一、知识库的介绍
这里的知识库就是我们提及的数据集,如你日常所作笔记,产品文档,论文数据集,垂直领域所积累的用户数据集等,也可以是一本书,一类型书籍等。格式可以是txt,pdf,markdown,docm或者json数据。
二、数据准备
本次教程可以使用自己笔记作为数据集进行使用,也可以下载一本书籍作为数据集,或者其他类型数据集,推荐使用书籍作为数据集。
1.数据准备:
- 确定知识库的目的:明确你想要从数据集中获取什么样的信息或知识。
- 选择数据源:可以是个人笔记、产品文档、学术论文、用户数据集、书籍等。
- 确定数据格式:常见的格式包括TXT、PDF、Markdown、DOCM、JSON,SQL等,选择适合你目的的格式。
- 进行数据清洗:一般来说进行数据清洗需要一些复杂的流程(如处理缺失值、异常值、数据格式转换、去重、数据规范化等),但是为了省事,我们可以借用自动化工具来进行相关的数据清洗工作。比如,EasyData智能数据服务平台,AWS,**OpenRefine等。**也可以选择dify自带的数据清洗功能。
2.进行文档上传:
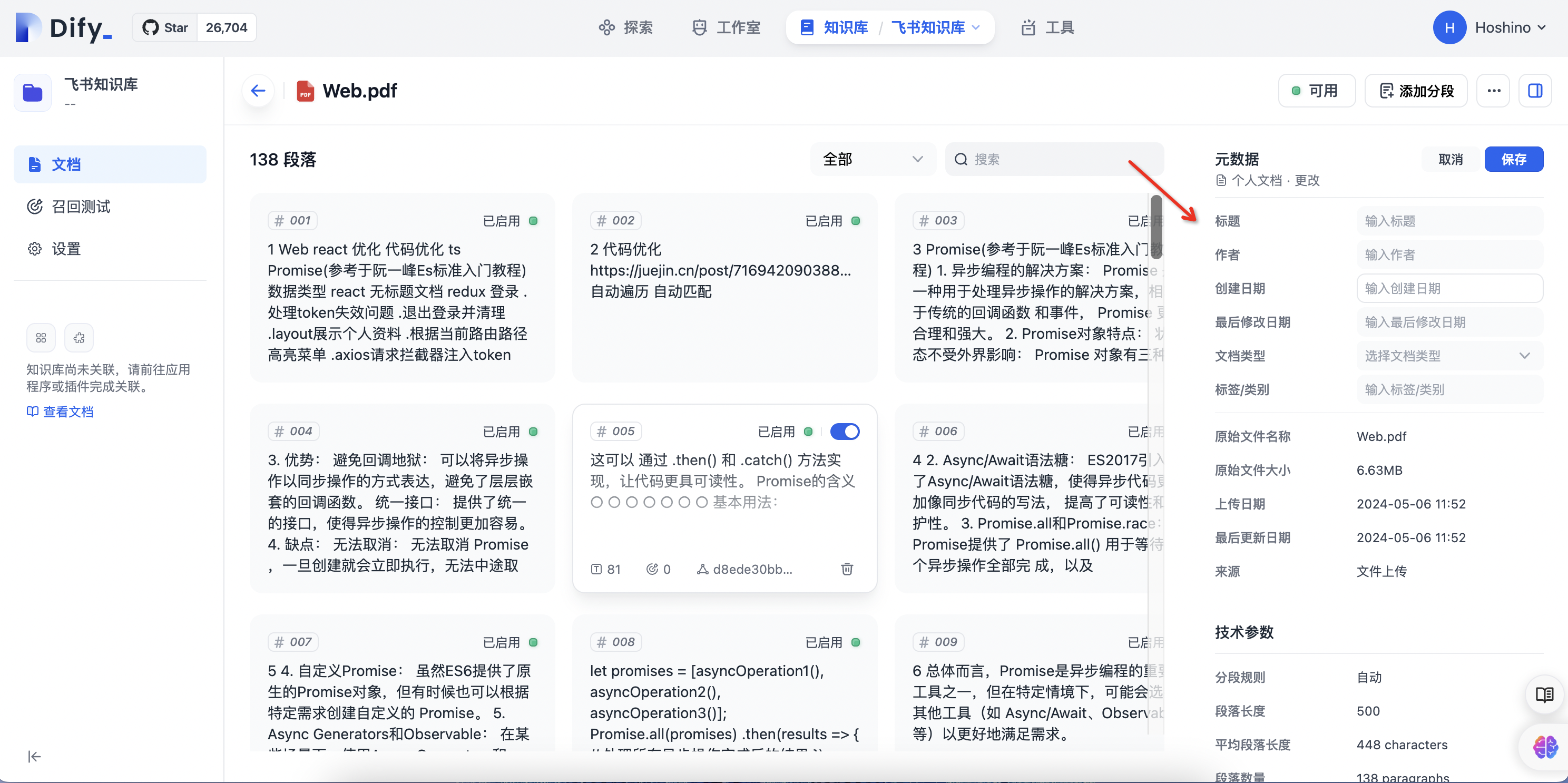
Dify支持对分段与清洗后的文本进行自定义增删改,和coze创建数据库文档一样,可以动态调整自己的分段信息,让数据集更加精准。通过点击数据集中 文档 —> 段落 —> 编辑 可修改段落内容以及自定义关键词。通过点击 文档 —> 段落—> 添加分段—>添加新分段 可手动添加新的分段内容,也可以点击 文档 —> 段落—> 添加分段—>批量添加 批量上传新的分段内容。
3.通过API进行数据库维护
鉴权、调用方式与应用 Service API 保持一致,不同的是一个数据集 API token 可操作所有数据集
