百度
- 关于MySQL数据库的crash-safe。csdn收藏
- 其实crash-safe指的就是当mysql运行期间突然发生崩溃,mysql是如何做到数据不发生错误的
- 主要是通过三个日志实现:redo-log,undo-log,bin-log
- redo-log:发出某条修改数据库的语句的时候,mysql都是在内存里面修改某条数据,然后记录该条语句到磁盘里面,最后后台线程才会决定在某个时间真正把数据刷到磁盘里面(刷盘)。这样,即使在刷盘之前突然宕机,也可以通过redolog实现重写。
- undo-log:当我们insert的时候,redo-log会记录一条相反逻辑的语句:delete。这样,当我们在事务执行期间如果发生宕机,也能快速回滚
- binlog是用于有从机的时候,从机同步主机数据用的
- url输入的全过程?
- 输入网址
- DNS寻址,将域名转化为IP地址
- 与服务器完成TCP连接的三次握手
- 客户端发送http请求报文,服务器发送http响应报文,浏览器页面渲染显示
- 四次挥手断开TCP连接
- InnoDB和MyIsam存储引擎的区别
- 键:InnoDB必须有唯一索引(如主键),如果没有也会自动生成一列row_id作为主键,MyIsam不需要。MyIsam不支持外键,InnoDB支持。
- 事务:InnoDB支持事务,MyIsam不支持。
- 索引:InnoDB为聚簇索引,MyIsam为非聚簇索引
- 锁:InnoDB支持行级锁,MyIsam只支持表级锁
- MyIsam自带一个统计整张表的行数的变量,所以select count(*)会非常快。InnoDB需要一行行遍历
- 如何数据库调优(csdn数据库优化方案整理)
- sql优化:
- select *要慎用,一次查询的数据太多
- 不带where条件的sql要慎用
- 合理使用索引:一般是指where字句的优化:
- where后面跟的列一般要加索引
- 以下几种都是为了防止mysql放弃索引的使用:
- 不要用 !=
- 不要用or,用union代替or
- like 后面的关键字不要以占位符%开头
- where num/2=4 计算不好
- where substring(name,1,3) 使用函数不好
- 数据库结构:分表(使用频率低的字段和高的字段分开)、增加中间表(减少联表查询)、增加冗余字段(减少联表查询,但要注意其他表的更新)
- 读写分离:一台数据库支持最大连接数是有限的,如果用户的并发访问很多,一台服务器无法满足需求,可以集群处理。mysql集群处理技术最常用的就是读写分离。读写分离实现了负载均衡
- 缓存:高并发查询热点数据,后端数据库不堪重负,可以用缓存来扛。
- sql优化:
- 讲一下联合索引?
- ALTER TABLE table_name ADD INDEX index_name(col1,col2,col3)可以创建联合索引,也叫组合索引
- 这个索引会让该表数据先以col1升序排列,col1相等的再按col2升序排列,col1与col2都相等的时候再按照col3升序排列
- where col1=111 and col3=222中col3就没法命中索引,因为不连续。最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
- 网络模型7层
- 在应用层和传输层之前多了个表示层(数据的加密)、会话层(会话管理)
- 为什么需要三次握手而不是两次?
- 因为如果少了最后一次,服务端就不知道它上次发的信息对方是否成功接收
- 四次挥手说一下,为什么是4次?
