浮点数
1.2e-5 0.000012
转义符
在python中 ‘’也需要转移,所以比如 换行符变成了 \n
地板除
10//3 >>> 3
list
计算List长度len(),要将某个元素加入list,使用insert(i,""),删除则用pop(i),追加到末尾使用append(),
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
for i in range(5):# 0 1 2 3 4
dict
dict={}
删除一个key用pop
set=([]),set没有重复的key,不存储value,两个set可以做数学集合操作。
d.items打印key和value,d.key,d.value
函数
return 可以返回多个值,实际上返回一个tuple。
必选参数在前,默认参数在后。
默认参数必须指向不变对象
可变参数
*arg
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,
因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
关键字参数
**kwarg
可变参数和关键字参数的区别:可变参数传入的是一个tuple,关键字参数传入的是一个dict
切片
L[0:3] == L[:3]
前10个数,每两个取一个:>>> L[:10:2][0, 2, 4, 6, 8]
enumerate函数可以把一个list变成索引-元素对
>>> for i,j in enumerate(a):... print(i,j)0 11 22 3
列表生成器
生成i*i的列表
[x * x for x in range(1,11)]
后面加上if判断,就可以筛选出仅有偶数的平方
[x * x for x in range(1,11) if x%2 == 0]
还可以使用两层循环生成全排列
[m + n for m in 'ABC' for n in 'XYZ']
比如列出目录
d for d in os.listdir('.')
for循环其实可以同时使用两个甚至多个变量
for k, v in d.items():
生成器
使用next()调用
- 把列表生成器的[]变成()
>>> a=(m+n for m in 'ABC' for n in 'XYZ')>>> next(a)'AX'>>> next(a)'AY'>>> next(a)'AZ'
- 在函数中加入yield
def fib(max):n, a, b = 0, 0, 1while n < max:yield ba, b = b, a + bn = n + 1return 'done'>>> f = fib(6)>>> f<generator object fib at 0x104feaaa0>
在每次调用next()的时候执行,遇到yield语句返回
迭代器
可以直接作用于for循环的数据统称为可迭代对象Iterable
使用isinstance()判断数据类型。
isinstance([],Iterable)
- 可迭代对象包含迭代器。
- 如果一个对象拥有iter方法,其是可迭代对象;如果一个对象拥有next方法,其是迭代器。
- 定义可迭代对象,必须实现iter方法;定义迭代器,必须实现iter和next方法。
迭代器和生成器的区别
迭代器是一个更抽象的概念,任何对象,如果它的类有 next 方法和 iter 方法返回自己本身,对于 string、list、dict、tuple 等这类容器对象,使用 for 循环遍历是很方便的。在后台 for 语句对容器对象调用 iter()函数,iter()是 python 的内置函数
生成器是创建迭代器的简单而强大的工具。它们写起来就像是正规的函数,只是在需要返回数据的时候使用 yield 语句。每次 next()被调用时,生成器会返回它脱离的位置
生成器能做到迭代器能做的所有事,而且因为自动创建了 iter()和 next()方法,生成器显得特别简洁,而且
生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当
生成器器终结时,还会自动抛出 StopIteration 异常。
生成器不需要事先准备好整个迭代过程的所有元素,仅在迭代到某个对象才将元素放入内存。挂起并返回属性中间值之后,仍能多次继续执行
而迭代器没有以上的特性
函数式编程
把函数作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式。
python内建了map()和reduce()函数
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>> def f(x):... return x * x...>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])>>> list(r)[1, 4, 9, 16, 25, 36, 49, 64, 81]>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))['1', '2', '3', '4', '5', '6', '7', '8', '9']
reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
>>> from functools import reduce>>> def add(x, y):... return x + y...>>> reduce(add, [1, 3, 5, 7, 9])25
filter用于过滤序列,传入序列,根据返回值true或false来决定保留或丢弃该元素
def is_odd(n):return n % 2 == 1list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
sorted()函数也是一个高阶函数,可以接收一个key函数来实现自定义的排序
>>> sorted([36, 5, -12, 9, -21], key=abs)[5, 9, -12, -21, 36]
返回函数
高阶函数可以把函数作为结果值返回
def lazy_sum(*args):def sum():ax = 0for n in args:ax = ax + nreturn axreturn sum>>> f = lazy_sum(1, 3, 5, 7, 9)>>> f<function lazy_sum.<locals>.sum at 0x101c6ed90>>>> f()25
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
>>> f1 = lazy_sum(1, 3, 5, 7, 9)>>> f2 = lazy_sum(1, 3, 5, 7, 9)>>> f1==f2False
匿名函数
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
g = lambda x:x+1# 等价于def g(x):2 return x+1
装饰器
假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
装饰器的参数为函数
偏函数
int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做N进制的转换:
>>> int('12345', base=8)5349>>> int('12345', 16)74565
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2):return int(x, base)
这样,我们转换二进制就非常方便了:
>>> int2('1000000')64>>> int2('1010101')85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools>>> int2 = functools.partial(int, base=2)>>> int2('1000000')64>>> int2('1010101')85
所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
>>> int2('1000000', base=10)1000000
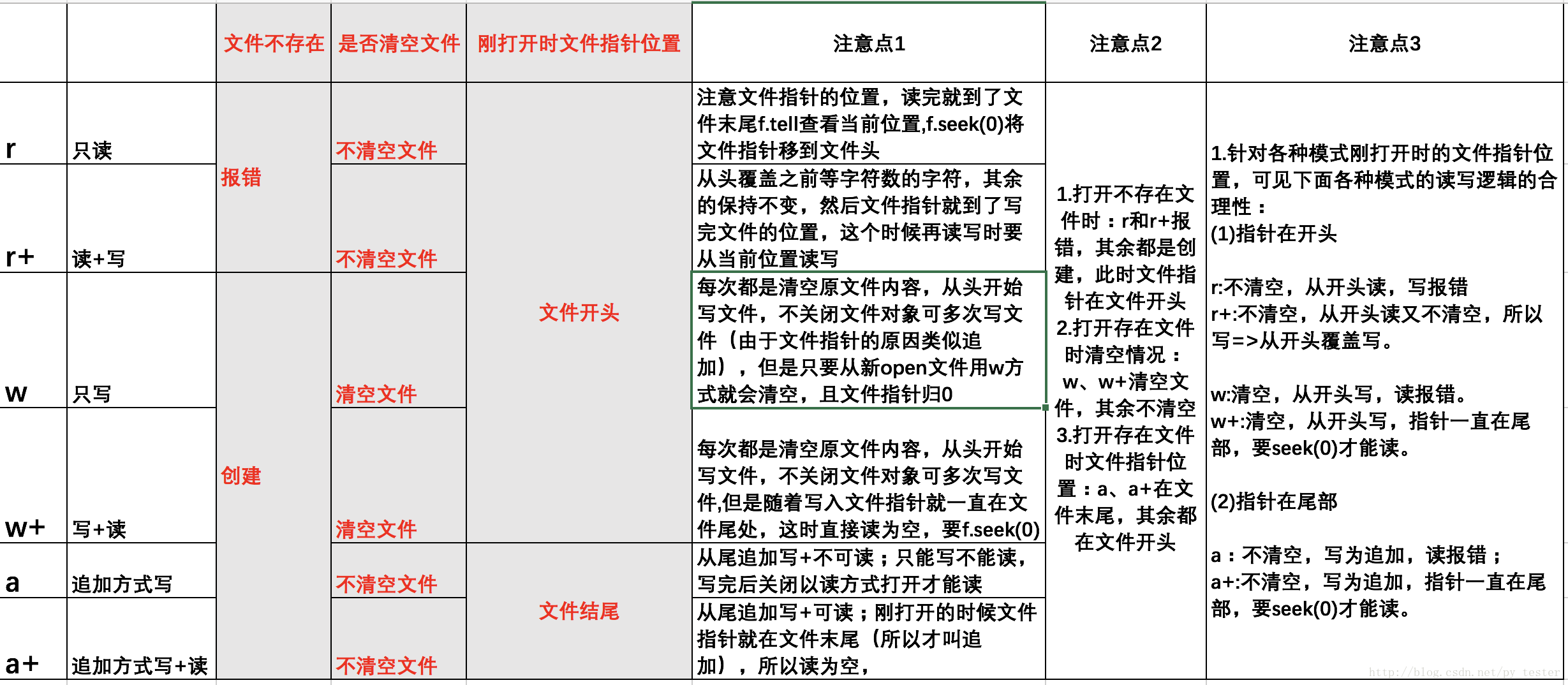
I/O
Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:print(f.read())
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就爆了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size个字节的内容。
另外,调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
for line in f.readlines():print(line.strip()) # 把末尾的'\n'删掉
read 一次都全部内容 readline() 迭代读 readlines() 一次都所有内容按行返回list
二进制文件
前面讲的默认都是读取文本文件,并且是UTF-8编码的文本文件。要读取二进制文件,比如图片、视频等等,用’rb’模式打开文件即可:
>>> f = open('/Users/michael/test.jpg', 'rb')>>> f.read()b'\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节
字符编码
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')>>> f.read()'测试'
遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')
StringIO
StringIO顾名思义就是在内存中读写str。
>>> from io import StringIO>>> f = StringIO()>>> f.write('hello')5>>> f.write(' ')1>>> f.write('world!')6>>> print(f.getvalue())hello world!
