引言
如你所知,Java是一门面向对象的编程语言。我们平常在写代码的时候也是在不停的操作各种对象,那么当你在写出User user = new User();这样一行代码的时候,JVM都做了些什么呢?
了解对象
内存布局
在Hotspot虚拟机中一个对象的内存布局分为三个部分:对象头、实例数据、对齐填充。
对象头又有两部分的信息,第一部分是用于存储对象自身的运行数据(HashCode、GC分代年龄、锁状态标志等)。另一部分是类型指针,指向它的类元数据,虚拟机通过这个指针确定这个对象是哪个类的实例(如果使用句柄池方式则不会有)。如果是数组还会有一个记录数组长度的如下表所示:
| 内容 | 说明 |
|---|---|
| Mark Word | 对象的hashCode或锁信息等 |
| Class Metadata Address | 对象类型数据指针 |
| Array length | 数组长度 |
Mark Word是一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。各状态下的存储内容如下表所示:
| 标志位 | 状态 | 存储内容 |
|---|---|---|
| 01 | 未锁定 | 对象HashCode、分代年龄 |
| 00 | 轻量级锁定 | 指向锁记录的指针 |
| 10 | 重量级锁定 | 指向锁记录的指针 |
| 11 | GC标记 | 空 |
| 01 | 可偏向 | 偏向线程ID、偏向时间戳、对象分代年龄 |
实例数据**部分是正在存储的有效信息,就是在代码中定义的各种类型的字段内容。无论是父类继承下来的,还是在子类中的。
对齐填充不是必须存在的,仅仅起着占位符的作用,因为HotSpot虚拟机要求对象的起始地址必须是8字节的整数倍。
**
对象访问
Java程序中我们操作一个对象是通过指向这个对象的引用。我们都知道对象存在堆中,这个引用存在虚拟机栈中。那么引用通过什么方式去定位堆中对象的位置呢?
直接指针法(HotSpot实现):引用中直接存储的就是堆中对象的地址。好处就是一次定位速度快,缺点是对象移动(GC时对象移动)引用本身需要修改。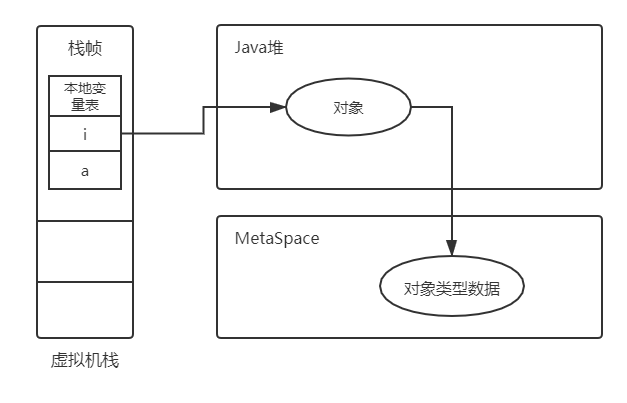
句柄法:Java堆中划分出一部分作为句柄池,引用存储的是对象的句柄地址,而句柄中包括了对象实例和类型的具体位置信息。好处是对象移动只会改变句柄中的实例数据指针,缺点是两次定位。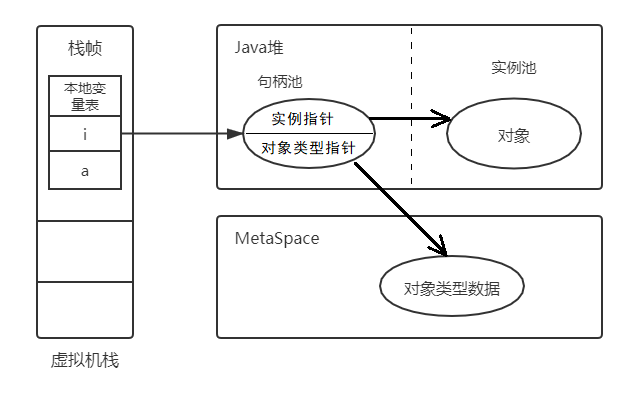
创建对象流程
上面介绍了对象的基本信息,现在来讲一讲创建对象的流程:
- 当虚拟机遇到一条new指令时,会去检查这个指令的参数能否在常量池中定位到一个类的符号引用,并检查代表的类是否已经被类加载器加载。如果没有被加载那么必须先执行这个类的加载。
- 类加载检查通过后,虚拟机将为新对象分配内存,对象所需内存的大小在类加载后便可以确定。
- 内存分配完成后,虚拟机需要将对象初始化为零值,保证对象的实例变量在代码中不赋初始值就能直接使用。类变量在类加载的准备阶段初始化为零值。
- 对对象头进行必要信息的设置,比如如何找到类的元数据信息、对象的HashCode、GC分代年龄等。
- 经过上述操作,一个新的对象已经产生,但是
方法还没有执行,所有的字段都是零值。这时候需要执行 方法(构造方法)把对象按照程序员的意愿进行初始化。类变量的初始化操作在类加载的初始化阶段 方法完成;
分配内存有两种方式:
- Java堆内存是规整的(使用标记整理或带压缩的垃圾收集器),使用一个指针指向空闲位置,分配内存既将指针移动与分配大小相等的距离
- 内存不是规整的(使用标记清除的垃圾收集器),虚拟机维护一个可用内存块列表,分配内存时从列表中找到一个足够大的内存空间划分给对象并更新可用内存列表。
无法找到足够的内存时会触发一次GC。
分配内存时并发问题解决方案:
- 对分配内存空间的动作进行同步操作—-采用CAS失败重试的方式保证更新操作的原子性。
- 每个线程在堆中预先分配一块小内存,称为本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),哪个线程要分配内存就在它的TLAB上分配,只有TLAB用完并分配新的TLAB时才需要同步锁定。通过-XX:+/-UseTLAB参数来设定。
创建对象指令重排序问题
A a = new A();
new一个对象的简单分解动作:
- 分配对象的内存空间
- 初始化对象
- 设置引用指向分配的内存地址
其中2、3两步间会发生指令重排序,导致多线程时如果在初始化之前访问对象则会出现问题,单例模式的双重检测锁模式正是会存在这个问题。可以使用volatile来禁止指令重排序解决问题

若有收获,就点个赞吧
0 人点赞
