表设计
from datetime import datetimefrom peewee import *from playhouse.shortcuts import ReconnectMixinfrom playhouse.pool import PooledMySQLDatabasefrom playhouse.mysql_ext import JSONFieldclass ReconnectMySQLDatabase(ReconnectMixin, PooledMySQLDatabase):passdb = ReconnectMySQLDatabase("shop_inventory_srv", host="xxxx", port=3306, user="root", password="xxxx")class BaseModel(Model):add_time = DateTimeField(default=datetime.now, verbose_name="添加时间")is_deleted = BooleanField(default=False, verbose_name="是否删除")update_time = DateTimeField(verbose_name="更新时间", default=datetime.now)def save(self, *args, **kwargs):#判断这是一个新添加的数据还是更新的数据if self._pk is not None:#这是一个新数据self.update_time = datetime.now()return super().save(*args, **kwargs)@classmethoddef delete(cls, permanently=False): #permanently表示是否永久删除if permanently:return super().delete()else:return super().update(is_deleted=True)def delete_instance(self, permanently=False, recursive=False, delete_nullable=False):if permanently:return self.delete(permanently).where(self._pk_expr()).execute()else:self.is_deleted = Trueself.save()@classmethoddef select(cls, *fields):return super().select(*fields).where(cls.is_deleted==False)class Meta:database = db## class Stock(BaseModel):# #仓库表# name = CharField(verbose_name="仓库名")# address = CharField(verbose_name="仓库地址")class Inventory(BaseModel):#商品的库存表# stock = PrimaryKeyField(Stock)goods = IntegerField(verbose_name="商品id", unique=True)stocks = IntegerField(verbose_name="库存数量", default=0)version = IntegerField(verbose_name="版本号", default=0) #分布式锁的乐观锁def reback():for i in range(1,6):goods_inv = Inventory(Inventory.goods==i)goods_inv.stocks = 100goods_inv.save()
库存扣减
因为扣减是从订单开始的,所以往往涉及到多个商品同时扣减,现在模拟如下:
添加事务扣除
if __name__ == "__main__":
# 假定库存都为100
goods_list = [(1,2),(2,3),(3,120)]
# 添加事务
with db.atomic() as txn:
for goods_id,num in goods_list:
# 查库存
goods_inv = Inventory.get(Inventory.goods==goods_id)
if goods_inv.stocks<num:
print(f"{goods_id}:库存不足")
txn.rollback()
break
else:
goods_inv.stocks-=num
goods_inv.save()
超卖问题
多线程模拟,显然下面代码执行结果是不对的启动了两个线程对于商品1来说各扣除10件,但是最终结果是扣除了10件。这样超卖问题出现。下面代码中在更新库存的时候使用的当时查询到的变量,由于是多线程进行的,会发生资源竞争,所以两个线程可能得到的数据是一样的(如果同时执行),所以在做更改的时候会发生结果和预期不一样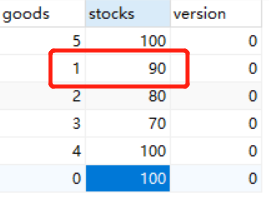
def sell():
goods_list = [(1, 10), (2, 20), (3, 30)]