BytesIO
如果要操作二进制数据,就需要使用BytesIO。
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
>>> from io import BytesIO>>> f = BytesIO()>>> f.write('中文'.encode('utf-8'))6>>> print(f.getvalue())b'\xe4\xb8\xad\xe6\x96\x87'
JSON
>>> import json>>> d = dict(name='Bob', age=20, score=88)>>> json.dumps(d)'{"age": 20, "score": 88, "name": "Bob"}'
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'>>> json.loads(json_str){'age': 20, 'score': 88, 'name': 'Bob'}
OOP
- slots 限制实例能添加的属性。
- 使用@property限制参数
- super() 父类,超类
我们可以在子类中找不到对应属性的时候,使用super()去父类中寻找。
- super的使用方法:
class Manager(Manage, Regular)::def __init__(self):super(Manager, self).__init__()print("Manager init")
这里调用的是Manager的父类的mro,也就是Manage的init。
如果要调用Manage的父类的mro,也就是Regular的mro,需要用super(Manage, self).init()
- super(type, type2)
当定义一个子类时:
class Regular(Staff):def __new__(Manager):obj = super(Manage, Manager).__new__(Manager)print("Manager new")return obj
即搜索Manager的mro,搜索找到的new函数。如果我们想从mro的某个位置开始,修改super()里的第一个参数即可
- 钻石问题
多重继承的时候,我们需要通过不同的参数来初始化。
由于调用的问题很可能出现初始化错误,因此最好使用super来进行参数传递
- 多态
接口的多种实现
- 经典类与新式类
如果我们继承了object,就是新式类,新式类mro的搜索方式是广度搜索。即
A(object)B(A)C(A)D(B,C),D-B-C-A-object
如果没有继承object,则是经典类,搜索方式为深度搜索,即
A,B,C,D(B,C),D-B-A
- 定制类
- str 和 repr str是以字符的形式打印出来,repr是调试看到的(>>>)
- iter 返回一个迭代对象,会一直去调用next()的方法,然后返回iter,此时类可以被迭代,但不能像List一样被使用
for n in Fib():print(n)
- getitem 可以使类变为可迭代对象,并通过下标取出迭代结果
>>> f = Fib()>>> f[0]1
通过isinstance()函数判断传入下标是int还是slice(切片),可以对类进行切片操作。同样,它的下标也可以是key,作为字典使用
setitem()赋值,delitem()删除某个元素
- getattr()动态返回属性
自省
- type() 获取类型
- isinstance() 类型对比
- dir() 获取一个对象所有的属性和方法
- 类的内置函数getattr(得到该属性的value),setattr(设置该属性的value),hasattr(判断是否存在该属性),delattr(删除这个属性)
- 单例模式:确保一个类只有一个实例。
- 使用模块
# test.pyclass A(object):def test(self):print('A.test')a=A()# test1.pyfrom .test import aa.test()
- 使用 new
class A(object):_instance = Nonedef __new__(cls, *args, **kwargs):if not cls._instance: # 将类的实例和一个类变量 _instance 关联起来,如果 cls._instance 为 None 则创建实例,否则直接返回 cls._instance。cls._instance = super(A, cls).__new__(cls, *args, **kwargs)return cls._instanceclass AA(A):a = 1
- 使用装饰器
def A(cls, *args, **kw):instances = {}def getinstance(): # 判断某个类是否在字典 instances 中,如果不存在,则会将 cls 作为 key,cls(*args, **kw) 作为 value 存到 instances 中,否则,直接返回if cls not in instances:instances[cls] = cls(*args, **kw)return instances[cls]return getinstance@Aclass AA:
问题收集
- PEP8
- xrange和range range生成一个列表,而xrange是一个生成器
>>>xrange(8)xrange(8)>>> list(xrange(8))[0, 1, 2, 3, 4, 5, 6, 7]>>> range(8) # range 使用[0, 1, 2, 3, 4, 5, 6, 7]>>> xrange(3, 5)xrange(3, 5)>>> list(xrange(3,5))[3, 4]>>> range(3,5) # 使用 range[3, 4]>>> xrange(0,6,2)xrange(0, 6, 2) # 步长为 2>>> list(xrange(0,6,2))[0, 2, 4]
- 介绍一下修饰器
装饰器接受一个函数作为参数,返回的值是一个函数,通过修饰器可以增强函数的功能,但又不修改函数的定义。通过定义修饰器可以缩减代码量。
处理场景:我把它用在了验证登录和生成日志文件中
- with的使用:
- 对try except finally的优化,让代码更加美观
with open('file_name','r') as f:r=f.read()
当with里面的语句产生异常的时候,也可以正常关闭文件
- with定义上下文管理器
class A():def __enter__(self):self.a=1return selfdef f(self):print 'f'def __exit__(self,a,b,c):print 'exit'def func():return A()with A() as a:1/0a.f()print a.a
在执行中无论成功与否,都会调用exit
- 调试python代码的方式有哪些:
- print()
- assert()
- 断点
- 多线程,多进程与进程池,线程池,高并发
进程:有独立的地址空间,一个进程崩溃后,在保护模式下不会对其他进程产生影响。
线程:一个进程中的不同执行路径。
线程拥有自己的堆栈和局部变量,但线程之间没有单独的地址空间。一个线程死掉就等于整个进程死掉,所以多进程的程序比多线程的程序强壮,但在进程切换时,耗费资源较大,效率要差一点。
对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
- fork
fork() 调用一次,返回两次,子进程返回0,父进程返回子进程id。python的os模块封装了fork
import osprint(' 进程 %s 开启' % os.getpid())pid = os.fork() # 父进程返回子进程idif pid == 0:print(' 子进程 %s 的父进程是 %s' % (os.getpid(), os.getppid()))else:print(' 父进程 %s 创建了子进程 %s' % (os.getpid(), pid))
有了fork()调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务。
- Process
python提供了mutilprocessing模块来进行进程操作。
from multiprocessing import Processimport osdef run(name):print("开启%s %s" % (name,os.getpid()))print('父进程为 %s.' % os.getpid())p = Process(target=run, args=('子进程',)) # 开启进程print('子进程将开启')p.start() # 启动p.join() # 等待子进程结束后再继续往下运行,常用于进程间的同步print('子进程结束.')
- Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程
from multiprocessing import Poolimport os, time, randomdef task(name):print('开启任务 %s %s...' % (name, os.getpid()))start = time.time()time.sleep(random.random() * 3)end = time.time()print('任务 %s 开启 %0.2f 秒.' % (name, (end - start)))print('父进程为 %s.' % os.getpid())p = Pool(4) # 同时跑四个进程for i in range(5):p.apply_async(task, args=(i,)) # 开启进程print('等待所有子进程结束...')p.close() # 调用close()之后就不能继续添加新的Process了。p.join() # 调用join()之前必须先调用close(),等待所有子进程执行完毕print('所有子进程结束.')
