在使用Flink做数据处理时,一个典型的场景是对两个流的数据进行关联。Flink DataStream API中,相关方法有3个:join, coGroup和intervalJoin。
Join和CoGroup
调用示例
stream.join(otherStream).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>)stream.coGroup(otherStream).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<CoGroupFunction>)
介绍
这两个都属于WindowJoin,join为在窗口内做inner join,而coGroup为在窗口内做outer join。
以 join为例,根据指定Window类型的不同,能达到以下效果:
| Tumbling Window Join | 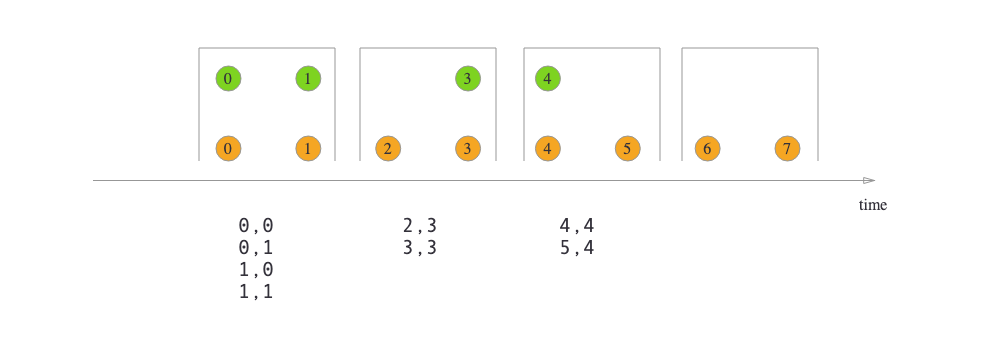 |
|---|---|
| Sliding Window Join |  |
| Session Window Join |  |
join后元素的时间戳为该窗口的最大时间戳。
代码
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {/*** The join method, called once per joined pair of elements.*/OUT join(IN1 first, IN2 second) throws Exception;}public interface CoGroupFunction<IN1, IN2, O> extends Function, Serializable {/*** This method must be implemented to provide a user implementation of a* coGroup. It is called for each pair of element groups where the elements share the* same key.*/void coGroup(Iterable<IN1> first, Iterable<IN2> second, Collector<O> out) throws Exception;}
- JoinFunction作用于一个窗口内,参数为两个流中按key匹配上的每一对元素,为innerjoin
- CoGroupFunction的参数为一个窗口内,两个流中key相同的所有元素,因此即可实现innerjoin,又可实现outerjoin。
先来看一下join的代码
stream.join(otherStream) -> JoinedStreams.where(<KeySelector>) -> JoinedStreams.Where.equalTo(<KeySelector>) -> JoinedStreams.EqualTo.window(<WindowAssigner>) -> JoinedStreams.WithWindow.apply(<JoinFunction/FlatJoinFunction>)
- 核心代码在JoinedStreams.WithWindow中,别的都是简单的check和wrap
- Join被转换成CoGroup进行处理
/*** A streaming join operation is evaluated over elements in a window.** <p>Note: Right now, the join is being evaluated in memory so you need to ensure that the number* of elements per key does not get too high. Otherwise the JVM might crash.*/@Publicpublic class JoinedStreams<T1, T2> {@Publicpublic static class WithWindow<T1, T2, KEY, W extends Window> {private final DataStream<T1> input1;private final DataStream<T2> input2;private CoGroupedStreams.WithWindow<T1, T2, KEY, W> coGroupedWindowedStream;public <T> DataStream<T> apply(JoinFunction<T1, T2, T> function, TypeInformation<T> resultType) {// clean the closurefunction = input1.getExecutionEnvironment().clean(function);// Join被转换成CoGroup操作coGroupedWindowedStream = input1.coGroup(input2).where(keySelector1).equalTo(keySelector2).window(windowAssigner).trigger(trigger).evictor(evictor).allowedLateness(allowedLateness);// 用户传入的JoinFunction被封装成JoinCoGroupFunctionreturn coGroupedWindowedStream.apply(new JoinCoGroupFunction<>(function), resultType);}}}
/*** A streaming join operation is evaluated over elements in a window.** <p>Note: Right now, the join is being evaluated in memory so you need to ensure that the number* of elements per key does not get too high. Otherwise the JVM might crash.*/@Publicpublic class JoinedStreams<T1, T2> {/*** CoGroup function that does a nested-loop join to get the join result.*/private static class JoinCoGroupFunction<T1, T2, T>extends WrappingFunction<JoinFunction<T1, T2, T>>implements CoGroupFunction<T1, T2, T> {public JoinCoGroupFunction(JoinFunction<T1, T2, T> wrappedFunction) {super(wrappedFunction);}@Overridepublic void coGroup(Iterable<T1> first, Iterable<T2> second, Collector<T> out) throws Exception {for (T1 val1: first) {for (T2 val2: second) {out.collect(wrappedFunction.join(val1, val2));}}}}}
再看一下coGroup的代码:
Flink先将两个流union成一个流(元素类型为TaggedUnion
@Internalpublic static class TaggedUnion<T1, T2> {private final T1 one;private final T2 two;}