# 添加事务
with db.atomic() as txn:
for goods_id, num in goods_list:
# 查库存
goods_inv = Inventory.get(Inventory.goods == goods_id)
from random import randint
time.sleep(randint(1,3))
if goods_inv.stocks < num:
print(f"{goods_id}:库存不足")
txn.rollback()
break
else:
goods_inv.stocks -= num
goods_inv.save()
if __name__ == "__main__":
thed1 = threading.Thread(target=sell)
thed2 = threading.Thread(target=sell)
thed1.start()
thed2.start()
thed1.join()
thed2.join()
Mysql在执行Update操作时是加锁的,所以可以把修改操作使用Mysql原理执行,update tablename set filename=xxx where 
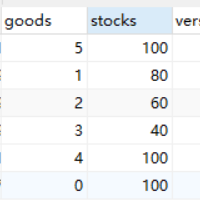
def sell():
goods_list = [(1, 10), (2, 20), (3, 30)]
# 添加事务
with db.atomic() as txn:
for goods_id, num in goods_list:
# 查库存
goods_inv = Inventory.get(Inventory.goods == goods_id)
from random import randint
time.sleep(randint(1,3))
if goods_inv.stocks < num:
print(f"{goods_id}:库存不足")
txn.rollback()
break
else:
query = Inventory.update(stocks=Inventory.stocks-num).where(Inventory.goods==goods_id)
ok = query.execute()
if ok:
print("更新成功")
else:
print("更新失败")
使用更新操作后看到数据是可以更新成功的,但是试想一种场景,线程1和线程2都想买商品1 99件,可以看到超卖问题出题,出现问题的原因是读取时,线程的更新操作还未完成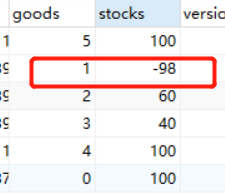
如何解决?,可以对执行过程加锁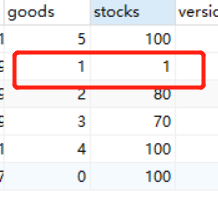

R = threading.Lock()
def sell():
goods_list = [(1, 99), (2, 20), (3, 30)]
# 添加事务
with db.atomic() as txn:
for goods_id, num in goods_list:
# 查库存
R.acquire() # 获取锁
goods_inv = Inventory.get(Inventory.goods == goods_id)
from random import randint
time.sleep(randint(1,3))
if goods_inv.stocks < num:
print(f"{goods_id}:库存不足")
txn.rollback()
break
else:
query = Inventory.update(stocks=Inventory.stocks-num).where(Inventory.goods==goods_id)
ok = query.execute()
if ok:
print("更新成功")
else:
print("更新失败")
R.release()
解决到这,问题看似已经得到很好的解决,在单体应用中可以通过加锁来解决这种问题,但是在分布式系统中或者是微服务中,普通的锁机制无法满足需求,需要分布式锁。
常见的分布式锁实现方案
mysql实现
- 悲观锁
是指操作数据库库时对数据库进行加锁,实现简单,但是并发性不高
- 乐观锁
def sell(): goods_list = [(1, 10), (2, 20), (3, 30)] # 添加事务 with db.atomic() as txn: for goods_id, num in goods_list: while True: # 查库存(这是当前查询到的记录 ) goods_inv = Inventory.get(Inventory.goods == goods_id) print(goods_inv,"----") print(f"当前版本号{goods_inv.version}") from random import randint time.sleep(randint(1,3)) if goods_inv.stocks < num: print(f"{goods_id}:库存不足") txn.rollback() break else: # 更新的时候同时更新版本信信息 query = Inventory.update(stocks=Inventory.stocks-num,version=Inventory.version+1).where( Inventory.goods==goods_id,Inventory.version==goods_inv.version) ok = query.execute() if ok: print("更新成功") break else: print("更新失败")基于redis的分布式锁
