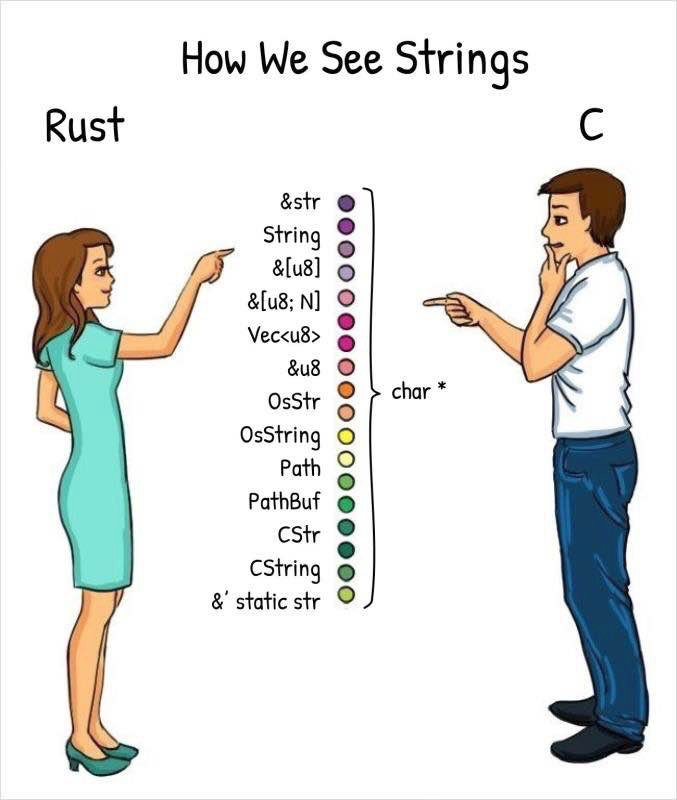
1、分类
Rust的文本类型主要包含6种:character,string,raw string,byte,byte string,raw byte string。
1.1、character(rust类型为:char)
以一对单引号包含的单个合法的Unicode character,可以包含单引号自身,但是此时要以斜杠转义,如下都是合法的character字符:
let s1 = 'H';let s2 = '\'';let s3 = '"';let s4 = '\n';let s5 = '\x41'; // 与s6等价let s6 = 'A';let s7 = '\u{6211}'; //与s8等价let s8 = '我';
特别注意:char值的合法范围是 0x0000 ~ 0xD7FF 或者 0xE000 ~ 0x10FFFF,采用UTF-32编码,固定4个字节长度。
1.2、string(rust类型为:&str)
**
以一对双引号包含的多个合法的Unicode character,可以包含双引号自身,但是此时要以斜杠转义,并允许使用”\”换行,此时下一行行首的所有空白字符会被自动去除,如下都是合法的string:
let s1 = "HHHH";let s2 = "\"";let s3 = "''";let s4 = "\n\n\n";let s5 = "\x41\x41"; // 与s6等价let s6 = "AA";let s7 = "\u{6211}\u{6211}"; //与s8等价let s8 = "我我";let s9 = "hello"; // 与s10等价let s10 = "he\llo";
1.3、raw string(rust类型为:&str)
raw string不处理任意转义字符,以r开头,紧跟着0~n个#字符,中间是任何的Unicode character序列,然后以同样数量的 # 结束,以下都是合法的 raw string:
let s1 = r"abc"; // -> abclet s2 = r"abc'"; // -> abc'let s3 = r"我"; // -> 我let s4 = r"\x41"; // -> \x41let s5 = r"\n"; // -> \nlet s6 = r"\u{6211}\u{6211}"; // -> \u{6211}\u{6211}let s7 = r#"""#; // -> "let s8 = r"###"; // -> ###let s9 = r#"helloworld"#; // -> hello\n\n\tworld
- 如果
Unicode character序列不包含双引号,则首尾的#可以省略。 如果
Unicode character序列包含有#序列,并且包含双引号字符,则位于开始和结束的#数量要比Unicode character序列包含的连续的#的最多个数至少多一个。1.4、byte literals(rust类型为:u8)
**
以b字符开头,一对单引号包含的单个合法的ASCII,可以包含单引号自身,但是此时要以斜杠转义,如下都是合法的byte literals字符,与character的差别是:character支持unicode,byte literals不支持Unicode,如下都是合法的byte literals:let s1 = b'\x41';let s2 = b'A';let s3 = b'\t';let s4 = b'\'';let s5 = b'"';let s6 = b'\\';
1.5、byte string literals(rust类型是:&[u8; usize])
以
b字符开头,一对双引号包含的多个合法的ASCII,可以包含双引号自身,但是此时要以斜杠转义,并允许使用”\”换行,此时下一行行首的所有空白字符会被自动去除,如下都是合法的byte string literals:let s1 = b"\x41\x41";let s2 = b"AA";let s3 = b"\t\t";let s4 = b"\'\'";let s5 = b"\"\"";let s6 = b"\\\\";
1.6、raw byte string literals(rust类型是:&[u8; usize])
raw byte string不处理任意转移字符,以br开头,紧跟着0~n个#字符,中间是任何的ASCII序列,然后以同样数量的#结束,以下都是合法的raw byte string literals:let s1 = br"abc";let s2 = br"abc'";let s3 = br"\x41";let s4 = br"\n";let s5 = br"\u{6211}\u{6211}";let s6 = br#"""#;let s7 = br"###";let s8 = r#"helloworld"#; // -> hello\n\n\tworld
如果
raw byte string序列不包含双引号,则首尾的#可以省略;- 如果
raw byte string序列包含有#序列,并且包含双引号字符,则位于开始和结束的#数量要比raw byte string序列包含的连续的#的最多个数至少多一个。重要类型
其基本等价于一个智能指针,内部实现为:Stringpub struct String {vec: Vec<u8>,}
2、应用场景
2.1、类型转换
```rust let s1 = String::from(“中国-China”); let s2 = s1.as_str();Stringto&str
<a name="RvHGF"></a>#### `&str` to `String````rustlet s1 = "中国-China";let s2 = s1.to_string();let s3 = String::from("中国-China");let s4: String = s1.into();
