原文地址 https://aturon.github.io/blog/2015/08/27/epoch/
众所周知,垃圾回收的一大优势就是构建高性能无锁数据结构。手动做这些数据结构的内存管理并不简单,GC使之变成非常简单的事。
这篇文章要说明,使用Rust,能为并发数据结构构建Api:
使实现无锁数据结构像GC一样简单
静态安全的安全防卫,防止误用内存管理机制
和GC型语言有充足的竞争力
在我下面要展示的benchmark中,Rust用一个很容易写的代码轻松击败了Java的无锁实现。
我在一个新的叫 crossbeam 的库中实现了“基于分代的内存回收(epoch-based memory reclamation)”,已经可以在你的数据结构中用了。本文会包含一些无锁数据结构,分代算法,和Rust API的背景知识。
Benchmark
在深入API设计和分代回收的使用前,我们先直入主题:性能。
为了测试我的Crossbeam执行GC时的开销,我基于它实现了一个基础的无锁队列(Michael-Scott 队列),并且用scala实现了相同的队列。通常来说,基于JVM的语言对于无锁数据结构是“优秀的GC”的一个优秀的测试场景。
作为这些实现的补充,我们对比了:
- 一个更高效的分段式队列:会分配节点(node)到多个槽(slot)中,我用Rust基于Crossbeam实现了这个队列。
- 一个被Mutex保护的Rust单线程队列。
- 一个 java.util.concurrent的队列的实现(ConcurrentLinkedQueue)实际上是一个Michael-Scott 队列的优化变种。
我用两种方式测试这些队列:
多生产,单消费场景:2个线程持续发送消息,1个线程接受消息,二者都在一个密集的循环中执行。
多生产,多消费场景:2个线程持续发送消息,2个线程接受消息,二者都在一个密集的循环中执行。
像这样的Benchmark对于衡量一个无锁结构在多线程的竞争下的可扩展性非常有代表性——多个线程竞争以同时并发更新。构建生产级队列实现时,应benchmark多个变种,它的目的是衡量内存管理机制的损耗。
对于MPSC的测试,我也会对比Rust内置channel中用的算法,它对这种场景(MPSC,它不支持MPMC)有优化。测试机是4核,2.6GHz, Intel Core i7 16G内存。
这里是结果: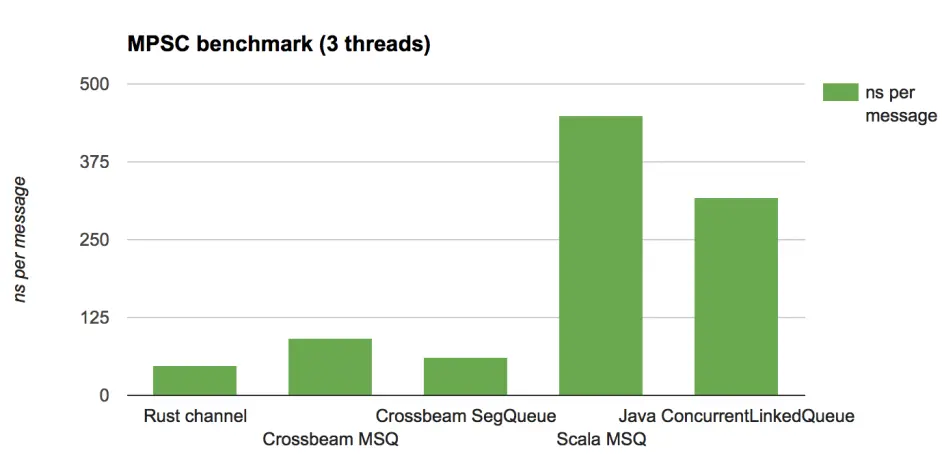
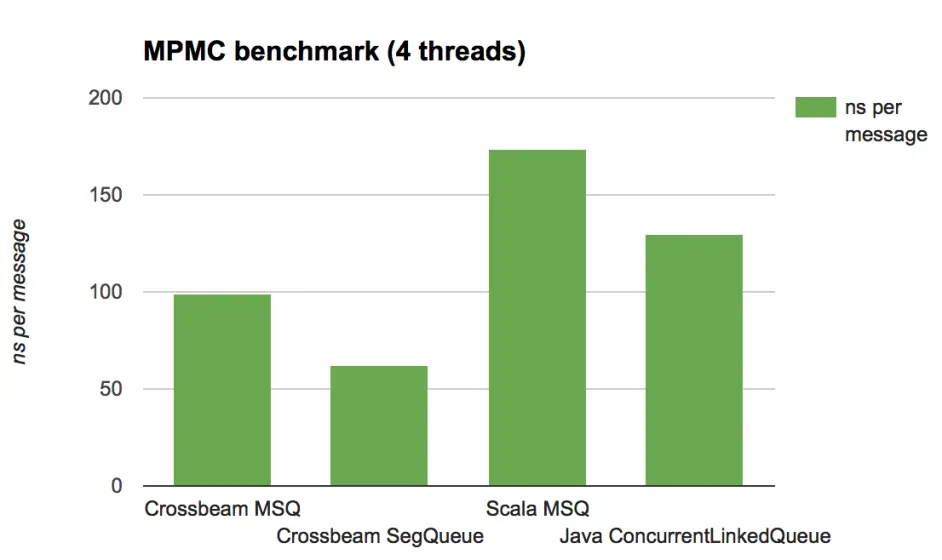
分析
我们主要讨论Crossbeam的实现——实际上还没有优化——在所有场景下都很有竞争力。在Rust和JVM侧都有可能使用一些更聪明和特殊的队列,但是这些结果显示,至少他们的损耗是合理的。
注意,Java/Scala版本MPMC测试比MPSC测试结果好的多,为什么呢?
答案很简单:垃圾回收。在MPSC测试中,生产者生产超过了消费速率,这意味着队列的数据将缓慢增长。这将会增大每次垃圾回收的损耗,因为它会遍历所有数据集。
在分代体系中,管理内存的损耗是相对固定的:它与线程数量成正比,而不是和活跃的数据量。这会带来更好的,更可预测的性能。
最后,我们没有包含的一项对比(因为这会让其他的柱状图看起来太矮了)是Rust中使用Mutex包着Deque。对于MPMC测试性能在3040ns/ops祖佑,比crossbeam慢上20倍。这可以说是为何无锁结构如此重要的完美诠释,让我们开始看下它们到底是啥吧。
无锁数据结构
当你想从多个线程使用(并且修改)一个数据结构时,你需要同步。最简单的方法是一个全局锁,在Rust中,就是把数据结构整个包装在一个Mutex中,然后就完事了。
问题是,这种粗糙的同步意味着多个线程访问数据结构时总是需要协调,即使是访问某些脱节的数据也是如此。这也意味着即使仅有一个线程尝试读,也会产生写操作:更新锁状态,由于这个锁是全局单点,这些写操作也会给CPU总线带来大量缓存失效的流量。即使你使用了大量细粒度的锁也会带来死锁,优先级错乱的危害,你可能还是没能解决性能问题。
一个更激进的选择是无锁数据结构,它使用原子操作来直接修改数据结构,不会有更近一步的同步,它们通常比基于锁的设计更快,更可扩展,更鲁棒。
