1 简介
双向链接
2022/6/24周五和@王晓阳 交流中,了解到logseq、obsidian等双向链接笔记的思想:一种双链笔记比较主要的应用,是可以流水账式地写日记,只要分好层次关系,打好tag,后续通过tag的关联,可以自己进行不同事项的汇总。一方面数据收集阶段符合人的思维过程,先有具体序列式地生成发散的信息。另一方面又能在后续检索笔记中,打破信息孤岛,能将特定关键词的信息进行关联提取、归纳。
流水账式地记录:
通过反向链接,可以找到跟”康明”有关的所有笔记: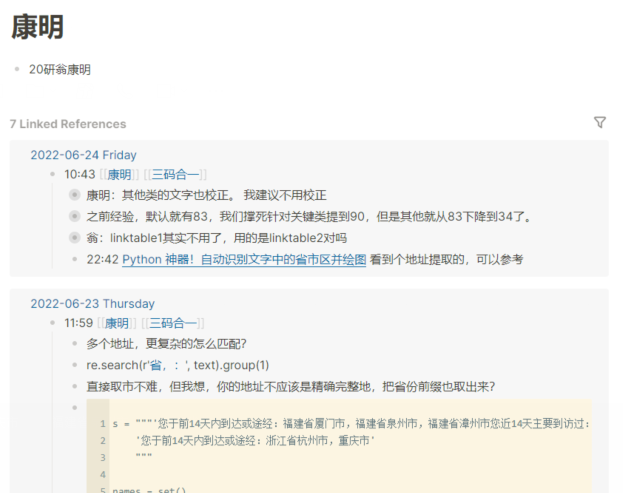
现有笔记软件不足
试用了两个软件,个人感觉
- logseq颜值更高,双链展示效果相比ob更好,能自动展示父级结点
- 但是子结点顺序可能会错乱
- ob排版更灵活,我喜欢排版灵活的
- 但是无法自动显示父结点层次关系
- 另外
- 我想排版更加灵活到图片、表格、代码也能缩进展示
- 以及图片、附件等资源还是想内嵌到一个完整的笔记页面中,不太喜欢md这种文字图片分离的模式
于是就想给我经常使用的OneNote,做一套扩展功能,从而也能实现双链笔记中一些基础功能效果。
顺便,OneNote的搜索功能非常垃圾,正好把这个问题一起解决了~~
自己扩展工具的安装
- 笔者OneNote2016测试可用,OneNote2013、2010应该也能用,其他版本不确定。
- python版本≥3.8
- pip install pyxllib>=0.2.41
- v0.2.38 基本功能
- v0.2.40 做了加速,和显示进度条。sever服务。
- v0.2.41 超链接功能
- 如果使用 from pyxllib.file.onenotelib import onenote
- 报错:This COM object can not automate the makepy process - please run makepy manually for this object
- 可以照 varunsrin/one-py: Python Object Model and COM Interface Wrapper for OneNote 2013 文章末尾的方式操作
- 把 HKEY_CLASSES_ROOT\TypeLib{0EA692EE-BB50-4E3C-AEF0-356D91732725} 的 1.0 删掉
- 注:这个 KEY ID 大家电脑上都是一样的
2 功能
from pyxllib.file.onenotelib import onenote
目前只写了检索关键词,并展示树形结构的功能。
检索(关键词)
展示格式:纯文本、网页富文本
# 可以用[x]直接一层层引用:笔记本、分区组、分区、Page。# 如果遇到 名称重复 情况,也可以用数字下标引用,下标从0开始编号res = onenote['核心']['2022ch4']['w220620: logseq'].search('康明')print(res)# 更新及获得索引副本:0.14秒,内容检索:0.00秒,匹配条目数:15,内容大小:978 bytes### [Table]# 3、晚上和康明彭琪去吃芒果蛋糕、biangbiang面。# 2、中午康明多地址匹配# 5、和康明讨论三码合一相关配置# ......# 220626周日# 11:00 后勤# 17:30 吃完出门看到康明坐在那玩手机,我没叫他。
所有的笔记内容组合在一起,可以认为是一个树形结构。对下述五种情况,都会产生一个父结点:
- OneNote中:笔记本Notebook、分区组SectionGroup、分区Section、页面Page(一二三级页面也有层级)
- 每个Page中的多个Outline 文本框(如果该Page只有一个Outline,则省略该Outline结点)
- 文章中的标题:h1、h2、h3 …
- 正文里使用\t产生的缩进层级
- 表格、图片本身也会产生一个结点。但目前表格还无法处理内部更加精细的层次结构。
可以设置return_mode=’html’,获得html描述,再用浏览器打开,就能看到正文中超链接、高亮等格式:
res = onenote['核心']['2022ch4']['w220620: logseq'].search('康明', return_mode='html')# 1 普通展示方法with open('test.html', 'w') as f:f.write(res)# 打开test.html可以看到内容# 2 使用我库里的接口,这个需要chrome配置到环境变量的路径中from pyxllib.xl import browserbrowser.html(res)

默认的html展示格式,在复制的时候,会失去缩进格式,所以如果要复制的保留缩进,需要用空格来实现缩进,这样展示效果虽然差一点,但可以复制到语雀等其他笔记中:
res = onenote['核心']['2022ch4']['w220620: logseq'].search('康明', return_mode='html', padding_mode=1)
我没有做关键词的高亮,因为如果涉及正则、自定义规则很不好做。