- 因为服务端可能还有数据没发完
- nginx算法:做的是将请求分配给布置了相同服务的服务器集群
- 轮询算法:按顺序将请求依次分配给下一个服务器
- ip_hash算法:按照ip的hash值将某个请求分配给某个服务器
- weight算法:服务器的性能有个权重
- fair算法:根据响应时间,响应时间短的优先分配请求
- url_hash算法:按照URL的hash值分配
- Synchronized底层原理(脉络,详细请看csdn深入理解Java并发之synchronized实现原理以及)
- https://www.bilibili.com/video/BV14i4y1G79E
一个对象被new出来以后,在堆里面存放,它的结构为:
markword:会记录锁的一些信息
classpointer:指向对象所属的类信息
成员变量:
补齐8的整数倍的一些字节:无意义
markword中记录的信息:
synchronized代码块反编译之后实际上是被monitorenter和monitorexit包着。在hotspot更底层实际上经历过一系列的锁升级:
一个对象new出来以后,它是一个普通对象:Object o = new Object();当它进入synchronized(o){}之后,该对象的markword就会发生变化,偏向锁位置为1,变成偏向锁。当有轻度的竞争时,该锁会升级为轻量级锁。有重度竞争的时候,锁才会升级为重量级锁。
在java6以前只有重量级锁。由于重量级锁实际上是依赖于操作系统的Mutex Lock,需要用户态切换为内核态,时间成本高。因此java6以后引入偏向锁和轻量级锁作为优化。
- ReentrantLock底层原理:底层是基于AQS实现的,具体看打印
- ARP协议
- 是将IP地址转化为MAC地址(网卡地址/物理地址)的协议,是个链路层协议。
- 链路层主要是MAC协议,链路层传输的数据帧,要包括源MAC地址和目的MAC地址,目的MAC地址就是通过ARP协议拿到。可见ARP协议是为MAC协议服务的
- 基于springboot从0开始一个项目一个应用的步骤
- 设置maven仓库(一般是new Spring Initializer,选择web..)、配置tomcat端口号、连接mysql、mybatis逆向工程生成mapper文件、创建controller、service、serviceimpl、dao等等
- 项目配置文件:resources/application.yml
- 静态资源目录:resources/static/
- 视图模板目录:resources/templates/
- mybatis映射文件:resources/mappers/
- mybatis配置文件:resources/spring-mybatis.xml
- 运行主启动类
阿里
- 排序算法有哪些?(阿里钉钉)
- 冒泡排序,每次从左到右,把大的往右移动。这样右边界就主键往左了
- 选择排序,每次找到剩下元素里面最小的元素,放到左边
- 插入排序,每次拿当前元素与之前的比较,小,则往前插队
- 归并排序。一个MergeeSort主方法(拆分两边分别MergeeSort,返回合并结果),一个merge方法合并两个排好的数组
- 快速排序。getIndex(int[]array,low,high)方法:
- 桶思想排序
- 多线程的一些问题(阿里钉钉)
- 锁细化:synchronized修饰方法->修饰代码块
- 锁粗化:太细了,需要频繁获取锁、释放锁,没必要
- synchronized锁升级
- 线程池:几大参数:核心线程数、最大线程数、队列种类、拒绝策略
- CAS无锁
- InnoDB和MyIsam存储引擎的区别(阿里钉钉)
- 键:InnoDB必须有唯一索引(如主键),如果没有也会自动生成一列row_id作为主键,MyIsam不需要。MyIsam不支持外键,InnoDB支持。
- 事务:InnoDB支持事务,MyIsam不支持。
- 索引:InnoDB为聚簇索引,MyIsam为非聚簇索引
- 锁:InnoDB支持行级锁,MyIsam只支持表级锁
- MyIsam自带一个统计整张表的行数的变量,所以select count(*)会非常快。InnoDB需要一行行遍历
阿里交易流程团队(已挂)
总结:1、说话的时候有些不自信,还反问对方,是这样的不?2、遇到陌生的问题没办法思考了,不太会扯
- 对于10亿个订单数据,它分布在各个服务器上,如何对它进行排序?
- 比如有十台服务器,用归并排序,两两一组先排好,比如1、2号服务器先按顺序排好他们的数据
- 如何不使用中间件比如redis,去实现一个分布式锁?
- 是否进程可见
- 是否互斥
- 是否可重入
- 性能够不够高
- linux上ping一个网络,有ping过吗?
- mysql的缓冲区知道吗?
- 一个项目刚启动,收到的请求很慢,过一会就快了,为什么? JIT相关?
- JIT是个即时编译器,能把JVM将class文件解释成的机器码保存起来,便于下次使用,这就类似于纯编译型语言了,下次就快了
- 为什么那样会导致索引失效?
- 几个ClassNotFoundException的区别
- Java基础知识查漏补缺
阿里钉钉(自我感觉良好,挂了)
总结:应该再自信一点
- 快排的实现方式,口述一下?分析一下它的时间复杂度?
- 平衡搜索树的时间复杂度。log2N
- spring的ioc是什么?依赖注入是什么?
- 项目你做了什么?
- 类加载的时候,创建了多个Class对象的时候,会不会产生两个对象呢?
- 类加载器的分类:
- Bootstrap ClassLoader
- Extension ClassLoader
- Application ClassLoader

双亲委派模型:首先会交给父加载器加载,父加载器加载不了,再给子加载器加载
蚂蚁数据部(等三面)
- lambda表达式的原理是什么?
- 什么是依赖注入?
- 依赖注入,是 IOC 的一个方面,是个通常的概念,它有多种解释。这概念是说你不用创建对象,而只需要描述它如何被创建。你不在代码里直接组装你的组件和服务,但是要在配置文件里描述哪些组件需要哪些服务,之后一个容器(IOC 容器)负责把他们组装起来。
- 快速排序算法为什么不稳定?