这篇文章不会给出一个无锁编程的全面教程,核心观念是如果没有全局锁,想确定何时释放内存是很困难的。许多公布的算法基本都会假定存在一个“垃圾回收器(GC)”或者其他什么回收内存的东西。所以在我们真正用Rust搞无锁并发之前,我们需要讨论下内存回收的故事,这个这篇文章要讨论的东西。
Treiber栈
说点实在的,我们看下无锁数据结构的“hello world” : Treiber栈。这个栈看起来像个单向链表,所有修改都发生在头节点:
#![feature(box_raw)]use std::ptr::{self, null_mut};use std::sync::atomic::AtomicPtr;use std::sync::atomic::Ordering::{Relaxed, Release, Acquire};pub struct Stack<T> {head: AtomicPtr<Node<T>>,}struct Node<T> {data: T,next: *mut Node<T>,}impl<T> Stack<T> {pub fn new() -> Stack<T> {Stack {head: AtomicPtr::new(null_mut()),}}}
从pop开始最简单。要pop,你只需要做loop循环,获取一个head的快照,然后做compare-and-swap用下一个指针替换掉快照就可以了。
注意:compare_and_swap 如果老值匹配,将原子替换AtopmicPtr的值从老值到新值。另外这篇文章不讨论Acquire, Release,Relaxed,你如果不熟悉 可以忽略它们。
impl<T> Stack<T> {pub fn pop(&self) -> Option<T> {loop {// take a snapshotlet head = self.head.load(Acquire);// we observed the stack emptyif head == null_mut() {return None} else {let next = unsafe { (*head).next };// if snapshot is still good, update from `head` to `next`if self.head.compare_and_swap(head, next, Release) == head {// extract out the data from the now-unlinked node// **NOTE**: leaks the node!return Some(unsafe { ptr::read(&(*head).data) })}}}}}
ptr::read是Rust中在没有静态/动态追踪的情况下提取数据所有权的方式。
- 我们此处用到compare_and_swap的原子性来保证只有一个线程会调用ptr::read
- 此实现永远不会释放Node,所以调用data的释放函数永不会被调用。
以上两点保证我们能安全地调用ptr::read。
push也十分类似:
impl<T> Stack<T> {pub fn push(&self, t: T) {// allocate the node, and immediately turn it into a *mut pointerlet n = Box::into_raw(Box::new(Node {data: t,next: null_mut(),}));loop {// snapshot current headlet head = self.head.load(Relaxed);// update `next` pointer with snapshotunsafe { (*n).next = head; }// if snapshot is still good, link in new nodeif self.head.compare_and_swap(head, n, Release) == head {break}}}}
问题
