背景
我们很多同事之前没有接触过数仓,刚开始的时候很难理解几个问题:
- 数仓是个啥?从网上搜索资料的时候,有的讲的是理念,有的讲的是技术,很难理解;
- 数仓和常见的mysql、sqlserver有啥区别?
- 为什么sqlserver也能做数仓?
- 为什么要用数仓?
- 为什么要进行数据分层?
这个过程很正常,我们做ERP过来的人因为过去接触的都是用来搞“生产”的数据库,就好比如果没有见过汽车的人,有人跟他描述,有一种车,是由好几个车箱连起来,可以座很多人时,人们肯定只能联想到把“拖车”把一辆车和另外一辆车用拖车的方式连起来。
所以数仓入门除了理念以外最关键的是去体验一下已有的客户实践。
数据库分类
分类
OLTP(on-line transaction processing)翻译为联机事务处理,
OLAP(On-Line Analytical Processing)翻译为联机分析处理,
从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询。
再从应用上来看看OLTP与OLAP的区别。
OLTP主要用来记录某类业务事件的发生,如购买行为,当行为产生后,系统会记录是谁在何时何地做了何事,这样的一行(或多行)数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,像公司常见的业务系统如ERP,CRM,OA等系统都属于OLTP。
当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做OLAP了。
因为OLTP所产生的业务数据分散在不同的业务系统中,而OLAP往往需要将不同的业务数据集中到一起进行统一综合的分析,这时候就需要根据业务分析需求做对应的数据清洗后存储在数据仓库中,然后由数据仓库来统一提供OLAP分析。所以我们常说OLTP是数据库的应用,OLAP是数据仓库的应用,下面用一张图来简要对比。
多维数据库
OLAP分析的分类:ROLAP与MOLAP
OLAP分析分为关系型联机分析处理(ROLAP)、多维联机分析处理(MOLAP)两种,他们的设计理念以及解决场景不一样,各有优劣。
ROLAP
以ROLAP为代表的有传统关系型数据库、MPP分布式数据库以及基于Hadoop的Spark/Impala,特点是能同时连接明细数据和汇总数据,实时根据用户提出的需求对数据进行计算后返回给用户,所以用户使用相对比较灵活,可以随意选择维度组合来进行实时计算。
以传统关系型数据库为代表的如Teradata、Oracle等,由于传统架构可扩展性较差,所以对硬件的要求非常高,当计算的数据量达到千万,亿级别时,数据库的计算就会出现延时,使得用户不能及时得到响应,更别提高并发了。
这个地方也是容易混淆的,传统的数据库也能做数仓,本质来讲数仓是一种理念,不同的技术都可以去实现这种理念,只是不同的技术有不同的擅长领域和优劣势。
MPP分布式数据库(GreenPlum/GBase/Vertica)则解决了一部分可扩展性问题,对硬件设备的要求也稍稍下降了(还是有一定的硬件要求),在支持的数据体量(GB,TB级别)上有了很大的提升。当集群有几百、上千节点时,会出现性能瓶颈(增加再多节点,性能提升也不会很明显),扩容成本同样不菲。
基于Hadoop的Spark/Impala,则对部署硬件的要求很低(常见服务器即可,只是其主要依靠内存计算来缩短响应时间,所以对内存要求较高),在节点扩容上成本上相对较低,但当计算量达到一定级别或并发达到一定级别后,无法秒级响应,且容易出现内存溢出等问题。