- 它只表示两个值相同的元素在排序前后是否有位置变化。如果前后位置变化,则排序算法是不稳定的,否则是稳定的。稳定性的定义符合常理,两个值相同的元素无需再次交换位置,交换位置是做了一次无用功。
- 快排和堆排序?
- 快排:NlogN,不稳定
- 堆排序:NlogN,不稳定
- 选择排序也不稳定,除了这三个,其他的算法都是稳定的
- 设计模式的六大原则
- 单一职责模式:通俗的说,即一个类只负责一项职责。
- 里氏替换原则: 子类可以扩展父类的功能,但不能改变父类原有的功能。能不重写就不重写
- 依赖倒置原则:核心思想是面向接口编程
- 接口隔离原则:客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。(接口中尽量少一些用不上的方法)
- 迪米特法则:尽量降低类与类之间的耦合。类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
- 装饰者模式和适配器模式的区别?
- 适配器模式:我想用Translator类的对象去调用Speaker类的对象的某个方法,就利用一个桥梁去连接他们

- 装饰模式:是你还有你,一切拜托你
- 加锁的逻辑?再复盘一遍
- 检查redis中有没有三级分类的数据
- 如果有,直接返回,结束
- 如果没有,调用查询数据库的方法。查询数据库的方法是加锁的,在方法里面,再次判断redis里面有没有数据(避免多线程查询数据库的关键)。如果没有,真正去查询数据库。
- 项目中最有成果的一件事情?
- 贪心思想是什么?0-1背包问题的解法
- 贪心思想总是求的局部最优解,总是考虑当前情况的最优解。但像01背包问题里面用贪心思想就得不到全局最优解。参考买卖股票的最佳时机Ⅱ
- 动态规划
- 判断二叉搜索树??????????????????????????
- 了解反射吗?
- 反射可以在运行时为我们提供一些类的结构信息,包括属性、方法、构造器等结构
- 用处:在运行时才决定创建哪个对象(这就是动态性),比如改进后的单例模式。
- 反射的一切操作都是从Class对象开始的。首先要获取这个对象。然后才能去获取该类的属性、方法、构造器等结构、操作某个对象。
- https://blog.csdn.net/qq_26558047/article/details/109745018 反射创建对象和new一个对象的区别
- 对多态的理解??
- JIT?
- https://blog.csdn.net/qq_36042506/article/details/82976586
- just in time complier即时编译器,是JVM为了优化java的一种手段。早期jvm是个纯粹的解释型语言,对.class文件解释一句执行一句(解释为机器码),没有保存完整的机器码,这样非常慢。在执行时JIT会把翻译过的机器码(使用频率高的)保存起来,已备下次使用,因此从理论上来说,采用该JIT技术能够,能够接近曾经纯编译技术。
- 锁在操作系统层面怎样实现的?
- Linux的文件系统了解吗,什么是文件描述符表
- 进程的内存映象
- 如果一个应用程序访问一个不允许访问的内存(如0x0),会发生什么?
- 红黑树的特性?
- 层序遍历可以用深度优先吗?
- 可以,此题的关键在于用height记录层数
- 要先新建一个list存放在result里面,再去取,存值。
- 最长有序子串的长度。例如[“aaa”,”bcd”,”zzz”,”bcdef”,”def”] aaabcddefzzz
- 动态规划
- redis与memcached有什么区别,为什么选择Redis,而不是memcached
- redis支持5种数据类型,而memcached只支持文本
- redis支持持久化RDB和AOF两种方式,而memcached不支持持久化
- redis速度比memcached快
- final关键字的用法,final域的重排序规则(不了解),final修饰形参时会怎么样(同final修饰变量)
- final域的指令重排限制:
https://blog.csdn.net/weixin_37948564/article/details/105781412
- 对final变量的写操作:不允许跳出构造器,保证final一定先被初始化
- 对final变量的读操作:必须在引用指向完成才能读
- Object类中的方法(toString、hashCode、equals、wait、notify、notifyAll、getClass、clone和finalize)
- 知道乐观锁和悲观锁吗,应用场景
- 乐观锁:
- 描述:每次读数据的时候都假设人家不会修改,不上锁,但写入前时候会看看这个数变没变
- 数据的版本号;CAS例如atomic
- 悲观锁:
- 描述:每次读数据的时候都假设人家会修改,上锁,不让别人update
- synchronized
- 线程池初始化方式和参数:Executors方式和ThreadPoolExecutor方式
- Executors.newSingleThreadExecutor()
- new ThreadPoolExecutor(参数)
- 快速向未到达corePoolSize的线程池添加两个线程,会向queue中添加然后转发运行还是直接向corePoolSize中增加并运行?
- bfs算法????????????????????????????????
