ES 对 Luence 数据的封装说明
一个**Elasticsearch**的**Index**由多个**Shard**组成,每一个**Shard**都对应着**Luence**的一个**Index**,而**Luence**的**Index**又由多个**Segment**组成,每个Segment都是倒排索引的集合。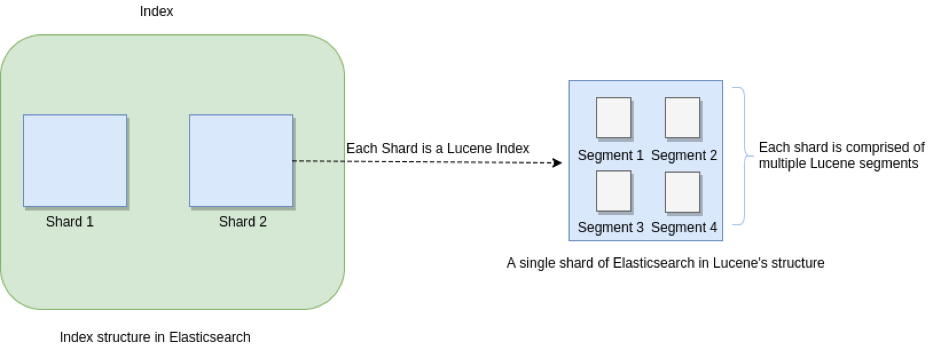
数据存储位置解剖
对内存空间的使用并非直来直往的结构,而是划分了挺多的层次,这对许多应用都是同理的。
点击查看【processon】Elasticsearch会涉及到这三个空间的读写。
- 如果对
PageCache有疑惑的可以参照《💨关于IO 之 PageCache》- 如果对 IO操作 有疑惑的可以参照《🎣《现代操作系统》 - IO篇之软件原理》
基本名词
概念
document,既然看到这篇文章了,那必然是对Elasticsearch有一定的了解了。它表示了一个新增的文档记录。translog,类似MySQL的binlog,用于记录每条操作的日志。segment file,在本文中segment file表示存储在磁盘空间里的segment;segment是存储在内存空间的。commit point,记录当前哪些segment已经提交了
操作
refresh,Elasticsearch的操作,将数据从用户空间刷新到内核空间,即PageCache中flush,Elasticsearch的操作,将所有内存中的数据刷到磁盘中去fsync,系统调用,将内存数据写入到磁盘中
Elasticsearch写操作
当客户端发起 写文档 请求后:
- 文档处理后被存储到
Elastichsearch进程空间的Buffer中(在Buffer中的数据无法直接被搜索到) - 记录 写操作 到
translog中,这个translog是一直追加的。触发translog刷盘有几个操作:- 每隔 5s
fsync到磁盘里去 - 当内存中的
translog增长到一定体积时自动触发刷盘 translog每30分钟会执行一次flush
- 每隔 5s
- 当触发了
refresh操作时(?refresh=true的API、index.refresh_interval等操作会触发),会触发以下几个动作:- 将
Buffer的数据写入新的segment,这个segment的体积必然很小(就是tiny segment)存在于Page Cache中 - 清空
buffer - 这个时候
segment虽然还没刷盘,但是已经可以被搜索到了
- 将
- 当触发了
flush操作时(?flush的API、每隔30分钟自动flush等操作会触发),会触发以下几个动作:- 清空
buffer,将buffer中的数据放到一个新的tiny segment存入Page Cache中 - 将
Page Cache中的数据全都刷盘 - 记录到
commit log中 - 删除硬盘上的
translog,并重新开始新的一轮translog
- 清空
总结几个关键要素,document被PUT进来后,首先会被存放在 Buffer 和 translog 中;当执行 refresh 操作时, document 就会被追加到一个新建的 tiny segment (同期的其他document也会被加入进来),然后存储在Page Cache中;当发生 flush 操作时,所有 Page Cache 中的 segment 都会刷新到磁盘里去,并记录下commit point,最后清空硬盘上原来的 translog 并开始一轮新的translog 。
translog 的作用,每次操作都得记录到translog中,translog每隔5秒刷盘一次(刷盘时并不清空translog),当translog体积达到一定程度(或者已经30分钟没有