Dify 提供了一套 API,允许用户通过编程方式维护数据集。以下是通过 API 维护 Dify 数据集的基本步骤和一些操作示例:
- 创建数据集:
- 使用 POST 请求创建一个新的数据集。
curl --location --request POST 'https://api.dify.ai/v1/datasets' \--header 'Authorization: Bearer {api_key}' \--header 'Content-Type: application/json' \--data-raw '{"name": "name"}'
- 获取数据集列表:
- 通过 GET 请求获取数据集的列表。
curl --location --request GET 'https://api.dify.ai/v1/datasets?page=1&limit=20' \--header 'Authorization: Bearer {api_key}'
- 通过文本创建文档:
- 使用 POST 请求通过文本创建一个新的文档。
curl --location --request POST '<https://api.dify.ai/v1/datasets/<uuid:dataset_id>/document/create_by_text>' \\--header 'Authorization: Bearer {api_key}' \\--header 'Content-Type: application/json' \\--data-raw '{"name": "Dify","text": "Dify means Do it for you...","indexing_technique": "high_quality","process_rule": {"rules": {"pre_processing_rules": [{"id": "remove_extra_spaces","enabled": true}, {"id": "remove_urls_emails","enabled": true}],"segmentation": {"separator": "###","max_tokens": 500}},"mode": "custom"}}'
- 通过文件创建文档:
- 使用 POST 请求上传文件来创建文档。
curl --location POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_file' \--header 'Authorization: Bearer {api_key}' \--form 'data="{"name": "Dify","indexing_technique": "high_quality","process_rule": {"rules": {"pre_processing_rules": [{"id": "remove_extra_spaces","enabled": true}, {"id": "remove_urls_emails","enabled": true}],"segmentation": {"separator": "###","max_tokens": 500}},"mode": "custom"}}";type=text/plain' \--form 'file=@"/path/to/file"'
- 获取文档嵌入状态(进度):
- 使用 GET 请求查询文档的嵌入状态。
