info
acwing 算法基础课笔记
课程地址:https://www.acwing.com/activity/content/11/
欢迎使用我的链接进行学生认证,认证后填写邀请码可以获得 AC 币,AC 币在购买课程时可以 1:1 抵扣。
AcWing【AC之星】教育优惠计划!https://www.acwing.com/user/security/school_verify/ac_stars/ 我的邀请码是:JGURH
tips
对于递归类型的算法一定要考虑终止条件,否则会死循环。
声明 or 定义局部变量时需要进行赋值,栈的初始值无法保证。
使用数组模拟链表时一定要注意 idx 初始化和调用 init() 函数!
scanf / printf is much faster than cin / cout (even with sync_with_stdio)
some snippets
// 优化 cin coutcin.tie(0);ios::sync_with_stdio(false);// 保证 x 模 N 得到的是正整数(x % N + N) % N// 遍历链表的时候记得更新p = p->next;
存双向图的时候数组空间记得 x2
基础算法
排序
快速排序
思想是分治
算法流程如下:
- 确定分界值 x :arr[l] / arr[(l+r)/2] / arr[r] / arr[random_index]
- 将 arr 分为两个部分,左边的值 小于等于 x ,右边的值大于等于 x (重要)
- 递归对两部分进行排序
- 不稳定,可以用 pair(val, idx) 解决,问题不大。
模板:
void quick_sort(int q[], int l, int r){if (l >= r) return;int x = q[l + r >> 1], i = l-1, j = r+1;while(i < j){do i++; while(q[i] < x);do j--; while(q[j] > x);if (i < j) swap(q[i], q[j]);}quick_sort(q, l, j);quick_sort(q, j+1, r);}
归并排序
思想也是分治
快排是选择分界值,归并是选择分界点
算法流程如下:
- 选择分界点:mid = (l+r)/2
- 递归排序左右两部分
- 归并,合二为一 (重要)
模板:
int tmp[N];void merge_sort(int q[], int l, int r){if (l >= r) return;int mid = l + r >> 1;merge_sort(q, l, mid);merge_sort(q, mid+1, r);int k = 0, i = l, j = mid + 1;while(i <= mid && j <= r){if (q[i] <= q[j]) tmp[k++] = q[i++];else tmp[k++] = q[j++];}while(i <= mid) tmp[k++] = q[i++];while(j <= r) tmp[k++] = q[j++];for(int i = l, j = 0; i <= r; i ++, j ++) q[i] = tmp[j];}
二分
整数二分
有单调性是可以二分的充分不必要条件
二分的本质是寻找满足某种性质的边界
算法可分为两种情况,寻找右边界和左边界。计算 mid 方法不同,详见下图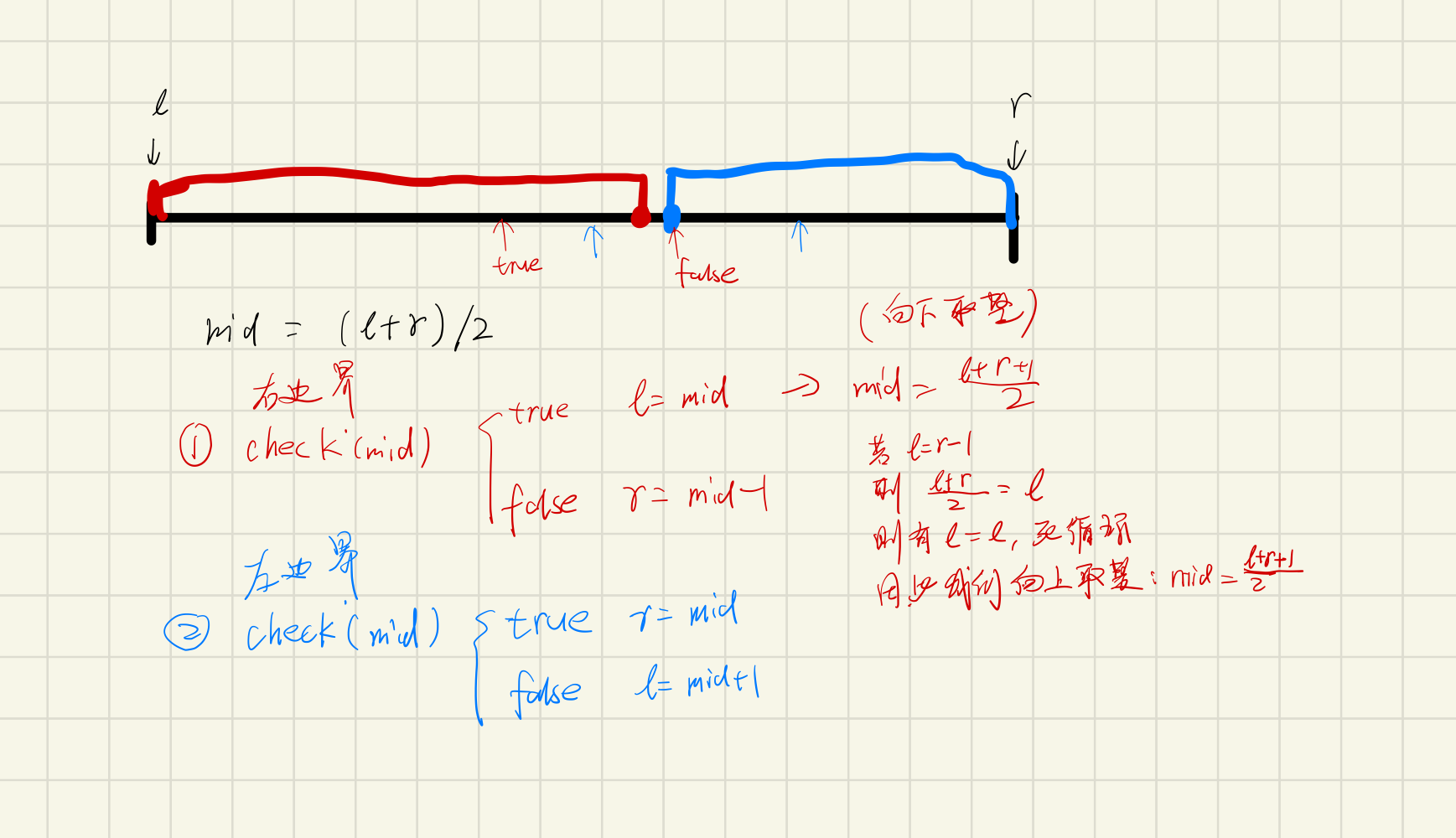
两个模板:
// 找到小于等于 x 的最大(右)下标int bsearch_r(int q[], int l, int r, int x){if (x < q[l] || q[r] < x) return -1;while(l < r){int mid = l + r + 1>> 1;if (q[mid] <= x) l = mid;else r = mid-1;}return q[l] == x ? l : -1;}// 找到大于等于 x 的最小(左)下标int bsearch_l(int q[], int l, int r, int x){if (x < q[l] || q[r] < x) return;while(l < r){int mid = l + r >> 1;if (q[mid] >= x) r = mid;else l = mid + 1;}return q[l] == x ? l : -1;}
浮点数二分
不用考虑各种边界条件。
r - l <= 1e-6 / for(int i=0; i<100; i++)
注意题目中的书数字范围,需要用于 l, r 的初始化
example:
int main(){double x;cin >> x;// printf('')double l = -10000, r = -l;while( r - l >= 1e-8){// for(int i=0; i<100; i++){double mid = (r + l) / 2;if (mid * mid * mid < x) l = mid;else r = mid;}printf("%.6f", l);return 0;}
高精度
java 和 python 不需要考虑。
常见四种:
- 两个大整数相加
- 两个大整数相减
- 一个大整数 x 一个小整数
- 一个大整数 / 一个小整数
tips: 使用 vector 存储大整数,并且将大整数的地位存到 vector 的低位,这样之后进位方便。
// 读取大整数并放到数组中string a; vector<int> A;cin >> a;for(int i = a.size() - 1; i >= 0; i --) A.push_back(a[i] - '0');// 打印数组中的大整数for(int i = C.size() - 1; i >= 0; i --) printf("%d", C[i]);// 大整数比较// A >= Bbool cmp_ge(vector<int> A, vector<int> B){if (A.size() != B.size()) return A.size() > B.size();for(int i = A.size() - 1; i >= 0; i --)if (A[i] != B[i]) return A[i] >= B[i];return true;}// 去除前导 0while(C.size() > 1 && C.back() == 0) C.pop_back();
大整数加法
读进大整数字符串之后存到数组中,大整数的低位存到数组的低位,类似小端序,计算和的过程就和人工计算一样。
模板如下:
// C = A + Bvector<int> add(vector<int> A, vector<int> B){vector<int> C;int t = 0;for (int i = 0; i < A.size() || i < B.size() || t; i ++){if (i < A.size()) t += A[i];if (i < B.size()) t += B[i];C.push_back(t % 10);t /= 10;}return C;}
大整数减法
需要先判断一下 A 和 B 的大小,用大的数减去小的数,避免考虑边界情况。
具体计算过程也是模拟人工计算减法的过程:
模板如下 :
// A >= Bbool cmp_ge(vector<int> A, vector<int> B){if (A.size() != B.size()) return A.size() > B.size();for(int i = A.size() - 1; i >= 0; i --)if (A[i] != B[i]) return A[i] >= B[i];return true;}// C = A - B (A >= B)vector<int> sub(vector<int> A, vector<int> B){vector<int> C;int t = 0;for (int i = 0; i < A.size(); i ++){t = A[i] - t;if (i < B.size()) t -= B[i];C.push_back((t + 10) % 10);if (t < 0) t = 1;else t = 0;}// 去除前导 0while(C.size() > 1 && C.back() == 0) C.pop_back();return C;}
大整数 x 小整数:A x b
思想就是分别计算 A 的每一位和 b 的乘法,然后进位相加。
模板如下:
// C = A x bvector<int> mul(vector<int> A, int b){vector<int> C;int t = 0;for(int i = 0; i < A.size() || t; i ++){if (i < A.size()) t += A[i] * b;C.push_back(t % 10);t /= 10;}while(C.size() > 1 && C.back() == 0) C.pop_back();return C;}
大整数 / 小整数:A / b
模拟人工计算方法。但是除法是从大整数的高位开始算,不过为了一致性我们还是使用相同的方法表示大整数,所以计算除法的时候会多一个 reverse 操作。
r 为余数
r = r * 10 + A[i]
c = r / b
r /= 10
模板如下:
// C = A / b// r = A % bvector<int> div(vector<int> A, int b, int &r){vector<int> C;r = 0;for(int i = A.size() - 1; i >= 0; i --){r = r * 10 + A[i];C.push_back(r / b);r %= b;}// 将大整数的低位放到数组的低位。reverse(C.begin(), C.end());while(C.size() > 1 && C.back() == 0) C.pop_back();return C;}
前缀和 and 差分
一维数组前缀和

