引言
不同与我们之前介绍的线性结构,今天我们介绍一种非线性结构:树,本章重点介绍树与二叉树的基础必会内容,在开始这一章节前,请思考以下内容:
- 什么是树?
- 什么是二叉树?
- 什么是平衡二叉树?
- 在代码中如何表示一棵二叉树?
- 二叉树的前序、中序、后序遍历又是什么?如何实现?能否用递归及迭代两种方式实现喃?
- 什么是 BST 树?
- 什么是 AVL 树?
- 什么是红黑树?
- 什么是 Trie 树?
- 什么是 B 、B+ 树?
下面进入本节内容👇
8.1 树
不同于我们上面介绍的线性结构,树是一种非线性结构。
图:
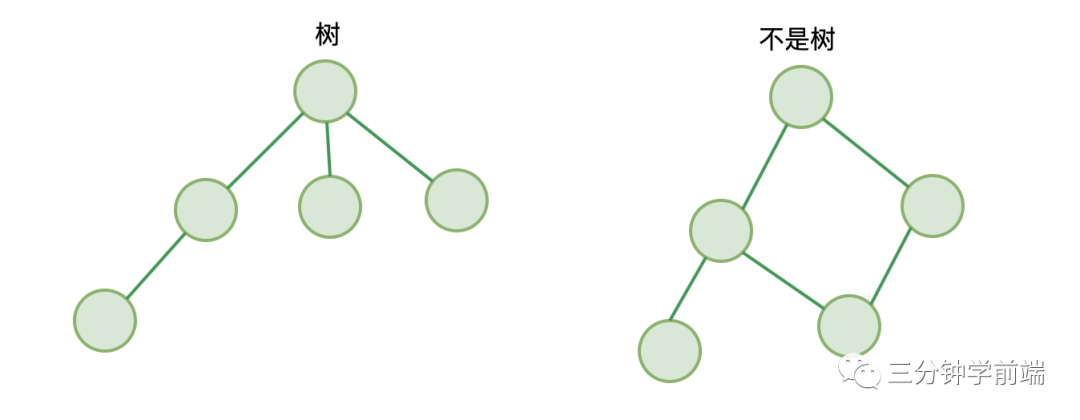
它遵循:
- 仅有唯一一个根节点,没有节点则为空树
- 除根节点外,每个节点都有并仅有唯一一个父节点
- 节点间不能形成闭环
这就是树!
