一、概述
TCP 通过 滑动窗口 做 流量控制,但这仅局限于连接的发送端和接收端。TCP 不能忽略网络上的事情,而无脑地发送数据,造成严重的网络拥塞。流量控制 可以想象成为一条车道,它只针对这条车道做流量控制。而拥塞控制则可以想象成交警,对一条路(拥有多个车道)进行管控,让每条道路都近乎通畅运行,从而避免拥塞。
所谓的 拥塞控制 就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。它是一个全局性的过程,涉及到所有主机、路由器以及与降低网络传输性能有关的所有因素。
拥塞控制主要是由下面 4 个算法组成:
- 慢启动(slow-start)。
- 拥塞避免(congeston advoidance)。
- 拥塞发生时 快重传(fast retransmit)。
-
拥塞窗口(cwnd)
Congestion window, cwnd,用于反应网络传输能力的变量。
- 分类
- 接收端所通告窗口 rwnd(receiver’s advertised window)。
- 发送窗口
_**swnd=min(cwnd, rwnd)。**_
- 拥塞窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口等于拥塞窗口。
- 发送方控制拥塞窗口的原则是:
- 只要网络没有出现拥塞,拥塞窗口就可以再增大一些,以便把更多的分组发送出去,提供网络利用率。但
- 只要网络出现拥塞或有可能出现拥塞,就必须把拥塞窗口减小一些,以减少注入到网络中的分组数,缓解网络出现的拥塞。
慢启动初始窗口 IW(Initial Window) 变迁
