缓冲流
虽然普通的文件流读取文件数据非常便捷,但是每次都需要从外部I/O设备去获取数据,由于外部I/O设备的速度一般都达不到内存的读取速度,很有可能造成程序反应迟钝,因此性能还不够高,而缓冲流正如其名称一样,它能够提供一个缓冲,提前将部分内容存入内存(缓冲区)在下次读取时,如果缓冲区中存在此数据,则无需再去请求外部设备。同理,当向外部设备写入数据时,也是由缓冲区处理,而不是直接向外部设备写入。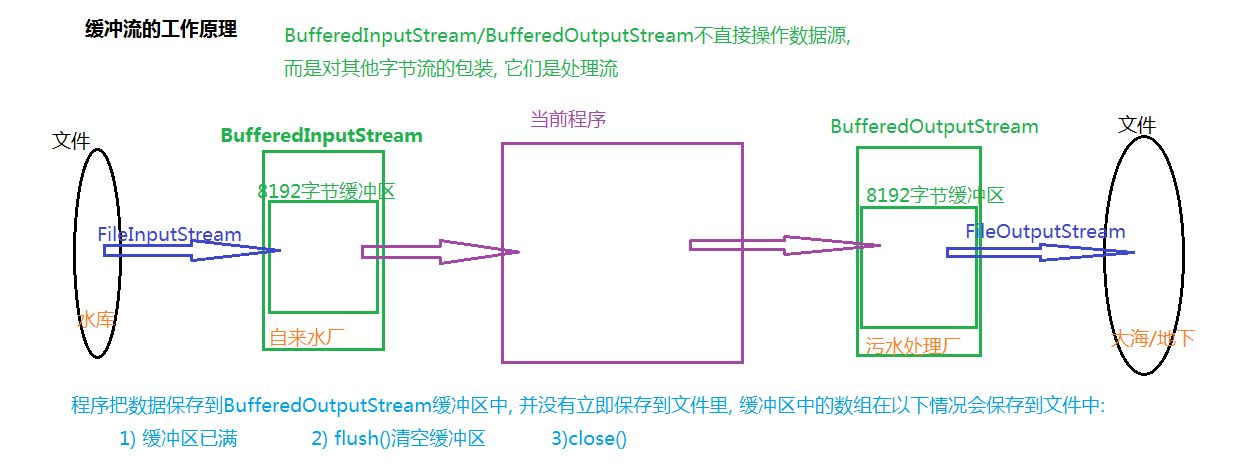
缓冲字节流
要创建一个缓冲字节流,只需要将原本的流作为构造参数传入BufferedInputStream即可:
public static void main(String[] args) {try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){ //传入FileInputStreamSystem.out.println((char) bufferedInputStream.read()); //操作和原来的流是一样的}catch (IOException e){e.printStackTrace();}}
实际上进行I/O操作的并不是BufferedInputStream,而是我们传入的FileInputStream,而BufferedInputStream虽然有着同样的方法,但是进行了一些额外的处理然后再调用FileInputStream的同名方法,这样的写法称为装饰者模式
public void close() throws IOException {byte[] buffer;while ( (buffer = buf) != null) {if (bufUpdater.compareAndSet(this, buffer, null)) { //CAS无锁算法,并发会用到,暂时不管InputStream input = in;in = null;if (input != null)input.close();return;}// Else retry in case a new buf was CASed in fill()}}
实际上这种模式是父类FilterInputStream提供的规范,后面我们还会讲到更多FilterInputStream的子类。
我们可以发现在BufferedInputStream中还存在一个专门用于缓存的数组:
/*** The internal buffer array where the data is stored. When necessary,* it may be replaced by another array of* a different size.*/protected volatile byte buf[];
I/O操作一般不能重复读取内容(比如键盘发送的信号,主机接收了就没了),而缓冲流提供了缓冲机制,一部分内容可以被暂时保存,BufferedInputStream支持reset()和mark()操作,首先我们来看看mark()方法的介绍:
/*** Marks the current position in this input stream. A subsequent* call to the <code>reset</code> method repositions this stream at* the last marked position so that subsequent reads re-read the same bytes.* <p>* The <code>readlimit</code> argument tells this input stream to* allow that many bytes to be read before the mark position gets* invalidated.* <p>* This method simply performs <code>in.mark(readlimit)</code>.** @param readlimit the maximum limit of bytes that can be read before* the mark position becomes invalid.* @see java.io.FilterInputStream#in* @see java.io.FilterInputStream#reset()*/public synchronized void mark(int readlimit) {in.mark(readlimit);}
当调用mark()之后,输入流会以某种方式保留之后读取的readlimit数量的内容,当读取的内容数量超过readlimit则之后的内容不会被保留,当调用reset()之后,会使得当前的读取位置回到mark()调用时的位置。
public static void main(String[] args) {try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){bufferedInputStream.mark(1); //只保留之后的1个字符System.out.println((char) bufferedInputStream.read());System.out.println((char) bufferedInputStream.read());bufferedInputStream.reset(); //回到mark时的位置System.out.println((char) bufferedInputStream.read());System.out.println((char) bufferedInputStream.read());}catch (IOException e) {e.printStackTrace();}}