```python def sell(): goods_list = [(1, 10), (2, 20), (3, 30)]添加事务
with db.atomic() as txn:for goods_id, num in goods_list: # 查库存(这是当前查询到的记录 ) # 获取锁 lock = Lock(f"lock:good_{goods_id}") lock.acquire() goods_inv = Inventory.get(Inventory.goods == goods_id) print(goods_inv,"----") print(f"当前版本号{goods_inv.version}") from random import randint time.sleep(randint(1,3)) if goods_inv.stocks < num: print(f"{goods_id}:库存不足") txn.rollback() break else: # 更新的时候同时更新版本信信息 query = Inventory.update(stocks=Inventory.stocks-num).where( Inventory.goods==goods_id) ok = query.execute() if ok: print("更新成功") else: print("更新失败") lock.release()
class Lock(): def init(self,name): self.redis_client = redis.Redis(host=”127.0.0.1”) self.name = name
# 阻塞获取
def acquire(self):
if not self.redis_client.get(self.name):
self.redis_client.set(self.name, 1)
return True
else:
while True:
import time
time.sleep(1)
if not self.redis_client.get(self.name):
return True
def release(self):
self.redis_client.delete(self.name)
该版本存在的问题:如果是多线程,那么获取值和设置值得操作可能同时执行,即多个进程同时执行到如下代码<br /><br />这样就会发生超卖现象,解决方案就是把两个操作变成一步操作这样就会保证到锁获取的原子性。业务端复无法实现此类操作,但是redis提供一个命令setnx,他的作用就是设置为一个不存在的键设置值
<a name="peyGE"></a>
### 基于setnx确保分布式锁的原子性
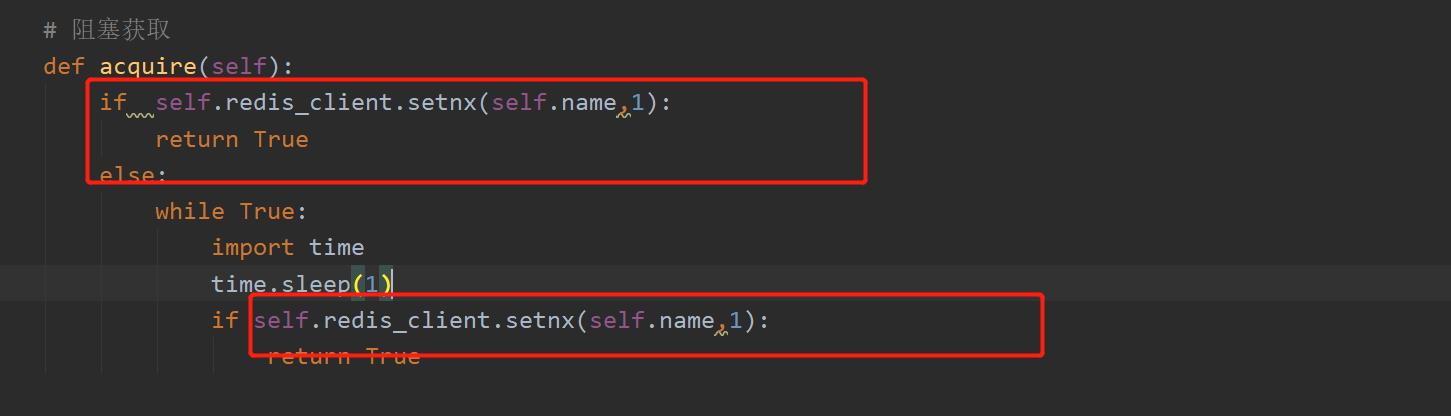
```python
class Lock():
def __init__(self,name):
self.redis_client = redis.Redis(host="127.0.0.1")
self.name = name
# 阻塞获取
def acquire(self):
if self.redis_client.setnx(self.name,1):
return True
else:
while True:
import time
time.sleep(1)
if self.redis_client.setnx(self.name,1):
return True
def release(self):
self.redis_client.delete(self.name)
分布式锁需要解决的问题
- 互斥性:任意时刻只能有一个客户端拥有锁,不能同时多个客户端获取
- 安全性:锁只能被持有该锁的用户删除,而不能被其他用户删除
- 死锁:获取锁的客户端因为某些原因而宕机,而未能释放锁,其他客户端无法获取此锁,需要有机制来避免该类问题的发生
- 代码异常,导致无法运行到release
- 你的当前服务器网络出问题 - 脑裂
- 断电
- 容错:当部分节点宕机,客户端仍能获取锁或者释放锁
如何解决上述问题的发生 - 设置过期时间
过期设置会产生新的问题:
- 当前的线程如果在一段时间后没有执行完, 当前的程序没有执行完,然后key过期了
- 不安全
- 另一个线程进来以后会将当前的key给删除掉, 另一个线程删除掉了本该属于我设置的值
- 如果当前的线程没有执行完,那我的这个线程还应该在适当的时候去续租,将过期时间重新设置
- 应该在什么时候去设置过期 - 15的2/3的时候去续租,也就是运行10s以后去将过期时间重新设置为15s
- 如果去定时的完成这个续租的过程 - 启动一个线程去完成
如何设置本线程设置的key只能本线程删除?如何设置过期时间?如何续租?
