这里记录过去一周,大数据相关值得分享的东西,每周发布。
今天尝试写第 6 期,记录过去一周一点所见所闻。假期玩(。・∀・)ノ゙嗨了。
技术一瞥
1、hdfs getconf 命令使用
hdfs getconf is utility for getting configuration information from the config file.hadoop getconf[-namenodes] gets list of namenodes in the cluster.[-secondaryNameNodes] gets list of secondary namenodes in the cluster.[-backupNodes] gets list of backup nodes in the cluster.[-includeFile] gets the include file path that defines the datanodes that can join the cluster.[-excludeFile] gets the exclude file path that defines the datanodes that need to decommissioned.[-nnRpcAddresses] gets the namenode rpc addresses[-confKey [key]] gets a specific key from the configuration
栗子:hdfs getconf -confKey fs.defaultFS 查看 hdfs 的 uri 地址。
2、gzip 在 hadoop 中不会分割
图片
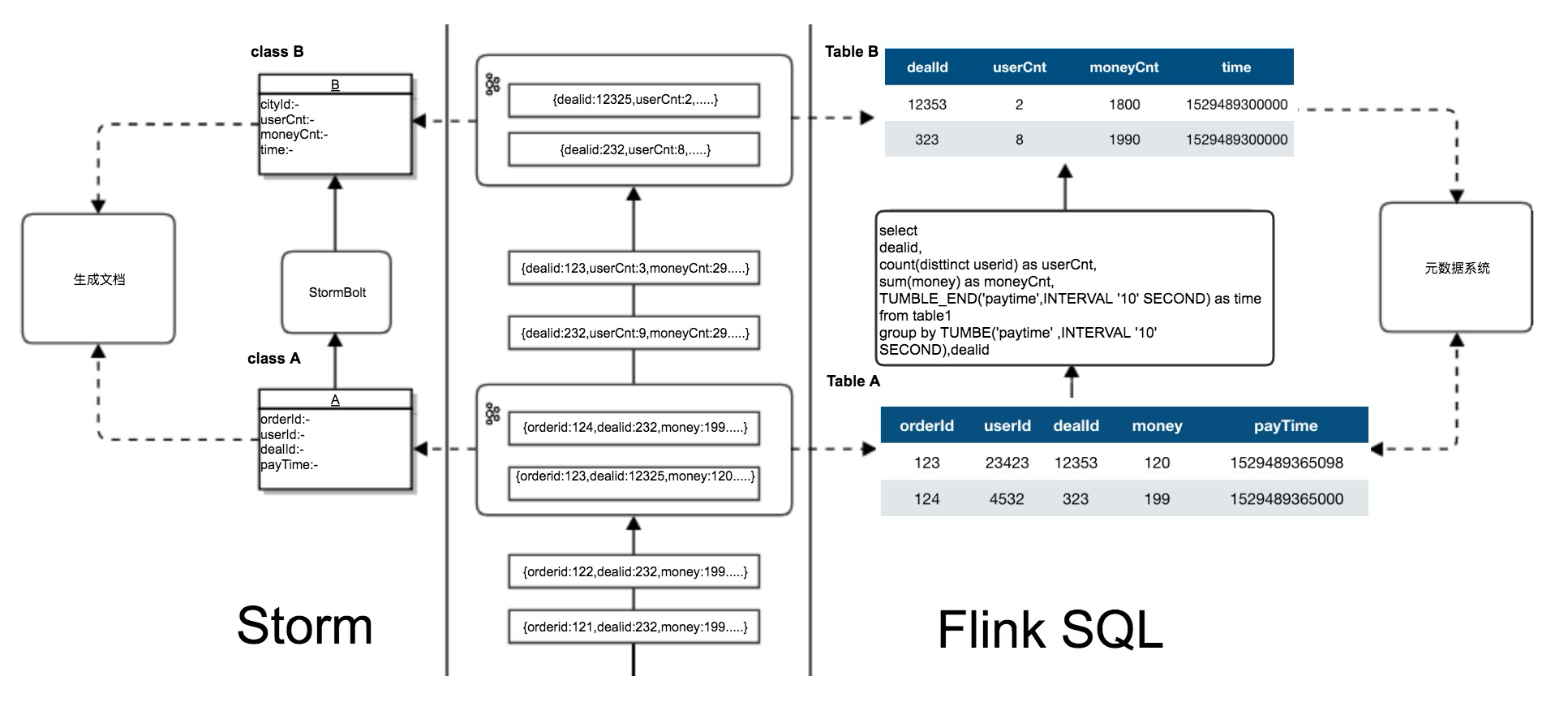
对比 Storm,我为什么选择 Flink 引擎?