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{batch}/indexing-status' \--header 'Authorization: Bearer {api_key}'
- 删除文档:
- 使用 DELETE 请求删除一个文档。
curl --location --request DELETE 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}' \--header 'Authorization: Bearer {api_key}'
- 获取数据集文档列表:
- 通过 GET 请求获取数据集中所有文档的列表。
curl --location --request GET 'https://api.dify.ai/v1/datasets/{dataset_id}/documents' \--header 'Authorization: Bearer {api_key}'
- 新增分段:
- 使用 POST 请求为文档新增分段。
curl 'https://api.dify.ai/v1/datasets/aac47674-31a8-4f12-aab2-9603964c4789/documents/2034e0c1-1b75-4532-849e-24e72666595b/segment' \--header 'Authorization: Bearer {api_key}' \--header 'Content-Type: application/json' \--data-raw $'"chunks":[{"content":"Dify means Do it for you","keywords":["Dify","Do"]}]'--compressed
以上操作都需要使用有效的 api_key 进行鉴权。具体的 API 接口和参数可能会根据 Dify 的实际 API 文档有所不同,因此在使用前应参考最新的 Dify API 文档 以确保正确性。
通过这些 API,用户可以方便地在 Dify 上进行数据集的创建、管理和维护,实现自动化的数据集同步和更新流程。
- 错误信息
document_indexing,文档索引失败provider_not_initialize, Embedding 模型未配置not_found,文档不存在dataset_name_duplicate,数据集名称重复provider_quota_exceeded,模型额度超过限制dataset_not_initialized,数据集还未初始化unsupported_file_type,不支持的文件类型,目前只支持:txt, markdown, md, pdf, html, htm, xlsx, docx, csvtoo_many_files,文件数量过多,暂时只支持单一文件上传file_too_large,文件太大,支持15M以下
4.添加飞书知识库
- 先在飞书文档中创建一个知识库
- 创建文档列表并添加内容
- 下载文档
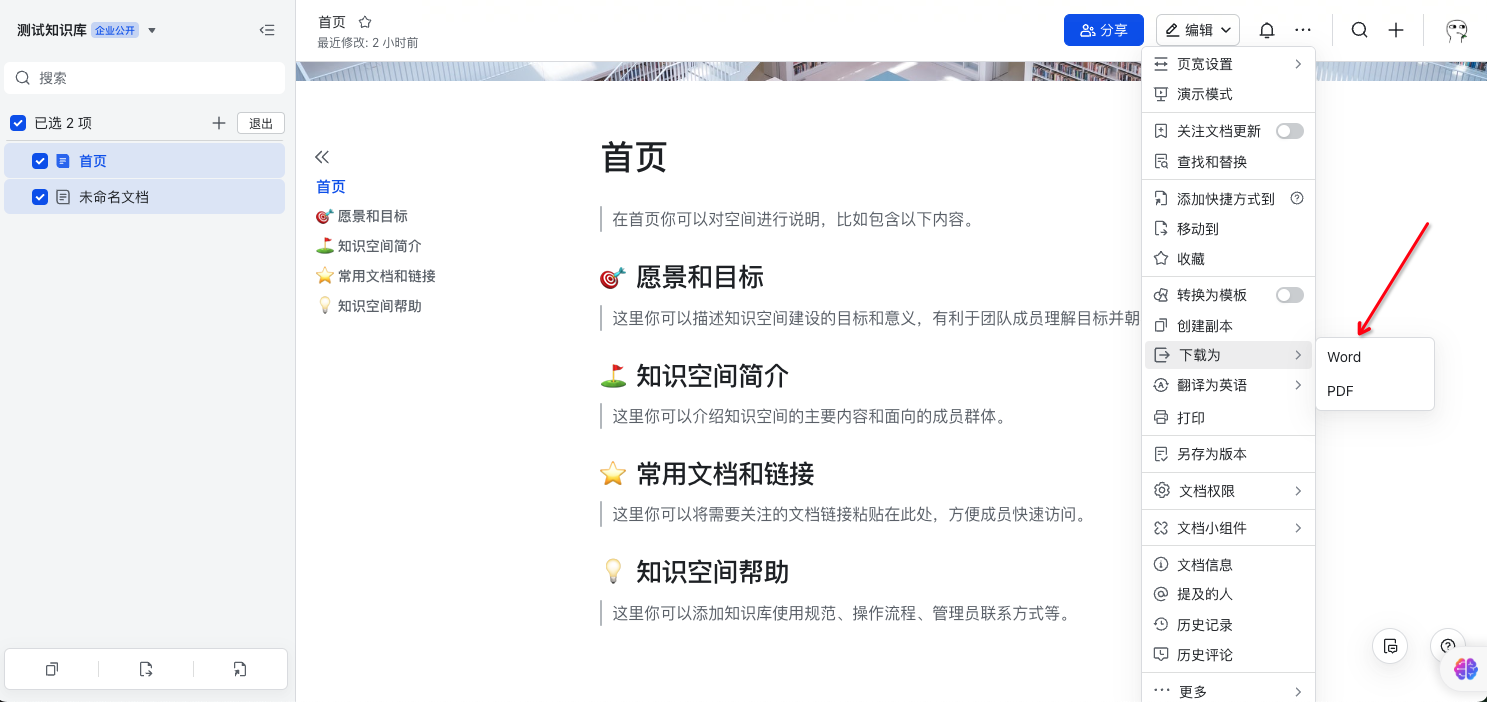
- 在dify中添加下载的文档

- 数据清洗
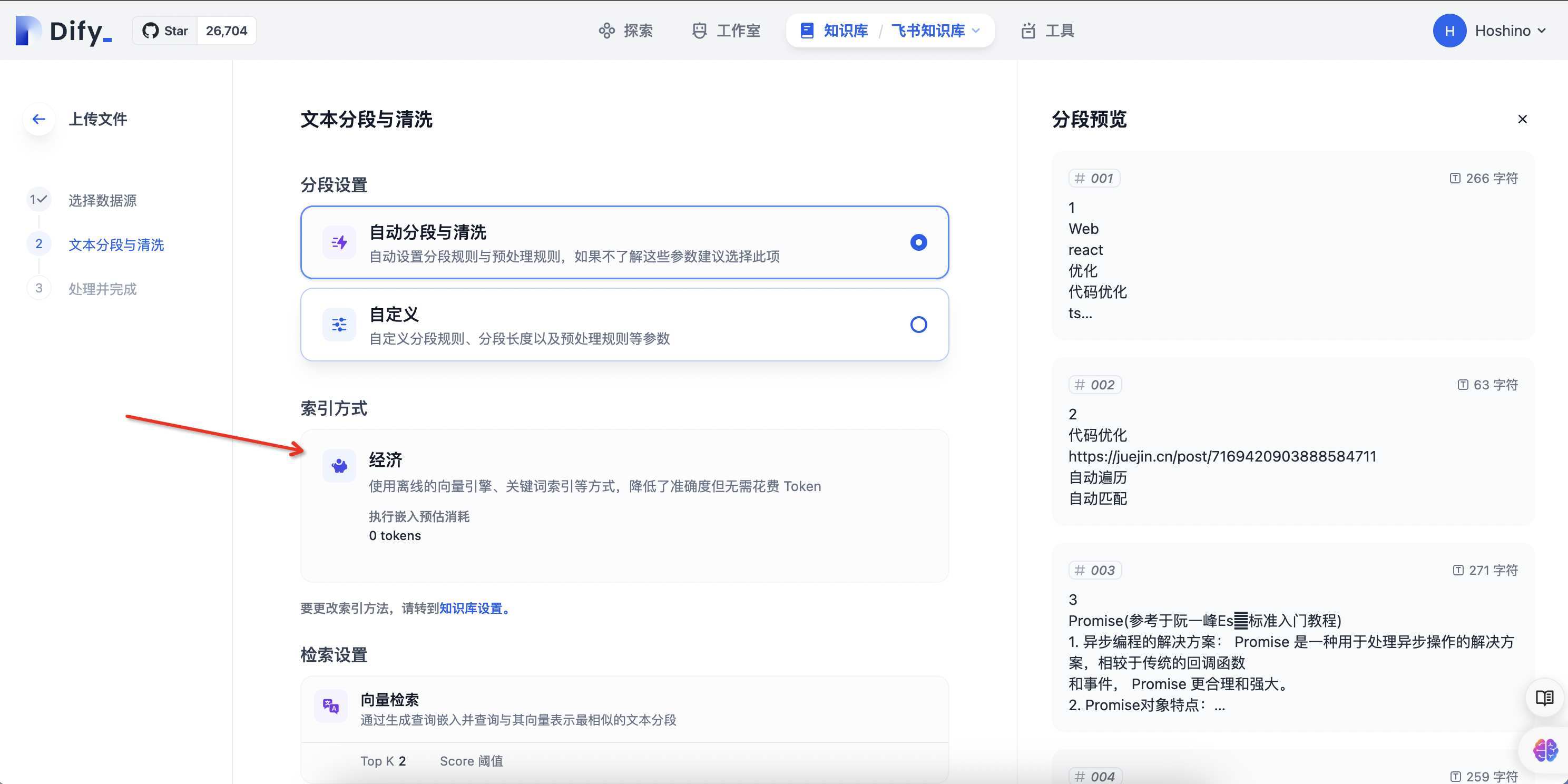
5.添加语雀知识库
- 创建知识库
- 创建文档列表并添加内容
- 打开设置

- 下载文档
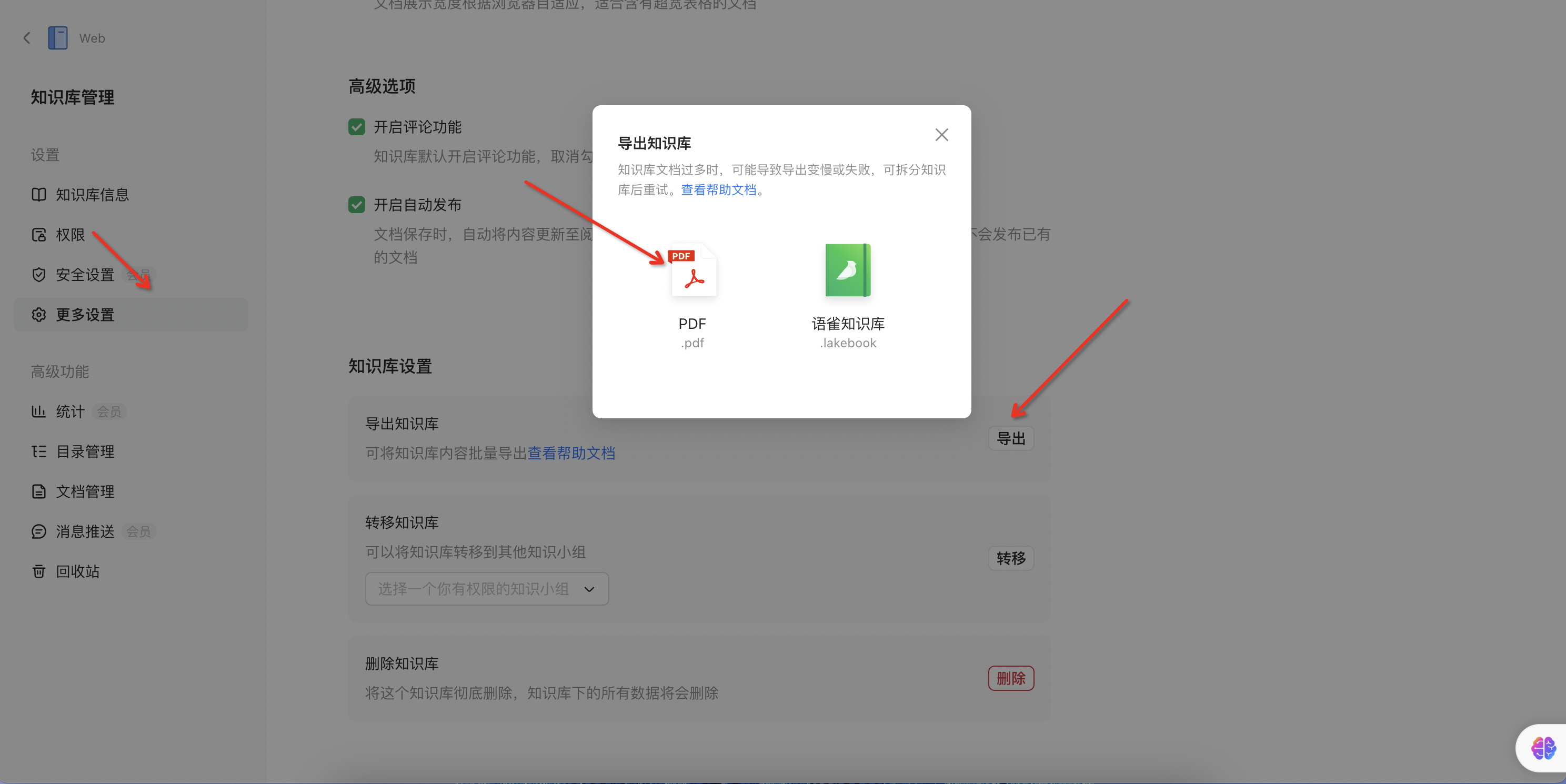
- 上传文档,同上
若文档大小超过15MB 建议进行分批上传。
6.编辑文档片段与元数据

若有收获,就点个赞吧
0 人点赞