分布式中的重点难题
设置当前线程只能删除自己设置的键值
class Lock():
def __init__(self,name):
self.id = uuid.uuid4()
self.redis_client = redis.Redis(host="127.0.0.1")
self.name = name
# 阻塞获取
def acquire(self):
# 设置过期时间
if self.redis_client.set(self.name,self.id,nx=True,ex=15):
# 启动一个线程定时属性这个过期来完成续租功能 lua实现
return True
else:
while True:
import time
time.sleep(1)
if self.redis_client.set(self.name,self.id,nx=True,ex=15):
return True
def release(self):
# 下面代码可能第一步执行成功后第二步执行失败 所以要保证其原子性 redis未提供相应的命令
# 但是可以使用redis支持的脚步语言 lua
if self.redis_client.get(self.name) == self.id:
self.redis_client.delete(self.name)
else:
print("不能删除不属于自己的锁")
基于Python的开源分布式锁
分布式锁的优缺点
基于redis
- 优点 性能高 简单,redis本身使用频繁,不需要额外维护
- 缺点 依赖三方组件,单机redis挂掉可能性较高。
消息队列在外微服务中的作用和选型
1. MQ的使用场景
1. 什么是mq
消息队列是一种“先进先出”的数据结构

2. 应用场景
其应用场景主要包含以下3个方面
- 应用解耦
系统的耦合性越高,容错性就越低。以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
使用消息队列解耦合,系统的耦合性就会提高了。比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
- 流量削峰
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。
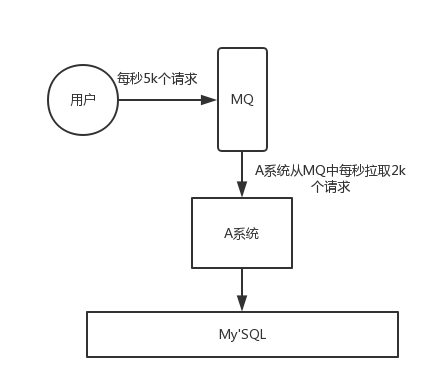
一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
处于经济考量目的:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削峰
- 数据分发
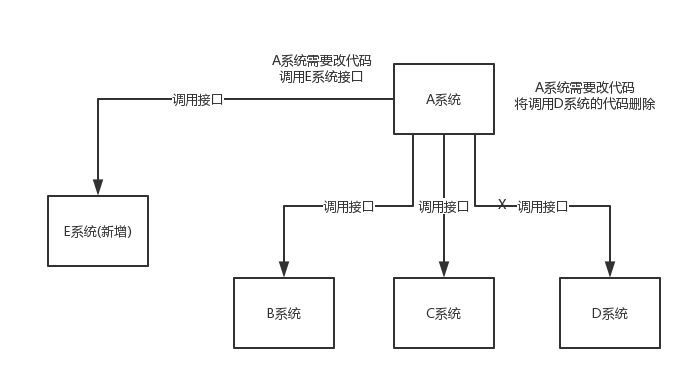
