(一)引言
N-gram是自然语言处理中常见一种基于统计的语言模型。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。每一个字节片段称为gram,在所给语句中对所有的gram出现的频数进行统计。再根据整体语料库中每个gram出现的频数进行比对可以得到所给语句中每个gram出现的概率。N-gram在判断句子合理性、句子相似度比较、分词等方面有突出的表现。
(二)朴素贝叶斯(Naive Bayes)
首先我们复习一下一个非常基本的模型,朴素贝叶斯(Naive Bayes)。朴素贝叶斯的关键组成是贝叶斯公式与条件独立性假设。可以参考(https://www.yuque.com/dadahuang/tvnnrr/gksobm)。为了方便说明,我们举一个垃圾短信分类的例子:
假如你的邮箱受到了一个垃圾邮件,里面的内容包含:
“性感荷官在线发牌…”
根据朴素贝叶斯的目的是计算这句话属于垃圾短信敏感句子的概率。根据前面朴素贝叶斯的介绍,由 可得:
可得:
P(垃圾短信|“性感荷官在线发牌”) 正相关于 P(垃圾邮件)P(“性感荷官在线发牌”|垃圾短信)
由条件独立性假设可得:
P(“性感荷官在线发牌”|垃圾短信) = P(“性”,”感”,”荷”,”官”,”在”,”线”,”发”,”牌”|垃圾短信) = P(“性”|垃圾短信)P(“感”|垃圾短信)P(“荷”|垃圾短信)…P(“牌”|垃圾短信)
上面每一项条件概率都可以通过在训练数据的垃圾短信中统计每个字出现的次数得到,然而这里有一个问题,朴素贝叶斯将句子处理为一个“词袋模型(Bag-of-Words, BoW)”,以至于不考虑每个单词的顺序。这一点在中文里可能没有问题,因为有时候即使把顺序打乱,我们还是能看懂这句话在说什么,但有时候不行,例如:
“我喜欢打游戏”跟“游戏喜欢打我”意思就变了。
下面就介绍考虑到语句中单词之间顺序的语言模型——N-gram
(三)N-gram模型
(1) 概念
N-gram是一种语言模型N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。比如:
假设你在和一个外国人交流,他说了一句“I have a gun”,但是由于他的发音不标准,到你耳朵里可能是“I have a gun”、“I have a gull”或“I have a gub”。那么哪句话是正确的呢?。假设你根据经验觉得有80%的概率是“I have a gun”,那么你已经得到一个N-gram的输出。即:
P(**I have a gun) = 80%
N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N=2) 和 Tri-gram (N=3),一般已经够用了。例如在“I love deep learning”这句话里,可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : **{I, love, deep}, {love, deep, learning}
(2) 概率计算
假设你并不知道马尔科夫假设(Markov Assumption),那么我们该如何计算N-gram的输出,即一个句子的概率呢。给定一个句子S=( ),首先假设句子中的每个单词
),首先假设句子中的每个单词 都依赖于第一个单词到它前一个单词
都依赖于第一个单词到它前一个单词 的影响,则这个句子的概率为(
的影响,则这个句子的概率为( ):
):
但是,显而易见,这种计算方法有两个缺陷:
- 参数空间过大,计算量太大:p(w3|w_1w_2)···p(w_n|w{n-1}···w_2w_1)的参数就有O(n)个。
- 数据稀疏严重:词同事出现的情况很大可能没有。组合阶数越大越明显。
(3) 引入马尔科夫假设

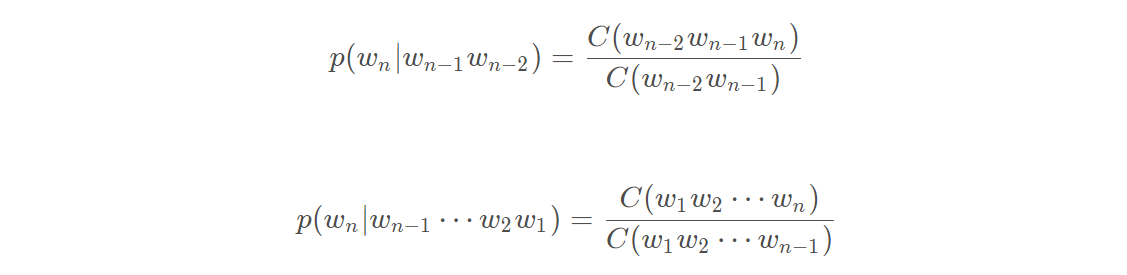
举个例子:以Bi-gram为例。假如有三句话:“you like cat”、“he like cat and dog”,“he like you”。
根据统计可得 “you”出现了3次,“you like”出现了1次。则根据公式得:
同理:
再提供一个经典的例子:
《Language Modeling with Ngrams》中,Jurafsky et al., 1994 从加州一个餐厅的数据库中做了一些统计:

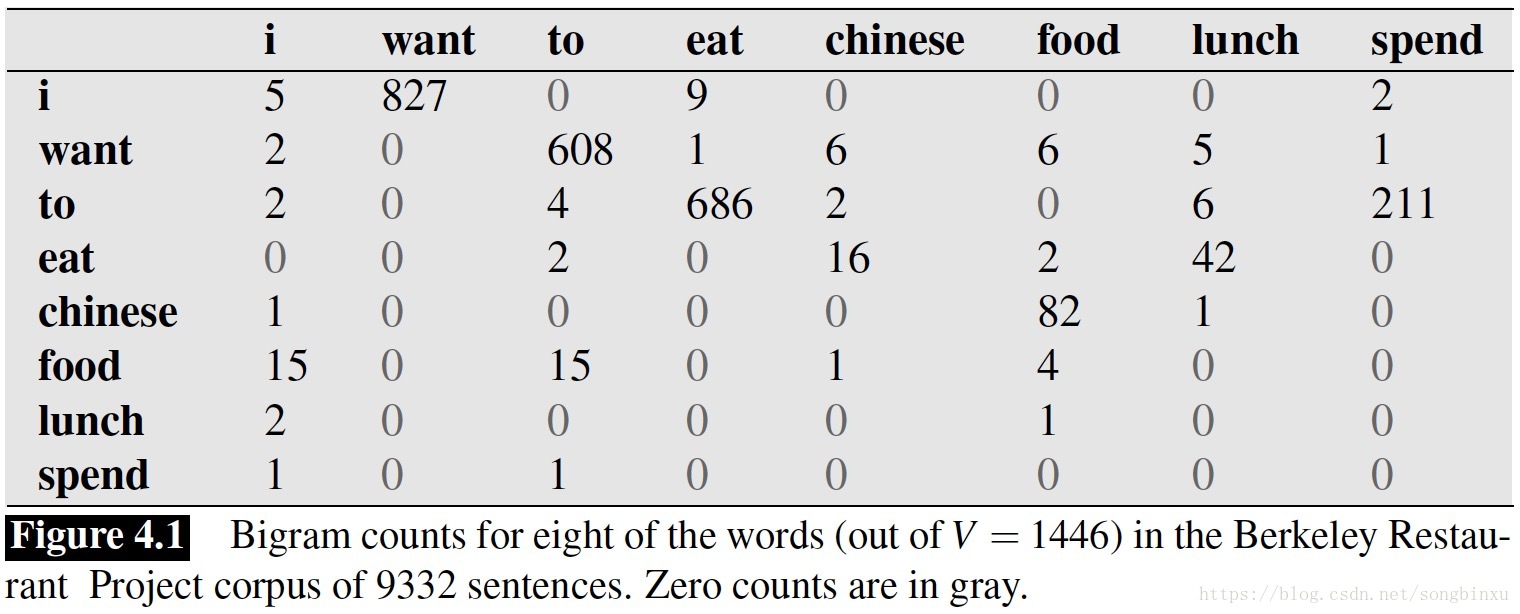
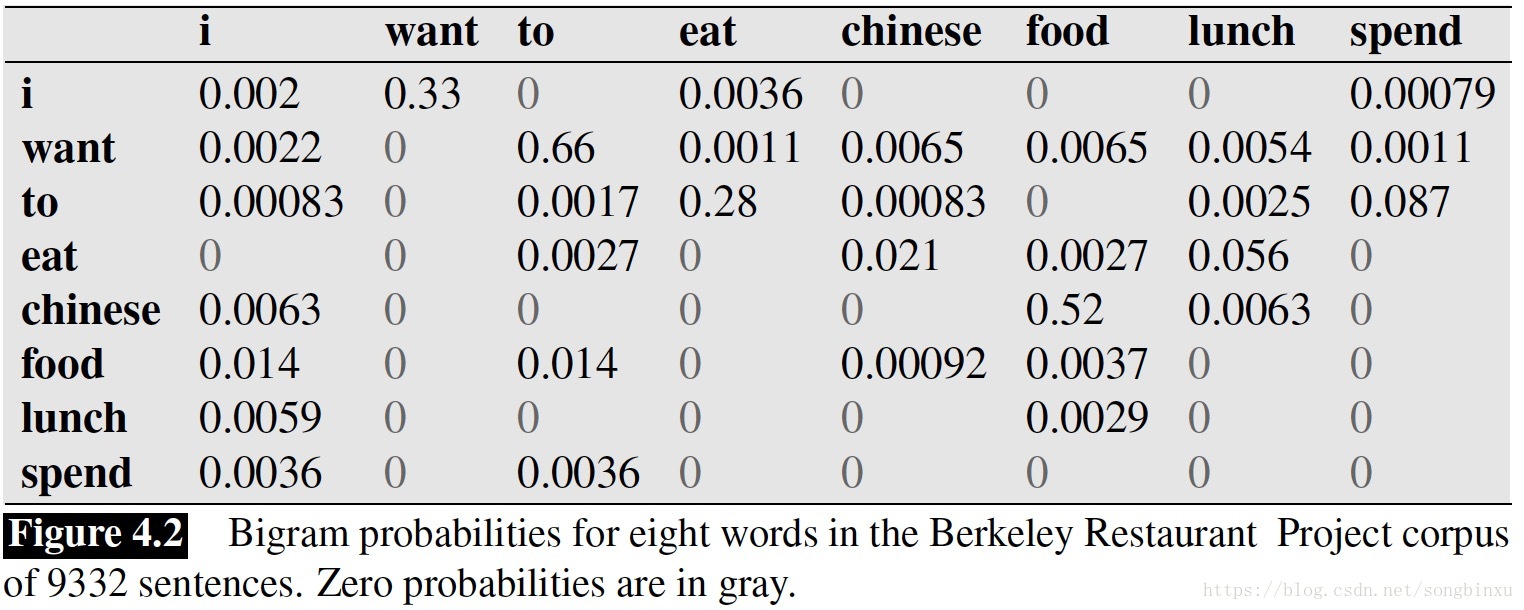
据统计,  则“I want chinese food”这句话的概率为:
则“I want chinese food”这句话的概率为:

如果一段话很长,则结果会很小(约等于0),这时可以用log概率来做。
(4) N-gram中的数据平滑方法
n-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有20k个词,那么两两组合 就有近2亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
就有近2亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的n-gram概率都不为0。它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。


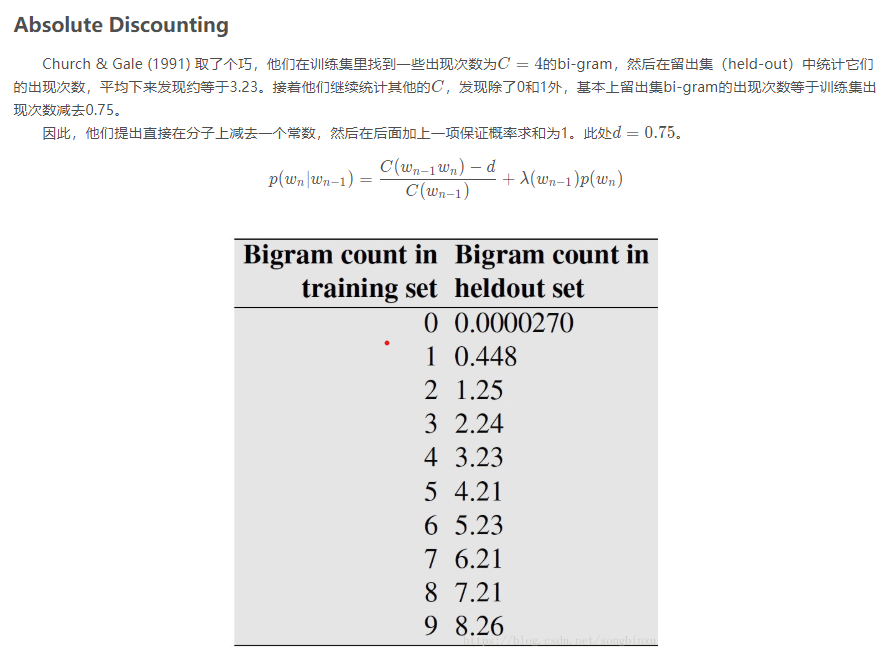
(4) N-gram对训练数据集的要求
关于N-gram的训练数据,如果你以为“只要是英语就可以了”,那就大错特错了。文献《Language Modeling with Ngrams》**的作者做了个实验,分别用莎士比亚文学作品,以及华尔街日报作为训练集训练两个N-gram,他认为,两个数据集都是英语,那么用他们生成的文本应该也会有所重合。然而结果是,用两个语料库生成的文本没有任何重合性,即使在语法结构上也没有。
这告诉我们,N-gram的训练是很挑数据集的,你要训练一个问答系统,那就要用问答的语料库来训练,要训练一个金融分析系统,就要用类似于华尔街日报这样的语料库来训练。


参考资料:

若有收获,就点个赞吧
0 人点赞