- 子进程
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出
import subprocessprint('$ ls -a')r = subprocess.call(['ls', '-a'])print('Exit code:', r)
- 进程间通信
Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
from multiprocessing import Process, Queueimport os, time, randomdef write(q): # 写数据进程执行的代码:print('写数据进程: %s' % os.getpid())for value in ['A', 'B', 'C']:print('将 %s 放入队列...' % value)q.put(value)time.sleep(random.random())def read(q):print('读数据进程: %s' % os.getpid()) # 读数据进程执行的代码:while True:value = q.get(True)print('从队列中得到 %s ' % value)q = Queue() # 父进程创建Queue,并传给各个子进程:pw = Process(target=write, args=(q,))pr = Process(target=read, args=(q,))pw.start() # 启动子进程pw,写入:pr.start() # 启动子进程pr,读取:pw.join() # 等待pw结束:pr.terminate() # pr进程里是死循环,无法等待其结束,只能强行终止:
一个往管道中写,一个在管道中读,无限循环。
在linux中,mutilprocess封装了fork,我们不需要去关注fork()的细节。
使用pipe(分单向管道和双向管道,单向管道Pipe ( duplex = False ) )
from multiprocessing import Pipe,Processimport os, randomdef write(q): # 写数据进程执行的代码:value = {'a': "hello"}q[0].send(value)print('写进程收到 %s ' % q[1].recv()['a'])def read(q): # 读数据进程执行的代码:print(' %s' % q[1])value = {'a': "hi"}q[1].send(value)print('读进程得到 %s ' % q[0].recv()['a'])pipe = Pipe()pw = Process(target=write, args=(pipe,))pr = Process(target=read, args=(pipe,))pw.start() # 启动子进程pw,写入:pr.start() # 启动子进程pr,读取:pw.join() # 等待pw结束:pr.join() # 等待pw结束
- 多线程
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threadingdef loop():"""新线程执行的代码:"""print('运行线程 %s ' % threading.current_thread().name)n = 0while n < 5:n = n + 1print('线程 %s >>> %s' % (threading.current_thread().name, n))time.sleep(1)print('线程 %s 结束.' % threading.current_thread().name)print('线程 %s 正在运行...' % threading.current_thread().name)t = threading.Thread(target=loop, name='LoopThread')t.start()t.join()print('线程 %s 结束.' % threading.current_thread().name)
任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。
- GIL
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,
因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
使用锁可以防止线程中变量被乱改或冲突,创建一个锁就是通过threading.Lock()来实现:
lock = threading.Lock()def run_thread(n):for i in range(100000):lock.acquire() # 获取锁:try:run(n) # 运行函数finally:lock.release() # 释放锁
- 线程池
思路:创建一个线程类,执行线程池中的任务队列的一个任务。创建一个线程池类,为线程类提供任务队列。登录ssh,创建线程池并工作。
- 分布式进程
python中的mutilprocessing模块不仅支持多进程,其中managers子模块还支持把多进程分布到多台机器上。可以使用managers模块把Queue通过网络暴露出去,使其他机器可以访问queue。
任务是在任务服务器上生成,之后暴露到本端的一个端口,当机器过来获取队列,获取任务,分别运行
写一个类,让它尽可能多的支持操作符
这应该是要使用定制类
多线程的限制以及多进程中传递参数的方式
进程:资源分配的最小单位,创建和销毁的开销较大
线程:CPU调度的最小单位,开销小,切换速度快
操作系统将CPU时间片分配给多个线程,每个线程在指定放到时间片内完成。
在python中有一个GIL的锁,限定了在任一时间内只能由一个线程使用解释器。
多进程间传递参数,可以使用queue或者pipe来传递信息。
多进程和多线程的区别:1. 在某个进程结束后,需要被父进程调用wait,否则会变成僵尸进程。但是对于多线程,它只有一个进程,因此不需要。
2. 多进程要避免共享资源,多线程共享资源比较容易,变量传递比较方便。
python中的三种方法
类方法:
class A(object):def foo(self, x):print("executing foo(%s,%s)" % (self,x))@classmethoddef class_foo(cls,x):print("executing class_foo(%s,%s)" % (cls,x))print('cls:', cls)@staticmethoddef static_foo(x):print("executing static_foo(%s)" % x)a=A()print(a.foo(1))print(a.class_foo(1))print(a.static_foo(1))