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可。
3. MQ的优点和缺点
优点:解耦、削峰、数据分发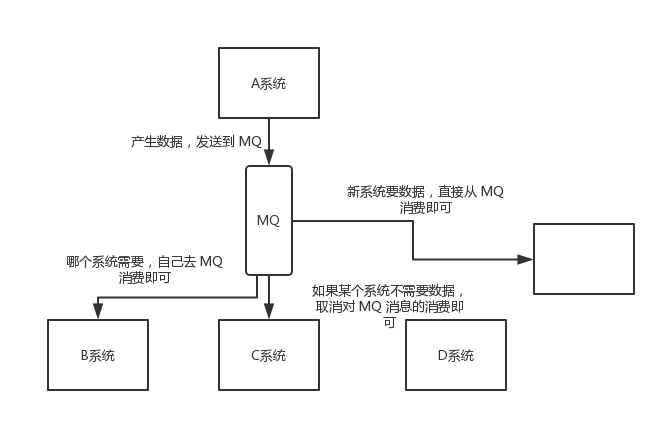
缺点包含以下几点:
- 系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用? - 系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性? - 一致性问题
A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。
如何保证消息数据处理的一致性?2. MQ技术选型
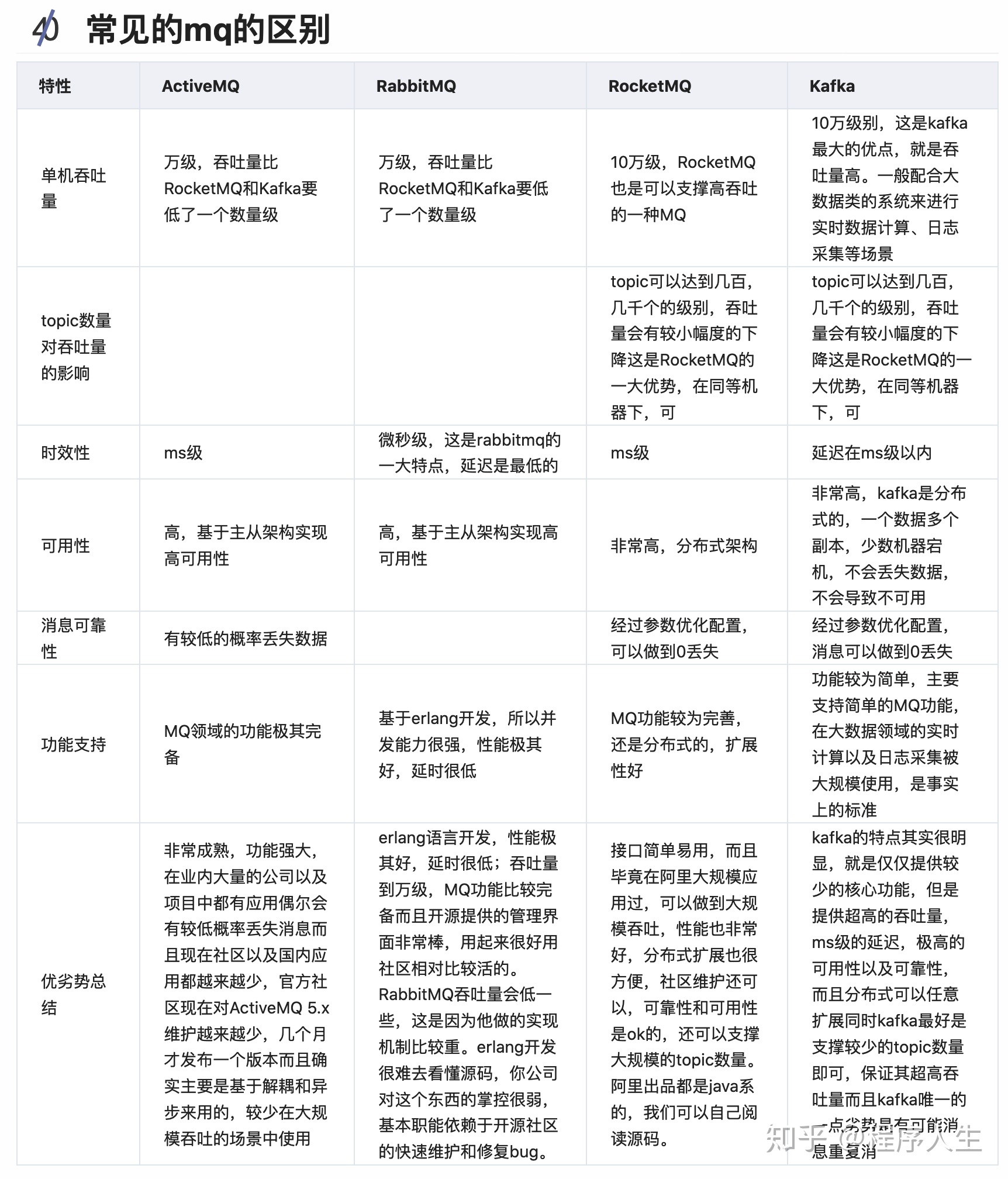
结论:
(1)中小型软件公司,建议选RabbitMQ.一方面,erlang语言天生具备高并发的特性,而且他的管理界面用起来十分方便。正所谓,成也萧何,败也萧何!他的弊端也在这里,虽然RabbitMQ是开源的,然而国内有几个能定制化开发erlang的程序员呢?所幸,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug,这点对于中小型公司来说十分重要。不考虑rocketmq和kafka的原因是,一方面中小型软件公司不如互联网公司,数据量没那么大,选消息中间件,应首选功能比较完备的,所以kafka排除。但是rocketmq已经交给apache管理,所以rocketmq的未来发展趋势看好。
(2)大型软件公司,根据具体使用在rocketMq和kafka之间二选一。一方面,大型软件公司,具备足够的资金搭建分布式环境,也具备足够大的数据量。针对rocketMQ,大型软件公司也可以抽出人手对rocketMQ进行定制化开发,毕竟国内有能力改JAVA源码的人,还是相当多的。至于kafka,根据业务场景选择,如果有日志采集功能,肯定是首选kafka了。具体该选哪个,看使用场景。
课程中选择rocketmq,基于两点考虑:
- 延迟消息简单高效
- 死信队列
- 完善的事务消息功能
rocketmq入门
1. 安装
下载
install.zip
安装#1. cd到目录之下 docker-compose up2 基本概念
- Producer:消息的发送者;举例:发信者
- Consumer:消息接收者;举例:收信者
- Broker:暂存和传输消息;举例:邮局
- NameServer:管理Broker;举例:各个邮局的管理机构
- Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
- Message Queue:相当于是Topic的分区;用于并行发送和接收消息
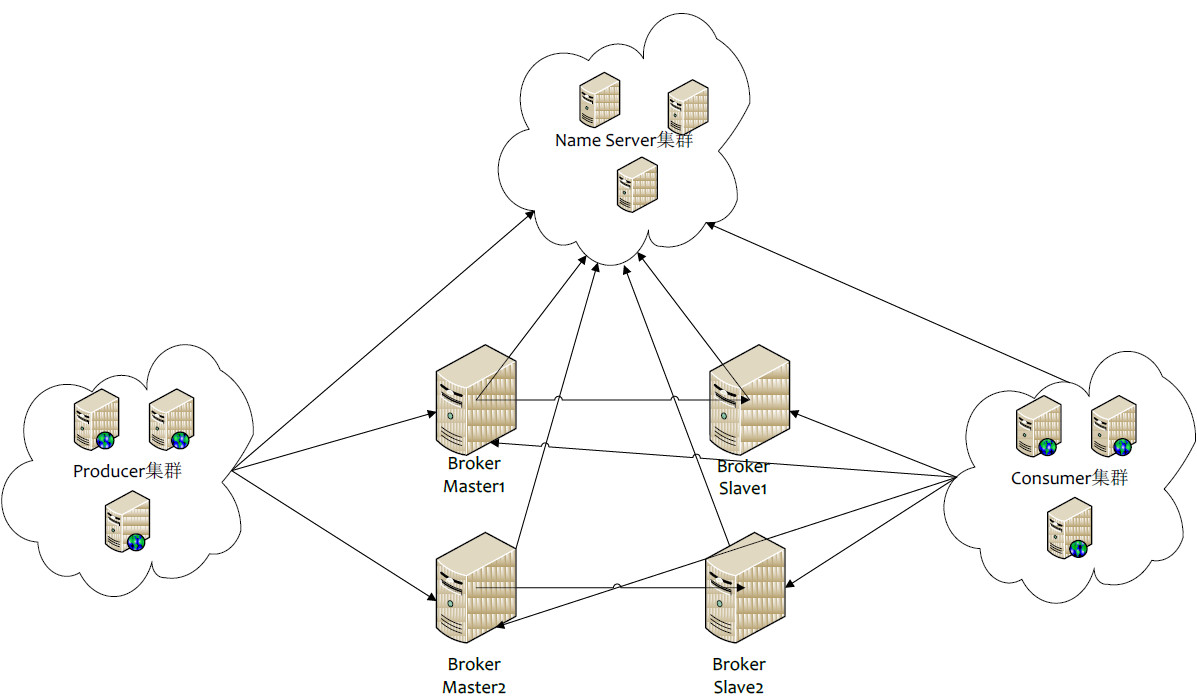