如果需要高亮显示,直接用chrome浏览器的搜索功能搜索下,就会高亮显示了。
支持对分区、分区组、笔记本直接进行全文检索
不过使用这个功能时,要注意如果内容量特别大,速度会很慢!最好自己从小范围慢慢测试到大范围里检索,对耗时有个预估。
onenote['核心']['2022ch4'].search('康明') # 检索分区:2022ch4
onenote['核心']['2020'].search('康明') # 检索分区组:2020
onenote['核心'].search('康明') # 检索笔记本:核心
一个页面,因为还要初始化等一些操作,大概要 1秒钟
22M的一个分区,我测试需要 7秒钟
定制展示内容
默认对找到的结点,会展示其直接子结点的内容。如果想修改展示的深度,可以修改child_depth参数:
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', child_depth=0) # 不展示子结点(默认值)
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', child_depth=2) # 展示两层子结点
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', child_depth=-1) # 展示所有子结点
# 减小缩进层级,原父级结点位置会用空行代替而不是删除
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', dedent=1) # 不显示root根节点(默认值)
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', dedent=0) # 不减小缩进,root根节为第1级
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', dedent=-1) # 可以用负值,相当于加缩进
onenote['核心']['2022ch4']['w220620: logseq'].search('康明', dedent=3) # 减少3层父结点展示
定制检索规则
# 1 任何结点的纯文本或富文本中,出现了指定关键词
onenote['核心']['2022ch4']['w220620: logseq'].search('康明')
onenote['核心']['2022ch4']['w220620: logseq'].search('[[康明]]')
# 2 正则匹配:(纯文本或富文本中)任何有出现数字的结点
import re
onenote['核心']['2022ch4']['w220620: logseq'].search(re.compile(r'\d+'))
# 3 自定义函数
def check_node(node):
# node 是结点对象,可以获得其父结点等很多信息
# node.name 存储了结点的纯文本内容
# node._html_content存储了其富文本内容,但这个字段有些node可能会不存在
# 出现了'三码合一',但没有出现'康明'的结点
return '三码合一' in node.name and '康明' not in node.name
onenote['核心']['2022ch4']['w220620: logseq'].search(check_node)
全文检索
目前对大批量数据的检索有一定的优化策略,具体原理细节可以参考第3节“检索加速”。
这里只先简单讲下基本用法:
# 在全OneNote笔记里检索"康明",其他参数功能跟前文一样。
# 但因为首次使用初始化可能太慢,建议使用print_mode=1,打开进度条,查看初始化解析进度。
# 首次使用初始化可能要半个小时,但后续就很快了,因为有了缓存,大概半分钟就够。
onenote.search('康明', print_mode=1)
# 如果自己研究底层代码,修改了page页面结构化解析规则,则需要手动指定reparse重解析,大概需要3分钟。
onenote.search('康明', print_mode=1, reparse=True)
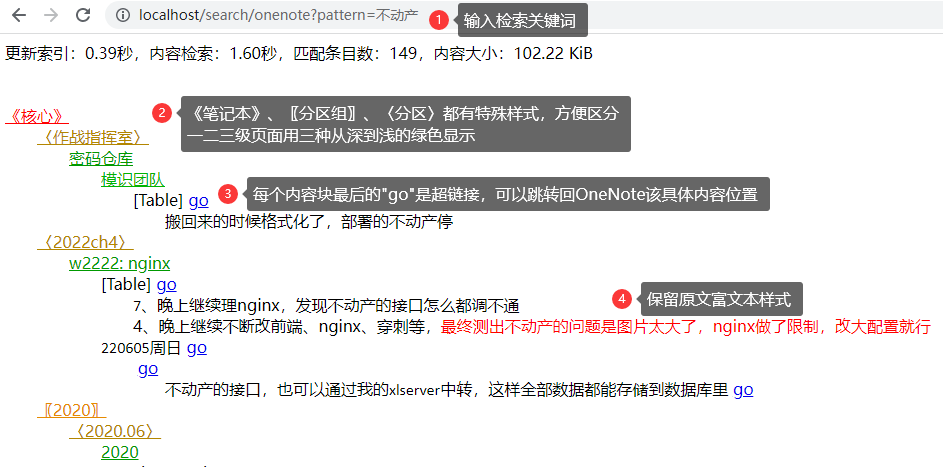
# 在命令行,执行下述代码,会启动一个http服务:http://localhost/search/onenote?pattern=输入关键词
# 可以在浏览器直接检索,每次大概1秒钟
python -m pyxllib.file.onenotelib start_server
# 如果有正常编辑的分区(组)等笔记,可以指定edits参数,让每次search的时候会实时更新获取最新页面内容
python -m pyxllib.file.onenotelib start_server --edits="核心/2022ch4,核心/快速笔记"
# 其他
# --root 或者第1个位置参数,可以修改检索根目录,比如 --root 核心,只在[核心]笔记本全文检索
# --port 80 修改默认端口号
除了最基本的用法:http://localhost/search/onenote?pattern=输入关键词
