一、背景
UK8S的三大插件:CNI、CloudProvider、CSI都依赖UCloud APIs,在实际运营过程中,发现UCloud APIs经常出现调用失败等问题,影响集群的正常运行,甚至导致客户业务受影响,如CloudProvider调用ULB APIs超时导致LoadBalancer Service依赖的ULB被重建,业务接入层IP全部变更。
目前K8S的监控主要可分为集群监控、资源监控、性能监控三种,其中集群监控和资源监控由于其实现机制,其实是存在一定的延时,如一个Pod因为资源不足一直处于Pending状态,一般需要几分钟时间才能触发告警,但K8S的events其实具备实时的资源状态及状态装换的信息。
从这个角度看,我们可以将kube events作为一类单独的监控,即事件监控。
二、事件类型
在UK8S中,主要有两类事件:
1、因K8S资源变更而产生的事件,有normal和warning两种类型,可直接从kube events中获取;
2、UK8S插件CNI、CloudProvider、CSI、ClusterAutoScaler产生的日志信息(如重启),主要是retcode为0和非0两种类型。
三、方案概览
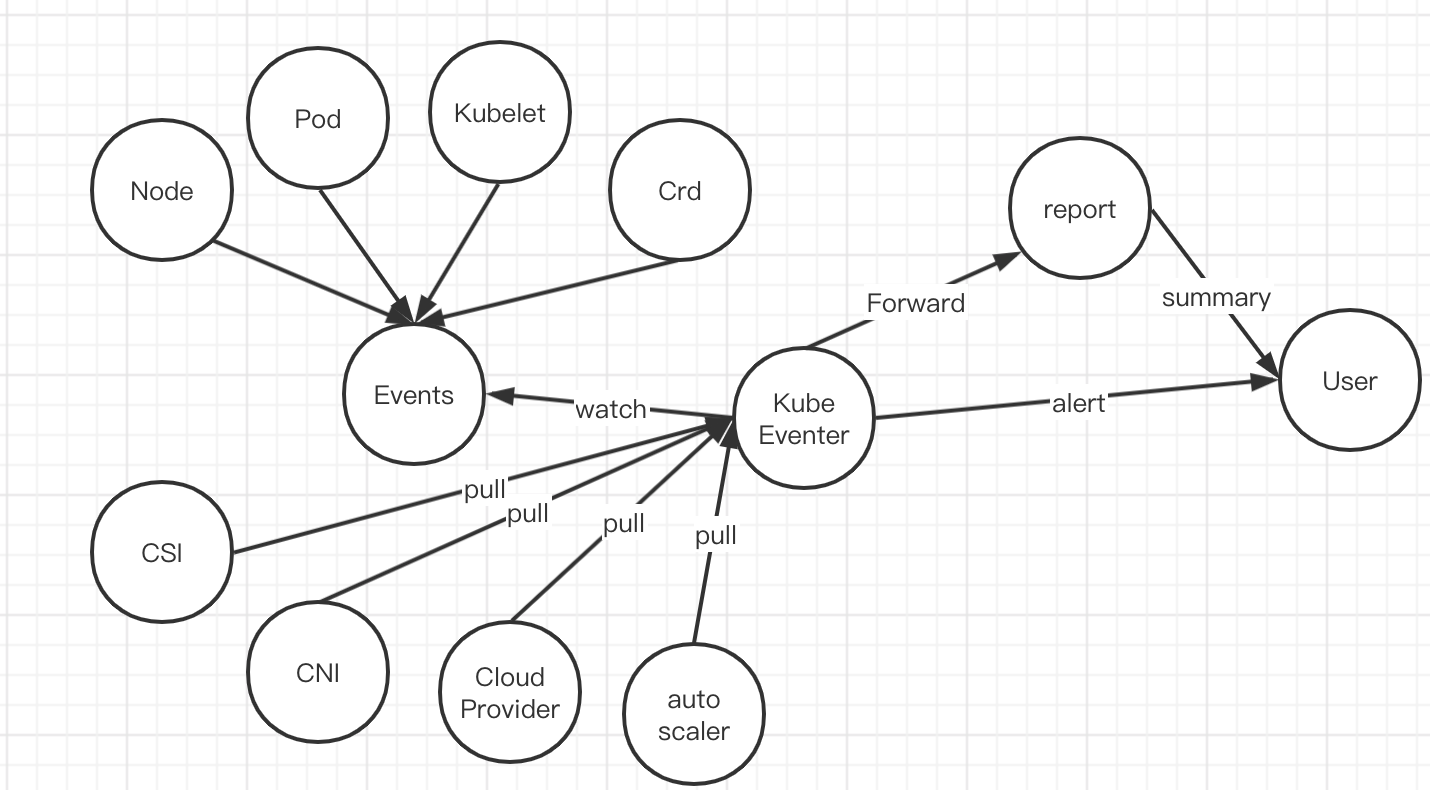
问题: CSI、CNI等的错误日志,在正常运行过程中,都会体现在Events里面,只有其重启等情况下,才会因业务实现去访问API,产生日志信息。因此eventer通过watch和pull产生的信息可能有重复。

若有收获,就点个赞吧
0 人点赞