flush了),则执行flush操作,将目前所有的数据都持久化,然后删除旧的translog,使用新的translog。当发生了异常要重启elasticsearch时,elasticsearch会去取磁盘上的translog和磁盘上的commitpoint进行比较,笔者猜测里面会有个ID,用来判断谁大谁小的问题。如果translog > commitpoint,那么回放translog,把数据持久化到segment中;如果translog == commitpoint,那么相安无事,正常启动(但其实有可能丢了5秒的数据了);如果translog < commitpoint,应该会报异常,这个不是很确定。
Elasticsearch删除与更新操作
在Elasticsearch中所有的段只要被持久化了就不支持在原文档基础上的更新 或 删除。
当发生了 更新 或者 删除 时,则在.del文件里记录下这个document(逻辑删除),虽然 ES 执行查询时依然会查询到这些(被删除)的记录,但是返回结果时会在 **.del**文件中过滤。
针对更新的文档来说,新的文档会被加入到新的段中,所以查询时,新的、老的都会被查询到,但是返回结果时会在
.del文件中过滤,最终只会返回新的document
每个commit point里都会包含上.del信息,然而 物理删除数据 并不发生在commit point的更新上。而是发生在段合并中。
Elasticsearch段合并
首先为什么会有段合并?原因有以下几个:
- 每次
refresh都会产生新的segment,即tiny segment - 在
refresh频繁的情况下,tiny segment的数量会在短时间内暴增 - 每个
tiny segment都会占用一个文件句柄、部分内存以及CPU时间片 - 每次查询都得轮流检查每个
segment,所以段越多,查询的越慢
那么Elasticsearch则通过在后台进行 段合并技术 来解决以上几个问题,段合并很容易理解——合并进程选择几个大小相似的segment(可以部分在内存中,部分在磁盘上),然后在后台合并为更大的segment(不影响新增和搜索)。示意图如下所示:
合并过程中不会把 被删除的文档、被更新的文档的旧版本 合并到新的大段中。
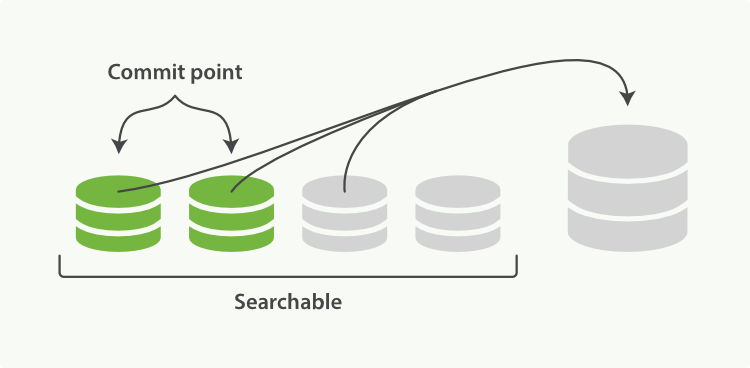
《两个提交了的段和一个未提交的段正在被合并到一个更大的段》
一旦合并结束,就会把新的段flush到磁盘中,然后更新commit point,即 移除旧的被合并的段 并 写入新的段 到commit point中。随后打开新的段用于搜索,老的段被删除。示意图如下所示: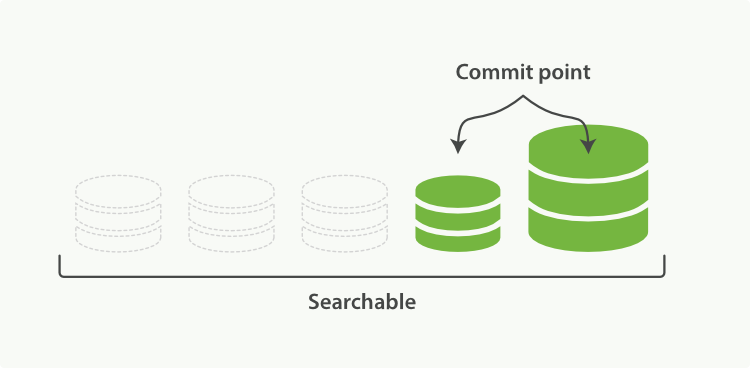
《一旦合并结束,老的段被删除》
注意,合并操作也是很费资源的,需要考虑一些优化操作。本篇主要分析原理,具体的优化过程往后学到了再列出来。
参考资料
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/dynamic-indices.html
- https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/translog.html
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/indexing-performance.html#segments-and-merging
- https://www.elastic.co/guide/cn/elasticsearch/guide/current/merge-process.html#merge-process
- https://elasticsearch.cn/question/3724
- https://xie.infoq.cn/article/2f8732411ea2f8d10cba85b78
- https://www.cnblogs.com/wcgstudy/p/11449000.html
- https://www.jianshu.com/p/3b68f351bdc7

若有收获,就点个赞吧
0 人点赞