- 1 SMSS。RFC 2001(1997)
- 2~4 SMSS。RFC 2414(1998)
- 若
_**SMSS > 2190字节**_,则设置cwnd=2*SMSS字节,且不超过 2 个报文段。 - 若
**_2190字节 ≥ SMSS > 1095字节_**,则设置**_cwnd=3*SMSS字节_**,且不超过 3 个报文段。 - 若
**_SMSS ≤ 1095字节_**,则设置**_cwnd=4*SMSS字节_**,且不得超过 4 个报文段。
- 若
- 10 SMSS。RFC 6928(2013)
- Linux 3.0 后采用 Google 论文 的建议,把
cwnd的初始化设置为10个MSS。慢启动门限(ssthresh)
- Linux 3.0 后采用 Google 论文 的建议,把
与拥塞避免算法相关,为防止拥塞窗口 cwnd 增长过大而引起网络拥塞,默认值为 65535字节。用法如下:
- 当
_cwnd < ssthresh_时,使用慢启动算法。 - 当
_cwnd > ssthresh_时,停止使用慢开始算法而改用拥塞避免算法。 - 当
_cwnd = ssthresh_时,既可以使用慢启动算法,也可以使用拥塞避免算法。
- 当
它存在的意义是记录上一次最好的操作窗口的估计值,即 TCP 最优窗口估计值的下限。
二、拥塞控制算法
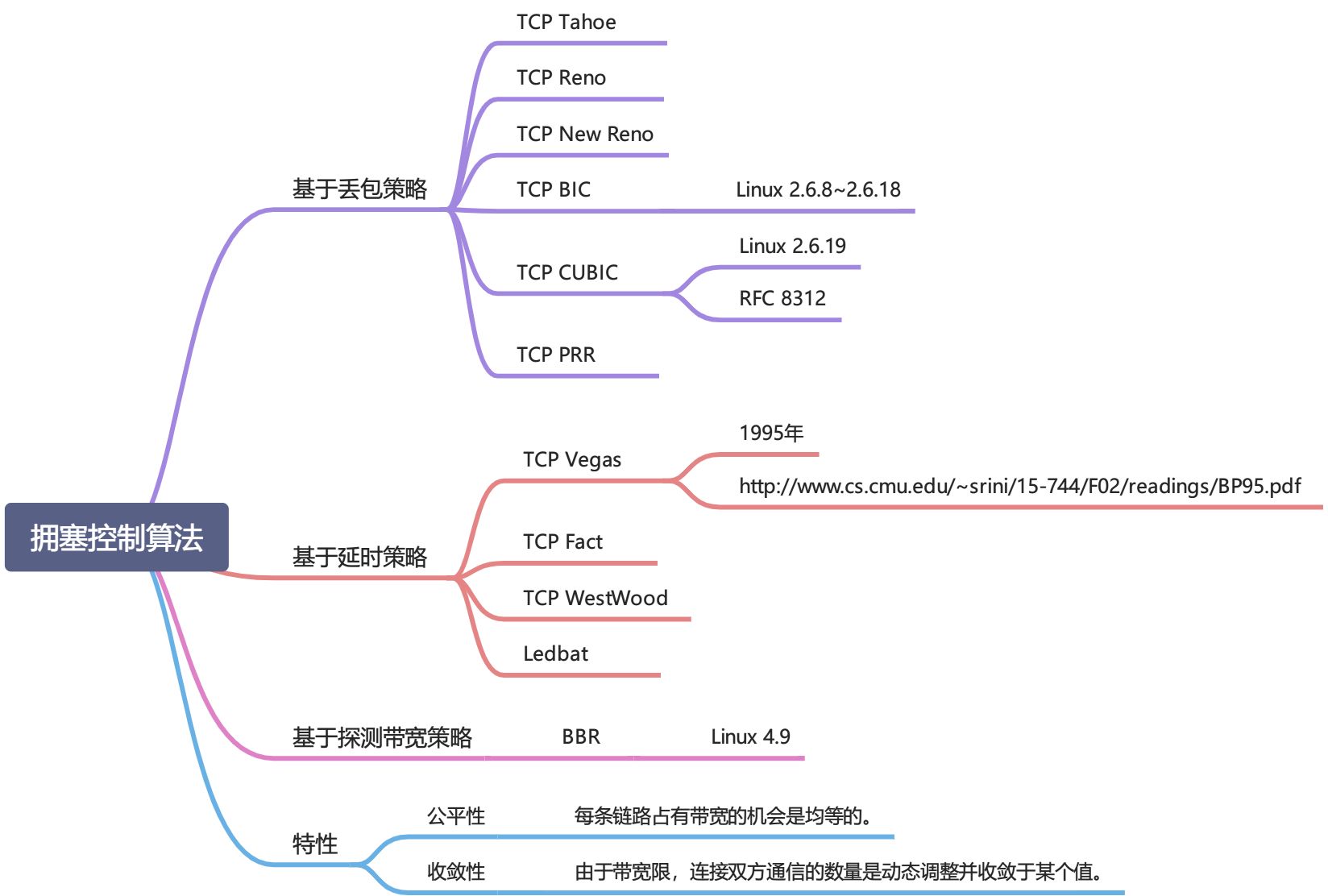
拥塞控制算法总览
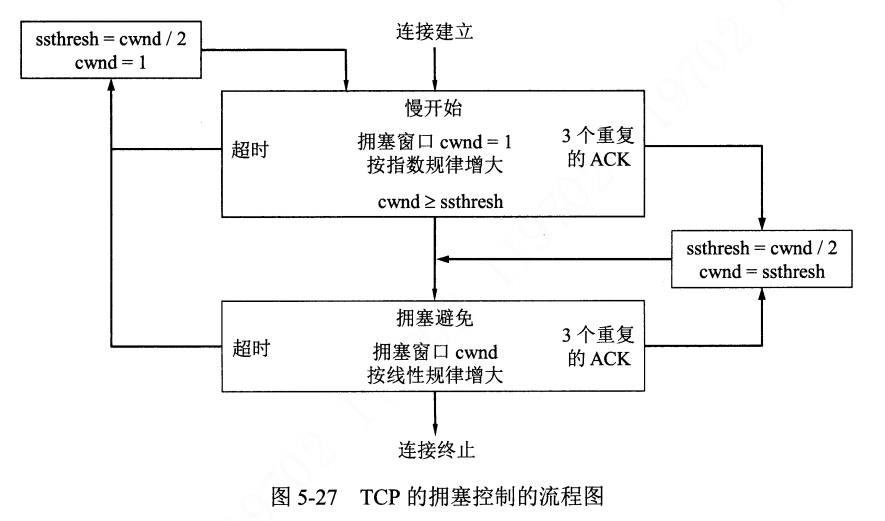
慢启动算法(slow-start)