可以使用url的规则,用&配合不同参数效果:http://localhost/search/onenote?pattern=输入关键词&dedent=0
支持的参数跟前文介绍的类似。
跳转回原始页面修改内容
TODO 知识图谱
我的检索功能并不严格要求要用”[[ ]]”来标记关键词tag。
所以在做知识图谱的时候,需要获取所有内容,进行”分词”,然后进行全量关键词的关系计算。
最后实际展示哪些关键词,可以通过频率、配置文件等策略进行优化。
3 技术实现原理
使用win32com,可以获得OneNote的接口,从而可以获得其Page内容,或修改Page内容。
OneNote的Page内容是用xml描述的,可以使用bs4的BeautifulSoup进行结构解析。
解析到的内容,可以用anytree来存储树形结构。
使用anytree能很方便地进行各种树形结构的逻辑处理。
检索加速
- 首次使用,每个Page页面都要通过OneNote获取xml文本信息。存在的问题和解决方案
- 速度很慢
- 【备份已读取的xml文件】笔者4G的笔记,500M纯文本,全量初始化需要30分钟。所以默认在临时目录里缓存了xml文本内容,只要检查页面最近没有更新,可以直接用备份的文件数据。
- 我的临时目录在:C:\Users\chen\AppData\Local\Temp\OneNote\SearchCache
- 【显示进度条】在主线程读取数据之外,有个独立的子线程会监控已解析的页面数,展示解析进度。
- 【备份已读取的xml文件】笔者4G的笔记,500M纯文本,全量初始化需要30分钟。所以默认在临时目录里缓存了xml文本内容,只要检查页面最近没有更新,可以直接用备份的文件数据。
- 另有个别页面可能会存在读取不了的情况
- 【问题描述】笔者遇到有一页有插入Office公式的,读取的时候,OneNote软件直接卡死了。因为无法事先判断页面是否可读取,软件卡死后也没法在py干涉onenote的操作。
- 【使用Timout机制报错】所以最多只能python里设一个计时器子线程,当一个页面读取30秒(默认值,可改)还未成功,则子线程发送signal信号给主线程,直接强制中断。并报出读取失败的页面地址。
- 使用onenote.timeout_seconds = 30,可以修改超时时限。其实大部分页面5秒内就足够了,但不排除有的页面特别大,需要较充裕的等待时间。
- 使用这么绕圈圈的方法,一方面是windows上没有signal.alarm信号。另一方面这个涉及到win32com,无法放置在子线程里执行onenote。
- 速度很慢
- 解析xml为结构化数据还是要一些时间,笔者的笔记全量解析仍需要3分钟
- 【缓存结构化数据】将解析结果也预存到文件中 page_parsed_cache_file.pkl
- 注意anytree的Node需要序列化为dict来保存,不能直接用pickle。具体实现还有不少细节,这里不展开。
- 因为解析算法可能会更新,默认可以开启这个缓存策略,但search也要有一个参数接口reparse=True,支持强制重置解析
- 使用该机制,初始化时间可以提高到20秒。这样一次全量检索,时间就压缩到30秒以内了。
- 【缓存结构化数据】将解析结果也预存到文件中 page_parsed_cache_file.pkl
- 每次检索都要初始化、运行代码很麻烦
- python -m pyxllib.file.onenotelib start_server 可以直接开http服务
- 在本地 http://localhost/search/onenote?pattern=输入关键词 可以实时查询,基本上可以1秒内出结果
- 大部分笔记其实都是冷数据,真正频繁在修改的可能就那么几个分区
- search、server支持设置edits参数,指定相对地址,正在编辑修改的笔记:edits=[‘杂项’, ‘CF’, ‘吃土乡/大家的幻想乡’]
- 底层_search算法在检索时,有个use_node_cache的参数,对一般数据为True,不重复更新。只有edits设置的笔记,每次都会重新更新。另外注意,use_node_cache和reparse虽然有一定相关性,但配置上是独立的两个参数功能。
- server开启示例:python -m pyxllib.file.onenotelib start_server —edits=”核心/2022ch4”,这样每次search,都会先更新获取最新的「2022ch4」分区内容,能检索到最新的结果。这样每次检索虽然时间会多花一些,但实效性效果更好。
- python -m pyxllib.file.onenotelib start_server 可以直接开http服务
4 TODO
[ ] 网页展示使用支持层次折叠、展开的控件
[ ] 将当前检索功能扩展到OneNote以外的笔记内容
可以通过解析其他笔记格式实现
也可以把其他笔记变成OneNote来中转实现
由于数据较大,在实现后,可以把全量数据库存在服务器里
- 独立于onenote之外的,通用的全文检索功能,数据统一存储在PG数据库中

若有收获,就点个赞吧
0 人点赞