如果我们在有GC的语言里编写了上面的代码,我们已经完工了,但是我们写的是Rust,这就会导致内存泄漏。具体来说,pop的实现从Stack上移除node时,没有去释放node指针导致的。
假如我们这么做了会发生什么呢?
// extract out the data from the now-unlinked nodelet ret = Some(unsafe { ptr::read(&(*head).data) });// free the nodemem::drop(Box::from_raw(head));return ret
问题是其他线程可能也在通知执行pop,那些线程可能已经有了一个快照,在我们是否这个节点后,没有任何东西能阻止这个线程用这个快照读 (*head).next,use-after-free的bug就产生了。
这就是难点了。我们想使用无锁算法,但是大多都跟上面的stack类似,我们没有一个清晰的时间节点可以安全的删除一个节点,这该怎么办?
Epoch-based reclamation
目前有几种不是基于GC的方式能在无锁的情况下管理内存,他们都满足下面几个规则:
- 有两个访问数据结构的方式:数据结构,和其他线程的对数据结构的快照,在我们删除一个节点之前,我们必须知道它不会以上面的任何方式访问了。
- 一旦一个节点断开同数据结构的连接,不再有新的能访问到它的快照产生。
其中一个最优雅有希望的回收体系是Keir Fraser的epoch-based reclamation,他在他的PhD论文中非常详细的描述了这个体系。
这个体系的基本思想是把数据结构(第一个可达性)中断开链接(unlink)的节点隐藏起来,直到他们可以被安全的删除。在我们能删除一个被隐藏的节点之前,我们必须知道所有所有访问这个数据结构的线程此时已经完成了他们的操作。这意味着没有任何快照了(并且此时也没有线程会创建新的快照了)。困难的部分是在没有锁的前提下做到上面的几点。否则我们将失去我们用无锁本来的目的了。
Epoch体系工作的基础是:
一个全局分代计数器,可取值0,1,2
每个epoch配置一个垃圾链表
每个线程配置一个活跃标记
每个线程自己有一个分代计数器,取值也是0,1,2
分代的目的是当没有线程访问,垃圾可以被安全地释放时,可以被发现。不同于传统GC,它不要求遍历全部活跃数据,它纯粹就是检测分代计数器。
当一个线程想给此线程提交一个操作。它首先标记自己为active,然后更新自己的epoch计数器和全局计数器相同。如果线程从数据结构中删除一个节点,它会把节点加到当前全局分代的垃圾链表中(注意,此处将垃圾加到全局分代链表而不是自己的分代的链表很重要),当他完成自己的操作时,清空活跃标记。
当尝试回收垃圾时(这个操作什么时候都能做),一个线程遍历所有参与的线程的活跃标记,检测是否所有线程在当前分代。如果是,它将尝试对全局分代计数增加1(最终对3取模)。如果增加成功,两代之前的垃圾就可以被回收了。
为什么我们会需要分代,因为“垃圾回收”是并发完成的,任何时候都可能有线程在两代里(新的和老的)。但是我们增加全局分代前会检测所有活跃线程都在老分代里,我确认没有线程会在第三个分代里。
这个体系设计得很小心,大部分时候,访问数据的线程已经缓存的数据或者在threadlocal。做GC实际上就是修改下全局计数或者读一下别的线程的计数。分代法的算法透明,方便使用,性能可以与其他方法匹敌。
它和Rust所有权系统也十分匹配。
Rust API
我们希望Rust API反馈 分代回收机制的基本原则。
- 当操作共享数据时,线程必须在“活跃”状态
- 当一个线程是活跃状态,所有从数据结构中读出的数据,将保留到线程“不活跃”为止。
只要满足了epoch API的约束,我们就受影响于Rust所有权系统,所有权基于资源管理系统(也叫RAII)。这会帮助我们正确地使用epoch管理体系。
Guard
如果要操作一个无锁数据结构,你首先要申请一个guard,它是一个有所有权的值,表示当前线程被标记为“活跃”。
pub struct Guard { ... }pub fn pin() -> Guard;
pin函数标记当前线程为活跃,并且加载全局分代,也会尝试GC(细节后面详述)。Guard的析构通过标记当前线程为“不活跃”来退出分代管理。