当一个新的 TCP 连接建立或检测到由 超时重传 导致的丢包时,需要执行启动过程。
- 思路: 当主机开始发送数据时,由于并不清楚网络的负荷情况,所以如果立即把大量数据字节注入到网络,那么就有可能引起网络发生拥塞。比较好的方式是先探测一下,由小到大逐渐增大拥塞窗口的数值。
- 算法如下:
- 在刚开始发送时,初始化
_**cwnd=1**_,表示可传一个 MSS 大小的数据。 - 每当收到一个 ACK,
**_cwnd++_**,呈线性上升。 - 每当过了一个传输轮次(一个传输轮次所经历的时间其实就是往返时间 RTT),
**_cwnd=cwnd*2_**,呈指数上升。 - 每当
**_cwnd ≥ssthresh_**时,进入拥塞避免算法。
- 在刚开始发送时,初始化
- 我们可以看到,如果网速很快的话,
ACK确认报文也会很快返回,RTT 时间也会很短。此时的慢启动一点也不慢。在慢启动过程阶段,cwnd数值会快速增长,帮助确定一个慢启动阈值。一旦到达阈值,表示资源快到达瓶颈,此时如果还以现阶段速度增大,可能会使共享路由器队列的其他连接出现严重的丢包或重传等情况。于是,我们需要执行拥塞避免算法。
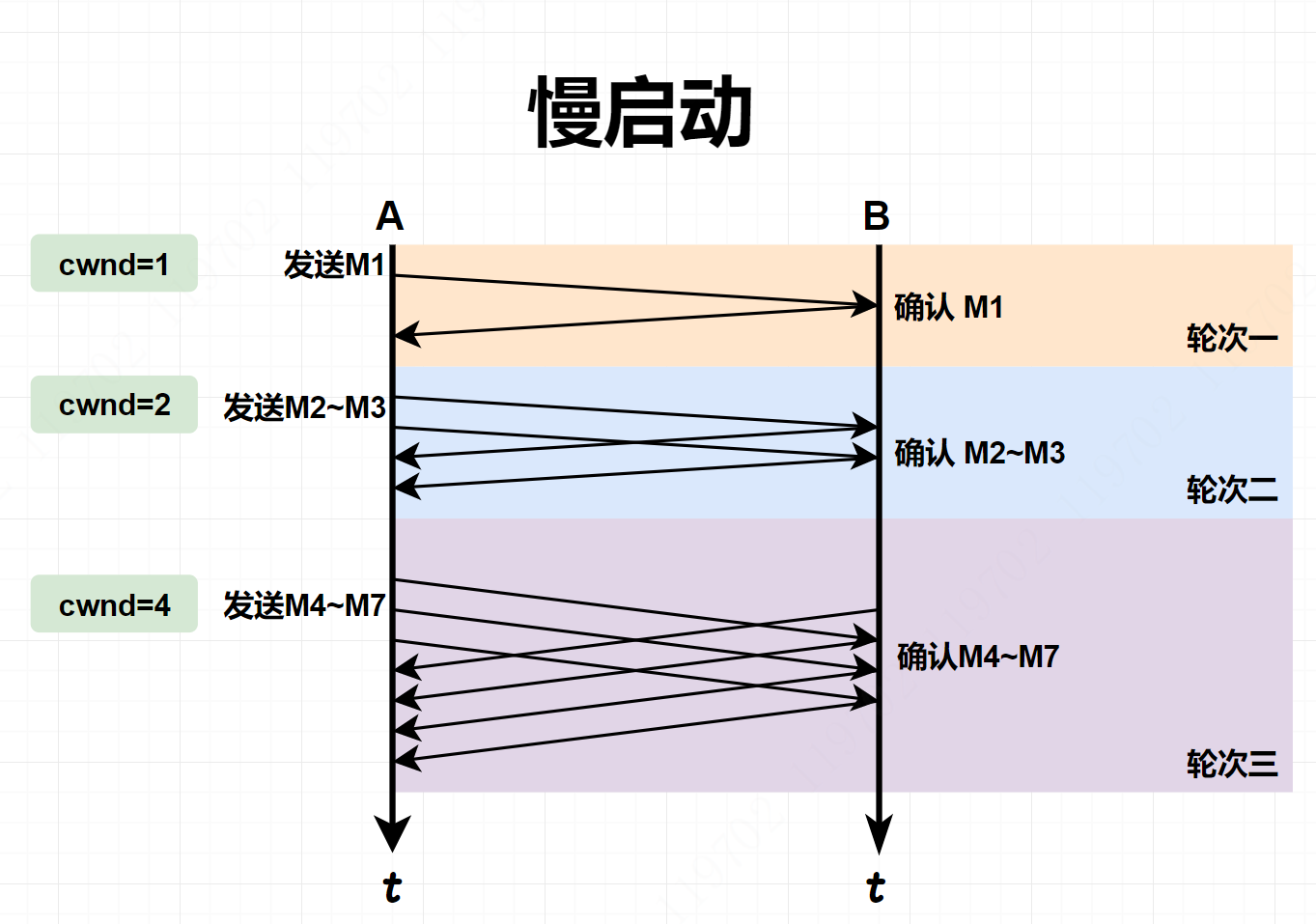
在 TCP 实际运行中,发送方只要收到一个对新报文的确认,其拥塞窗口 cwnd 就立即加1,并可以立即发送新的报文段,而不需要等这个轮次中所有确认都收到后才发送新的报文段。
拥塞避免算法(congestion avoidance)