MOLAP
以MOLAP分析为代表的有Cognos,SSAS,Kylin等,设计理念是预先将客户的需求计算好以结果的形式存下来(比如一张表分为10个维度,5个度量,那客户提出的需求会有2的10次方种可能,然后将这么多种可能提前计算好存储下来),当客户提出需求后,找到对应结果返回即可(好比你提前一天将领导明天会布置的任务先做好,明天领导布置对应任务后你直接告知他已做好),特点是当命中需求后返回非常快(所以MOLAP非常适合常见固定的分析场景),同等资源下支持的数据体量更大,支持的并发更多,不足则是当表的维度越多,越复杂,其所需的磁盘存储空间则越大,构建cube也需要一定的时间。
Cognos和SSAS是早期比较传统的产品,Cognos限制了Cube的大小(即限制了表的复杂度大小),而SSAS的cube则受限于单机的容量,即需要专用的服务器来进行存储。
这个地方也是需要注意,有些不明白的客户,会认为多维数据集才是数仓。
观点
- 数仓是一种理念,mysql,sqlserver,oracle,congnos,Kylin,Greenplum,postgres等拿来做数仓;
- mysql这样的OLTP数据库不太适合做数仓,所以一般也不采用,潜规则是一般也没用人用来做数仓理念的落地;
- 常说的数仓都是指OLAP数据库,比如:Greenplum,doris,click house,kylin,congnos,sap-bw这样的更适合做数仓;
- 云数仓是趋势,比如阿里云的ADB
数据库的分界线
数据库大小以2T为分界线的(ntfs单一文件的大小),阿里云有很多数据库,一开始很难理解,为什么要那么多数据库。背后还是场景,不同的场景需要不同的优劣势,就好比都是出行,但是有汽车、火车、飞机、自行车、滑板车……,这样来理解数据库也是一样的。
