一、二进制与字符编码
(1)二进制
位,
表示更多的状态的话增加计算机识别位置,一般计算计算机识别为八位(bit),
两个位置的话会有-00,01,11,10四种状态
八个位置的话会有2种状态
单位换算关系
8个bit=1个byte(字节)
1024byte=1KB(千)
1024KB=1MB(兆)
1024MB=1GB(吉)
1024GB=1TB(太)
(2)字符编码
计算机识别的八位的256种状态对应256种编码,并且编制成ASCIII字符表
ASCIII字符表中: 0~127种128种状态对应128中现实生活中的符号
A对应ASCII字符表中65号,通过calc计算器找到程序员型
十进制的65 改成二进制1000001
中国和国际字符表
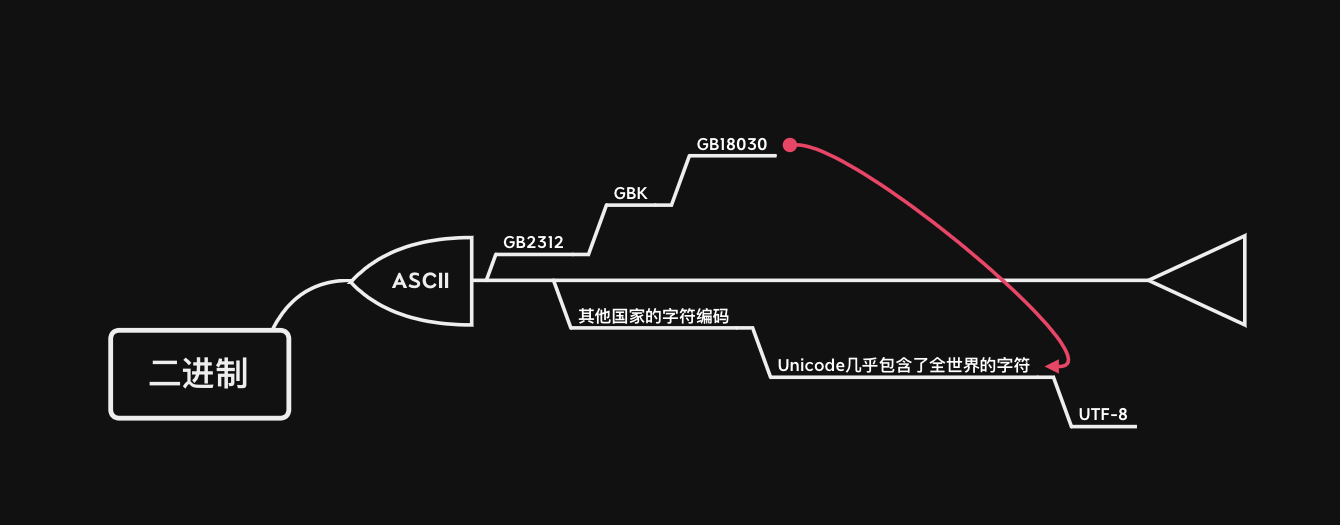
ASCII:为了人们方便记忆二进制字符码表格
中国:
GB2312: 1980年推出表示简体中文字符
GBK: 1995年推出简体和繁体中文
GB18030: 2000年推出含有少数民族语言的字符表(每个字符由一个、两个甚至四个组成)
Unicode:为避免中国与其他国家的字符表出现混乱,统一编制
UTF-8: 规定二次码表中英文用一个字节表示而中文用三个字节表示
用python输出“乘”字
(1)找到字符表中乘字的编码,4E58,
(2)打开calc计算器,找到程序员型,找到十六进制,输入4E58

(3)换成二进制得到100111001011000

(4)打开pycharm新建一个test.py代码页输入
print(chr(100111001011000)) #chr是一个函数
问题
此时会出现字符串太长翻译不出来,这是因为这里面是二进制翻译不出来

解决办法
在数字前面加上0b
print(chr(0b100111001011000)) #0b表示二进制

(5)再输入以下代码得到其十进制
print(ord("乘"))