这个名字取得好,就是避免网络拥塞的算法。我们知道,发送端不能无限制发送网络包,肯定是有一个限度的。回顾发包的一生,刚开始通过指数上升的慢启动逐渐接近网络带宽最大值,但此时还有一点网络余量,但此时,如果继续指数上升则可能立马出现丢包情况,因此,我们需要通过 拥塞避免算法 慢慢靠近网络最大值。
- 算法思路:

拥塞发生时的 重传算法
反应墙裂算法(RTO 超时)
- 等到 RTO 超时,重传数据包。然后进入慢启动状态。
- 算法步骤:
- 慢启动门限值
sshthresh=cwnd/2。 cwnd=1。- 进入慢启动过程。
- 慢启动门限值
很明显,一发生重传就立即进入慢启动过程,这样会导致网络波动较大。因为有可能只是个别分组出现超时,但此时网络状况良好。
快重传算法
- 触发条件: 收到 3 个重复的失序 ACK 段时触发快重传,而不用等到 RTO 超时。
- 接收方
- 当收到一个失序数据段时,立刻发送它所期待的缺口 ACK 序列号。
- 当接收到填充失序缺口的数据段时,立刻发送它所期待的下一个 ACK 序列号。
- 发送方
- 当接收到 3 个重复的失序 ACK 段(4个相同的失序 ACK 段)时,不再等待重传定时器的触发,立刻基于快速重传机制重发报文段。
- 算法:
- TCP Tahoe 的实现和 RTO 超时一样。
- TCP Reno 实现
cwnd = cwnd/2sshthresh = cwnd- 进入快速恢复算法
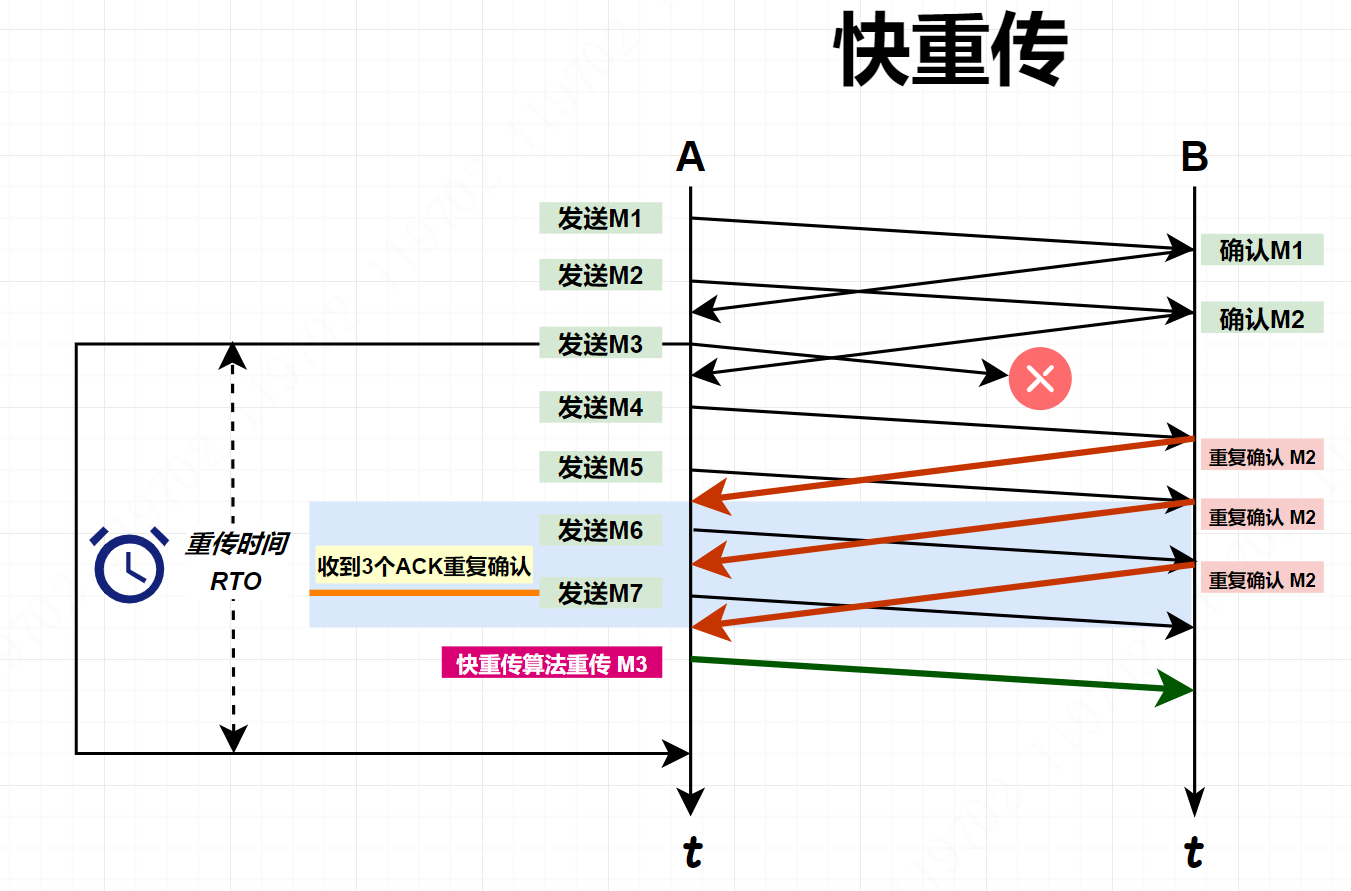
快重传规定,发送方只要连续收到 3 个重复确认 ACK,就知道存在报文丢失,需要立即进行重传报文,这样就不需要等待超时后重传,发送方也不会误认为出现了网络拥塞。使用快重传可以使整个网络的吞量提高约 20%。
快速恢复 fast recovery