由于 Guard 代表了“活跃” ,guard的引用 &’a Guard 也保证线程在 ‘a 的整个生命周期里是活跃的,这正是我们在无锁算法里需要给快照绑定的生命周期。
要用这个guard,Crossbeam提供了三个指针类型:
Owned ,和Box 类似,指向了并发数据结构中那些还没被公开的独占的数据。
Shared<’a,T>,和&’a T 类似,指向了共享数据,这些数据对于数据结构可能可达,也可能不可达,但是Crossbeam保证在 ‘a 期间它不会被释放。
Atomic 类似于 std::sync::atomic::AtomicPtr ,为Shared和Owned提供指针原子更新,并且将它们和Guard关联在一起。
我们逐个看下这些东西:
Owned和Shared指针
Owned指针有类似Box的api
pub struct Owned { ... }impl Owned {pub fn new(t: T) -> Owned;}impl Deref for Owned {type Target = T;...}impl DerefMut for Owned { ... }
Shared<’a,T>指针类似于&’a T,它是Copy的,但他会解引用为&’a T。这是一种传达它的生命周期是‘a的hacky的方式。不同于Owned,我们没有办法直接创建Shared。相反,Shared指针应从Atomic中读,我们后面会看到。
Atomic
这个库的核心就是Atomic,它提供了访问可空指针的原子操作,它把库中其他的类型连在一起:
pub struct Atomic { ... }impl Atomic {/// Create a new, null atomic pointer.pub fn null() -> Atomic;}
我们逐个看下这些精心设计的API
Loading
首先,从Atomic中load:
impl Atomic {pub fn load<'a>(&self, ord: Ordering, _: &'a Guard) -> Option<Shared<'a, T>>;}
为了执行这个load操作,我们必须传入一个Guard。正如上面解释的,这是保证线程在整个’a生命周期内都处于激活状态的方式。它将返回一个生命周期被绑定给guard的Option的Shared指针(如果Atomic当前是null的话就是None)。
比较这个Atomic和标准库load时返回*mut T的AtomicPtr非常有趣。由于用了分代,我们可以保证解引用’a 的指针是安全的,而标准库的AtomicPtr没有任何这种保证。
Storing
写操作(store)因为这几个指针类型会更复杂些。
如果我们只是想写一个Owned指针或者null值,我们甚至不需要当前线程为“活跃”,我们只需要把所有权转移到数据结构中就可以了,不需要指针的生命周期的任何保证。
impl Atomic {pub fn store(&self, val: Option<Owned>, ord: Ordering);}
有时,我们想把所有权转移到数据结构中,并且立刻尝试获取Shared指针,例如我们想给数据结构中的节点加个链接,在那种情况下我们必须把Shared的生命周期和guard绑定。
impl Atomic {pub fn store_and_ref<'a>(&self,val: Owned,ord: Ordering,_: &'a Guard)-> Shared<'a, T>;}
注意val的运行时表现和返回值的是完全一样的,我们传了一个指针进去,它又把相同的指针返回出来了。但是所有权的情况这时却彻底改变了。
最后,我们还能存一个共享指针到数据结构中:
impl Atomic {pub fn store_shared(&self, val: Option<Shared>, ord: Ordering);}
这个操作不要求guard,这是因为我们也没学到任何有关指针生命周期的东西(译:裸指针不携带生命周期信息)。
CAS
这个我们有些非常相似的操作,最简单的场景就是用一个新型的Owned指针交换Shared指针。