在使用 Storm 开发时处理逻辑与实现需要固化在 Bolt 的代码。Flink 则可以通过 SQL 进行开发,代码可读性更高,逻辑的实现由开源框架来保证可靠高效,对特定场景的优化只要修改 Flink SQL 优化器功能实现即可,而不影响逻辑代码。使我们可以把更多的精力放到到数据开发中,而不是逻辑的实现。当需要离线数据和实时数据口径统一的场景时,我们只需对离线口径的 SQL 脚本稍加改造即可,极大地提高了开发效率。同时对比图中 Flink 和 Storm 使用的数据模型,Storm 需要通过一个 Java 的 Class 去定义数据结构,Flink Table 则可以通过元数据来定义。可以很好的和数据开发中的元数据,数据治理等系统结合,提高开发效率。
文章
1、Flink Kafka Connector 与 Exactly Once 剖析
Flink Kafka Connector 是 Flink 内置的 Kafka 连接器,它包含了从 Kafka Topic 读入数据的 Flink Kafka Consumer 以及向 Kafka Topic 写出数据的 Flink Kafka Producer,除此之外 Flink Kafa Connector 基于 Flink Checkpoint 机制提供了完善的容错能力。本文从 Flink Kafka Connector 的基本使用到 Kafka 在 Flink 中端到端的容错原理展开讨论。
在业务开发中,大量场景需要唯一ID来进行标识:用户需要唯一身份标识;商品需要唯一标识;消息需要唯一标识;事件需要唯一标识…等等,都需要全局唯一ID,尤其是分布式场景下。
唯一ID有哪些特性或者说要求呢?按照我的分析有以下特性:
- 唯一性:生成的ID全局唯一,在特定范围内冲突概率极小
- 有序性:生成的ID按某种规则有序,便于数据库插入及排序
- 可用性:可保证高并发下的可用性
- 自主性:分布式环境下不依赖中心认证即可自行生成ID
- 安全性:不暴露系统和业务的信息
Flink在处理实时数据时,假如其中一条数据是脏数据,例如格式错误,字段缺少等会报错,这时候该怎么处理呢?该篇文章结合实际生产实例,总结了实际经验。
笔者从 2008 年开始工作到现在也有 11 个年头了,一路走来都在和数据打交道,做过大数据底层框架内核的开发(Hadoop,Pig,Tez,Spark,Livy),也做过上层大数据应用开发(写 MapReduce Job 做 ETL ,用 Hive 做 Ad hocquery,用 Tableau 做数据可视化,用 R 做数据分析)。我一直不太喜欢张口闭口讲“大数据”,我更喜欢说“数据”。因为大数据的本质在于“数据”,而不是“大”。由于媒体一直重点宣扬大数据的“大”,所以有时候我们往往会忽然大数据的本质在“数据”,而不是“大”,“大”只是你看到的表相,本质还是数据自身。
5、Linux系统——架构浅析
掐指一算自己从研究生开始投入到Linux的海洋也有几年的时间,即便如此依然对其各种功能模块一知半解。无数次看了Linux内核的技术文章后一头雾水,为了更系统地更有方法的学Linux,特此记录。
资源
2、深入理解浏览器原理
本文从市面主流的浏览器及相应的内核引擎开始,介绍了Chromium为代表的浏览器架构及Blink内核的功能架构。Chromium为多进程架构,用户从启动运行浏览器后,先后经过页面导航、渲染、资源加载、样式计算、布局、绘制、合成到栅格化,最后完成GPU展示。而页面渲染完成后,浏览器如何响应页面操作事件也进行了深入的介绍。良心推荐!