TCP Reno
- RFC5681。
- 快速恢复算法和快速重传算法一般同时使用。进入快速恢复算法之前,cwnd 和 sshthresh 已被更新。
- 算法如下:
- 将 ssthresh 设置为当前拥塞窗口 cwnd 的一半,设当前 cwnd 为
**cwnd = ssthresh + 3*MSS **。 - 重传分组。
- 每收到一个重复 ACK,则
cwnd=cwnd+1。 - 当新数据 ACK 到达后,设置
cwnd=ssthresh。随后进入拥塞避免算法。
- 将 ssthresh 设置为当前拥塞窗口 cwnd 的一半,设当前 cwnd 为
问题: 依赖于 3个重复的 ACK。3个重复的 ACK 并不只意味着丢失一个数据报,很可能已经丢失好多了。但这个算法只会重传一个,而剩下的数据报只能等到
RTO超时重传。于是,一超时拥塞窗口减半,多个超时会造成 TCP 的传输速度呈级数下降,且不会触发快恢复算法。通常 SACK/D-SACK 的方法会让重传变得更人性化,但这是 TCP 提供的可选功能,并非所有计算机都支持。所以,需要一个没有 SACK 的方案,即 FACK。TCP New Reno
1995年提出,主要是在没有 SACK 的支持下改进快恢复算法。RFC6582。
- 相关概念:
- 部分应答(Partial ACK,PACK): 在恢复阶段接收部分 ACK 报文。
- 恢复应答(Recovery ACK,RACK): 在恢复阶段接收所有 ACK 报文。
- 思想:
- 只有一个数据包丢失的情况下,其机制与
TCP Reno是一样的。 - 当同时有多个包丢失时,只有当所有报文都被应答后才会退出快速恢复状态。