二维矩阵前缀和

差分
对于一个区间进行多次操作的 时候可以使用差分数组的方法,降低时间复杂度。
一维数组差分
有一个数组 A,设 A 的差分为 B
则 A 为 B 的前缀和数组。
通过对 B 进行操作,可以等价于对 A 进行操作,同时复杂度可以从 O(n) 降到 O(1)。
如果想对 A 中 [l, r] 区间的值整体加上一个 c,那么就可以对比进行如下操作替代:
- B[l] += c
- B[r+1] -= c
初始化 B 数组我们也可以利用上面的思想
- 认为 A 中全为 0, 则 B 也全为 0
- A 在 [1, 1] 区间加上 A[1] -> B[1] += A[1], B[1+1] -= A[1]; 循环
插入操作
void insert(int l, int r, int c){a[l] += c;a[r+1] -= c;}
二维差分
思想和一维类似,插入操作代码如下
// b 为 a 的差分矩阵void insert(int x1, int x2, int y1, int y2){b[x1][x2] += c;b[x2+1][yy] -= c;b[x1][y2+1] -= c;b[x2+1][y2+1] += c;}
双指针算法
分类:
- 两个指针分别指向两个序列
- 两个指针指向同一个序列
常见写法
for (int i = 0, j = 0; i < n; i ++){while( j < i && check(i, j) j ++;////}// 核心思想for (int i = 0; i < n; i ++)for(int j = 0; j < n; j ++)// do sth
可以由朴素算法优化而来,通过寻找单调性来应用双指针算法,如题目最长单调子序列:
// 朴素算法for (int i = 0; i < n; i ++)for (int j = 0; j <= i; j ++)if check(j, i) {res = max(res, i - j + 1;}}// 双指针for (int i = 0, j = 0; i < n; i ++)while (j <= i && !check(j, i) j ++;res = max(res, i - j + 1);}
位运算
// n 的二进制表示中第 k 位是几(n >> k) & 1// x 的最后一位 1int lowbit(x){return x & -x;}
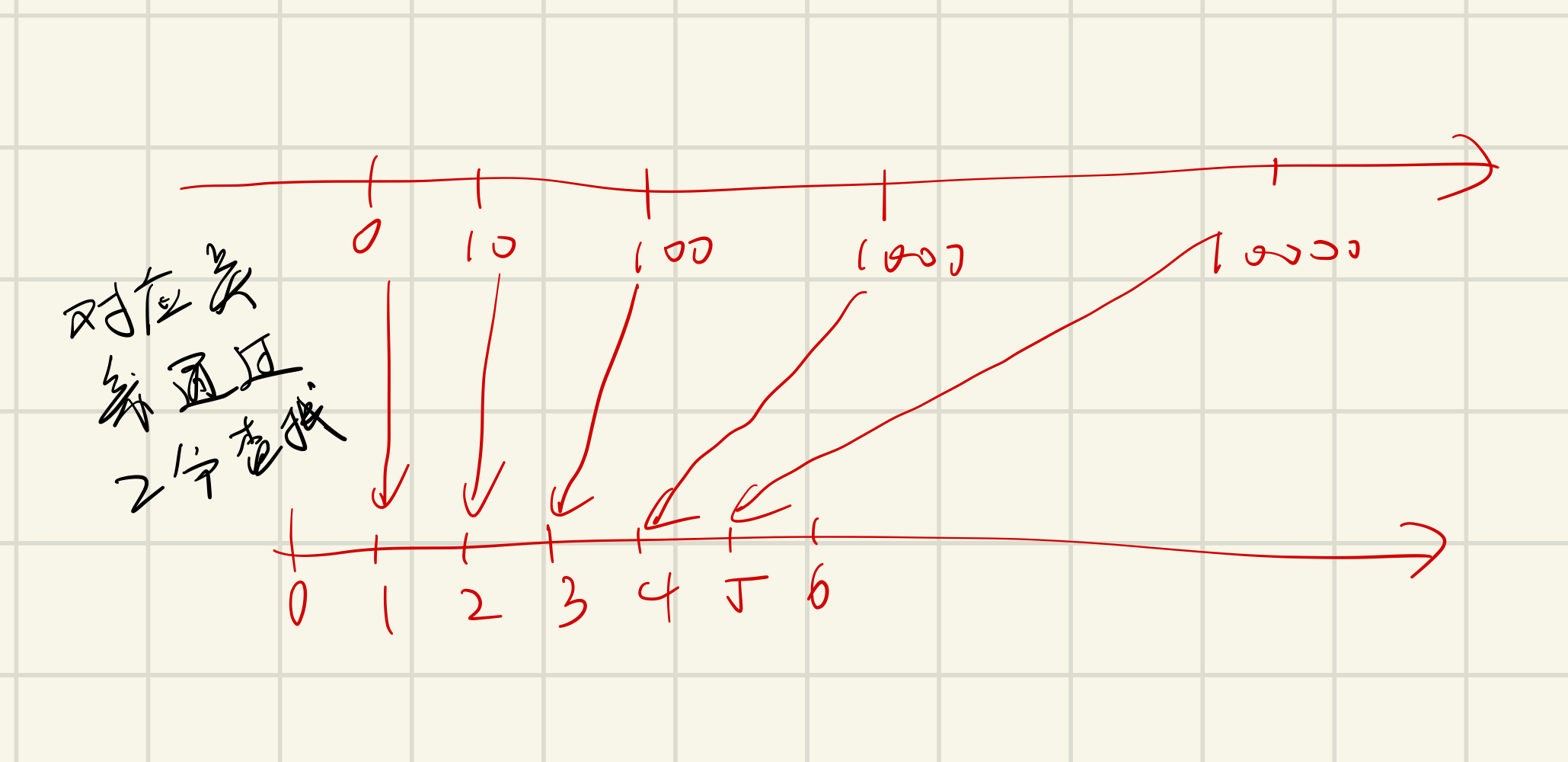
离散化
https://www.acwing.com/video/14/ 1:35:00
应用场景:值域很大,但是非常稀疏
将有序的离散的大整数序列 A 映射到连续的从1开始的自然数序列 B
- 从 1 开始是为了和前缀和操作结合
重点:
- A 中可能有重复元素,需要 去重
- 如何算出 A[i] 离散化后的值
- 下标,二分
vector<int> alls;sort(alls.begin(), alls.end());alls.erase(unique(alls.begin(), alls.end()), alls.end());int find(int x){int l = 0, r = alls.size() - 1;while (l < r){int mid = l + r >> 1;if (alls[mid] >= x) r = mid;else l = mid + 1;}return l + 1; // 下标从 1 开始,方便计算前缀和}
区间合并
https://www.acwing.com/video/14/
01:57:45
数据结构
- 链表与邻接表
- 栈与队列
- kmp
用数组来模拟(笔试用,速度快)
如果用指针+结构体每次 new 都很耗时,可以面试时用
链表
- 单链表
- 邻接表, 存储树和图
- 双链表
- 优化某些问题
单链表
#define N 10010// head 存储头结点, 用 ne[0] 表示,所以 idx 从 1 开始// e 存储第 k 个节点的值// ne 存储第 k 个节点的下个节点的下标// idx 为未使用的最小下标int e[N], ne[N], idx;void idx(){idx = 1;}// 插入到头结点void H(int x){e[idx] = x;ne[idx] = ne[0];ne[0] = idx ++;}// 删除第 k (k 从 1 开始)个插入的节点下一个节点, k = 0 时表示删除头节点void D(int k){ne[k] = ne[ne[k]];}// 第 k (k 从 1 开始)个插入的节点后插入一个节点,k >= 1void I(int k, int x){if (k == 0){H(x);} else {e[idx] = x;ne[idx] = ne[k];ne[k] = idx ++;}}// 遍历int cur = ne[0];while (cur) {// do sthcur = ne[cur];}
双链表
const int N = 100010;// head = 0// tail = 1int e[N], l[N], r[N], idx;void init(){r[0] = 1, l[1] = 0, idx = 2;}// (1) “L x”,表示在链表的最左端插入数xvoid L(int x){e[idx] = x;r[idx] = r[0];l[idx] = 0;l[r[0]] = idx;r[0] = idx ++;}// (2) “R x”,表示在链表的最右端插入数xvoid R(int x){e[idx] = x;r[idx] = 1;l[idx] = l[1];r[l[1]] = idx;l[1] = idx ++;}// (3) “D k”,表示将第k个插入的数删除void D(int k){k ++;r[l[k]] = r[k];l[r[k]] = l[k];}// (4) “IL k x”,表示在第k个插入的数左侧插入一个数void IL(int k, int x){k ++;e[idx] = x;l[idx] = l[k];r[idx] = k;r[l[k]] = idx;l[k] = idx ++;}// (5) “IR k x”,表示在第k个插入的数右侧插入一个数。void IR(int k, int x){// if// IL(++ k, x);k ++;e[idx] = x;l[idx] = k;r[idx] = r[k];l[r[k]] = idx;r[k] = idx ++;}
邻接表
其实就是一堆单链表
栈和队列
栈
#define N 100010int stk[tt], tt;void push(int x){ stk[++ tt] = x;}void pop(){tt --;}bool empty(){return tt <= 0;}int top(){return stk[tt];}int size(){return hh;}
队列
#define N 100010int a[N], q[N], hh, tt = -1, n, k;void push(int x){q[++ tt] = x;}void pop_front(){hh ++; }void pop_back(){ tt --; }bool empty(){return hh > tt;}int front(){return q[hh];}int back(){return q[tt];}int size(){return tt - hh + 1;}int clear(){hh = 0, tt = -1;}
单调栈
应用场景:找寻一个序列中每一个数的左边离它最近的且比它小的数的位置
example
3 4 2 7 5
-1 0 -1 2 2
