1 还有很多call相关功能要执行
错误示范:
module的call,还有这么多东西,然后才绕到forward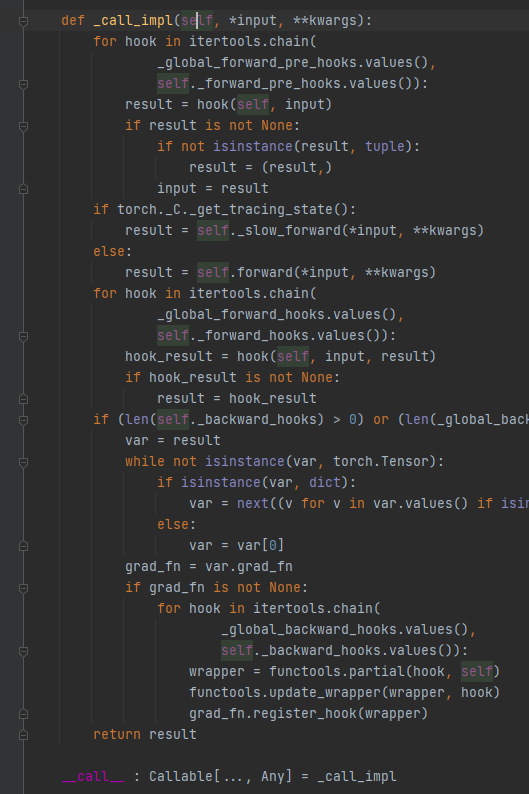
2 具体执行了什么
看源码,其嵌入了hook,实际执行顺序是:
- call -> _call_impl(self, input, *kwargs)
- forward_pre_hook,先执行全局的hook,再执行模块自己的hook
- from torch.nn.modules.module import register_module_forward_pre_hook 注册的功能
- hook(module, input) -> None or modified input
- 注册函数都是返回一个可以使用with上下文,可以remove移除hook的句柄,后面不再累述
- nn.Module.register_forward_pre_hook
- 相当于执行了 input = hook(self, input)
- 当然这里比较智能,如果返回值是None,则不会替换inpu。torch的hook都是这样的处理模式。
- 因为input本来就是打包的,非tuple对象会强制转为tuple存储回input。其实hook里都按打包的input处理就好了。
- from torch.nn.modules.module import register_module_forward_pre_hook 注册的功能
- _get_tracing_state模式?
- 执行_slow_forward,其内部最终也是会执行 forward 的
- 否则执行 forward
- forward_hook,同pre_hook,先 register_module_forward_hook,再register_forward_hook
- result = hook(self, input, result)
- backward_hooks,这个感觉不太用的到。。。
- grad_output = hook(module, grad_input, grad_output)
- result.grad_fn会绑定这个hook
2a是全局所有的module,2b是指定实例化的某个model。
注意2b是指定对象,只对实例化的某个model有用,无法针对某一类module处理。
如果确有针对某一类module的需求,可以使用全局的,配合条件判断isinstance(module, nn.Linear)使用。
3 hook的应用举例:查看每步feature_size
全局,给所有module添加hook
import numpy as npimport torchfrom torch import nnfrom torch.nn.modules.module import register_module_forward_pre_hookfrom pyxllib.xl import shorten # 将文本折叠为一行的函数def build_dataloader(n):""" 生成n个数据样本,每个样本是 5个 [0, 6) 的整数按照数值和分成两类, 10<sum(x)<20是1类,其他是0类"""data = np.random.randint(0, 6, [n, 5])dataset = [(torch.FloatTensor(x), int(10 < sum(x) < 20)) for x in data]return torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)class NumNet(nn.Module):def __init__(self):super().__init__()self.classifier = nn.Sequential(nn.Linear(5, 10),nn.ReLU(),nn.Linear(10, 5),nn.ReLU(),nn.Linear(5, 2),nn.ReLU(),)def forward(self, batched_inputs):x, y = batched_inputslogits = self.classifier(x)loss = nn.functional.cross_entropy(logits, y)return lossdef print_feature_size(module, inputs):inputdata = inputs[0] # 有很多位置参数会传给module,inputs[0]才是这里原来的batched_inputsif isinstance(inputdata, (list, tuple)):x, y = inputdata # NumNet传入的batched_inputselse:x = inputdata # 传给Linear、ReLU等forward的时候只有xprint(x.shape, '-->', shorten(module))if __name__ == '__main__':register_module_forward_pre_hook(print_feature_size)dataloader = build_dataloader(20) # 生成20个数据,batch_size=16,跑两轮model = NumNet()for batched_inputs in dataloader:model(batched_inputs)print('= ' * 20)# torch.Size([16, 5]) --> NumNet( (classifier): Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, ou...# torch.Size([16, 5]) --> Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, out_features=2, bias=Tru...# torch.Size([16, 5]) --> Linear(in_features=5, out_features=10, bias=True)# torch.Size([16, 10]) --> ReLU()# torch.Size([16, 10]) --> Linear(in_features=10, out_features=5, bias=True)# torch.Size([16, 5]) --> ReLU()# torch.Size([16, 5]) --> Linear(in_features=5, out_features=2, bias=True)# torch.Size([16, 2]) --> ReLU()# = = = = = = = = = = = = = = = = = = = =# torch.Size([4, 5]) --> NumNet( (classifier): Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, ou...# torch.Size([4, 5]) --> Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, out_features=2, bias=Tru...# torch.Size([4, 5]) --> Linear(in_features=5, out_features=10, bias=True)# torch.Size([4, 10]) --> ReLU()# torch.Size([4, 10]) --> Linear(in_features=10, out_features=5, bias=True)# torch.Size([4, 5]) --> ReLU()# torch.Size([4, 5]) --> Linear(in_features=5, out_features=2, bias=True)# torch.Size([4, 2]) --> ReLU()# = = = = = = = = = = = = = = = = = = = =
这是检查forward前data的尺寸是多大,然后丢入该层module的;
如果要检查forward后尺寸多大,可以使用:
from torch.nn.modules.module import register_module_forward_hook。
仅给指定实例化的某个model添加hook
前面不变,main改成:
if __name__ == '__main__':# register_module_forward_pre_hook(print_feature_size)dataloader = build_dataloader(20) # 生成20个数据,batch_size=16,跑两轮model = NumNet()model.register_forward_pre_hook(print_feature_size)for batched_inputs in dataloader:model(batched_inputs)print('= ' * 20)# torch.Size([16, 5]) --> NumNet( (classifier): Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, ou...# = = = = = = = = = = = = = = = = = = = =# torch.Size([4, 5]) --> NumNet( (classifier): Sequential( (0): Linear(in_features=5, out_features=10, bias=True) (1): ReLU() (2): Linear(in_features=10, out_features=5, bias=True) (3): ReLU() (4): Linear(in_features=5, ou...# = = = = = = = = = = = = = = = = = = = =

若有收获,就点个赞吧
0 人点赞
