概述
本篇文章记录相关大数据组件安装过程。其中组件包含 Hadoop、Flink、Kafka、Zookeeper、Iceberg等。
虚拟机配置
从 镜像源 中下载 Centos镜像,这里是 Centos 7.0版本。规划每台虚拟机节点的 IP地址、磁盘容量大小、CPU和内存大小等资源。
| 主机名称 | IP 地址 | 磁盘容量 | CPU | 内存 |
|---|---|---|---|---|
| hadoop101 | 192.168.100.101 | 50GB | 1 | 3G |
| hadoop102 | 192.168.100.102 | 50GB | 1 | 3G |
| hadoop103 | 192.168.100.103 | 50GB | 1 | 3G |
使用 VMware 安装 Centos 操作系统
配置磁盘分区


配置Vmware网络
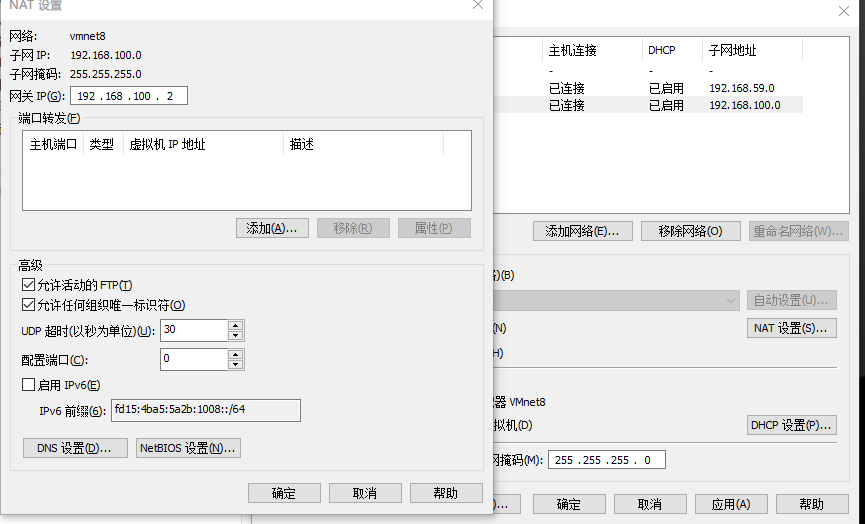


配置 Windows网络,选择 VMware8,点击属性:

主要配置 DNS 服务器和网关 IP。
配置 Centos7 网络:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改 BOOTPROTO为 static,然后添加以下参数配置:
IPADDR=192.168.10.100GATEWAY=192.168.10.2DNS1=192.168.10.2
修改 Linux 主机名称:
vim /etc/hostname
添加:
hadoop100
修改 hosts文件:
vim /etc/hosts
添加
192.168.100.100 hadoop100192.168.100.101 hadoop101192.168.100.102 hadoop102192.168.100.103 hadoop103192.168.100.104 hadoop104192.168.100.105 hadoop105192.168.100.106 hadoop106
重启 Linux。
验证:
hostname #输出 hadoop100curl www.baidu.com 可以正常访问互联网
修改本地 Windows``host映射,文件路径为 C:\Windows\System32\drivers\etc,添加以下内容:
192.168.10.100 hadoop100192.168.10.101 hadoop101192.168.10.102 hadoop102192.168.10.103 hadoop103192.168.10.104 hadoop104192.168.10.105 hadoop105192.168.10.106 hadoop106
安装必要软件
yum install -y vim epel-release net-tools lrzsz
关闭防火墙
systemctl stop firewalldsystemctl disable firewalld.service
克隆 Centos
- 关闭虚拟机。