3. 消息类型
按照发送的特点分:
同步发送
- 同步发送,线程阻塞,投递completes阻塞结束
- 如果发送失败,会在默认的超时时间3秒内进行重试,最多重试2次
- 投递completes不代表投递成功,要check SendResult.sendStatus来判断是否投递成功
SendResult里面有发送状态的枚举:SendStatus,同步的消息投递有一个状态返回值的
public enum SendStatus { SEND_OK, FLUSH_DISK_TIMEOUT, FLUSH_SLAVE_TIMEOUT, SLAVE_NOT_AVAILABLE, }retry的实现原理:只有ack的SendStatus=SEND_OK才会停止retry
注意事项:发送同步消息且Ack为SEND_OK,只代表该消息成功的写入了MQ当中,并不代表该消息成功的被Consumer消费了
- 异步发送
- 异步调用的话,当前线程一定要等待异步线程回调结束再关闭producer啊,因为是异步的,不会阻塞,提前关闭producer会导致未回调链接就断开了
- 异步消息不retry,投递失败回调onException()方法,只有同步消息才会retry,源码参考 DefaultMQProducerImpl.class
- 异步发送一般用于链路耗时较长,对 RT 响应时间较为敏感的业务场景,例如用户视频上传后通知启动转码服务,转码完成后通知推送转码结果等。
- 异步发送
- 单向发送
- 消息不可靠,性能高,只负责往服务器发送一条消息,不会重试也不关心是否发送成功
- 此方式发送消息的过程耗时非常短,一般在微秒级别
- 单向发送
下表概括了三者的特点和主要区别。
| 发送方式 | 发送 TPS | 发送结果反馈 | 可靠性 |
|---|---|---|---|
| 同步发送 | 快 | 有 | 不丢失 |
| 异步发送 | 快 | 有 | 不丢失 |
| 单向发送 | 最快 | 无 | 可能丢失 |
按照使用功能特点分:
- 普通消息(订阅)
普通消息是我们在业务开发中用到的最多的消息类型,生产者需要关注消息发送成功即可,消费者消费到消息即可,不需要保证消息的顺序,所以消息可以大规模并发地发送和消费,吞吐量很高,适合大部分场景。
- 顺序消息
顺序消息分为分区顺序消息和全局顺序消息,全局顺序消息比较容易理解,也就是哪条消息先进入,哪条消息就会先被消费,符合我们的FIFO,很多时候全局消息的实现代价很大,所以就出现了分区顺序消息。分区顺序消息的概念可以如下图所示: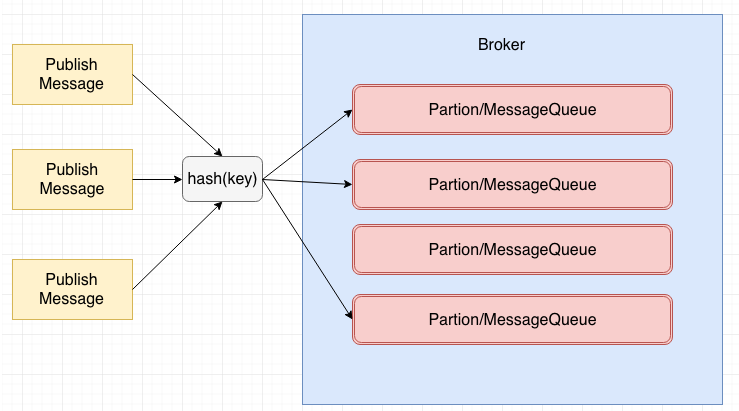
我们通过对消息的key,进行hash,相同hash的消息会被分配到同一个分区里面,当然如果要做全局顺序消息,我们的分区只需要一个即可,所以全局顺序消息的代价是比较大的。