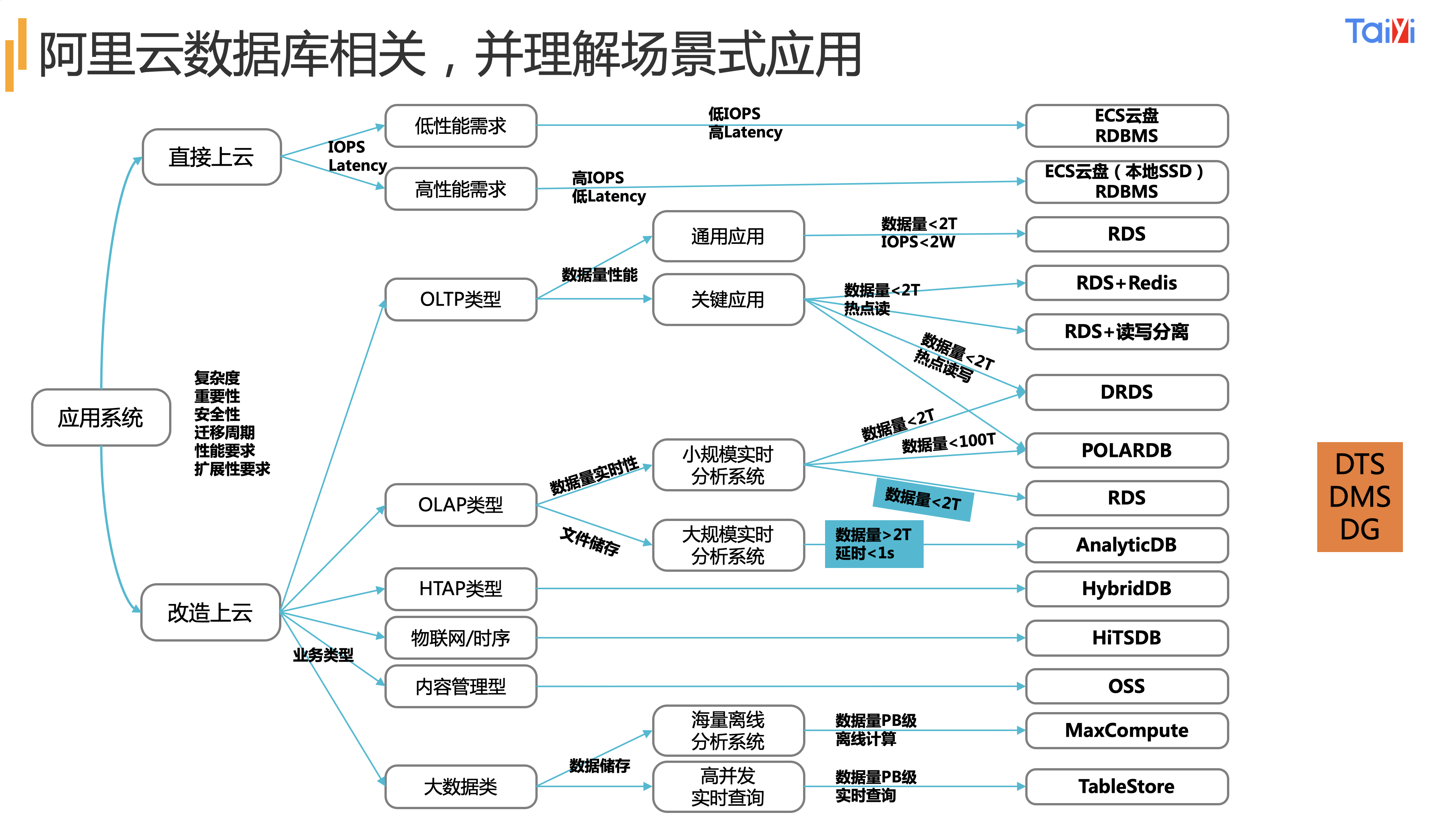
阿里云把数仓和大数据的产品类型是分开的,叫法也不同,一个叫数据仓库,一个叫计算服务,这一点我们后面再讲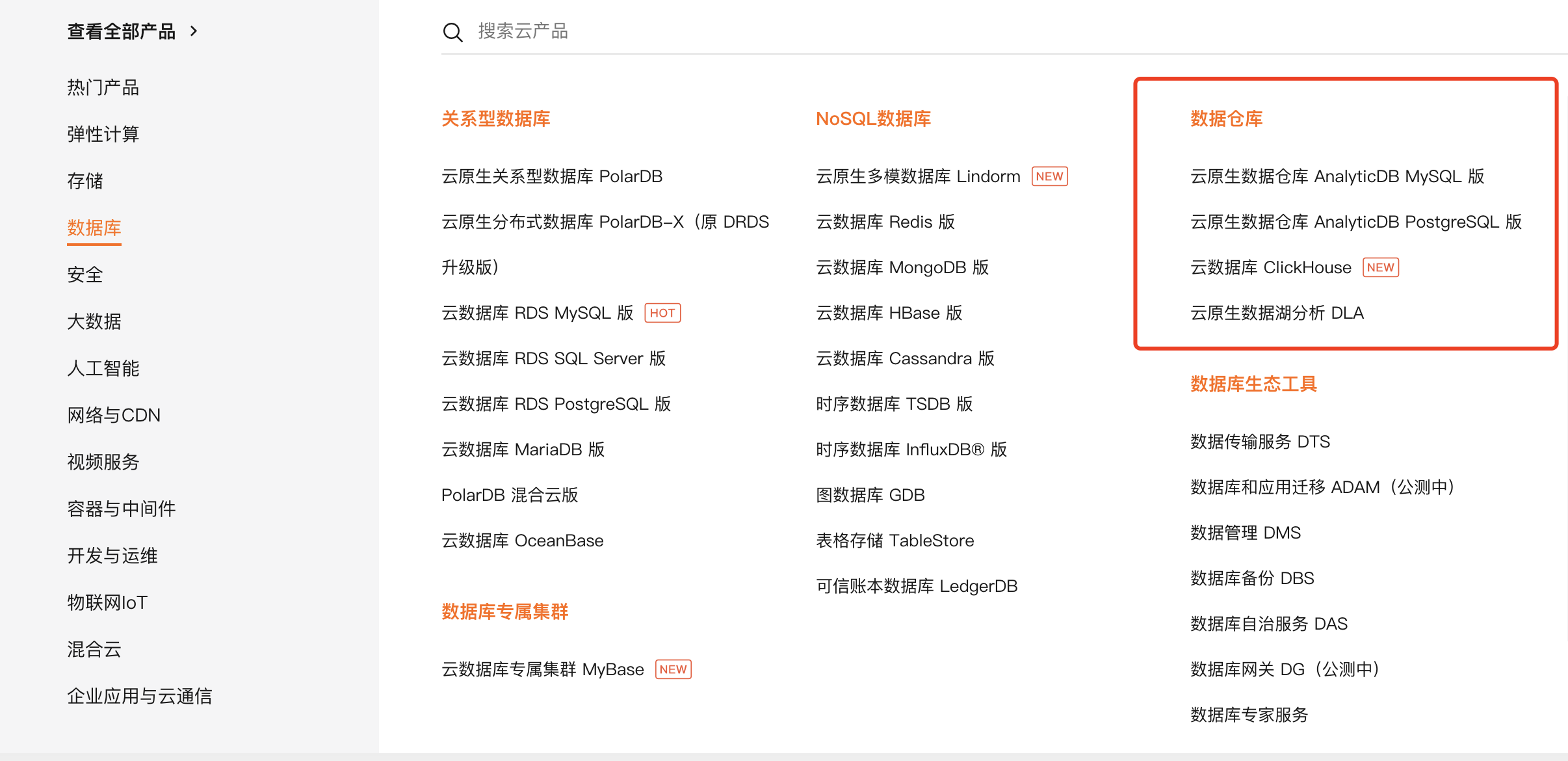

为什么要用数仓
观点
常见的资料都是从OLTP和OLAP的角度来谈为什么需要数仓的。下面我们从实际应用和客户视角来谈为什么要数仓。
- 数据分析经常需要读取很多数据,比如近十年的数据趋势,如果直接的MYSQL这样的oltp生产数据库上搞,录入数据的用户要骂人了。因为大量的数据会占用数据库很多资源导致录入数据很慢。独立的数仓性能更高,还不影响生产系统。
- 从权责的角度,生产系统的数据库是营销、成本、财务……等部门建立的,这是他们的资产,出了问题也是他们负责。分析数据库的用户有可能是运营,或同一个业务部门的不同的人,所以独立出分析库也是有必要的。
- 从领导的角度,条线业务生产端有千奇百怪的系统,很多都是采购而来的,但是数据分析的很重要的目标用户是老板和领导以及综合运用人员,他们需要的是拉通,统一。也需要有独立的系统来构建组织这些很多来源的数据。
数仓为什么要分层
我们通常把数仓分为ODS/DWD/DWS/ADS/DIM层,
这和宜家的仓库没啥区别,和超市的分门别类也没区别,本质就是为了提高复用性和使用数据的效率。
数仓和大数据
数据仓库和大数据也是容易混淆的概念,阿里云的区分比较好,大数据的概念比数据仓库更大。一些基于hadoop的分布式架构上的数据库,比如kylin是构建在hadoop上的,click house则不是。我们常说的hadoop其实是一个生态,基于HDFS的生态,HDFS和NTFS是一个道理,都是文件系统,只是一个是分布式架构可以把数据分解到几百几千个机器上可以很大很大,NTFS则是单机,只能在一台机器上通常只能小于2T。