类方法中self(cls)是类本身,调用方法时传递的值也只能是类的公有属性。也就是说类方法只能操作类本身的公有字段。
静态方法可以通过类直接调用。
闭包
def delay_fun(x, y):def caculator():return x+yreturn caculator
闭包可以实现先将一个参数传递给另一个参数,而并不立即执行
一些内置函数
python中有很多函数可以在某些对象上执行一个任务或者计算一个结果,而无须成为一个类中的方法。这些函数是对常用的计算进行抽象,进而适用于多种类型的类。
- len
其中最常见的就是len()函数,用来计算一些容器对象中项目的个数,比如字典或列表。
>>>a={"a":"123","b":"456"}>>>len(a)2>>>b=[1,2,3,4]>>>len(b)4
在执行len(obj)函数的时候,相当于调用obj. len ().但是使用的时候,由于双下划线的特殊方法是不能直接调用的,并且效率低下(比如每次对一个对象的属性或方法被访问时,都要调用 getattribute 方法,这样每次调用 len ()的时候就会有其他额外的方法函数被调用,甚至有一些函数或方法我们根本不想调用)
然而如果使用len()函数,则相当于调用底层类中的 len 函数。
- reversed
reversed()函数的输入是任意一个序列,返回一份倒序的序列副本,通常用于for循环需要倒序循环的时候。它与len()函数相同,调用的是参数类中的 reversed ()函数
>>> a=[1,2,3,4]>>> for i in reversed(a):... print(i)...4321
- Enumerate
当我们使用for循环对某个迭代对象遍历的时候,想要访问当前被处理的项目的索引,虽然for循环不提供索引值,但是穷举函数enumerate()可以实现:它创建一个元组列表,每个元组的第一个对象就是索引,第二个是原始条目内容。
>>> a=[1,2,3,4]>>> for i in enumerate(a):... print(i)...(0, 1)(1, 2)(2, 3)(3, 4)
- zip
zip将两个或以上的序列创建为一个新的元组序列,任意一个元祖都包含每个列表中的一个元素。
>>> a=[1,2,3,4]>>> b=[5,6,7,8]>>> for i in zip(a,b):... print(i)...(1, 5)(2, 6)(3, 7)(4, 8)>>> c=[9,0]>>> for i in zip(b,c):... print(i)...(5, 9)(6, 0)
这个函数可以用来处理文本文件数据。通常文本数据用制表符分隔的格式保存,文件的第一行作为头,其他每一行都是一条描述数据的唯一记录。
import sysfilename = "test.txt"namelist = []with open(filename) as file:header = file.readline().strip().split('\t') # 读取文件第一行,以制表符作为分隔符并把字符串作为列表保存到headerfor line in file:line = line.strip().split('\t') # 读取接下来的行数,以制表符作为分隔符并把字符串作为列表保存到linename = zip(header,line) # 合并两组字符串namelist.append(dict(name)) # 将元组转变为字典并存入namelist,即(name, col1)(wages, col2)(age, col3)for name in namelist:print("name:{name} --wages:{wages} --age:{age}".format(**name))
用来处理下面文档
name wages agewang 3000 20shuo 4000 30wangshuo 5000 40
运行结果
name:wang --wages:3000 --age:20name:shuo --wages:4000 --age:30name:wangshuo --wages:5000 --age:40
zip函数是它自身的反函数。它可以将多个序列合成一个单一的元组序列。因为元组也是序列,所以我们可以对一个经过zip的元组再次进行zip实现它的unzip
>>> c1 = [1,2,3]>>> c2 = ['a','b','c']>>> zipped = zip(c1,c2)>>> zipped = list(zipped)>>> zipped[(1, 'a'), (2, 'b'), (3, 'c')]>>> unzipped = zip(*zipped) # 将列表中的三个元组组合成一个元组,每个元组都包含一个元素>>> list(unzipped)[(1, 2, 3), ('a', 'b', 'c')]
首先将两个列表通过zip转化为一个新的元组列表。之后,我们使用参数将单独的序列作为参数传递给zip函数。zip将每一个元组的第一个值作为第一个序列,第二个值作为第二个序列,结果就是最开始的两个序列
- 其他函数
sorted()以一个迭代器作为输入,返回一个排过序地项目列表,和列表中的sort()方法很相似,区别在于它不仅能够用于列表,也能用于所有的迭代器。
还有另外三个函数min,max和sum,都是以一个序列作为输入,然后返回最小值,最大值和总和
python的垃圾回收机制
python的垃圾回收机制主要以引用计数为主,分代回收为辅。
- 引用计数:每个对象都维护一个引用次数,对象+1:
- 被创建
- 被引用
- 被作为参数传入函数
- 被放入容器
以下情况对象-1:
- 别名被显示销毁
del a - 别名被赋予新的值
a=26 - 对象离开作用域
- 对象从容器中被删除
缺点:
- 消耗资源
- 无法解决循环引用的问题
- 标记 - 清除
是一种基于追踪回收技术实现的垃圾回收算法。
- 标记,GC会把所有活动对象打上标记
- 回收,GC把没有标记的非活动对象回收。
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
- 分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象

若有收获,就点个赞吧
0 人点赞