// naive methodfor (int i = 0; i < n; i ++){for (int j = i; j >= 0; j --)if (a[j] < a[i]) break;cout << j << endl;}
也可用于寻找每个数右边第一个比它大的数的位置。此时栈中的元素从栈底到栈顶单调不升。
单调队列
应用场景:
- 求滑动窗口中的最大值 or 最小值
#include <iostream>using namespace std;const int N = 1000010;int a[N], n, k, q[N], hh, tt = -1;int main(){scanf("%d%d", &n, &k);for (int i = 0; i < n; i ++) scanf("%d", &a[i]);// 递增单调队列,求最小值。for (int i = 0; i < n; i ++) {if (hh <= tt && q[hh] < i - k + 1) hh ++;while (hh <= tt && a[q[tt]] > a[i]) tt --;q[++ tt] = i;if (i >= k - 1) printf("%d ", a[q[hh]]);}puts("");// 递减单调队列,求最大值。hh = 0, tt = -1;for (int i = 0; i < n; i ++) {if (hh <= tt && q[hh] < i - k + 1) hh ++;while (hh <= tt && a[q[tt]] < a[i]) tt --;q[++ tt] = i;if (i >= k - 1) printf("%d ", a[q[hh]]);}return 0;}
kmp 算法
#include <iostream>#include <cstdio>using namespace std;//string P, S;const int N = 100010, M = 1000010;int n, m;char p[N], s[M];int ne[N];int main() {cin >> n >> p + 1 >> m >> s + 1;// build nextfor (int i = 2, j = 0; i <= n; i ++){while (j && p[i] != p[j + 1]) j = ne[j];if (p[i] == p[j + 1]) j ++;ne[i] = j;}// kmp matchfor (int i = 1, j = 0; i <= m; i ++){while (j && s[i] != p[j + 1]) j = ne[j];if (s[i] == p[j + 1]) j ++;if (j == n){printf("%d ", i - n);j = ne[j];}}return 0;}
Trie 树
用于快速存储和查找字符串集合的数据结构
使用数组模拟:
#define N 100010int son[N][26], cnt[N], idx, n;void insert(char s[]){int cur = 0;for (int i = 0; s[i]; i ++){int u = s[i] - 'a';if (son[cur][u]){cur = son[cur][u];} else {son[cur][u] = ++ idx;cur = son[cur][u];}}cnt[cur] ++;}int query(char s[]){int cur = 0;for (int i = 0; s[i]; i ++){int u = s[i] - 'a';if (son[cur][u]) cur = son[cur][u];else return 0;}return cnt[cur];}
并查集
面试常见。代码段,思想比较巧妙。
用途:
- 合并两个集合
- 查询两个元素是否在同一个集合中
在近乎 O(1) 时间复杂度完成上述两个操作
原理:
- 每个集合用一颗树表示
- 树根的编号就是集合的编号
- 每个节点存储它的父节点 p[x]
问题1:如何判断树根:p[x] = x
问题2:如何求 x 的集合编号:while (p[x] != x) x = p[x];
问题3:如歌合并两个集合: p[x] = y
优化:
- 路经压缩:找到根节点之后,将路径上所有节点都直接指向根节点。 ```cpp // 返回 x 的祖宗节点 + 路径压缩 int find(int x){ if (p[x] != x) p[x] = find(p[x]); return p[x]; }
// merge p[find(a)] = find(b);
// whether in the same set find(a) == find(b);
<a name="znW64"></a>## 堆如何手写一个堆<br />支持的操作:- 插入一个数- 求集合中的最小值- 删除集合中的最小值- 删除任意一个元素- 修改任意一个元素基本结构- 一颗完全二叉树- 任意一个节点的值小于等于两个字节点的值使用二维数组存储:- left child : 2x- right child : 2x + 1两个基本操作:- down(x)- up(x)```cpp// heap starts at index 1// initialize heapfor (int i = n / 2; i >= 1; i --) down(i);// upvoid up(int u){while ( u / 2 && h[u / 2] > h[u]){swap(h[u / 2], h[u]);u /= 2;}}// downvoid down(int u){int t = u;if (u * 2 <= hsize && h[u * 2] < h[t]) t = u * 2;if (u * 2 + 1 <= hsize && h[u * 2 + 1] < h[t]) t = u * 2 + 1;if (u != t){swap(h[u], h[t]);down(t);}}// inserth[size] = x; size ++; up(x);// remove smallest xh[1] = h[size --]; down(1);// query smallest xh[1];// reomve kh[k] = h[size --]; down(k); up(k);// modify kh[k] = x; down(k); up(k);
哈希表
- 存储方式:
- 开放寻址法
- 拉链法
- 字符串哈希方法
算模的时候需要保证得到的结果是正整数 
拉链法
const int N = 100019;int h[N], e[N], ne[N], idx;void insert(int x){int y = (x % N + N) % N;e[++ idx] = x;ne[idx] = h[y];h[y] = idx;;}bool query(int x){int y = (x % N + N) % N;int cur = h[y];while(cur && e[cur] != x) cur = ne[cur];return e[cur] == x;}
开放寻址法
// 开放寻址法const int N = 100019;int h[N * 3];int find(int x){int y = (x % N + N) % N;while (h[y] && h[y] != x) y ++;return y;}void insert(int x){int y = find(x);h[y] = x;}bool query(int x){if(h[find(x)] == x) return true;else return false;}
字符串哈希
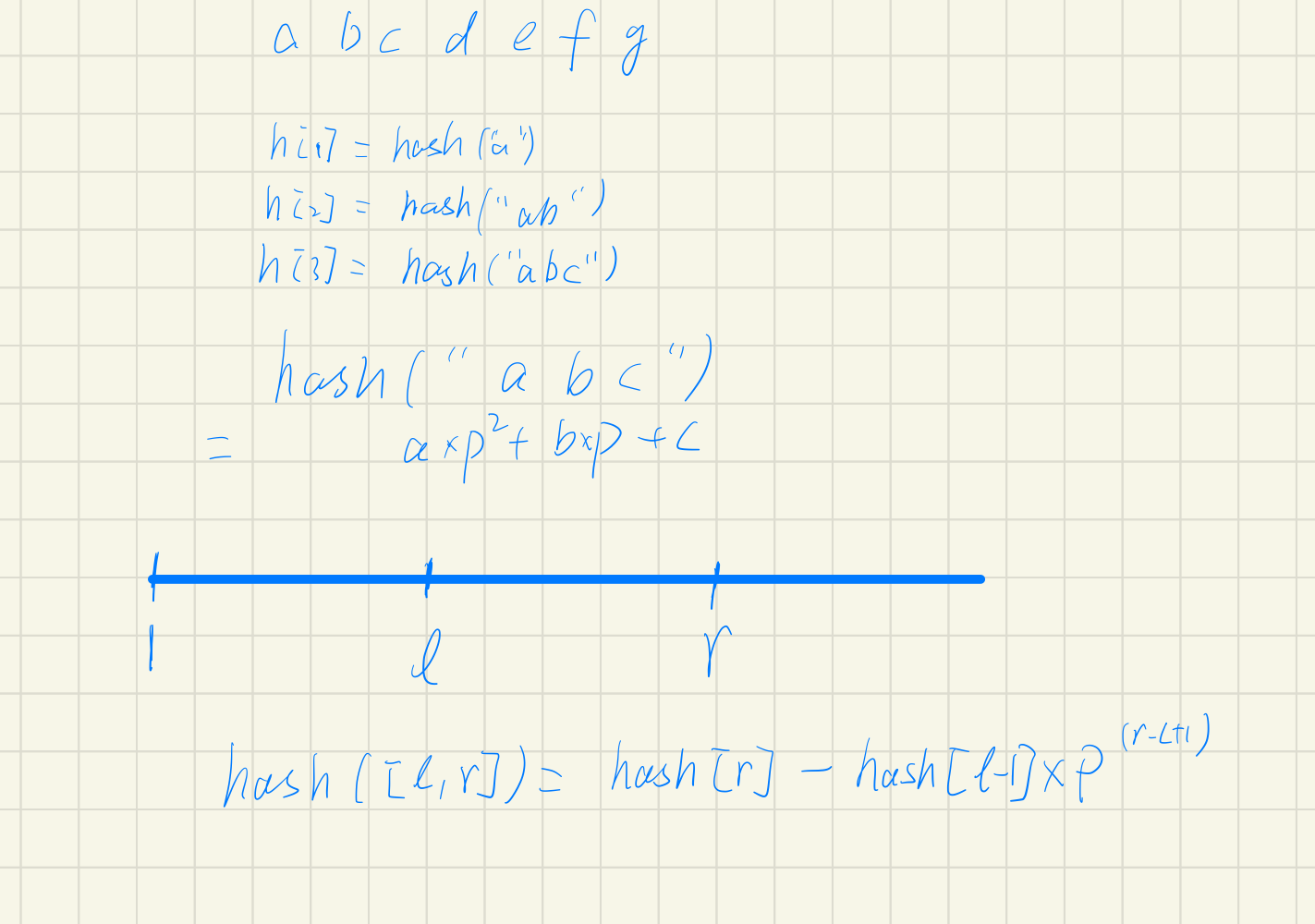
