库被干掉。
事发后:Redis 持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。

若有收获,就点个赞吧
0 人点赞