impl Atomic {pub fn cas(&self,old: Option<Shared>,new: Option<Owned>,ord: Ordering)-> Result<(), Option<Owned>>;}
跟store一样,这个操作也不需要guard,它不产生新的生命周期。Result表明CAS是否成功,如果没有,新指针的所有权还是会返回给调用方。
我们再讨论一个衍生物 store_and_ref:
impl Atomic {pub fn cas_and_ref<'a>(&self,old: Option<Shared>,new: Owned,ord: Ordering,_: &'a Guard)-> Result<Shared<'a, T>, Owned>;
在这种情况下,成功的CAS返回Shared指针指向我们刚插入的数据。
最后我们可以用一个Shared指针替换另一个
impl Atomic {pub fn cas_shared(&self,old: Option<Shared>,new: Option<Shared>,ord: Ordering)-> bool;}
返回true时代表cas成功了。
释放内存
当然,所有上面的组件都是服务于共同的目标:释放不可达内存。当一个节点从数据结构中断开链接后,将其断开链接的线程可以提醒guard,内存应该回收了。
impl Guard {pub unsafe fn unlinked(&self, val: Shared);}
此操作添加Shared指针到相关垃圾链表,允许它两代后被回收。
此操作是unsafe,这是因为它假定:
此 Shared 指针在数据结构中不可达
没有别的线程会调用unlinked
重要的是,其他线程可能会继续引用这个Shared,分代系统必须在此指针被真正释放前保证没有线程这么做。
此处的Shared指针和Guard没有生命周期关联,如果我们有可达的Shared指针,我们就知道此指针来自的guard已经活跃了。
基于分代的Treiber栈
不用怀疑,这就是使用crossbeam epoch API 构建的Treiber栈的代码
use std::sync::atomic::Ordering::{Acquire, Release, Relaxed};use std::ptr;use crossbeam::mem::epoch::{self, Atomic, Owned};pub struct TreiberStack<T> {head: Atomic<Node<T>>,}struct Node<T> {data: T,next: Atomic<Node<T>>,}impl<T> TreiberStack<T> {pub fn new() -> TreiberStack<T> {TreiberStack {head: Atomic::new()}}pub fn push(&self, t: T) {// allocate the node via Ownedlet mut n = Owned::new(Node {data: t,next: Atomic::new(),});// become activelet guard = epoch::pin();loop {// snapshot current headlet head = self.head.load(Relaxed, &guard);// update `next` pointer with snapshotn.next.store_shared(head, Relaxed);// if snapshot is still good, link in the new nodematch self.head.cas_and_ref(head, n, Release, &guard) {Ok(_) => return,Err(owned) => n = owned,}}}pub fn pop(&self) -> Option<T> {// become activelet guard = epoch::pin();loop {// take a snapshotmatch