通常 P 取 131 / 13331,hash 值对 2 ** 64 取模。
#include <iostream>#include <cstring>using namespace std;const int N = 100019;typedef unsigned long long ULL;ULL h[N], ps[N], P = 131;char s[N];ULL get(int l, int r){return h[r] - h[l - 1] * ps[r - l + 1];}int main(){int n, m;scanf("%d%d", &n, &m);scanf("%s", s + 1);ps[0] = 1;for (int i = 1; i <= n; i ++){ps[i] = ps[i - 1] * P;h[i] = h[i - 1] * P + s[i];}while (m --){int l1, r1, l2, r2;scanf("%d%d%d%d", &l1, &r1, &l2, &r2);if (get(l1, r1) == get(l2, r2)) printf("Yes\n");else printf("No\n");}return 0;}
stl
vector, 变长数组,倍增的思想size() 返回元素个数empty() 返回是否为空clear() 清空front()/back()push_back()/pop_back()begin()/end()[]支持比较运算,按字典序pair<int, int>first, 第一个元素second, 第二个元素支持比较运算,以first为第一关键字,以second为第二关键字(字典序)string,字符串size()/length() 返回字符串长度empty()clear()substr(起始下标,(子串长度)) 返回子串c_str() 返回字符串所在字符数组的起始地址queue, 队列size()empty()push() 向队尾插入一个元素front() 返回队头元素back() 返回队尾元素pop() 弹出队头元素priority_queue, 优先队列,默认是大根堆size()empty()push() 插入一个元素top() 返回堆顶元素pop() 弹出堆顶元素定义成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;stack, 栈size()empty()push() 向栈顶插入一个元素top() 返回栈顶元素pop() 弹出栈顶元素deque, 双端队列size()empty()clear()front()/back()push_back()/pop_back()push_front()/pop_front()begin()/end()[]set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列size()empty()clear()begin()/end()++, -- 返回前驱和后继,时间复杂度 O(logn)set/multisetinsert() 插入一个数find() 查找一个数count() 返回某一个数的个数erase()(1) 输入是一个数x,删除所有x O(k + logn)(2) 输入一个迭代器,删除这个迭代器lower_bound()/upper_bound()lower_bound(x) 返回大于等于x的最小的数的迭代器upper_bound(x) 返回大于x的最小的数的迭代器map/multimapinsert() 插入的数是一个pairerase() 输入的参数是pair或者迭代器find()[] 注意multimap不支持此操作。 时间复杂度是 O(logn)lower_bound()/upper_bound()unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表和上面类似,增删改查的时间复杂度是 O(1)不支持 lower_bound()/upper_bound(), 迭代器的++,--bitset, 圧位bitset<10000> s;~, &, |, ^>>, <<==, !=[]count() 返回有多少个1any() 判断是否至少有一个1none() 判断是否全为0set() 把所有位置成1set(k, v) 将第k位变成vreset() 把所有位变成0flip() 等价于~flip(k) 把第k位取反作者:yxc链接:https://www.acwing.com/blog/content/404/来源:AcWing著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
数学知识
质数
试除法判定质数
O(sqrt(n)
bool is_prime(int x) {if (x < 2) return false;for (int i = 2; i <= x / i; i ++)if (x % i == 0) return false;return true;}
分解质因数
O(sqrt(n))
注意处理最后剩的一个大于 sqrt(x) 的因数
void divide(int x){if (x < 2) return ;for (int i = 2; i <= x / i; i ++) {if (x % i == 0) {int cnt = 0;while (x % i == 0) {x /= i;cnt ++;}printf("%d %d\n", i, cnt);}}if (x > 1) printf("%d %d\n", x, 1);printf("\n");}
筛质数
埃氏筛法
用每个质数去筛后面所有 <= n 的倍数。
O(n loglogn)
void get_primes(int n) {for (int i = 2; i <= n; i ++)if (!st[i]) {// printf("%d ", i);primes[cnt ++] = i;for (int j = i + i; j <= n; j += i) st[j] = true;}}
线性筛法
对于每个数用最小的质因数筛掉。
因为每个数最多只会被标记一次,所以算法的时间复杂度是:O(n)
//线性筛法-O(n), n = 1e7 的时候基本就比埃式筛法快一倍了//算法核心:x仅会被其最小质因子筛去void get_prime(int x) {for(int i = 2; i <= x; i++) {if(!st[i]) prime[cnt++] = i;for(int j = 0; prime[j] <= x / i; j++) {//对于任意一个合数 x ,假设 pj 为 x 最小质因子,当 i x / pj 时,一定会被筛掉st[prime[j]*i] = true;if(i % prime[j] == 0) break;/*1.i % pj == 0, pj 定为 i 最小质因子,pj 也定为 pj * i 最小质因子2.i % pj != 0, pj 定小于 i 的所有质因子,所以 pj 也为 pj * i 最小质因子*/}}}
约数
试除法求约数
O(sqrt(n)
如果 n 是平分数需要避免输出两次 sqrt(n),所以需要增加一次判断。
void get_divisors(int x) {vector<int> res;for (int i = 1; i < x / i; i ++)if (x % i == 0) {res.push_back(i);if (i != x / i) res.push_back(x / i);}sort(res.begin(), res.end());for (auto val : res) printf("%d ", val);pust("");}
约数个数/约数和

