最近突然对人工智能有点兴趣,想学一学,虽然我自己知道我这种大概就是三分钟热血吧,但本着能学一点是一点的精神,学到哪就是哪吧,无所谓终点,只看旅途;毕竟我只是个臭搞安全的,大部分工作时间也在搞安全,现在工作内容暂时也与AI无关,所以纯粹就是兴趣来了,那就搞一搞
废话不多说,开搞吧
基本概念
我这里是跟着B站的一个大佬来学的,他这个讲得很清楚,不需要什么所谓的数学理论基础即可开始学习,我其实也最烦那些一上来就堆数学公式的教程,像这种会用通俗的语言讲清楚基本概念,然后又有代码实操的教程才是最屌的,我一直相信大道至简是真理
链接:https://www.bilibili.com/video/BV13W411Y75P?p=1
所谓的强化学习, 是让计算机实现从一开始什么都不懂, 脑袋里没有一点想法, 通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法. 这就是一个完整的强化学习过程,简单来说,这是个基于反馈的AI算法,会根据反馈不断条件自己策略的东西,说到这里,有经验的二进制漏洞挖掘狗就明白了,这个玩意的算法核心思想和fuzz是很像的,都是通过反馈机制不断调整行为的算法
有关强化学习的算法有好几种,这里先从最简单的Qlearning开始学习吧
简单的例子
这里用了一个最简单的找宝藏的例子,如下
0——T
0表示探宝者的位置,他可以往右边走5步即可找到宝藏T,这个事情用强化学习的算法来做,就能在10轮尝试的学习时间内找到最短的寻宝路径
直接看代码即可
import numpy as npimport pandas as pdimport timeN_STATES = 6 # 1维世界的宽度ACTIONS = ['left', 'right'] # 探索者的可用动作EPSILON = 0.9 # 贪婪度 greedyALPHA = 0.1 # 学习率GAMMA = 0.9 # 奖励递减值MAX_EPISODES = 10 # 最大回合数FRESH_TIME = 0.1 # 移动间隔时间def build_q_table(n_states, actions):table = pd.DataFrame(np.zeros((n_states, len(actions))), # q_table 6行2列全0初始化columns=actions, # columns 对应的是行为名称)return table
首先引入两个模块 numpy、pandas,这两个模块是很常用的,Numpy支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库;pandas是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)
需要了解一下这两个模块的基本api的用法才能理解后面的一系列的操作,这里简单贴两个教程:
https://www.runoob.com/numpy/numpy-ndarray-object.html
https://www.runoob.com/pandas/pandas-tutorial.html
然后定义一些全局变量,这些后面会介绍用途
最后定义build_q_table函数用于生成一个q_table,这个q_table是这个记录这个算法核心数据的矩阵,初始化后的值是这样的:
left right0 0.0 0.01 0.0 0.02 0.0 0.03 0.0 0.04 0.0 0.05 0.0 0.0
左边的一列代表探索者每一步状态,最上边一行代表探索者可能采取的动作,也就是向左还是向右,中间的数据则是表示每个状态中采取动作时的概率系数
接着 定义choose_action函数
# 在某个 state 地点, 选择行为def choose_action(state, q_table):state_actions = q_table.iloc[state, :] # 选出这个 state 的所有 action 值if (np.random.uniform() > EPSILON) or (state_actions.all() == 0):# 非贪婪 or 或者这个 state 还没有探索过#也就是10%的概率或者 state没探索过的情况下进行随机选择action_name = np.random.choice(ACTIONS)else:# 90%的情况下都返回一个当前可采取的收益最大的动作# action_name = state_actions.argmax() # 这个函数没了,版本问题,要换下边这个action_name = state_actions.idxmax()return action_name
然后是获取环境的函数,这个函数反馈的东西是采取A动作后走到的新位置S和走到S位置的收益R
def get_env_feedback(S, A):#得到环境的反馈#这里反馈的值由reward决定,如果走到了宝藏的位置那么R就会等于1if A == 'right': # move rightif S == N_STATES - 2: # terminateS_ = 'terminal'R = 1else:S_ = S + 1R = 0else: # move leftR = 0if S == 0:S_ = S # reach the wallelse:S_ = S - 1return S_, R
接着是一个输出函数,就是打印寻宝者的位置的函数
def update_env(S, episode, step_counter):# 更新环境,这个函数就是用来画图的,描述当前探险者走到哪里了env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environmentif S == 'terminal':#这种情况说明这一回合已经走完了interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)print('\r{}'.format(interaction), end='')time.sleep(1)print('\r ', end='')else:env_list[S] = 'o'#标识第S+1步的位置interaction = ''.join(env_list)print('\r{}'.format(interaction), end='')#输出位置寻宝者的位置time.sleep(FRESH_TIME)
最后就是我们最核心的强化学习的算法函数
def rl():q_table = build_q_table(N_STATES, ACTIONS) # 初始 q tableprint(q_table)for episode in range(MAX_EPISODES): # 回合step_counter = 0S = 0 # 回合初始位置is_terminated = False # 是否回合结束update_env(S, episode, step_counter) # 初始环境更新,探险者0在最左边开始while not is_terminated:A = choose_action(S, q_table) # 选行为,向左走还是向右走S_, R = get_env_feedback(S, A) # 实施行为并得到环境的反馈, S_表示新走到的位置q_predict = q_table.loc[S, A] # 获取当前qtable中采取A动作可获取的收益值# print("q_predict",q_predict)# input()if S_ != 'terminal':q_target = R + GAMMA * q_table.iloc[S_, :].max()#获取走下一步位置可以获得的收益最大值乘以一个系数GAMMA,再加上一个下一步可获取的R值#注意这里获取的是下一步中可能的所有动作的最大值,这是为了ai分辨走下一步的性价比是否更高else:q_target = R # 实际的(状态-行为)值 (回合结束)is_terminated = True # terminate this episodeq_table.loc[S, A] += ALPHA * (q_target - q_predict) # q_table 更新# 这里公式就是 (预估的收益值-现有qtable记录的收益值)*一个系数ALPHA# 这实际上表示,当探险者走到S位置时,采用A动作所带来的收益,这里训练的时间越长,采取不同动作的倾向性就更明显S = S_ # 探索者移动到下一个 stateupdate_env(S, episode, step_counter+1) # 环境更新step_counter += 1print("\n",q_table)return q_tableif __name__ == "__main__":q_table = rl()print('\r\nQ-table:\n')print(q_table)
这里写了很多注释进行描述了,不过多的阐述函数作用
运行一下先看结果,这里设计成每一回合都会输出当前回合生成的qtable