- 发送端在收到第一个 PACK 时,并不会立即结束快恢复过程,而是会持续重发 PACK 之后的数据包,直到将所有遗失的数据包 ACK 后才结束快恢复过程。
- 每收到一个 PACK时,就复位重传计时器。这使得发送端在当前网络中存在大量丢失情况下不需要等待 RTO超时 就能更正此错误,从而减少部分丢包对网络造成的影响。
- TCP 发送端接收到恢复应答表明: 经过重传,TCP 发送端已发送的报文都已经被接收端正确接收,网络已从拥塞中恢复。
TCP New Reno算法每一个 RTT 时间可重传一个丢失的数据报,如果一个发送窗口有 M 个数据报丢失,则该算法的快速恢复阶段将持续 M 个 RTT。因此,该算法是一个非常激进的算法,他同时延长了快重传和快恢复的过程。
- 只有一个数据包丢失的情况下,其机制与
- 算法:
- 重新定义恢复阶段。
- 进入恢复阶段,发送端重传丢失报文。更新慢启动阈值和拥塞窗口大小。
ssthresh=cwnd/2,cwnd=ssthresh + 3*MSS。 - 每收到一个重复 ACK,则
**_cwnd=cwnd+MSS_**。 - 当收到
PACK时,发送端重传PACK所确认报文的后续报文。 - 当收到
RACK时,发送端认为拥塞中所有被丢弃的报文都已经被重传,此时拥塞状态结束。更新拥塞窗口**_cwnd=ssthresh_**并退出拥塞状态。
-
FACK 算法
Forward Acknowledgment,FACK。论文地址。
该算法基于
SACK,SACK是使用 TCP 扩展字段解决非连接报文段确认情况,发送端通过SACK了解滑动窗口内哪些数据报已被确认,哪些数据报丢失。因此,发送端根据 SACK 精确重传丢失报文。三、图解 AMID