// hashmap tips:unordered_map<int, int> hash;hash[k ++]; // 若 k 不在 hash 的 key 中的话则等价于 hash[k] = 1;// 遍历 hash 表for (auto [k, v] : hash) {// ...}// 计算 p^0 + p^1 + ... + p^ktypedef long long LL;const int mod = 1e9 + 7;LL t = 1;while (k --) t = (t * p + 1) % mod;// 分解质因数,并记录每个质因数的次数unordered_map<int, int> primes;void get_primes(int x) {for (int i = 2; i <= x / i; i ++)if (x % i == 0)while (x % i == 0) {x /= i;primes[i] ++;}if (x > 1) primes[x] ++;}
最大公约数
欧几里得算法
int gcd(int a, int b) {return b ? gcd(b, a % b) : a;}
欧拉函数
欧拉函数  的定义为:从 1 到 n 中所有和 n 互质的数的个数。特别地,对于质数 p,
的定义为:从 1 到 n 中所有和 n 互质的数的个数。特别地,对于质数 p, 。
。
一个 n 的欧拉函数的计算方法如下:
求欧拉函数
O(sqrt(n))
和分解质因数代码类似。实现的时候为了避免出现小数误差所以需要调整一下计算顺序。
int main() {int n;cin >> n;while (n --) {int x;cin >> x;int res = x;for (int i = 2; i <= x / i; i ++) {if (x % i == 0) {res = res / i * (i - 1);while (x % i == 0) x /= i;}}if (x > 1) res = res / x * (x - 1);cout << res << endl;}return 0;}
筛法求欧拉函数
可以一次性求 2 到 n 所有数的欧拉函数。
O(n)
#include <iostream>using namespace std;const int N = 1000010;typedef long long LL;int primes[N], cnt, phi[N];bool st[N];void get_primes(int n) {phi[1] = 1;for (int i = 2; i <= n; i ++) {if (!st[i]) {primes[cnt ++] = i;// i 是质数,所以 \phi(i) = i - 1phi[i] = i - 1;}for (int j = 0; primes[j] <= n / i; j ++) {int t = i * primes[j];st[t] = true;if (i % primes[j] == 0) {// primes[j] 是 i 的(最小)质因数,因此计算 \phi(i) 的时候已经// 乘过一次 (primes[j] - 1 / primes[j])。所以在计算 t 的质因数的时候// 就不需要再乘 (primes[j] - 1 / primes[j]) 了。// \phi(x) = \phi(i) / i * t = \phi(i) * primes[j];phi[t] = (LL) phi[i] * primes[j];break;}// primes[j] 和 i 互质,因此 \phi(x) = \phi(i) / i * t * (primes[j] - 1) / primes[j]// = \phi(i) * (primes[j] - 1)phi[t] = (LL) phi[i] * (primes[j] - 1);}}}int main() {int n;cin >> n;get_primes(n);LL res = 0;for (int i = 1; i <= n; i ++) res += phi[i];cout << res << endl;return 0;}
欧拉定理