@Publicpublic class CoGroupedStreams<T1, T2> {@Publicpublic static class WithWindow<T1, T2, KEY, W extends Window> {private WindowedStream<TaggedUnion<T1, T2>, KEY, W> windowedStream;public <T> DataStream<T> apply(CoGroupFunction<T1, T2, T> function, TypeInformation<T> resultType) {//clean the closurefunction = input1.getExecutionEnvironment().clean(function);UnionTypeInfo<T1, T2> unionType = new UnionTypeInfo<>(input1.getType(), input2.getType());UnionKeySelector<T1, T2, KEY> unionKeySelector = new UnionKeySelector<>(keySelector1, keySelector2);// 给两个流分别加上标识DataStream<TaggedUnion<T1, T2>> taggedInput1 = input1.map(new Input1Tagger<T1, T2>()) // 生成TaggedUnion(one, null).setParallelism(input1.getParallelism()).returns(unionType);DataStream<TaggedUnion<T1, T2>> taggedInput2 = input2.map(new Input2Tagger<T1, T2>()) // 生成TaggedUnion(null, two).setParallelism(input2.getParallelism()).returns(unionType);// 两个流合并成一个流DataStream<TaggedUnion<T1, T2>> unionStream = taggedInput1.union(taggedInput2);// we explicitly create the keyed stream to manually pass the key type information inwindowedStream =new KeyedStream<TaggedUnion<T1, T2>, KEY>(unionStream, unionKeySelector, keyType).window(windowAssigner);if (trigger != null) {windowedStream.trigger(trigger);}if (evictor != null) {windowedStream.evictor(evictor);}if (allowedLateness != null) {windowedStream.allowedLateness(allowedLateness);}return windowedStream.apply(new CoGroupWindowFunction<T1, T2, T, KEY, W>(function), resultType);}}
window被触发时,将其中的元素分开成左边一组和右边一组,再交给CoGroupFunction处理。
@Publicpublic class CoGroupedStreams<T1, T2> {private static class CoGroupWindowFunction<T1, T2, T, KEY, W extends Window>extends WrappingFunction<CoGroupFunction<T1, T2, T>>implements WindowFunction<TaggedUnion<T1, T2>, T, KEY, W> {public CoGroupWindowFunction(CoGroupFunction<T1, T2, T> userFunction) {super(userFunction);}@Overridepublic void apply(KEY key,W window,Iterable<TaggedUnion<T1, T2>> values,Collector<T> out) throws Exception {List<T1> oneValues = new ArrayList<>();List<T2> twoValues = new ArrayList<>();// 窗口内的所有元素按左流和右流拆分开for (TaggedUnion<T1, T2> val: values) {if (val.isOne()) {oneValues.add(val.getOne());} else {twoValues.add(val.getTwo());}}wrappedFunction.coGroup(oneValues, twoValues, out);}}}
IntervalJoin
调用示例
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;import org.apache.flink.streaming.api.windowing.time.Time;...val orangeStream: DataStream[Integer] = ...val greenStream: DataStream[Integer] = ...orangeStream.keyBy(elem => /* select key */).intervalJoin(greenStream.keyBy(elem => /* select key */)).between(Time.milliseconds(-2), Time.milliseconds(1)).process(new ProcessJoinFunction[Integer, Integer, String] {override def processElement(left: Integer, right: Integer, ctx: ProcessJoinFunction[Integer, Integer, String]#Context, out: Collector[String]): Unit = {out.collect(left + "," + right);}});});
介绍
- Window Join和CoGroup要求关联上的两个消息必须在同一个窗口内
若想根据两个流中消息的相对时间来匹配,需要用Interval Join
orangeElem.ts`` + ``lowerBound``<= ``greenElem.ts``<= ``orangeElem.ts`` + upperBoundJoin后的元素的时间戳为两个消息时间戳中更大的一个

代码
Interval Join是基于ConnectedStreams实现的
@PublicEvolvingpublic static class IntervalJoined<IN1, IN2, KEY> {@PublicEvolvingpublic <OUT> SingleOutputStreamOperator<OUT> process(ProcessJoinFunction<IN1, IN2, OUT> processJoinFunction,TypeInformation<OUT> outputType) {Preconditions.checkNotNull(processJoinFunction);Preconditions.checkNotNull(outputType);final ProcessJoinFunction<IN1, IN2, OUT> cleanedUdf = left.getExecutionEnvironment().clean(processJoinFunction);final IntervalJoinOperator<KEY, IN1, IN2, OUT> operator =new IntervalJoinOperator<>(lowerBound,upperBound,lowerBoundInclusive,upperBoundInclusive,left.getType().createSerializer(left.getExecutionConfig()),right.getType().createSerializer(right.getExecutionConfig()),cleanedUdf);return left.connect(right).keyBy(keySelector1, keySelector2).transform("Interval Join", outputType, operator);}}