(6)找到calc计算器找到“乘”的十进制

总结:
在计算机中,中文还是英文都叫做字符,一个字符对应一个整数,整数可以使用十进制、八进制、二进制或十六进制。到最后在计算机中都会转换成二进制这样计算机才能识别。
二、python中的标识符和保留字
保留字
有一些单词被python赋予了特定的定义,在我给任何对象起名字的时候不能使用
import keword #keyword是关键词print(keyword.kwlist) #kwlist是keyword的一个列表

问题
先建立了一个keyword.py的文件夹
import keyworldprint(keword.kwlist)

出现了模块找不到的错误
分析:
可能是因为我创立的文件名和我输入代码中单词一样导致错误,
解决办法:
另立文件名为keyword_demo
标识符
注意
- 字母、数字、下划线
- 不能以数字开头
- 不能是python的保留字
- 严格区分大小写
三、变量的定义与使用
(1)变量
变量就是一个内存中带标签的盒子,我们把需要的数据放进去。
name=‘玛丽’
name(变量名)
=(赋值运算符)
‘玛丽’(值)name='玛丽'print(name)

(2)变量的使用
概念
标识
表示对象所存储的内存地址,通过内置函数id(obj)来获取类型
表示对象的数据类型,使用内置函数type(obj)来获取值
表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
将name=‘玛丽’进id、类型和值进行输出
输出错误name='玛丽'print(name)print('标识',id())print('类型',type)print(name)

解决办法
代码中没有给id和type具体的对象,输入具体的对象print('标识',id(name))print('类型',type(name))print('值'name)
变量name实际上存储的就是他这个变量的id 注意
注意(3)变量的多次赋值
(1)当多次赋值后,变量名会指向新的空间
name='玛丽'name='张三'print(name)

(2)输出上述代码的标识、类型和值
之前输出的name='玛丽'name='张三'print('标识',id(name))print('类型',type(name))print(name)
标识 2187971112656
类型
玛丽
变成了内存垃圾(由相应的处理器处理)四、数据类型
常用的数据类型:
整数类型——-int———98
浮点数类型—-float——3.1415926
布尔类型——-bool——-True,False(只可以取两个值-真或者假)
字符串类型—str————(只要加上单引号、双引号和三引号就称作字符串类型)整数类型
英文为integer,简写为int,可以表示正数、负数和零整数的不同进制表示方式
- 十进制————默认的进制
- 二进制————以0b开头
- 八进制————以0o开头
- 十六进制——-以0x开头

操作
输出类型
n1=90n2=-70n3=0print(n1,n2,n3)
 输出上述代码的数据类型
输出上述代码的数据类型
n1=90n2=-70n3=0print(n1,type(n1))print(n2,type(n2))print(n3,type(n3))

整数表示为二进制、十进制、八进制和十六进制
十进制
print('十进制',118)

二进制
print('二进制',10101111)
此时是读不出来这个数是多少,因为电脑不识别
因为我们要在二进制前面加上0b
print('二进制',0b10101111)
最后得出该数为:175
通过calc计算器验证结果是对的
八进制
print('八进制',0o176)

通过calc计算器验证成功 十六进制
十六进制
print('十六进制'0x1EAF)


浮点类型
浮点类型由整数部分和小数部分组成
a=3.14159print(a,type(a))

浮点数存储不精确
使用浮点进行计算时,可能会出现小数点位数不确定的情况
n1=3.1n2=2.2print(n1+n2) #5.300000000000001print(n1+n2) #5.3
为什么结果后面多很多零
解决办法
因为计算机是采用二进制进行浮点数的计算所以储存浮点数会有不精确,通过导入模块decimal让计算机按照我们的要求进行计算存储。
from decimal import Decimalprint (Decimal('3.1')+Decimal('2.2'))

出现错误
问题分析
是因为之前我创建的keword安装包和使用decimal出现冲突
IMPORTERROR: CANNOT IMPORT NAME ‘ISKEYWORD’_enemy_sprites的博客-CSDN博客
https://blog.csdn.net/enemy_sprites/article/details/102681366