快速幂


typedef long long LL;int qmi(int a, int b, int p) {LL res = 1 % p;while (b) {if (b & 1)res = (LL) res * a % p;b >>= 1;a = (LL) a * a % p;}return res;}
应用:
- 求逆元(欧拉定理)

int exgcd(int a, int b, int &x, int &y) {if (!b) {x = 1, y = 0;return a;}int d = exgcd(b, a % b, y, x);// x = xy -= a / b * x;return d;}
应用:
- 线性同余方程
- 求逆元
中国剩余定理
// todo
高斯消元
用途:解方程。O(n^3) 时间复杂度解 n 元线性方程组。

#include <iostream>#include <cmath>using namespace std;const int N = 110;double q[N][N], eps = 1e-6;int n;/*return:0 表示无解1 表示有唯一解2 表示有无穷多解*/int gauss() {int c = 0, r = 0;for (c = 0; c < n; c ++) {int t = r;// 找到最大元素for (int i = r; i < n; i ++)if (fabs(q[i][c]) > fabs(q[t][c])) t = i;// 若均为 0,break;if(fabs(q[t][c]) < eps) continue;// 和最上面的行交换for (int i = c; i <= n; i ++) swap(q[r][i], q[t][i]);// 对最上面的行进行归一化处理, 注意要从后往前for (int i = n; i >= c; i --) q[r][i] /= q[r][c];// 消除下面的行for (int i = r + 1; i < n; i ++)if (fabs(q[i][c]) > eps)for (int j = n; j >= c; j --)q[i][j] -= q[r][j] * q[i][c];r ++;// log();}// log();// 此时我们已经得到了梯形矩阵,需要判断是否有解if (r < n) {for (int i = r; i < n; i ++)if (fabs(q[i][n]) > eps) return 0;return 2;}// 向上消除for (int i = n - 2; i >= 0; i --) {for (int j = n - 1; j > i; j --) {q[i][n] -= q[j][n] * q[i][j];q[i][j] = 0;}}return 1;}
组合数

解法:
- 预处理 C_i^j (a,b 较小 1e3 级别)
- 时间:O(n),空间 O(n^2)
- 预处理阶乘和对应的逆(快速幂)(a,b 较大 1e5 级别)
- O(nlogn)
卢卡斯定理(a,b 较大,1e18 级别)
高精度
- 分解质因数 + 高精度乘法
- 卡特兰数

容斥原理
时间复杂度:
实现:位运算
博弈论
nim 游戏
必胜状态:可以转移到必败状态
必败状态:无法走到必败状态
sg 图
mex 函数
搜索与图论
- 回溯
- 剪枝
关键是想清楚便利顺序
回溯的时候一定要注意恢复现场
经典题型
- 全排列
- N 皇后问题
N 皇后问题中判断对角线是否满足条件的技巧:
const int N = 10;bool col[N], dg[N * 2], udg[N * 2];int x, y, n;if ( ! col[y] && ! dg[x + y] && ! dg[x - y + n]){// do sth;}
BFS
queue
使用的空间和宽度成正比,指数级别。
包含最短路的性质。
只有在所有边权都为 1 时才能有 BFS 来解决最短路问题,否则需要使用专门的最短路算法。
典型例题:
- 走迷宫
树与图的存储
树是无环联通图
无向图是特殊的有向图
有向图的存储方法:
- 邻接矩阵
- 用的比较少
- 浪费空间 O(n ^ 2)
- 用于稠密图
- 邻接表
const int N = 10010;int h[N], e[N * 2], ne[N * 2], idx;//add edge : a -> bvoid ae(int a, int b){e[++ idx] = b;ne[idx] = h[a];h[a] = idx;}// iterate edges os node aint cur = h[a];while (cur){b = e[cur];// do sthcur = ne[cur];}
拓扑排序
有向无环图一定存在拓扑序列,因此也被称作拓扑图
入度和出度
基于 bfs,但是需要考虑重边的情况,所以不要用 st 数组。
- 比如有两条 a -> b 的边那么就需要两次才能让 b 的入度为 0。
- 因为仅当一个节点入度为 0 的时候才会被放到队列里面,所以也不用担心环导致的死循环。
最短路问题
约定
- n 表示点数量
- m 表示边数量
稠密图:m ~ n^2
稀疏图:m ~ n
分类
- 单源最短路
- 所有边权重都为正数
- 朴素 Dijkstra 算法:O(n^2)
- 堆优化 Dijkstra 算法:O(m logn)
- 存在负权遍
- Bellman-Ford 算法: O(m n)
- SPFA : 平均负责度为 O(m),最坏为 O(m n)
- 所有边权重都为正数
- 多源(起点)汇(终点)最短路
- Floyd 算法:O(n^3)
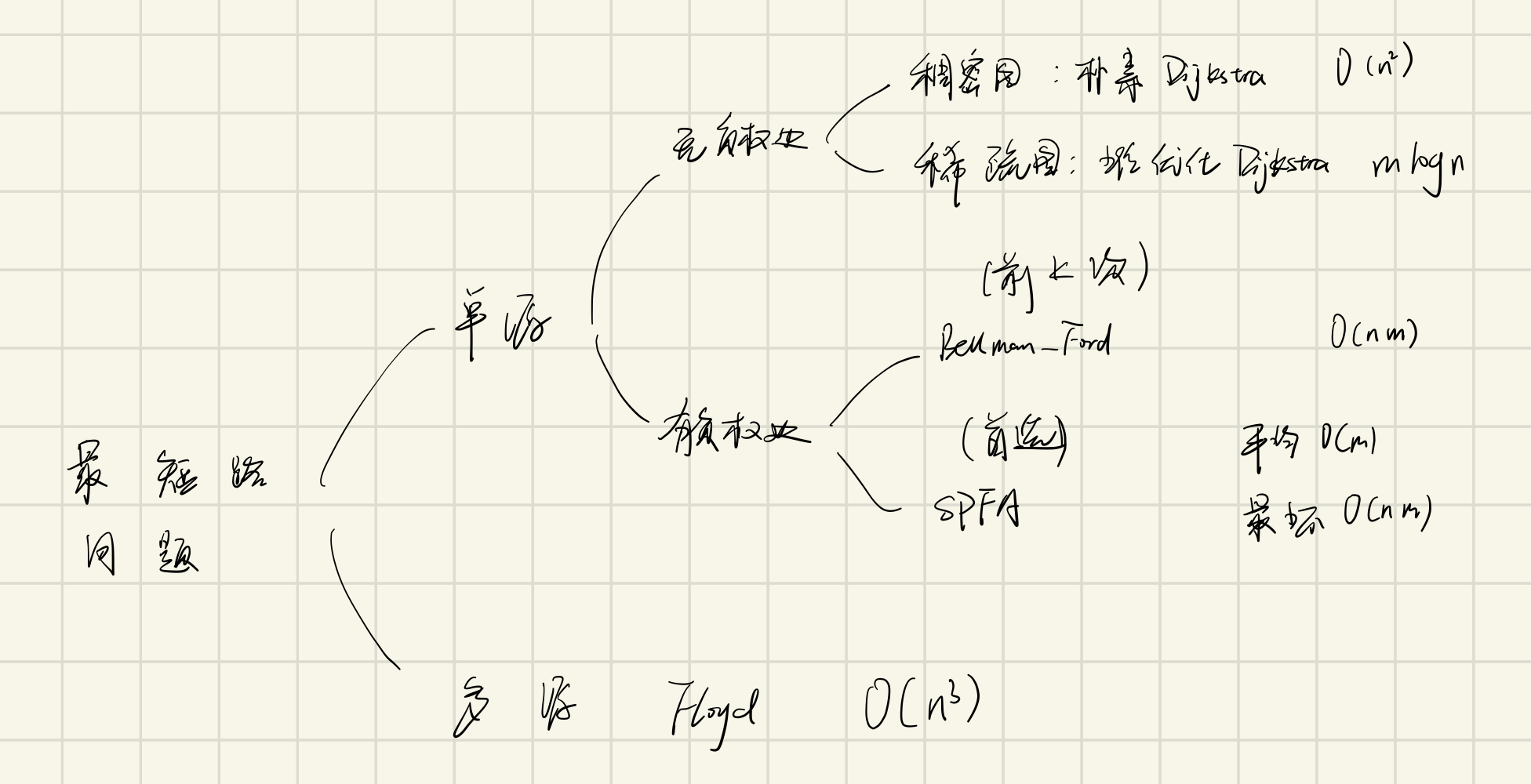
Dijkstra

