- 二分搜索树是二叉树
- 二分搜索树的每个节点的值都大于其左子树上所有节点的值,小于右子树所有节点的值
- 存储的元素必须有可比较性
- 每一个子树都是二分搜索树
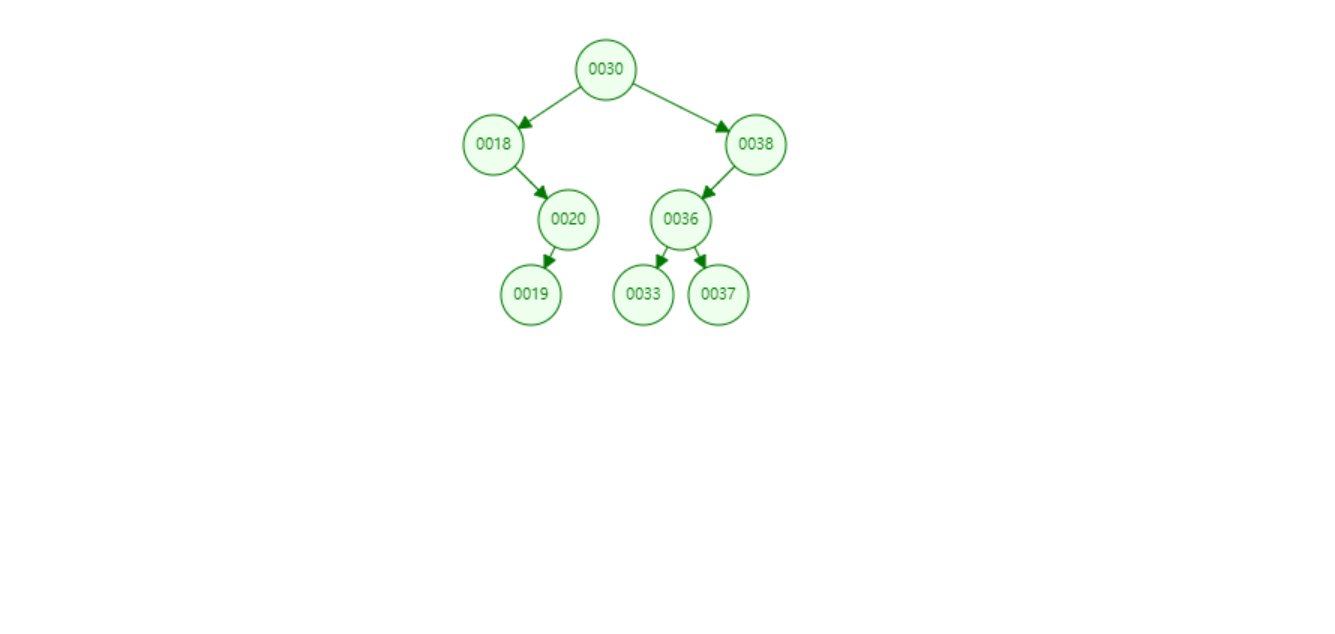
添加元素
class Node:def __init__(self, key=None, value=None, left=None, right=None):self.key = keyself.value = valueself.left = leftself.right = rightdef new(self, key=None, value=None, left=None, right=None):self.key = keyself.value = valueself.left = leftself.right = rightclass BST:"""二分搜索树"""def __init__(self):# 根节点self.root = None# 树的大小self.count = 0def size(self):# 返回树大小return self.countdef is_empty(self):# 是否为空树return self.count == 0# 添加元素def insert_r(self, key, value):# 递归实现self.root = self.__insert_r(self.root, key=key, value=value)def __insert_r(self, node: Node, key, value)->Node:"""插入元素 不存在重复元素 如果插入的元素存在 替换即可递归插入:param node: 子树的根:param key: 键:param value: 值:return: 当前树"""if node is None:# 上一个节点的子树为空 可以进行插入操作 OR Rootself.count += 1return Node(key=key, value=value)# 存在该键 替换值if key == node.key:node.value = valueelif key < node.key:# 应该存储在当前节点的左子树分支node.left = self.__insert_r(node.left, key, value)else:# 应该存储在当前节点的右子树分支node.right = self.__insert_r(node.right, key, value)# 返回这个节点return nodedef insert(self,key,value):# 非递归实现if self.root is None:# 根节点self.root = Node(key,value)else:# 当前遍历的节点node = self.root# 上一个节点pre = self.rootis_break =Falsewhile (node is not None):pre = nodeif key<node.key:# 应该插入到左子树node = node.leftelif key>node.key:# 应该插入到右子树node = node.rightelse:# 替换值node.value = valueis_break = treebreakif not is_break:if key<pre.value:pre.left = Node(key,value)else:pre.right = Node(key, value)# 是否包含该元素def contain(self, key):return self.__contain(self.root, key)def __contain(self, node: Node, key) -> bool:# 没有节点则直接返回if node is None:return Falseif key == node.key:return Trueelif key < node.key:# 在左子树中查找return self.__contain(node.left, key)else:# 在右子树中查找return self.__contain(node.right, key)# 查找元素def search(self, key):return self.__search(self.root, key)def __search(self, node: Node, key):if node is None:return Noneif key == node.key:return node.valueelif key < node.key:return self.__search(node.left, key)else:return self.__search(node.right, key)