- 分布式session,各种解决方案的优点和缺点
- 1、各个tomcat存放相同的session,一个改变,其他同步。数据量太大
- session存放在cookie里面。cookie存放数据有限;不受服务端控制
- nginx反向代理,一个用户固定一个服务器。害怕服务器宕机
- 后端统一管理session,redis,还可配置集群
- Spring Boot常用的框架(starter)
- spring-boot-starter-web
- spring-boot-starter-data-redis
- mybatis-spring-boot-starter
- spring-cloud-starter-openfeign
- spring-boot-starter-test
- Spring MVC接收到请求时的处理流程
- 客户端发送http请求至DispatcherServlet
- 通过handlermapping找到相应的controller,处理请求
- controller调用service,得到处理结果返回给DispatcherServlet
- DispatcherServlet通过ViewResolver处理视图映射,拼上前缀,找到对应的前端页面,并渲染。
- 将前端页面返回给客户端(http响应)
- 参考:
https://blog.csdn.net/cswhale/article/details/16941281
- Spring的IOC
- https://www.cnblogs.com/superjt/p/4311577.html
- IOC中的依赖注入是实现控制反转的一种实现方式。
- 所谓控制翻转是指:以前没有spring的时候,我们进行web开发的过程中,对象A需要依赖对象B,需要在A对象里面new一个B对象,这样协同完成某项任务。但企业级应用的依赖关系特别复杂,导致对象与对象间的耦合太严重,牵一发而动全身。因此,我们不让A掌握B的产生,主动权交给springioc,当A需要用到B的时候,再去注入对象B,这样就能解耦了。这就是所谓的控制反转。
- hashmap的扩容原理
- 堆内存不够用时可能的操作(垃圾回收,扩容堆)
- redis的存储原理
- string
- list
- hash
- set
- zset
- AVL树深度差不能超过多少?红黑树时间复杂度
- 1,logN
- 讲一下什么样的情况能用动态规划?
- TCP发数据过程中必须按顺序接收吗
- 不一定

- 虚拟内存和物理内存谈一谈
- String数组的最长公共前缀??????????????????????????
- 死锁,以及怎么解决死锁
- 线程之间出现了循环等待资源的情况,举个栗子:线程a拿到了锁1,现在还想要锁2;线程b拿到了锁2,现在还想要锁1。
- 如何解决:
- 破坏互斥条件,这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)
- 破坏请求与保持条件,一次性申请所有的资源。
- 破坏不剥夺条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件, 靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。比如两个线程都是按照一样的顺序申请两把锁
- mysql查找过程
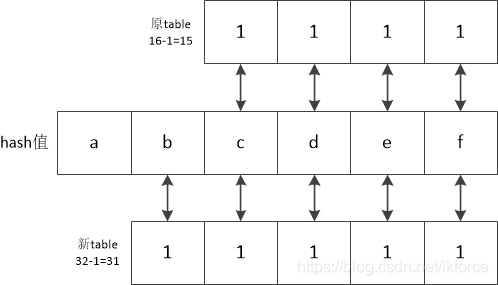

- LRU
- 项目中用的中间件的理解
- 具体场景的排序策略?Collections.sort底层排序方式?
- 从时间、空间复杂度、是否要求稳定性角度考虑:比如数据量n的大小不同的场景
- Collections.sort底层排序方式为mergeSort归并排序
- 说说自己参与的项目,技术难度在哪里?
- 说一说下订单,减库存
- 阻塞队列不用java提供的自己怎么实现,condition和wait不能用
- https://zhuanlan.zhihu.com/p/64156753
- 使用在put和take方法中使用while(true)循环,然后对两个方法加synchronized锁
- 介绍你的那个项目的来源是?为什么要做这个项目?目的是?
- 看了一些博客,关于如何实现一个高并发电商。就希望通过一些框架去实现这个项目,就慢慢做下去了。
- 查询sal表里面第二大的那条记录,也就是300 | name | salary | | —- | —- | | Tom | 100 | | Mike | 200 | | Jerry | 300 | | John | 400 |
要求查询结果是:
| SecondMaxSalary |
|---|
| 300 |
解答:使用order by结合limit
select sal.salary as SecondMaxSalary order by sal.salary desc limit 1,1
解释:
desc:降序
limit:从行号为1这一条(第二条)开始,只要1条
limit:limit 1表示只要一条数据,此时就只是第一条
- sleep()和wait()的区别,追问wait()为什么要在同步代码块或同步方法里面?