AMID,Additive-increase/MultiplicatIve-Decrease。
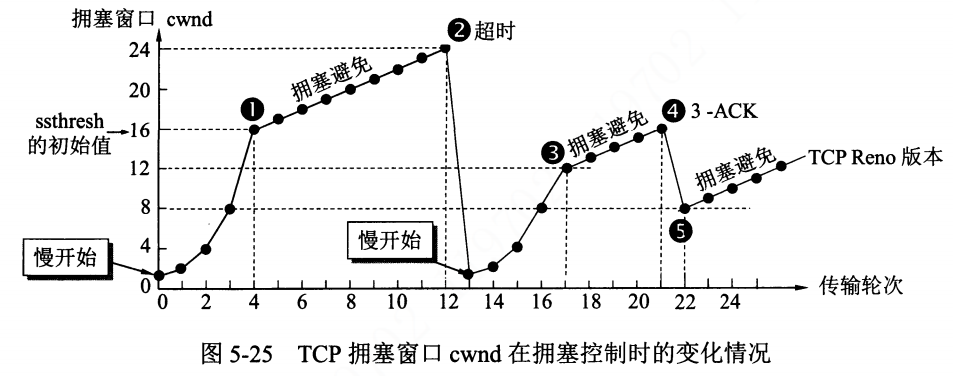
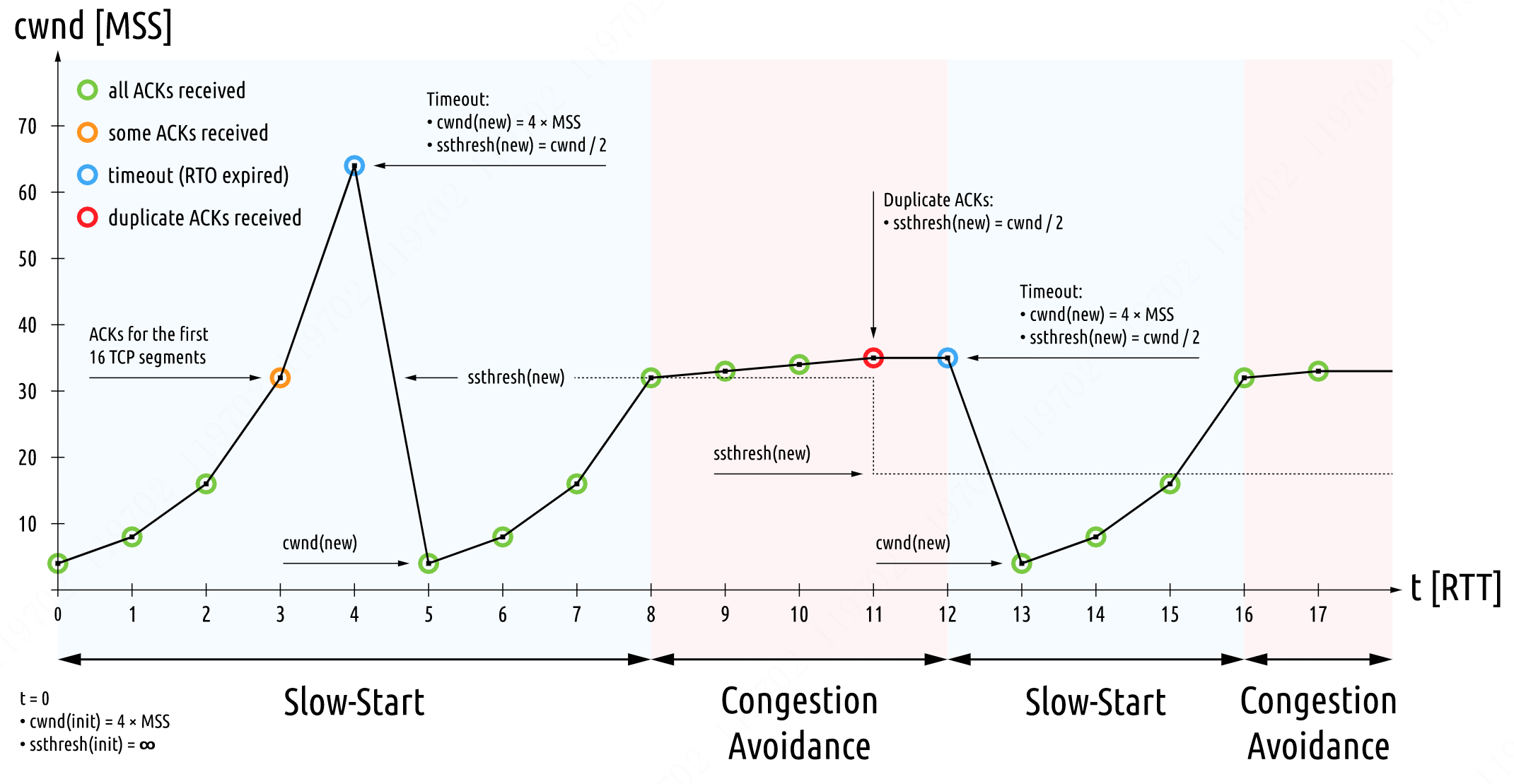
- ssthresh 初始值设置为 16 个报文段。
- 在执行慢开始算法时,发送方每收到一个对新报文段的确认 ACK,就把拥塞窗口值加1,然后开始下一轮的传输。此时,拥塞窗口 cwnd 随着传输轮次按指数规律增长。
- 当拥塞窗口 cwnd 增长到 ssthresh 时,就改为执行拥塞避免算法,拥塞窗口线性规律增长。
- 当拥塞窗口 cwnd = 24 时,网络出现超时,发送方判断为网络拥塞,于是调整门限值
ssthresh=cwnd/2=12,同时设置拥塞窗口cwnd=1,进入慢开始阶段。 - 当
_**cwnd=ssthresh=12**_时,改为执行拥塞避免算法,拥塞窗口按线性规律增大。 - 当
cwnd=16时,出现了发送方连续收到重复 ACK。由于网络实际上并未出现拥塞,所以使用快重传算法替代慢启动,使用快重传算法可以让发送方尽早知道发生了个别报文段的丢失。 - 在点 4 中,发送方知道现在中介丢失了个别的报文段,于是不启用慢开始,而是执行快恢复算法,这里,调整门限值
**_ssthresh=cwnd/2_**,同时设置拥塞窗口_**cwnd=ssthresh**_,并开始执行拥塞避免算法。
四、主动队列管理 AQM