我们发现虽然后面的部分没有保存,但是依然能够正常读取,其实mark()后保存的读取内容是取readlimit和BufferedInputStream类的缓冲区大小两者中的最大值,而并非完全由readlimit确定。因此我们限制一下缓冲区大小,再来观察一下结果:
public static void main(String[] args) {try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"), 1)){ //将缓冲区大小设置为1bufferedInputStream.mark(1); //只保留之后的1个字符System.out.println((char) bufferedInputStream.read());System.out.println((char) bufferedInputStream.read()); //已经超过了readlimit,继续读取会导致mark失效bufferedInputStream.reset(); //mark已经失效,无法reset()System.out.println((char) bufferedInputStream.read());System.out.println((char) bufferedInputStream.read());}catch (IOException e) {e.printStackTrace();}}
了解完了BufferedInputStream之后,我们再来看看BufferedOutputStream,其实和BufferedInputStream原理差不多,只是反向操作:
public static void main(String[] args) {try (BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("output.txt"))){outputStream.write("lbwnb".getBytes());outputStream.flush();}catch (IOException e) {e.printStackTrace();}}
操作和FileOutputStream一致,这里就不多做介绍了。
缓冲字符流
缓存字符流和缓冲字节流一样,也有一个专门的缓冲区,BufferedReader构造时需要传入一个Reader对象:
public static void main(String[] args) {try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){System.out.println((char) reader.read());}catch (IOException e) {e.printStackTrace();}}
使用和reader也是一样的,内部也包含一个缓存数组:
private char cb[];
相比Reader更方便的是,它支持按行读取:
public static void main(String[] args) {try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){System.out.println(reader.readLine()); //按行读取}catch (IOException e) {e.printStackTrace();}}
读取后直接得到一个字符串,当然,它还能把每一行内容依次转换为集合类提到的Stream流:
public static void main(String[] args) {try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){reader.lines().limit(2).distinct().sorted().forEach(System.out::println);}catch (IOException e) {e.printStackTrace();}}
它同样也支持mark()和reset()操作:
public static void main(String[] args) {try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){reader.mark(1);System.out.println((char) reader.read());reader.reset();System.out.println((char) reader.read());}catch (IOException e) {e.printStackTrace();}}
BufferedReader处理纯文本文件时就更加方便了,BufferedWriter在处理时也同样方便:
public static void main(String[] args) {try (BufferedWriter reader = new BufferedWriter(new FileWriter("output.txt"))){reader.newLine(); //使用newLine进行换行reader.write("汉堡做滴彳亍不彳亍"); //可以直接写入一个字符串reader.flush(); //清空缓冲区}catch (IOException e) {e.printStackTrace();}}

若有收获,就点个赞吧
0 人点赞
