为什么使用线程池
在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理。如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题:
如果并发的请求数量非常多,但每个线程执行的时间很短,这样就会频繁的创建和销毁线程,如此一来会大大降低系统的效率。可能出现服务器在为每个请求创建新线程和销毁线程上花费的时间和消耗的系统资源要比处理实际的用户请求的时间和资源更多。
那么有没有一种办法使执行完一个任务,并不被销毁,而是可以继续执行其他的任务呢?
这就是线程池的目的了。线程池为线程生命周期的开销和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到了多个任务上。
什么时候使用线程池?
- 单个任务处理时间比较短
- 需要处理的任务数量很大
好处:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池总体机制
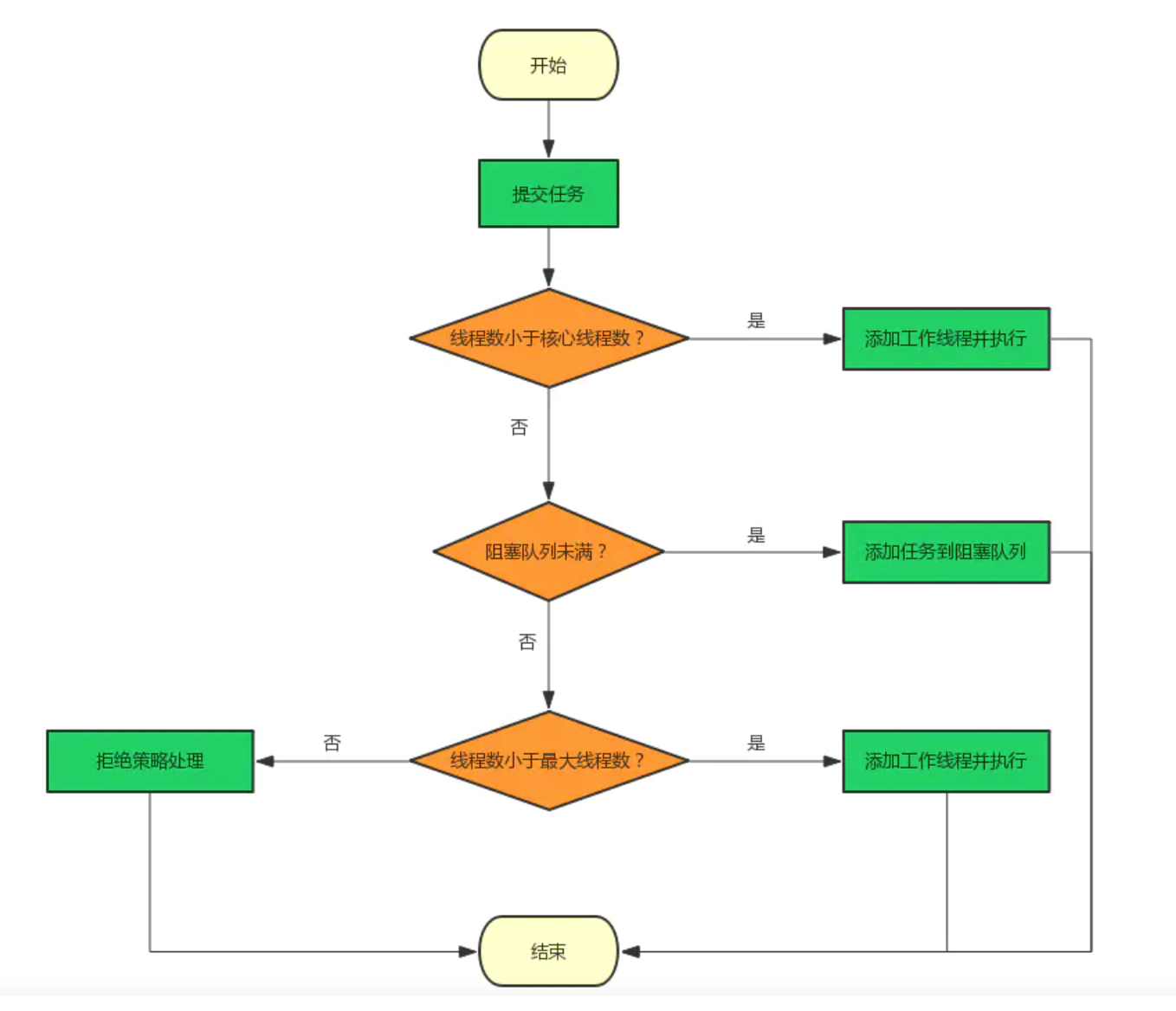
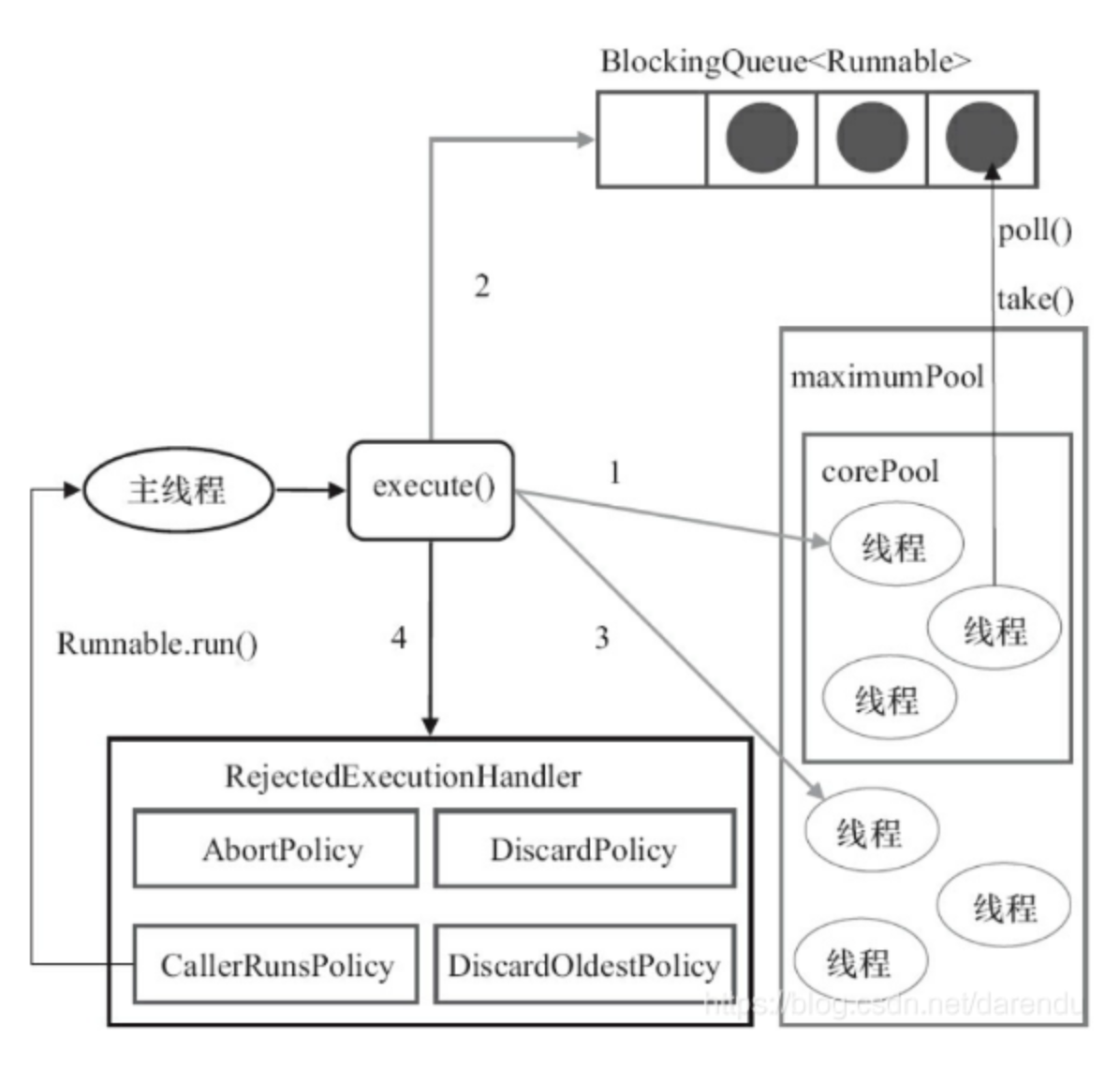
线程池的完整构造函数及含义
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory, RejectedExecutionHandler handler)
corePoolSize/maximumPoolSize
- corePoolSize:线程池中核心线程数量。
- maximumPoolSize:线程池同时允许存在的最大线程数量。
内部处理逻辑如下:
- 当线程池中工作线程数小于corePoolSize,创建新的工作线程来执行该任务,不管线程池中是否存在空闲线程。
- 如果线程池中工作线程数达到corePoolSize,新任务尝试放入队列,入队成功的任务将等待工作线程空闲时调度。
- 如果队列满并且线程数小于maximumPoolSize,创建新的线程执行该任务(注意:队列中的任务继续排序)。
- 如果队列满且线程数超过maximumPoolSize,拒绝该任务。
keepAliveTime
当线程池中工作线程数大于corePoolSize,并且线程空闲时间超过keepAliveTime,则这些线程将被终止。同样,可以将这种策略应用到核心线程,通过调用allowCoreThreadTimeout来实现。