self.head.load(Acquire, &guard) {// the stack is non-emptySome(head) => {// read through the snapshot, *safely*!let next = head.next.load(Relaxed, &guard);// if snapshot is still good, update from `head` to `next`if self.head.cas_shared(Some(head), next, Release) {unsafe {// mark the node as unlinkedguard.unlinked(head);// extract out the data from the now-unlinked nodereturn Some(ptr::read(&(*head).data))}}}// we observed the stack emptyNone => return None}}}}
一些结论
这个算法的基本逻辑和前面那个依赖GC的版本一样,除了我们显示的将pop出的节点标记的unlinked。总的来说,直接用现成的无锁算法是有可能的(我们现写的算法依赖GC)我们直接用Crossbeam把它们实现了。
我们取完快照后,我们可以不用unsafe解引用了,因为guard保证它的存活。
用compare-and-swap来保证只有一个线程调用 ptr::read ,并且epoch回收系统不会运行析构,仅仅回收内存。
关于回收最后一点需要多说一些,所以我们以讨论垃圾来收尾API描述这节。
垃圾管理
Crossbeam的设计理念是把分代管理当作所有数据结构共享的一个服务,有一个全局静态的分代计数和每个线程一个threadlocal。由于不需要为每个数据结构执行setup, 这令epoch API用起来非常简。这也意味着epoch的空间占用只跟线程数相关和数据结构数无关。
crossbeam实现的和现有的epoch论文的不同就是:crossbeam每个线程配置的自己的垃圾链表。这意味着,当我们调用unlinked时,此节点将被加入到threadlocal的区域,而不是全局垃圾链表中(这会减少一些额外的同步)。
每次你调用epoch::pin() ,当前线程都会检测释放本地垃圾超过了回收阈值,如果超过了,分代系统会开始收集。同时,任何时候你调用epoch::pin() 如果此时全局计数大于thread的快照,当前线程就会收集一些自己的垃圾。为了避免垃圾列表的全局同步,这个系统将垃圾收集的工作分给所有访问数据的线程。
由于GC只能在所有线程都在当前代的时候发生,不可能总是能收集垃圾。但是在实际应用中,某个线程的垃圾很少会超过阈值。
这里需要注意:如果线程退出,它必须对它的垃圾做些什么,否则GC可能失败。所以crossbeam的实现还加了全局垃圾链表,作为线程退出后,垃圾处理的最后一个防线。这些全局垃圾链表是在线程成功增加全局分代时收集的。
最后,“收集”垃圾到底是什么意思?正如前面说的,此库只释放内存,不会运行析构。
概念上讲,框架将对象的析构分为两部分:1. 释放/移动内部的数据,2. 释放保护这个结构的对象。前者在调用unlinked时候就会发生,此时仅有一个线程拥有对象,但是没有能力真正释放它。后者发生在当此对象明确不在被引用后,不确定的时候。这就抛给用户一个责任:通过快照访问数据在释放前只能读。但是这是那些倾向于把数据和容器有清晰分界的无锁结构里常见的情况。
用这种方式切分对象,意味着析构在可预测的时间内会被同步执行,缓解了GC的一个痛点,允许框架使用非’static 和非 Send数据。
前面的路
crossbeam还是项目初期。目前的工作主要是为探索大量Rust无锁数据结构打好基础,我希望crossbeam最终能为Rust扮演类似java中java.util.concurrent的角色:包含hashmap,工作窃取队列,和轻量任务引擎。如果你对此有兴趣,我希望能帮上忙。
译注:本文是crossbeam 刚出来时写的,里面的一些概念可能已经废弃了(如unlink),但是基本思想是没变的。

若有收获,就点个赞吧
0 人点赞