String/&str to slice: &[u8]
let s1 = String::from("中国-China");let s2 = s1.as_bytes();let s1 = "中国-China";let s2 = s1.as_bytes();
char to u8 与 u8 to char
let s1: u8 = 70;let s2 = s1 as char;let s3 = 'H';let s4 = s3 as u8;
2.2、具体场景
计算字节长度
fn main() {let s1 = "中国-China";println!("{:?}", s1.len()); // -> 12let s2 = String::from("中国-China");println!("{:?}", s2.len()); // -> 12}
计算字符个数
fn main() {let s1 = "中国-China";println!("{:?}", s1.chars().count()); // -> 8let s2 = String::from("中国-China");println!("{:?}", s2.chars().count()); // -> 8}
截取指定开始的 n 个的字符
fn substr(s: &str, start: usize, length: usize) -> String {s.chars().skip(start).take(length).collect()}
获取指定位置开始的n个字节(如果存在非法的字符边界,则返回None)
fn main() {let s = String::from("中国-China");println!("{:?}", s.get(0..=5)); // -> Some("中国")println!("{:?}", s.get(0..=4)); // -> None}
判断是不是包含某个子串
fn main() {let s1 = "中国-China";let s2 = String::from("中国-China");assert_eq!(true, s1.contains("中国"));assert_eq!(true, s2.contains("中国"));}
判断是不是以某个字符串开头
fn main() {let s1 = "中国-China";let s2 = String::from("中国-China");assert_eq!(true, s1.starts_with("中国"));assert_eq!(true, s2.starts_with("中国"));}
判断是不是以某个字符串结尾
fn main() {let s1 = "中国-China";let s2 = String::from("中国-China");assert_eq!(true, s1.ends_with("China"));assert_eq!(true, s2.ends_with("China"));}
全部转为大写
fn main() {let s1 = "中国-China";let s2 = String::from("中国-China");println!("{:?}", s1.to_uppercase()); // -> 中国-CHINAprintln!("{:?}", s2.to_uppercase()); // -> 中国-CHINA//请注意与 to_uppercase() 的不同let mut s3 = String::from("中国-China");s3.make_ascii_uppercase();println!("{:?}", s3); // -> 中国-CHINA}
全部转为小写
fn main() {let s1 = "中国-China";let s2 = String::from("中国-China");println!("{:?}", s1.to_lowercase()); // -> 中国-chinaprintln!("{:?}", s2.to_lowercase()); // -> 中国-china//请注意与 to_lowercase() 的不同let mut s3 = String::from("中国-China");s3.make_ascii_lowercase();println!("{:?}", s3); // -> 中国-china}
判断是不是ASCII字符串
fn main() {let s1 = "中国-China";let s2 = "China";assert_eq!(false, s1.is_ascii());assert_eq!(true, s2.is_ascii());}
判断指定位置是不是一个合法的 UTF-8 边界
fn main() {let s = String::from("中国-China");assert_eq!(true, s.is_char_boundary(0));assert_eq!(true, s.is_char_boundary(12));assert_eq!(false, s.is_char_boundary(2));assert_eq!(true, s.is_char_boundary(3));}
字符串替换
fn main() {let s = String::from("中国-China");println!("{:?}", s.replace("中国", "China"));}
字符串切割
fn main() {let s = String::from("中国-China");let result: Vec<&str> = s.split("-").collect();println!("{:?}", result); // -> ["中国", "China"]}

若有收获,就点个赞吧
0 人点赞