二分搜索树的遍历
深度
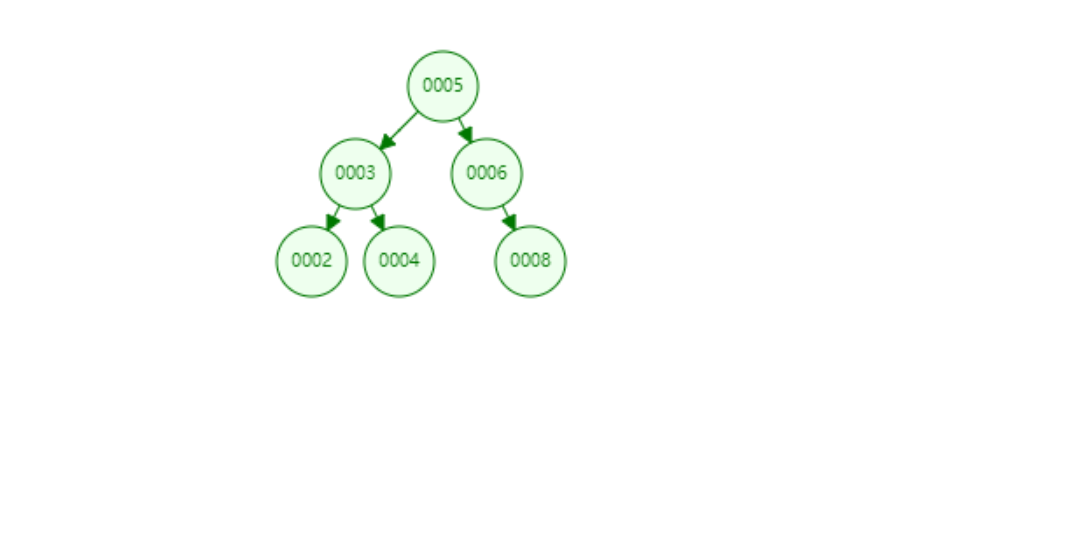
- 前序遍历
5 3 6 8 4 2
# 前序遍历def pre_order_r(self):# 递归实现遍历self.__pre_order(self.root)def __pre_order(self, node: Node):if node is not None:# 先打印当前节点的值print(node.key)# 后遍历左子树的值self.__pre_order(node.left)# 再遍历右子树的值self.__pre_order(node.right)def pre_order(self):# 非递归前序遍历stacks = [self.root]while len(stacks) >0:cur_node = stacks.pop()print(cur_node.value)if cur_node.right is not None:stacks.append(cur_node.right)if cur_node.left is not None:stacks.append(cur_node.left)
中序遍历
# 中序遍历def in_order_r(self):# 递归实现self.__in_order_r(self.root)def __in_order_r(self, node: Node):if node is not None:self.__in_order_r(node.left)print(str(node.key) + " ", end="")self.__in_order_r(node.right)def in_order(self):stacks = []cur_node = self.rootwhile cur_node is not None or len(stacks) > 0:if cur_node is not None:# 如果是有左边stacks.append(cur_node)cur_node = cur_node.leftelse:# 左子树为空 出pop_node = stacks.pop()print(pop_node.value, end=" ")cur_node = pop_node.right
后序遍历
# 后序遍历递归def post_order_r(self):self.__post_order_r(self.root)def __post_order_r(self, node: Node):if node is not None:self.__post_order_r(node.left)self.__post_order_r(node.right)print(node.key, end=" ")
广度
def level_order(self):qlist = Queue(maxsize=100)qlist.put(self.root)while (not qlist.empty()):node = qlist.get()print(node.key)if node.left is not None:qlist.put(node.left)if node.right is not None:qlist.put(node.right)
查询以及删除
# 查找最小值 最小值一定在左子树最左面def mininum(self):assert self.count > 0, "tree mast has value"mininode = self.__mininum(self.root)return mininode.keydef __mininum(self, node: Node):if node.left is None:return nodereturn self.__mininum(node.left)# 查找最大值 最大值一定是在右子树最右面def maxnum(self):assert self.count > 0, "tree mast has value"maxinode = self.__maxinum(self.root)return maxinode.keydef __maxinum(self, node: Node):if node.right is None:return nodereturn self.__maxinum(node.right)# 删除最小值def removeMin(self):if self.root is not None:self.root = self.__removeMin(self.root)def __removeMin(self, node: Node):# 已经是最小值if node.left is None:# 可能存在左子树right_node = node.rightdel nodeself.count -= 1return right_node# 删除后 最小节点的子树肯定是小于当前节点 故放leftnode.left = self.