数据库连接池的几个参数介绍一下
- 基本信息:
- driverClassName=com.mysql.jdbc.Driver
- url=jdbc:mysql://localhost:3306/mydb1
- username=root
- password=123
- initialSize:初始池大小,一开始池中就会有这么多个连接对象
- maxActive=8:最大活跃连接数,包括正在被使用的和空闲的
- maxIdle=8:最大空闲连接。这是从浪费系统资源角度考虑
- minIdle=8:最小空闲连接。这是从随时待命角度考虑
- maxWait=-1:最大等待时间。负数:无限等待,不抛异常
- 提交方式:默认AutoCommitted
- 只读连接:否
- 事务的隔离级别:默认为可重复读
阿里蚂蚁大数据部(二面)
- 基本信息:
ArrayList删除元素的时候要注意什么问题?有什么异常吗?
- 以太网了解吗?
- 堆排序
- 1亿条数据取前1000条,priorityQueue时间复杂度、空间复杂度
- 复盘一下统一的笔试题目?
- 虚拟内存?虚拟地址可以一样吗?虚拟地址空间可以有多大?
- linux指令?查询最占用cpu内存的进程?。。
- top:查看cpu使用情况,列出占用cpu从高到低的进程
- free:查看内存使用情况
- grep:包含指定文件名的文件
- find:找
- df:查看磁盘的使用情况
- kill -9:结束某个进程
- netstat -anp|grep port:查看某个端口的使用情况
- chmod:权限 777
- tryLock()方法失败之后做什么?
- 一般就是用if(lock.tryLock())包住代码块,如果成功,执行业务。如果失败就执行else中的代码。
- restful??put请求的url后面能带参数吗?
- GET:查询用户信息列表或者查询某个用户的信息
- POST:新建用户信息
- PUT:更新用户的的全部字段
- PATCH:更新用户的部分字段
- DELETE:删除某个用户的信息
腾讯(一面二面)
- http和https的区别
- socket编程,Time_Waited状态
- 一万条敏感词,对某句话进行敏感判断
- redis比数据库快多少倍?
- linux指令,查看cpu的一些指令
- top:查看cpu使用率、内存使用率..也有动态显示运行中的进程并且排序
- ps -aux 查看所有进程
- free查看内存情况
- C语言?
- 攻击http的漏洞有哪些?sql注入?
- 求两个字符串的最长公共子序列?什么算法?
- 动态规划:dp为一个二维数组,先把第一行和第一列的值赋上。再去用到了左边、上边、左上方这三个元素
腾讯牛客面经
- 十亿个数的集合和10w个数的集合,如何求它们的交集。集合的数字不重复
- 将10w个数据放到hashmap里面,然后遍历10亿个数据即可。节省空间
- 十亿和数找到前100个最大的
- 堆排序
- Time_Waited状态有什么用?
- 防止最后一次ACK没有被正确的传给被动方,被动关闭方会再次发送FIN信号。
- TCP四次挥手讲一下过程,最后一次ack如果客户端没收到怎么办。
- 对于socket编程,accept方法是干什么的,在三次握手中属于第几次,可以猜一下,为什么这么觉得。
//1.创建服务器端的ServerSocket,指明自己的端口号
ServerSocket ss = new ServerSocket(8899);
//2.调用accept()表示接收来自于客户端的socket
Socket socket = ss.accept();
//3.获取输入流
InputStream is = socket.getInputStream();
- accept方法是用于获取客户端的socket的,相当于获得一条TCP连接。
发生在三次握手之后,因为调用accept方法之后,就获取到了Socket对象了,就可以拿到客户端发送的数据了。肯定是建立连接之后才能这么做啊。
海量数据处理方法
第一部分,hash(x)%N分成若干小文件
海量日志数据,提取出某日访问百度次数最多的那个IP。
- 将这一个大文件分成1000个小文件,分的方法:将这个每个ip%1000,对1000取余之后,放在对应的小文件里面。(其实就是一种桶思想,分而治之)
- 对每个小文件中的每个ip进行频率统计,找出最大的ip。统计方法:hashmap。
- 1000个文件中取频率最大的ip
寻找热门查询,300万个查询字符串中统计最热门的10个查询
- hashmap统计频率
- 堆排序,top10的小顶堆。时间复杂度为300wlog10
- 有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
- 对于每个单词x,hash(x)%5000,然后按照该值存到5000个小文件
- 此题和第一题一样的,只是最后不是要最多的,需要把每个小文件中的所有词都参与比较
- 海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10。
- 若同一个数据只存在于一台电脑中,好办。直接统计每台电脑中的top10,再用堆排序排出这100个数据的top10
- 若同一数据可能分布在不同的电脑中。先通过hash(x)%10将其移动,保证同一数据只存在于同一台电脑上,再按照上述方法
- 有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
- 先通过hash(x)%10将query移动到不同的文件里面,保证相同的query一定在一个文件里面。
- 对每个文件里面的query进行频率排序(通过hashmap统计频率)。