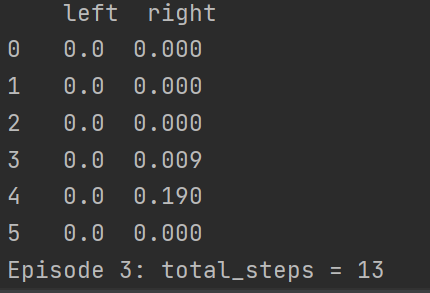
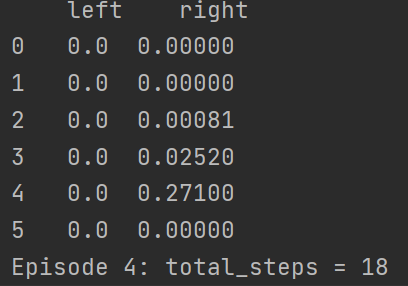
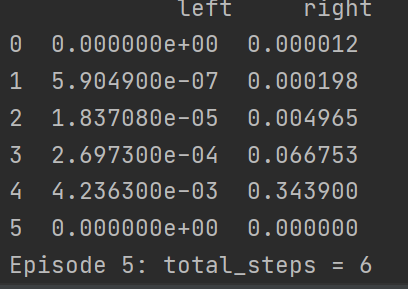

可以看到,到第六回合的时候已经产生最优解了,我最快的一次是在第三回合就产生这个最优解,此时可以看到这个qtable,每一步的选择上都是选择向右走的收益最大,因此这里就会一直向右走,因此做到最优解五步之内找到宝藏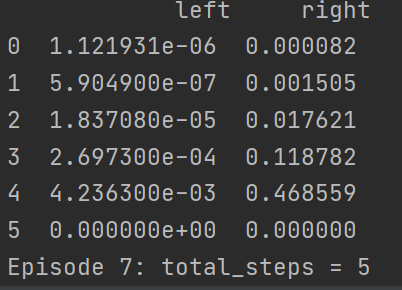
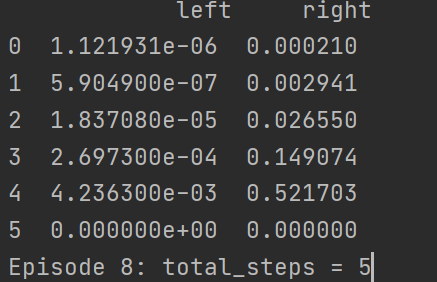
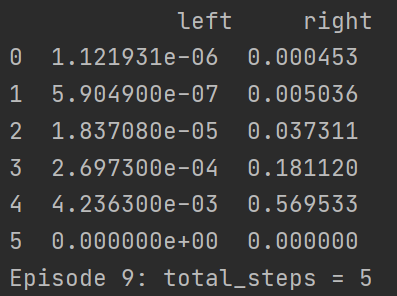

直到结束,一直都是五步最优解,但你多尝试几次就会发现有的时候前面的回合已经找到最优解了,但还是存在走了超过5步的情况,这是因为我们在choose_action函数中设计了10%的概率随机选择动作,于是才有了这种情况
小结
强化学习的思路很简单,无非就是根据环境选择最好的结果,这里涉及到的核心数据结构是qtable,纵轴表示每个不同的状态,横轴表示每个不同的选择,其值就是每个状态的不同选择的收益值,收益值越高选择对应行为的概率也就越高,从而实现了强化学习
除了qlearning的学习算法以外,另一个重要的因素是环境反馈,这里的环境反馈只会反馈一个新位置和新位置所带来的收益reward,且这里的reward只有在最终找到宝藏后才能有数值收益,如果你去调试一下第一回合你就会发现,由于最开始全部采取随机动作,我最倒霉的一次是一回合走了90步才找到宝藏,特别离谱,这个例子还只是一个一维地图的寻宝游戏,如果是二维甚至三维,那可供选择的动作可就是非常非常多了,这种情况下想要在初始环节随机撞到宝藏是几乎不可能的,因此这里有个需要改进的点是reward需要考虑多因素,除了找到宝藏的奖励值,还需要考虑与宝藏之间的距离,找宝藏过程中如果还有怪物的设定,就还需要加入负反馈机制
之后如果有空我想实现一个二维的寻宝游戏,加入多种宝藏和怪物的因素,让ai去学习如何避开怪物又吃到最多的宝藏,不过一般我这么说的时候就会鸽了。。。
参考
https://www.bilibili.com/video/BV13W411Y75P?p=1
https://mofanpy.com/tutorials/machine-learning/reinforcement-learning/intro-RL/

若有收获,就点个赞吧
0 人点赞