__removeMin(node.left)return node# 删除最大值def removeMax(self):if self.root is not None:self.root = self.__removeMax(self.root)def __removeMax(self, node: Node):# 已经是大小值if node.right is None:left_node = node.leftdel nodeself.count -= 1return left_node# 删除后 最大节点的子树肯定是大于当前节点 故放rightnode.right = self.__removeMax(node.right)return node"""删除任意节点删除左右都有孩子的节点 d找到后继即d右节点的最小值(并删除) 代替当前节点d"""def removeNode(self, key):self.__removeNode(self.root, key)def __removeNode(self, node: Node, key):if node is None:return Noneif key < node.key:# 继续从左子树中查找node.left = self.__removeNode(node.left, key)return nodeelif key > node.key:# 继续从右子树中查找node.right = self.__removeNode(node.right, key)return nodeelse:# 找到了要删除的点if node.left is None:right_node = node.rightdel nodeself.count -= 1return right_nodeif node.right is None:left_node = node.leftdel nodeself.count -= 1return left_node# 左右子树都不为空if node.left is not None and node.right is not None:# 找到当前节点下二叉树的最小值 要替换到当前位置minNode = self.__mininum(node.right)minNode.right = self.__removeMin(node.right)minNode.left = node.leftdel nodeself.count -= 1return minNode
基于二分搜索树和链表实现集合
```python from binary_tree import BST from linked_list import LinkedList
使用二分搜索树实现Set 集合
class SetTree:
# 基于二分搜索树的集合实现def __init__(self):self.bst = BST()def add(self, key, value):self.bst.insert_r(key,value)def delete(self, key):self.bst.removeNode(key)def get_size(self):return self.bst.size()def is_empty(self):return self.bst.is_empty()def c(self,key):return self.bst.contain(key)
class SetLinked:
# 基于链表的集合实现def __init__(self):self.list = LinkedList()def add(self, key):if not self.contains(key):self.list.add_first(key)def delete(self, key):self.list.remove(key)def get_size(self):return self.list.get_size()def is_empty(self):return self.list.is_empty()def contains(self,key):return self.list.contains(key)
``` 在集合中是没有重复元素的,集合中常见的操作就是添加,删除,查找,其时间复杂度分析如下:
- 二分搜索树实现的集合
新增O(h) h 表示层数
删除O(h) h 表示层数
查找O(h) h 表示层数
其中h和节点个数的关系(满二叉树为例) h = log2(n+1) 所以整体复杂度为O(log2n)
- 链表实现集合
新增O(n) 确保元素没有重复,需要在添加之前遍历查找是否存在。
删除O(n)
查找O(n)

若有收获,就点个赞吧
0 人点赞