- 对十个文件进行归并排序/堆排序
- 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
- 5×10^9×64B=320GB>>4GB,因此只能采用分治,将大文件分为1000个小文件,hash(url)%1000,将其分散带不同的文件里面。对a、b这两个大文件进行相同的操作,那么现在就有这些文件:a0,a1,a2,,,a999和b0,b1,b2,,,b999
- 显然a0只可能和b0中有交集。我们只需要对这1000对数据分别取交集就行了。具体取的方法:hashset
- 1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
- 如果太大没法一次读入内存,hash取模分成小文件,分别去重,合并即可
第二部分,多层划分
第三部分,索引、倒排索引等等
美团牛客
- mysql事务隔离级别和实现原理(mvcc):https://blog.csdn.net/suifeng629/article/details/99412343
- 读未提交:select加共享锁,增删改加排它锁
- 读已提交:select通过mvcc版本去读,读到最新的版本。有增删改的事务提交之后才会改变版本
- 可重复读:一个事务里面,第一次select的是哪个版本,后面select的还是这个版本,无论该版本是否更新,从而保证了可重复读
- 串行化:select也会加排它锁
- redis主从复制、redis哨兵机制、redis脑裂解决方案
- java8新特性
- JVM G1和CMS区别
- G1是针对整个堆内存的,CMS仅仅是清理老年代
- G1将内存分为一块块的region,分别回收。适合大内存的机器,因为大内存的机器如果对整个堆进行清理,会很慢。
- CMS采用标记清除算法,容易产生垃圾碎片,而G1不会产生
- 二者的清理过程都是:
- 初始标记-并发标记-重新标记-并发清理
- 其中1、3都有STW
- redis 如何实现高并发和高可用
- 高并发:主从复制🡪主负责写,从负责读
- 高可用:主备切换,master宕机了,slave顶上
- MYSQL如何优化
- 见“百度”章节
- 线程安全的类有哪些,平时有使用么,用来解决什么问题
- 线程安全集合类:vector/hashtable/concurrenthashmap/阻塞队列
- FutureTask+callable
- CompletableFuture
- mysql日志文件有哪些,分别介绍下作用
- redo-log
- undo-log
- binlog
- 你们项目为什么用redis,快在哪,怎么保证高性能,高并发的
- redis字典结构,hash冲突怎么办,rehash,负载因子
- jvm了解哪些参数,用过哪些指令
- -Xmx4g:堆内存最大值为4GB。
- -Xms4g:初始化堆内存大小为4GB 。
- -Xmn1200m:设置年轻代大小为1200MB。增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
- -Xss512k:设置每个线程的堆栈大小。
- 一个热榜功能怎么设计,怎么设计缓存,如何保证缓存和数据库的一致性
- 使用list作为存储结构,ltrim key1 0 3 这条指令会删除0-3这四条数据以外的元素。我们如果按照时间顺序插入到list,可以保留前多少条最新评论。
- 可以用zset再去保存一个点赞数最高的前多少条数据
- 因为评论无需全量保存
- redis集群,为什么是16384,哨兵模式,选举过程,会有脑裂问题么,raft算法,优缺点
- jvm类加载器,自定义类加载器,双亲委派机制,优缺点,tomcat类加载机制
- 阿里钉钉
- tomcat热部署,热加载了解么,怎么做到的
- cms收集器过程,g1收集器原理,怎么实现可预测停顿的,region的大小,结构
- cms:
- 初始标记:根可达
- 并发标记:和用户进程一起
- 重新标记:最终确定,修正并发标记时导致的一些错标
- 并发清除:和用户进程一起
- g1怎么实现可预测停顿的:
- 因为它有计划的避免在整个Java堆中进行全区域的垃圾收集。G1跟踪各个Region里面的垃圾堆积的大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region。这样就保证了在有限的时间内可以获取尽可能高的收集效率。
- cms:
- 内存溢出,内存泄漏遇到过么,什么场景产生的,怎么解决的
- 锁升级过程,轻量锁可以变成偏向锁么,偏向锁可以变成无锁么,自旋锁,对象头结构,锁状态变化过程
- 怎么理解分布式和微服务,为什么要拆分服务,会产生什么问题,怎么解决这些问题
- 服务的发现:ip+端口号让客户端、调用者知道
- Innodb的结构了解么,磁盘页和缓存区是怎么配合,以及查找的,缓冲区和磁盘数据不一致怎么办,mysql突然宕机了会出现数据丢失么
- redis字符串实现,sds和c区别,空间预分配
- redis有序集合怎么实现的,跳表是什么,往跳表添加一个元素的过程,添加和获取元素,获取分数的时间复杂度,为什么不用红黑树,红黑树有什么特点,左旋右旋操作
- 怎么理解高可用,如何保证高可用,有什么弊端,熔断机制,怎么实现
- 对于高并发怎么看,怎么算高并发,你们项目有么,如果有会产生什么问题,怎么解决
美团一面
- Future和CompletableFuture:研究一下
- ThreadLocal和参数传递,为什么不用参数传递?ThreadLocal原理
- sorted set的底层原理skiplist
- spring有哪些开发者可以改变的地方?