- ConnectedStreams可视为两个流的union,不要求两个流的数据类型一样
- 通过流之间共享状态,可以在双流上实现一些复杂操作。
@Publicpublic class ConnectedStreams<IN1, IN2> {protected final DataStream<IN1> inputStream1;protected final DataStream<IN2> inputStream2;public ConnectedStreams<IN1, IN2> keyBy(KeySelector<IN1, ?> keySelector1, KeySelector<IN2, ?> keySelector2) {return new ConnectedStreams<>(environment, inputStream1.keyBy(keySelector1),inputStream2.keyBy(keySelector2));}public <R> SingleOutputStreamOperator<R> map(CoMapFunction<IN1, IN2, R> coMapper) {TypeInformation<R> outTypeInfo = TypeExtractor.getBinaryOperatorReturnType(coMapper,CoMapFunction.class,0,1,2,TypeExtractor.NO_INDEX,getType1(),getType2(),Utils.getCallLocationName(),true);return map(coMapper, outTypeInfo);}}@Publicpublic interface CoMapFunction<IN1, IN2, OUT> extends Function, Serializable {OUT map1(IN1 value) throws Exception;OUT map2(IN2 value) throws Exception;}
在IntervalJoinOprater中,用两个MapState(leftBuffer, rightBuffer)分别保存两个流中到达的消息,map的key是消息的时间戳。
@Internalpublic class IntervalJoinOperator<K, T1, T2, OUT>extends AbstractUdfStreamOperator<OUT, ProcessJoinFunction<T1, T2, OUT>>implements TwoInputStreamOperator<T1, T2, OUT>, Triggerable<K, String> {private final long lowerBound;private final long upperBound;private transient MapState<Long, List<BufferEntry<T1>>> leftBuffer;private transient MapState<Long, List<BufferEntry<T2>>> rightBuffer;private transient InternalTimerService<String> internalTimerService;@Overridepublic void processElement1(StreamRecord<T1> record) throws Exception {processElement(record, leftBuffer, rightBuffer, lowerBound, upperBound, true);}@Overridepublic void processElement2(StreamRecord<T2> record) throws Exception {processElement(record, rightBuffer, leftBuffer, -upperBound, -lowerBound, false);}}
- 当左流的消息到达时,会将其加入leftBuffer中,然后到rightBuffer中找是否有符合时间范围的消息。如果有,匹配的元素就被传入用户自定义的ProcessJoinFunction中。反之亦然。
- join上的消息对的时间戳为两个消息中更大的一个。
- 为了避免两个state无限膨胀,每条消息会注册一个timer,在时间越过该消息的有效范围后,便将其移出state。
@Internalpublic class IntervalJoinOperator<K, T1, T2, OUT> {@SuppressWarnings("unchecked")private <THIS, OTHER> void processElement(final StreamRecord<THIS> record,final MapState<Long, List<IntervalJoinOperator.BufferEntry<THIS>>> ourBuffer,final MapState<Long, List<IntervalJoinOperator.BufferEntry<OTHER>>> otherBuffer,final long relativeLowerBound,final long relativeUpperBound,final boolean isLeft) throws Exception {final THIS ourValue = record.getValue();final long ourTimestamp = record.getTimestamp();if (ourTimestamp == Long.MIN_VALUE) {throw new FlinkException("Long.MIN_VALUE timestamp: Elements used in " +"interval stream joins need to have timestamps meaningful timestamps.");}if (isLate(ourTimestamp)) { // 若消息时间戳小于internalTimerService.currentWatermark(),丢弃return;}// 将消息加入状态addToBuffer(ourBuffer, ourValue, ourTimestamp);// 从另一个数据流的状态中查找匹配的消息for (Map.Entry<Long, List<BufferEntry<OTHER>>> bucket: otherBuffer.entries()) {final long timestamp = bucket.getKey();if (timestamp < ourTimestamp + relativeLowerBound ||timestamp > ourTimestamp + relativeUpperBound) {continue;}for (BufferEntry<OTHER> entry: bucket.getValue()) {if (isLeft) {collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);} else {collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);}}}// 注册清理消息的timerlong cleanupTime = (relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;if (isLeft) {internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);} else {internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);}}}

若有收获,就点个赞吧
0 人点赞