当面临存储选型时是选择关系型还是非关系型数据库?如果选择了非关系型的redis,redis常用数据类型占用内存大小如何估算的?redis的性能瓶颈又在哪里?
文摘
1
关于外交
我现在就特别看不起一些年轻人,没有什么阅历,什么都不懂,就按着自己想法去参与政治,开战,夺岛。以为自己什么对军事很有研究,说中国软弱,如果中国真的在你们这样的人手中,国家还能存活多久。
一个国家最重要的是什么,不是军事,更重要的是金融话语权,你以为俄罗斯拿到克里米亚,但你知道不道 俄罗斯只是看起来风光,背后的黄金储备不足,和经济低迷。其实看到这个问题我内心很是忧虑,中国外交现在处在一个尴尬的地步:国人觉得中国外交十分软弱,外国人却认为十分的强硬。当年,在我们外交上最强硬的年代,却是国防最薄弱,美国军舰飞机肆无忌惮侦查飞行的年代,而那个时候,美国是不表态的,而我们的军队就是:开火!想尽一切办法打下来,但是有时候真是无可奈何,国防不是武侠电影,不可能一夜之间变成高手。现在美国的军舰飞机离我们越来越远,而嘴上功夫却越来越多,是哪一方变强了一目了然,我们的军队依然希望开火把它打下来,可是美国人不给你机会,因为他不来了。50年的时候他在台湾海峡,因为他知道你拿他没辙,96年他在台湾东侧,因为他知道你鞭长莫及,99年他敢轰炸大使馆,因为他知道最坏的结果是怎样,现在,哪怕是远在关岛,他也会如坐针毡,美国人非常谨慎,如果我们像俄罗斯一样底牌俩王四个二的话,他连擦枪走火的机会都不会给你,还是那句话,不是我们越强大而国家越软弱,而是别人制造事端,让你自己觉得自己国家越来越软弱。从而让人们忽视恰恰是敌人用下三滥的招数,证明自己对越来越强大中国的无可奈何,因为他知道这个国家不可能被征服,却可以被自己人内部瓦解,战舰上的美国大兵只会越躲越远,而重金收买的汉奸卖国贼将会冲在看不见的最前线,网络赛博战已经打响,如果你做不了上阵杀敌的英雄,那就做一个明辨是非的智者。
2
关于“NBA”辱华
我来简单分析一下,美国的政治正确跟中国的政治正确,不一样,美国的言论自由底线是种族歧视,中国的言论自由底线是国家主权领土完整,这跟国家历史经历很大关系,我国有和而不同的大思路,不会存在种族歧视问题,各民族团结,更不会有因为种族歧视发生的大规模战争,屠杀等;反之,美国历史上从未经历过被人侵略,被人脚踏国土的战争,丧权辱国的经历更是没有,相反倒是短短两百年的历史是移民的问题,以及种族歧视问题导致的战争问题,这导致了两国之间对于言论自由底线不同,伤害民族感情的点不同。这件事很难处理,当我们这边的球迷在不解雇莫雷,不看NBA的时候,美国球迷在那边莫雷道歉,NBA要是处罚,就不给NBA花一分钱。在加上西方媒体渲染的中国形象,美国民众对中国没有正确的认知,导致了莫雷的这句话在他们眼里不算什么,是很言论自由的一句表达,而我们在这边试压,他们无法理解我们的民族感情所以科凡在直播中说了一句猩猩,就被封杀三年,涉及到人种,这在美国是大问题,是大的政治错误,尽管我们都知道科凡并无恶意,只是一种方便的称呼,但就是美国那边过不去,而现在我们也一样,过不去,(而且我并不认为莫雷无恶意,对于一个有政治经历的人来说)中国,美国已经是世界强国,不碰一碰,是不可能彻底了解的,政治,经济已经开始碰了,文化,社会也开始了,全方位碰撞,你们准备好了吗?中国人,你要自信!不看NBA,从我做起,女排联赛要开始了,我要关注他们,提高他们的关注度,增加他们的收入!让赞助商投女排!
订阅
本专栏也会定期同步到公众号和知识星球,欢迎订阅。直接扫码或者微信搜索大数据学习指南
(完)

若有收获,就点个赞吧
0 人点赞