Bellman-Ford

SPFA
图中不能有负权回路
优化的 Bellman-Ford 算法:只有一个节点的距离被更新了,才有必要更新他的后续节点。
队列中包含所有已经更新的点
需要用一个数组保证队列中的元素唯一,因为重复的点没有意义
Floyd
可以有负权边,但是不能有负权回路。
算法思想是动态规划:
f[k, i, j] 表示从 i 到 j 经过 1..k 个点的最短距离。
复杂度为 n^3
直接在原矩阵上操作即可:d[a][b] 表示从节点 a 到节点 b 的最短距离。
for k in 1..n {for i in 1..n {for j in 1..n {d[i][j] = min(d[i][j], d[i][k] + d[k][j]);}}}for (int i = 1; i <= n; i ++ )for (int j = 1; j <= n; j ++ )if (i == j) d[i][j] = 0;else d[i][j] = INF;while (m --) {int a, b, c;scanf("%d%d%d", &a, &b, &c);d[a][b] = min(d[a][b], c);}
最小生成树
无向图
两种算法:
- prime 算法
- kruskal 算法
难点:建图
prim 算法

写法和 Dijkstra 很像。
#include <iostream>#include <cstring>using namespace std;const int N = 510, M = 200010, INF = 0x3f3f3f3f;int g[N][N], n, m;void add_edge(int a, int b, int w) {if (a == b) return;g[a][b] = g[b][a] = min(g[a][b], w); // min !}bool st[N];int dist[N];int prim() {memset(dist, 0x3f, sizeof dist);int res = 0;for (int i = 0; i < n; i ++) {int t = -1;for (int j = 1; j <= n; j ++)if (!st[j] && (t == -1 || dist[j] < dist[t])) t = j;if (i && dist[t] == INF) return -1;if (i) res += dist[t];st[t] = true;for (int j = 1; j <= n; j ++) dist[j] = min(dist[j], g[t][j]);}return res;}int main() {scanf("%d%d", &n, &m);memset(g, 0x3f, sizeof g);for (int i = 0; i < m; i ++) {int a, b, w;scanf("%d%d%d", &a, &b, &w);add_edge(a, b, w);}int res = prim();if (res == -1) puts("impossible");else printf("%d\n", res);return 0;}
kruskal 算法

#include <iostream>#include <cstring>#include <algorithm>using namespace std;const int N = 100010, M = 400010, INF = 0x3f3f3f3f;int n, m;struct Edge {int a, b, w;bool operator< (const struct Edge &rhs) {return w < rhs.w;}} edges[M];int p[N];int find(int x) {if (p[x] != x) p[x] = find(p[x]);return p[x];}int kruskal() {for (int i = 0; i <= n; i ++) p[i] = i;sort(edges, edges + m);int res = 0;int cnt = 0;for (int i = 0; i < m; i ++) {auto e = edges[i];int a = e.a, b = e.b, w = e.w;int pa = find(a), pb = find(b);if (pa == pb) continue;else {cnt ++;res += w;p[pa] = pb;}}if (cnt == n - 1) return res;else return -1;}int main() {scanf("%d%d", &n, &m);for (int i = 0; i < m; i ++) {int a, b, w;scanf("%d%d%d", &a, &b, &w);edges[i] = {a, b, w};}int res = kruskal();if (res == -1) puts("impossible");else printf("%d\n", res);return 0;}
二分图

染色法
判定一个图是否是二分图。
性质:一个图是二分图当且仅当这个图中不含奇数环。
dfs
#include <iostream>// #incldueusing namespace std;const int N = 200010;int h[N], e[N], ne[N], idx;int n, m;int add_edge(int a, int b) {e[++ idx] = b;ne[idx] = h[a];h[a] = idx;}int colors[N];bool dfs(int a, int color) {colors[a] = color;int next_color = 3 - color;for (int cur = h[a]; cur; cur = ne[cur]) {int b = e[cur];if (colors[b]) {if (colors[b] != next_color) return false;} else {dfs(b, next_color);}}return true;}int main() {scanf("%d%d", &n, &m);for (int i = 0; i < m; i ++) {int a, b;scanf("%d%d", &a, &b);add_edge(a, b);add_edge(b, a);}for (int i = 1; i <= n; i ++) {if (!colors[i]) {if (!dfs(i, 1)) {puts("No");return 0;}}}puts("Yes");return 0;}
匈牙利算法
给定一个二分图,求最大匹配。
先到先得,能让就让。
太巧妙了。
#include <iostream>#include <cstring>using namespace std;const int N = 510, M = 200010;int h[N], e[M], ne[M], idx;int n1, n2, m;void add_edge(int a, int b) {e[++ idx] = b;ne[idx] = h[a];h[a] = idx;}int match[N];bool st[N];// int find(int a) {// for (int cur = h[a]; cur; cur = ne[cur]) {// int b = e[cur];// if (!st[b] && (!match[b] || find(match[b]))) {// st[b] = true;// match[b] = a;// return true;// }// }// return false;// }int find(int a) {for (int cur = h[a]; cur; cur = ne[cur]) {int b = e[cur];if (!st[b]) {st[b] = true;if (!match[b] || find(match[b])) {match[b] = a;return true;}}}return false;}int main() {scanf("%d%d%d", &n1, &n2, &m);for (int i = 0; i < m; i ++) {int a, b;scanf("%d%d", &a, &b);add_edge(a, b);}int res = 0;for (int i = 1; i <= n1; i ++) {memset(st, false, sizeof st);if (find(i)) res ++;}printf("%d\n", res);return 0;}
动态规划
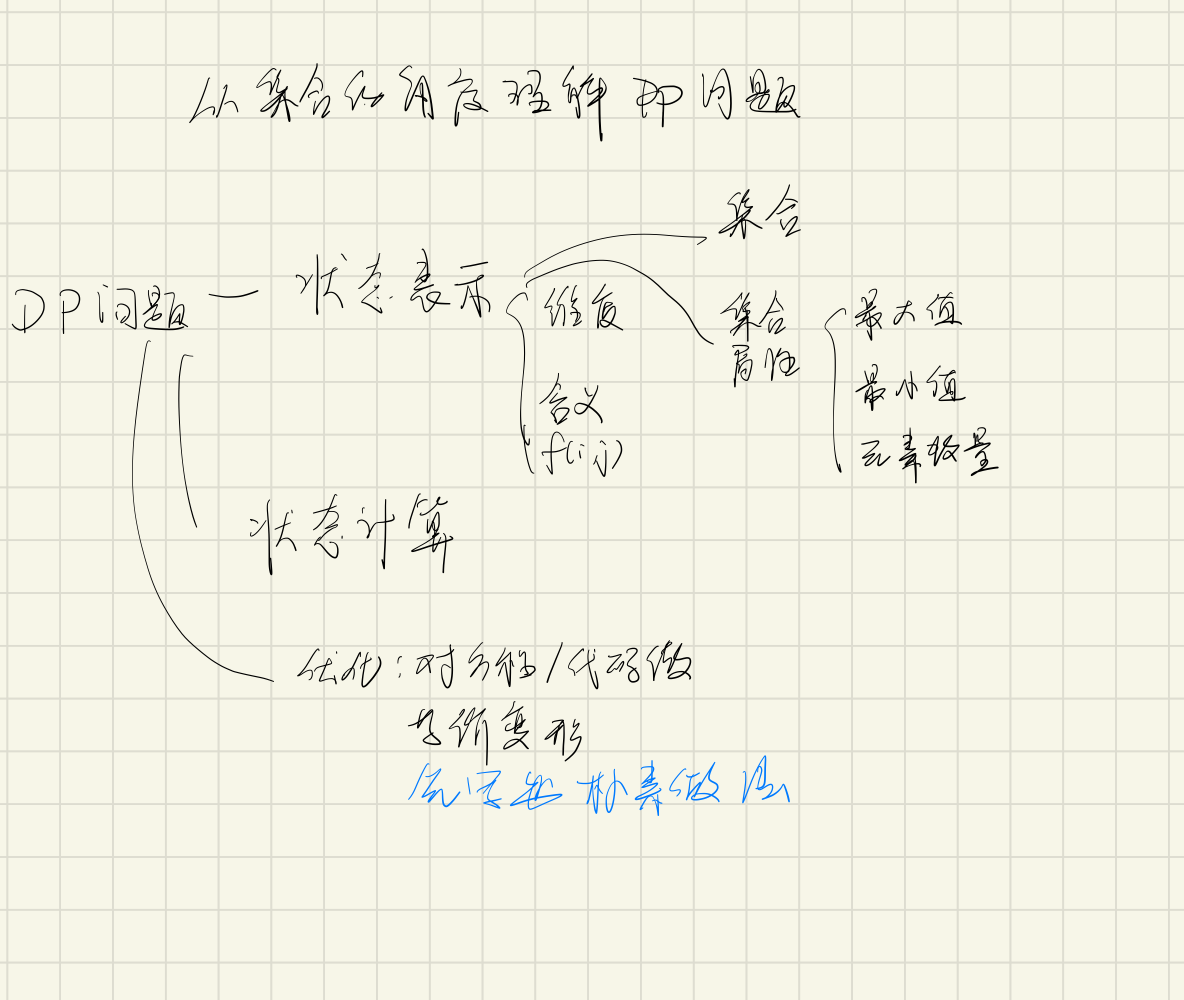
背包问题
01背包问题
N 个物品,每个物品的体积为 vi,价值为 wi 。每个物品最多只能用一次。同时有一个容量为 V 的背包。