- 网络层对 TCP 拥塞控制影响最大的就是路由器的分组丢弃策略。最简单情况下,通常按照 先进先出 的规则处理到来的分组。由于队列长度有限,因此当队列已满时,以后再到达的分组将都被丢弃,这就叫做尾部丢弃策略。缺点如下:
- 往往导致一连串分组丢失,会使发送方重传报文,使 TCP 进入拥塞控制的慢开启状态,发送速率降低到很小的数值。
- 网络中通常有很多 TCP 连接,这些连接中的报文段通常复用在网络层的 IP 数据报中传送,结果使这许多 TCP 连接在同一时间突然都进入到慢开始状态,这称为 全局同步,它使得全网的通信量突然下降了很多,而在网络恢复正常后,其通信量又突然增大很多。
- 为了避免全局同步现象, 在 1988 年得出 主动队列管理 AQM(Active Queue Management)。所谓主动就是不要等到队列满了时才丢弃报文,而是当队列长度达到某个阈值时就主动丢弃到达的分组。这样就主动提醒发送方应降低发送速率。AQM 可能有不同实现方式。
- 随机早期检测 RED(Random Early Discard)。
- 需要路由器维持两个参数,即队列长度最小门限和最大门限。
- 当每一个分组到达时,RED 就按照规定的算法先计算当前的平均队列长度。
- 若小于最小门限,则把新到达的分组放入队列排队。
- 若大于最大门限,丢弃。
- 若在两者之间,则按某一丢弃概率 p 把新到达的分组丢弃。
- 对于概率的选择是十分重要的,对每一个到达的分组都需要重新计算概率 p 。
- 经过多年检验,效果并不理想。现在已经有几种不同的算法来替代旧的 RED,但都还处于实验阶段。
- 随机早期检测 RED(Random Early Discard)。

若有收获,就点个赞吧
0 人点赞