非核心线程的线程空闲时间达到keepAliveTime的话就会被回收直至线程数为corePoolSize,开启allowCoreThreadTimeOut的话,所有线程空闲时间达到keepAliveTime的话会被回收直至线程数为0。
BlockingQueue
任务等待队列,用于缓存暂时无法执行的任务。分为如下三种堵塞队列:
- 直接递交。如SynchronousQueue,该策略直接将任务直接交给工作线程。如果当前没有空闲工作线程,创建新线程。这种策略最好是配合unbounded线程数来使用,从而避免任务被拒绝。但当任务生产速度大于消费速度,将导致线程数不断的增加。一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
- 无界队列。如LinkedBlockingQueue,当工作的线程数达到核心线程数时,新的任务被放在队列上。因此,永远不会有大于corePoolSize的线程被创建,maximumPoolSize参数失效。这种策略比较适合所有的任务都不相互依赖,独立执行。但是当任务处理速度小于任务进入速度的时候会引起队列的无限膨胀。一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- 有界队列。如ArrayBlockingQueue,按前面描述的corePoolSize、maximumPoolSize、BlockingQueue处理逻辑处理。队列长度和maximumPoolSize两个值会相互影响,是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
ThreadFactory
线程池中的工作线程通过ThreadFactory来创建的,如果没有指定,默认为Executors#defaultThreadFactory。这个时候创建的线程将都属于同一个线程组,拥有同样的优先级和daemon状态。采用自定义的ThreadFactory,可以配置线程的名字、线程组合daemon状态。如果调用ThreadFactory#createThread的时候失败,将返回null,executor将不会执行任何任务。
RejectedExecutionHandler
当新的任务无法进入等待队列且线程数已达maximumPoolSize上线时,需要定制拒绝策略,拒绝该任务。ThreadPoolExecutor提供了如下可选策略:
- ThreadPoolExecutor#AbortPolicy:这个策略直接抛出RejectedExecutionException异常。
- ThreadPoolExecutor#CallerRunsPolicy:这个策略将会使用Caller线程来执行这个任务,这是一种feedback策略,可以降低任务提交的速度。
- ThreadPoolExecutor#DiscardPolicy:这个策略将会直接丢弃任务。
- ThreadPoolExecutor#DiscardOldestPolicy:这个策略将会把任务队列头部的任务丢弃,然后重新尝试执行,如果还是失败则继续实施策略。
除了上述策略,可以通过实现RejectedExecutionHandler来实现自己的策略。
源码解析:
https://www.jianshu.com/p/d2729853c4da
如何制定线程数数量
https://blog.csdn.net/byteArr/article/details/96590084
1. CPU密集型任务
要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
一般配置线程数=CPU总核心数+1 (+1是为了利用等待空闲)
2. IO密集型任务
这类任务的CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。常见的大部分任务都是IO密集型任务,比如Web应用。对于IO密集型任务,任务越多,CPU效率越高(但也有限度)。
一般配置线程数=CPU总核心数 2 +1
线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程*
需要根据几个值来决定
tasks :每秒的任务数,假设为500~1000
taskcost:每个任务花费时间,假设为0.1s
responsetime:系统允许容忍的最大响应时间,假设为1s
https://zhuanlan.zhihu.com/p/118077275
面试题库
https://blog.csdn.net/qq_29373285/article/details/85238728
线程池使用
https://blog.csdn.net/qq_38428623/article/details/86688523

若有收获,就点个赞吧
0 人点赞