- 延时消息 - 订单超时库存归还
延迟的机制是在 服务端实现的,也就是Broker收到了消息,但是经过一段时间以后才发送
服务器按照1-N定义了如下级别: “1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h”;若要发送定时消息,在应用层初始化Message消息对象之后,调用Message.setDelayTimeLevel(int level)方法来设置延迟级别,按照序列取相应的延迟级别,例如level=2,则延迟为5s
msg.setDelayTimeLevel(2);
SendResult sendResult = producer.send(msg);
实现原理:
- 发送消息的时候如果消息设置了DelayTimeLevel,那么该消息会被丢到ScheduleMessageService.SCHEDULE_TOPIC这个Topic里面
- 根据DelayTimeLevel选择对应的queue
- 再把真实的topic和queue信息封装起来,set到msg里面
- 然后每个SCHEDULE_TOPIC_XXXX的每个DelayTimeLevelQueue,有定时任务去刷新,是否有待投递的消息
- 每 10s 定时持久化发送进度
- 事务消息
消息队列RocketMQ版提供的分布式事务消息适用于所有对数据最终一致性有强需求的场景。本文介绍消息队列RocketMQ版事务消息的概念、优势、典型场景、交互流程以及使用过程中的注意事项。
概念介绍
- 事务消息:消息队列RocketMQ版提供类似X或Open XA的分布式事务功能,通过消息队列RocketMQ版事务消息能达到分布式事务的最终一致。
- 半事务消息:暂不能投递的消息,发送方已经成功地将消息发送到了消息队列RocketMQ版服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成“暂不能投递”状态,处于该种状态下的消息即半事务消息。
- 消息回查:由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,消息队列RocketMQ版服务端通过扫描发现某条消息长期处于“半事务消息”时,需要主动向消息生产者询问该消息的最终状态(Commit或是Rollback),该询问过程即消息回查。
分布式事务消息的优势
消息队列RocketMQ版分布式事务消息不仅可以实现应用之间的解耦,又能保证数据的最终一致性。同时,传统的大事务可以被拆分为小事务,不仅能提升效率,还不会因为某一个关联应用的不可用导致整体回滚,从而最大限度保证核心系统的可用性。在极端情况下,如果关联的某一个应用始终无法处理成功,也只需对当前应用进行补偿或数据订正处理,而无需对整体业务进行回滚。

若有收获,就点个赞吧
0 人点赞