完全背包问题
朴素做法很好理解:第 i 个物品选择 0 到 k 个。
但是这样时间复杂度比较高:n x m x k
可以通过找规律优化状态转移方程,使得时间复杂度降到:n x m
最后可以优化成一维数组存储状态,使得空间复杂度降为:m
多重背包问题
优化思路比较 nb。
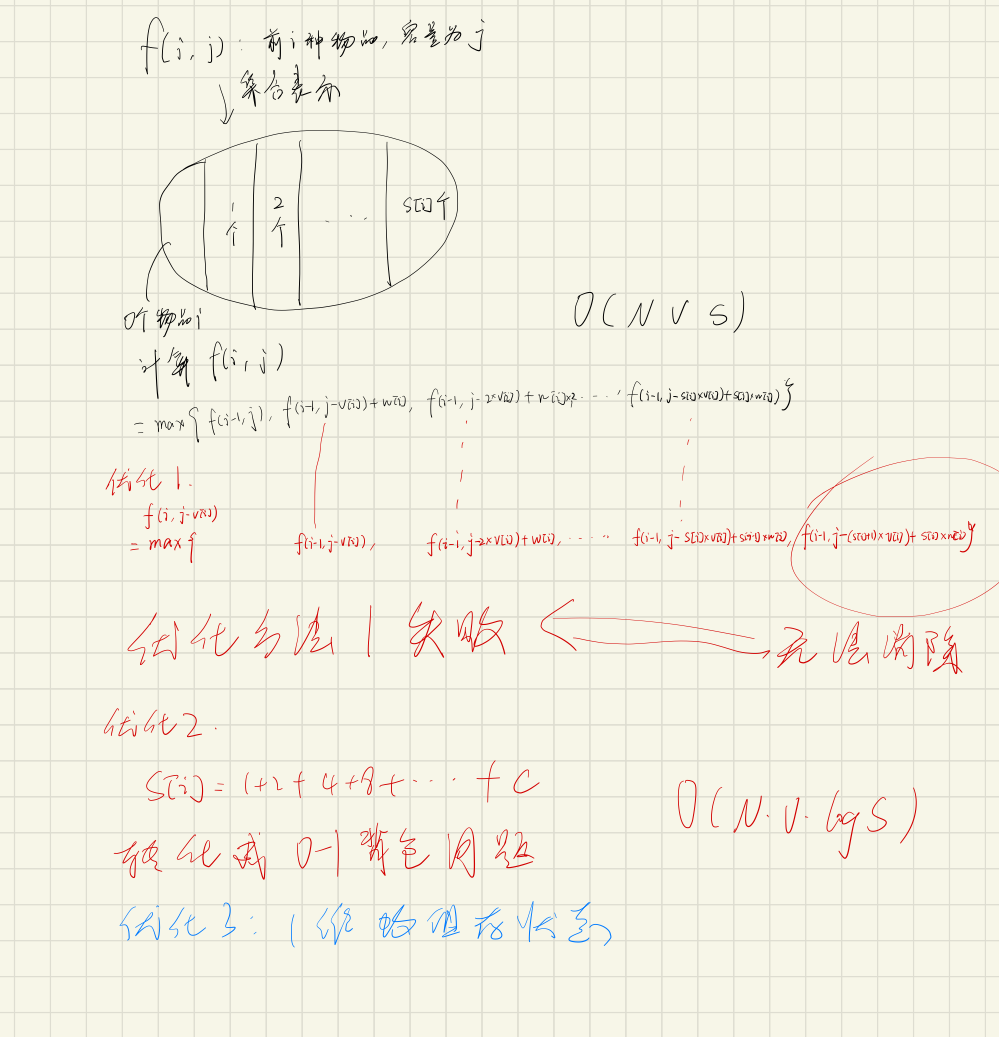
状态表示还是 f(i, j) :前 i 个物品,容量为 j。
状态计算思想如下:
- f(i, j) 表示可能的取法集合,该集合由以下子集构成:
- 取 0 个第 i 个物品
- 取 1 个第 i 个物品
- 。。。
- 取 s[i] 个地 i 个物品
所以朴素算法的时间复杂度就是:
但是我们可以对物品进行打包,比如第 i 个物品有 s 个,我们对其进行如下打包操作
- 1个:v = vi, w = wi
- 2个:v = vi 2,w = wi 2
- 。。。
- c 个:v = vi c,w = wi c
因为这些打包物品可以凑出 1 - s 其中任意多个物品,所以我们就把多重背包问题转化成了 01 背包问题。时间复杂度降到了 
实现的时候需要注意一下初始化空间的大小 
分组背包问题
f(i, j) 表示前 i 组,背包容量选 j
计算状态的思路就是遍历当前第 i 组中的每个物品,选或者不选。
线性dp
三角形权重最大路径
最长上升子序列问题

优化:
最长公共子序列

最短编辑距离

编辑距离
区间 dp
合并石子

也可以写成递归的形式(记忆化搜索)
数位统计 dp
分情况讨论
计数 dp
状态压缩 dp
使用二进制位表示状态
通常 n 比较小
蒙德里安的梦想
核心思想:
- 先放横着的小方块
- 总方案数等于所有横着小方块的合法摆放数
- 如何判断是否合法:
- 每一列不能有连续空奇数个
动态规划:
- 状态表示:
- f[i, j] 表示前 i - 1 列已经摆好,且从第 i-1 列伸到第 i 列的状态为 j 的所有摆放方式的集合
- 状态计算
树形 dp
通常用 dfs 求解
没有上司的舞会

记忆优化搜索
滑雪
贪心算法
区间问题
相关题目
- 111 畜栏
- 112 雷达
按照点的左端点 or 右端点进行排序。
证明正确性:
- Ans <= cnt
- Ans >= cnt
- Ans == cnt
- 结合反证法
区间选点

最大不相交区间数量

区间分组

区间覆盖

Huffman 树
最小堆冲冲冲
合并果子问题
和“合并石子”的区别:石子只能合并相邻的两堆石子,合并果子可以合并任意两堆果子
排序不等式
绝对值不等式
推公式

若有收获,就点个赞吧
0 人点赞