布尔类型
英文boolean简写为bool
f1=Truef2=Falseprint(f1,type(f1))print(f2,type(f2))

- 用来表示真或假的值
- True表示真,False表示假
布尔值可以转化为整数
True——-1
False——0print(True+1) #1加1等于2 true表示1print(False+1) #0加1等于1 false表示0
字符串类型
字符串又被不可变的字符序列
可以使用单引号 ‘ ‘ 双引号 “” 三引号 ‘’’ ‘’’或””” “””
单引号和双引号定义的字符串必须在一行
三印号定义的字符串可以分布在连续多行str1='人生苦短'str2="唯有杜康"str3="""人生苦短唯有杜康"""print(str1,type(str1))print(str2,type(str2))print(str3,type(str3))
数据类型转换
一、为什么需要数据类型转换?
二、数据类型转换
```python name=’张三’ age=20 print(type(name),type(age)) #说明name与age的数据类型不一样


当将str类型与int类型进行连接时,报错。<br />```pythonname='张三'age=20print(type(name),type(age)) #说明name与age的数据类型不相同print('我叫'+name+'今年,'+age+'') #加号在其中的意思是连接符当将str类型与int类型进行连接时报错解决:类型转换print('我叫'+name+'今年,'+str(age)+'') #将int类型通过str()函数转换成str类型

(1)print(‘——str()将其他类型转换成str类型’)
首先将各种函数的类型用type函数表达出来,再用str()函数转换,最后用type函数检验转化是否成功
a=10b=198.8c=Falseprint(type(a),type(b),type(c))print(str(a),str(b),str(c),type(str(a)),type(str(b)),type(str(c)))

(2)prinnt(‘——int()将其他类型转换成int类型’)
s1='128'f1=98.7s2='76.77'ff=Trues3='hello'print(type(s1),type(f1),type(s2),type(ff),type(s3))print(int(s1),type(int(s1))) #将str转换成int类型,字符串为数字串print(int(f1),type(int(f1))) #将float转换成int类型,抹零取整,截取整数部分舍去小数部分print(int(s2),type(int(s2))) #将str转换成int类型,报错,因为字符串为小数串print(int(ff),type(int(ff))) #将布尔类型转换成int类型,true可以当做1来运算print(int(s3),type(int(s3))) #将str转换成int类型时,字符串必须为数字串(整数),非数字串不允许转换
报错情况
注意
- 文字和小数类字符串,无法转化为整数
- 浮点数转化为整数:抹零取整
(3)prinnt(‘——float()将其他数据类型转换成float类型’)
s1='128.98's2='76'ff=Trues3='hello'i=98print(type(s1),type(s2),type(ff),type(s3))print(float(s1),type(float(s1)) )print(float(s2),type(float(s2)))print(float(ff),type(float(ff)))#print(float(s3),type(float(s3))) #字符串中的数据如果是非数据串,则不允许转换print(float(i),type(float(i)))

注意
- 文字无法转换为整数
-
五、python
注释
在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性
- 注释的内容会被Python解释器忽略
单行注释
———-以”#”开头,直到换行结束。#输出功能(单行注释)print('hello')
多行注释
———并没有单独的多行注释标记,将一对三印号之间的代码(三引号可以随意换行)'''嘿嘿我是多行注释'''
中文编码声明注释
———在文件开头加上中文声明注释,已指定源码文件的编码格式 #coding:*
首先找到demo——9的文件位置
点击file path找到文件所在位置,用记事本打开该文件,点击文件找到另存并点击
在这里我们可以看到它的编码模式时UTF-8,
更改编码模式方法—-
新建demo_10文件
在文件中用记事本打开新建demo_10,然后另存为,我们会看到编码换成了ANSI(包含我们输入的gbk)
把文件开头的中文注释改成
它的编码模式又换成了UTF-8#coding:utf-8


若有收获,就点个赞吧
0 人点赞