克隆时选择
创建完整克隆。
按以下步骤修改克隆主机信息:
- 网络:
vim /etc/sysconfig/network-scripts/ifcfg-ens33,修改为自己的 IP 地址。 vim /etc/hostname:修改主机名称配置 JDK
```shell删除 OS 自带的 JDK,xargs 得到前面的参数,-n1 表示每次只传递一个参数,
rpm -e —nodeps 强制制裁软件
rpm -qa | grep -i java | xargs -n1 rpm -e —nodeps
安装 JDK17,使用 yum 默认安装路径为 /usr/lib/jvm,一般不使用这种方式安装
yum search jdk
yum install
去 [清华镜像源](https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/17/jdk/x64/linux/) 中下载 JDK 安装包,使用 `tar -zxvf <.tar.gz> -C <路径>`解压文件。<br />一般而言,我们通过查看 `/etc/profile`了解到,它会循环遍历 `/etc/profile.d`所有后缀以 `.sh`结尾的文件,然后令其全局生效。所以,为了不污染 `profile`文件,我们选择在 `profile.d`文件夹下新建以 `.sh`结尾的文件作为 `jdk`的环境变量配置脚本:```bash#JAVA_HOMEexport JAVA_HOME=/opt/module/jdk-17.0export PATH=$PATH:$JAVA_HOME/bin
编写集群分发脚本
scp命令基本语法如下:
scp -r <dir>/<filename> <user>@<host>:<dir>/<filename>#涉及文件权限的,使用 chown 命令sudo shown <>:<> -R <dir>#将JDK文件拷贝到hadoop102机器中scp -r jdk-17.0/ root@hadoop102:/opt/module/
rsync远程同步工具:rsync主要用于备份和镜像,具有速度快、避免复制相同内存和支持符号链接等优点。基本语法如下:
rsync -av <dir>/<filename> <user>@<host>:<dir>/<filename>
#!/bin/bashif [ $# -lt 1]thenecho Not enough argument!exit;fi# 遍历所有机器for host in hadoop101, hadoop102, hadoop103doecho ===== $host =====for file in $@doif [-e $file]thenpdir = $(cd -P $(dirname $file); pwd)fname = $(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
SSH 无密登录
ssh-keygen -t rsacd ~/.sshssh-copy-id <host>
配置 Hadoop
从 镜像源 中获取对应的 Hadoop版本,并配置环境变量:
#HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop-3.3.2export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
Hadoop 三种运行模式
- 本地模式:数据存储在系统磁盘中。
- 伪分布式:数据存储在
HDFS中。 - 完全分布式:数据存储在
HDFS中,且多台服务器同时工作。Hadoop 资源节点分配情况
| 类型 | hadoop101 | hadoop102 | hadoop103 | | —- | —- | —- | —- | | HDFS | NameNode
DateNode | DateNode | SecondaryNameNode
DateNode | | YARN | NodeManager | ResourceManager
NodeManager | NodeManager |
NameNode和SecondaryNameNode不能安装在同一台机器上,因为他们两者是备份关系。ResourceManager比较消耗内存,不要和NameNode和SecondaryNameNode安装在同一台机器上。
core-site.xml
集群配置详见 Hadoop Cluster Setup。配置文件在 /opt/module/hadoop-3.3.2/etc/hadoop路径下:
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop101:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.3.2/data</value></property></configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.namenode.http-address</name><value>hadoop101:9870</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop103:9868</value></property></configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop102</value></property></configuration>
启动 Hadoop 集群
配置 workers:
vi /opt/module/hadoop-3.3.2/etc/hadoop/workers
添加以内容:
hadoop101hadoop102hadoop103
如果首次启动 Hadoop 集群,需要在 NameNode节点进行格式化操作。
hdfs namenode -format
正常情况下,没有报任何异常,就表明 HDFS 初始化完成。
在 /opt/module/hadoop-3.3.2/sbin目录下执行:
./start-dfs.sh
由于缺少用户定义,会造成该脚本启动报错: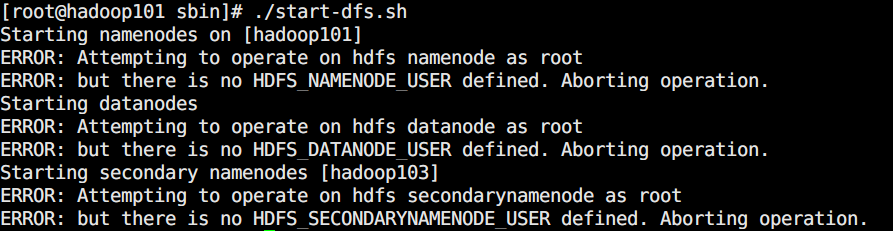
分别在 start-dfs.sh和 stop-dfs.sh脚本中添加以下内容即可:
HDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root



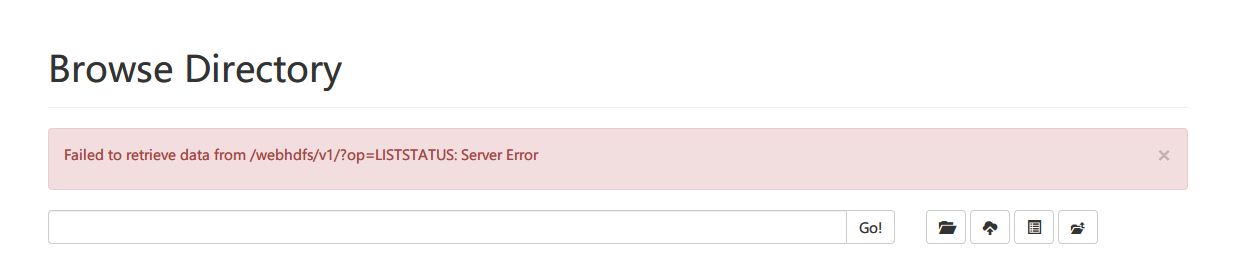
这是因为 JDK11以上的版本移除了 javax.activation.*。我们可以在 这里 下载,把包上传到 /opt/module/hadoop-3.3.2/share/hadoop/common/路径下即可。还有一种办法是回退 JDK 版本至 1.8。
配置 Flink
配置 Zookeeper
配置 Kafka
配置

若有收获,就点个赞吧
0 人点赞