- 为什么要用redlock?自己用redis实现分布式锁不也很简单吗?
- 算法题:字符串相乘?
- 说说你用的这些框架的源码?
美团一面
- ConcurrenHashMap的源码细节?
- hash冲突如何解决?源码?
- 多线程如何实现:线程池的几个参数,全都要??
- 封装、继承、多态?
- 项目:如何保证写数据库和写redis同时成功、同时失败?项目没做
- redis底层源码熟悉吗?
- 为什么要再次检查redis里面有没有?查redis里面没有的话,写redis的过程太慢了,导致其他线程都要等待,这个怎么解决?
- 使用Runnable和Thread两种方式创建线程有什么区别?
hr面
1一上来介绍一下自己和所做的项目
基于springboot+springcloud做的一个小型的电商平台
数据库设计
模块:
2介绍项目过程中遇到的最大难点
引入缓存之后导致的问题:锁时序问题、缓存击穿问题的解决
购物车如何实现对登录和未登陆状态的区分
解决提交订单的幂等性问题:数据库的唯一约束和token机制
JSR303分组校验,不算是难点,但很巧,很方便
订单模块的消息队列还没解决
3这个项目还有没有其他参与的人,说一下其他人的主要工作
主要还是自己独立完成的,做这个项目主要是为了强化一下自己的技术栈,对技术有进一步的认识。在做之前倒请教过已经工作的同学,他觉得商城系统需要用到很多的技术栈,很适合锻炼,于是就参考了博客上面很多大佬的思路,做了一个这样的项目。
4这个项目有没有其他可支撑或者参考的人
有,博客上jeason
5怎么评价这个项目完成的好坏
功能模块:是否满足用户的需求,这是基础。
性能:吞吐量(优化业务、技术栈等等),能否承受住高并发。可靠性
经济性:优化业务,减少服务器的个数。比如session的存储方案
6除了这个项目还有没有其他项目
7职业规划
希望在一个有沉淀的互联网公司一直做下去,从业务开始,毕竟头一次参加工作,可能一开始会觉得有些陌生,但自己相信能积极学习,把自己不懂的业务通过学习、向大佬请教,逐渐变成一个技术上的大牛。随着懂得越来越多,慢慢成长,自己希望能变成一个技术上的主管,如果可能的话,最终希望能成为一个后端开发的架构师。
8为什么选择蚂蚁金服这个岗位(一是为什么选这个岗位,二是为什么选这个部门,要两点都答)
众所周知,蚂蚁旗下有很多产品,比如支付宝、余额宝、芝麻信用等等。尤其是支付宝,每秒钟能处理十多万的交易,而且交易风险也低于十万分之一,这个在技术上是非常了不起的,在国内和国际上都是顶尖水平,因此我认为蚂蚁是一个非常有技术实力和沉淀的地方。
为什么选这个部门:
大数据是个非常有前景的方向,即便在IT行业也是如此。而且,在信息化时代、互联网时代,数据量会越来越大,大数据的高效处理在未来的作用也越来越大。在项目上面来说,意味着数据并发量会越来越大,这对于我们的的一些项目会产生巨大压力,如何高效处理海量数据,提高系统的高可用,对程序员来说都是巨大的挑战,也是巨大的机遇。
9本科和研究生成绩
9本科研究生都就读软件工程这个专业,是哪些点吸引你让你喜欢这个专业
10问竞赛经历
节能减排大赛:建模仿真
湖北省翻译大赛:省三等奖
你还有什么问题问我?
为了更好地胜任这个岗位,我还需要补充哪些技能?
入职后是否有产品培训和技能培训?
接下来的流程是什么?
如何评估员工在试用期间的表现?