在hadoop里面有很多技术,组合起来服务,这里不展开。有很多都是读取、计算HDFS上数据的技术。我觉着更准确的还是计算与存储的关系。
观点
- 数仓更多说的是存储,这个比较容易理解,不管是数仓,还是传统的数据库,都是储存数据的。
- 大数据更多讲的是计算,比如 maxcompute叫计算服务,为什么需要计算服务呢,主要还是性能问题。举个例子:我们有一个客户的“草签业绩”这个指标,不是简单的group by就可以算出来的,而是需要结合很多明细数据,用各种case when 才能算出来,在数仓里面跑一次这个数据需要1个小时,现在规模才1000亿,如果5000亿那就更大了。这个时候就需要计算引擎,把数据丢进去,在计算引擎里面可以快速算出结果。
- 通常了解大数据的时候都会讲hadoop,这个最底层的分布式架构,容易让人形成一个意识好像大数据=hadoop,这是不准确的。
数仓截图
下面这张截图是阿里云ADB for postgre 版本的截图。用的工具是网页版的Navicat,阿里云叫dms,就是通过网页管理数据库的。
可以看出来和普通的数据库没啥区别,也是机器(实例)-数据库-模式-表,视图,物化视图等。
比较新的概念是:
schema,模式,这个东西可以理解为组,方便数据库进行分层,分权限管理;
物化视图是一个重要的概念,相当于把视图存起来,性能等于实体表,但是需要刷新才能更新数据;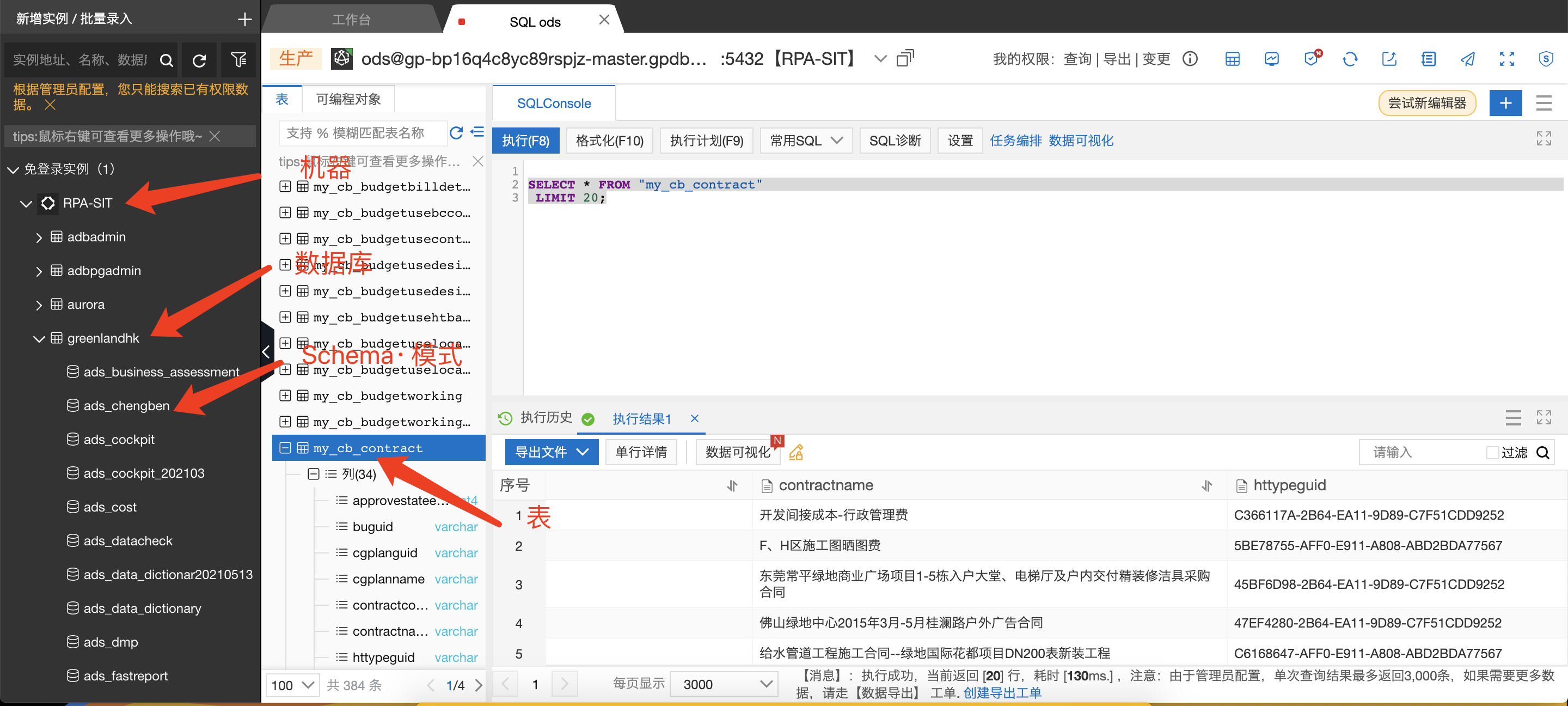

若有收获,就点个赞吧
0 人点赞