快手牛客一面
- 介绍一下mysql索引
- 是什么,优点。
- 分类:用的多的是主键索引、普通索引
- 数据结构b+树大体是个什么样的,有哪些优点
- (name,age,city)联合索引,name=’xx’ and age>12 city=’dd’用到的索引
- 前两个。因为age按照范围查的时候,city就不是按顺序排列的了
- 非聚簇索引非索引项叶子节点的其他数据是什么:主键和其他带索引的列数据
- 非聚簇索引和聚簇索引非叶子节点所存的数据是什么?
- 该索引的值呀
- 覆盖索引是什么
- 避免了回表查询。。以主键索引和普通索引举例(有点蒙,辅助索引的叶子节点是只存储了聚簇索引的值吗?)
- 隔离级别
- 可重复读:可能导致幻读
- 实现原理:美团牛客
- mysql锁
- 共享锁、排它锁、行锁、间隙锁。
- 过滤器是由的由谁提供的,拦截器是由谁提供的?
- 前者先执行,前者由servlet提供,后者由springmvc提供
- volatile
- 保证多个线程执行的时候,读在写之后执行
- 不能保证原子性,还得用原子类
腾讯一面
败还是败在现场撸算法
- 进程间通信方式?
- 信号量:该数据结构保证只有n个进程能进入临界区代码
- 共享内存:多个进程共享这一块内存
- 套接字:客户端和服务端进程之间的网络通信
- 管道:匿名管道、有名管道
- 消息队列:
- redis主从复制了解吗?(只是听说了哨兵模式)
简化文件路径
找出大于其他元素两倍的元素
sql
有一个用户表user(user_id)和一个文章表article(user_id, article_id),找出所有未发文用户的user_id
除了not in还有哪些方法?
腾讯二面
Linux操作指令了解吗?ping?
字节跳动四面
- 手写一个线程池
- 302、100?http状态码?
- 302表示重定向
- 100表示请求者需要继续发送请求
- ThreadLocal和参数传递,为什么不用参数传递?ThreadLocal原理
- 反射,结合spring说
- 进程在虚拟内存里面由哪几个部分组成
- 项目中的Token
- 终止线程的方式,stop的缺点?手写一个线程池?volatile关键字的作用?
-
字节支付业务(一面)
序列化和反序列化?java自带的序列化规则是什么?
- volatile关键字的作用?举个线程可见性安全的例子?指令重排是谁重排的?
- Spring中Autowired和Resource注解的区别?spring怎么样解耦的?
- wait()方法是怎样阻塞队列的?(底层)
- CountDownLatch不要忘记了
抖音面试(9.2)
- 请求方式有哪几个?
- http状态码:1开头的是?
- 进程间的通讯方式
- I/O模型有几种?
- TCP怎么保障可靠性传输的?
- 开发中如何实现串行化?
- MVCC底层实现?
- 算法:最大矩形
华为
技术面
设计模式:写一个单例模式。线程安全怎么去设计?
泛型快排怎么写?
防止sql注入:白名单
课程表算法
项目相关
你是不是很懂hadoop、flink这些?
8.手撕代码 leetcode692 前K个高频单词
hr面
1.自我介绍
2.介绍课题
3.学习遇到的困难
4.你觉得你的优点是什么 举个例子
5.反问环节
为什么选择华为
2、 为什么选择开发,开发很辛苦的balabala
3、 实习的同事怎么评价你
4、 还跟我聊了下5G,问我怎么看待5G
聊研究生的事情,学了什么课,自己觉得优势在哪,以后想在哪发展
腾讯
工厂模式和抽象工厂模式用分别在哪些地方?
链表和数组的存储结构?存在什么位置..
Future的原理?Future是怎么保证线程安全的?
待解决
设计模式:写一个单例模式。线程安全怎么去设计?(细一点)
泛型快排怎么写?
防止sql注入:白名单
课程表算法
还有哪些导致索引失效的场景?
除了OOM、StackOverFlow还有哪些内存溢出?
RPC的底层原理上讲,和http的区别?
indexOf(Object o)方法:返回第一个o元素,调用的是equals方法。
addAll():合并两个list?
MyBatis的xml里面有哪些标签?
spring里面bean的作用域有哪些?在哪指定?
<bean id="person" class="com.mengma.scope.Person" scope="singleton"/>
@Component("testBean2")@Scope("prototype")public class TestBean {}
spring属性注入有哪些方式?@Autowired是什么?
项目里面:万一某台服务器宕机了会怎么办?
如图所示,第三台机器宕机之后,映射关系就会改变,3号任务原来是由0号机器执行的,现在1号机器也能抢3号任务了,为了防止这种3号任务同时被两台机器执行,就将3号任务对应的gmt_scheduled改为未来的1min,目的就是为了等待0号机器执行完,才可能被1号机器执行。

若有收获,就点个赞吧
0 人点赞