树有几个概念:
- 拥有相同父节点的节点,互称为兄弟节点
- 节点的深度 :从根节点到该节点所经历的边的个数
- 节点的高度 :节点到叶节点的最长路径
- 树的高度:根节点的高度
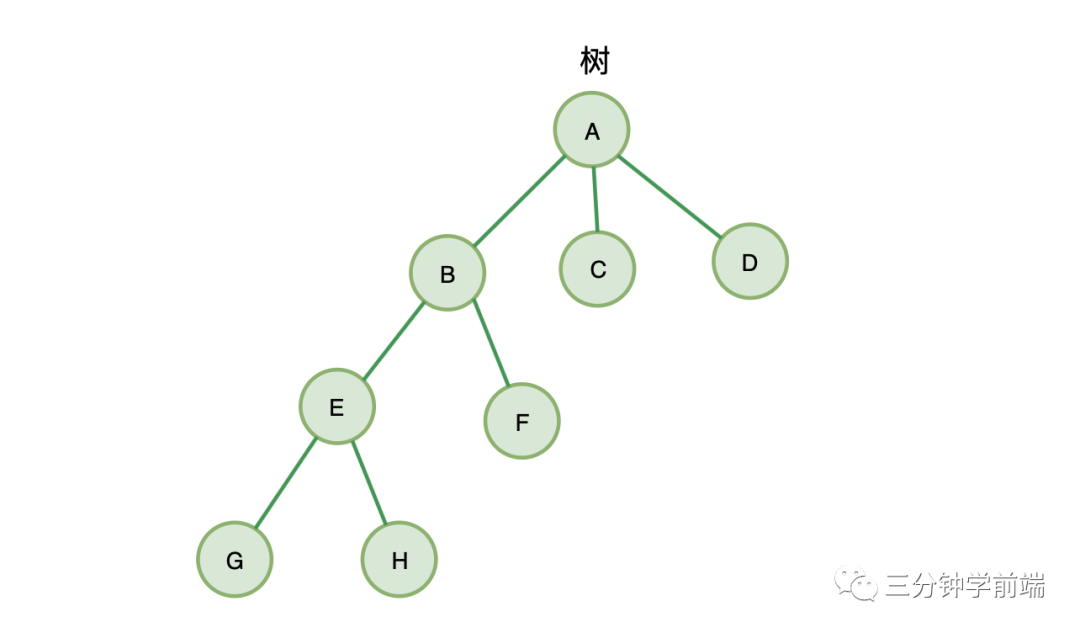
B、C、D就互称为兄弟节点,其中,节点B的高度为2,节点B的深度为 1,树的高度为3
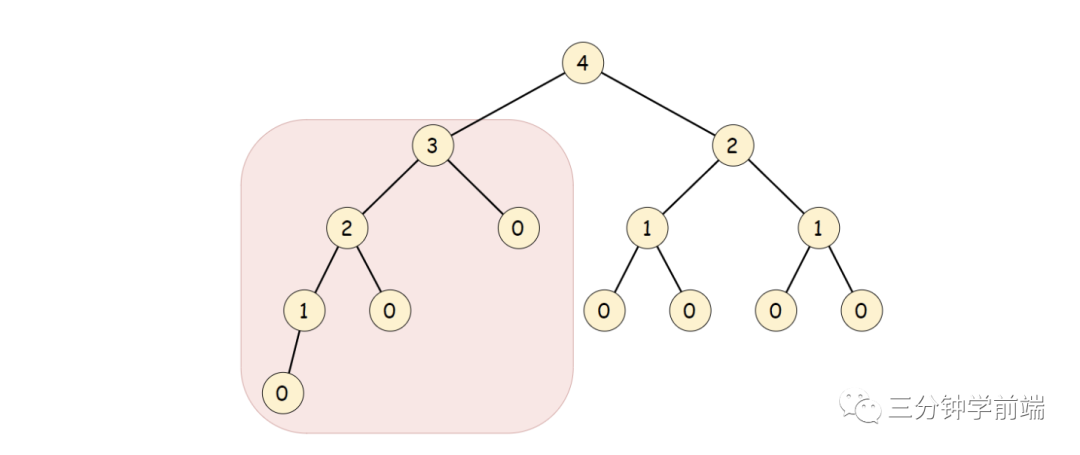
高度
树的高度计算公式:

下图每个节点值都代表来当前节点的高度:
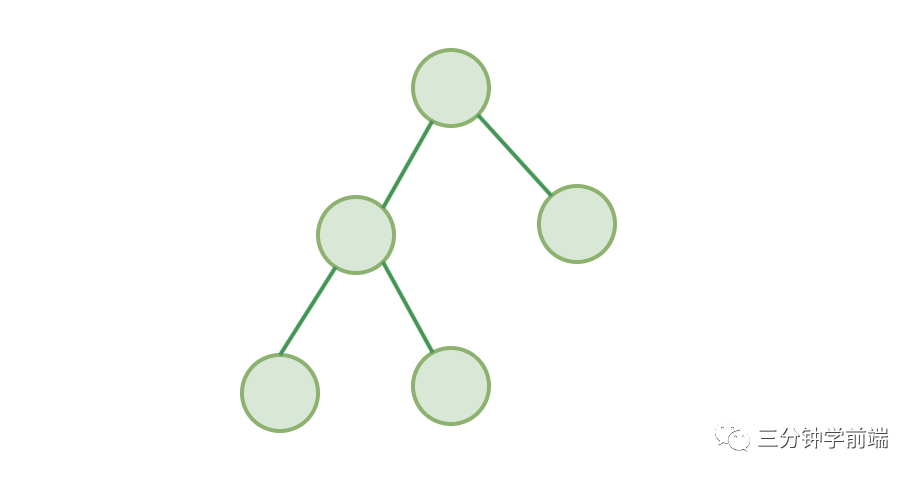
8.2 二叉树
二叉树,故名思义,最多仅有两个子节点的树(最多能分两个叉的树🤦♀️):
图:
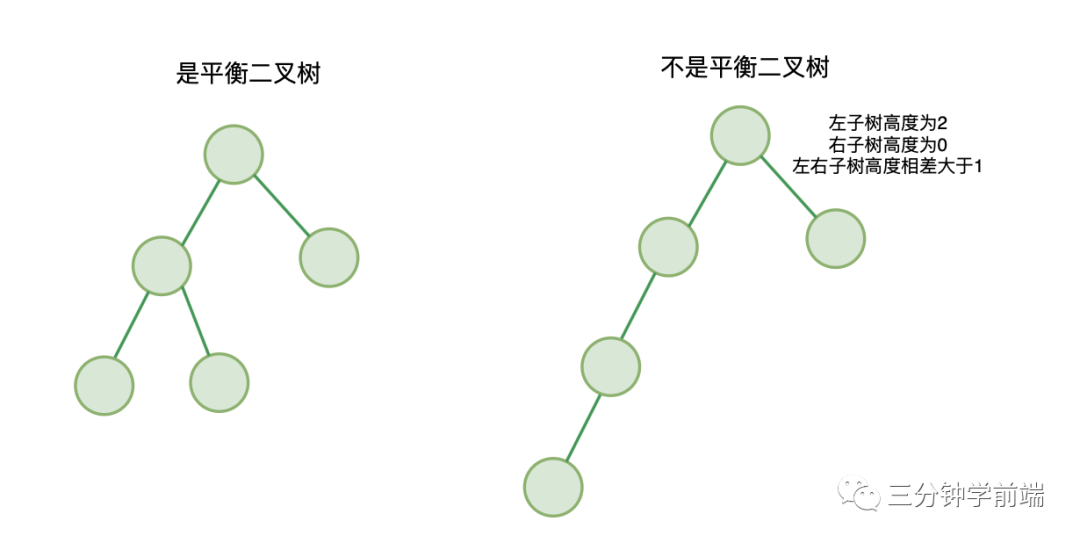
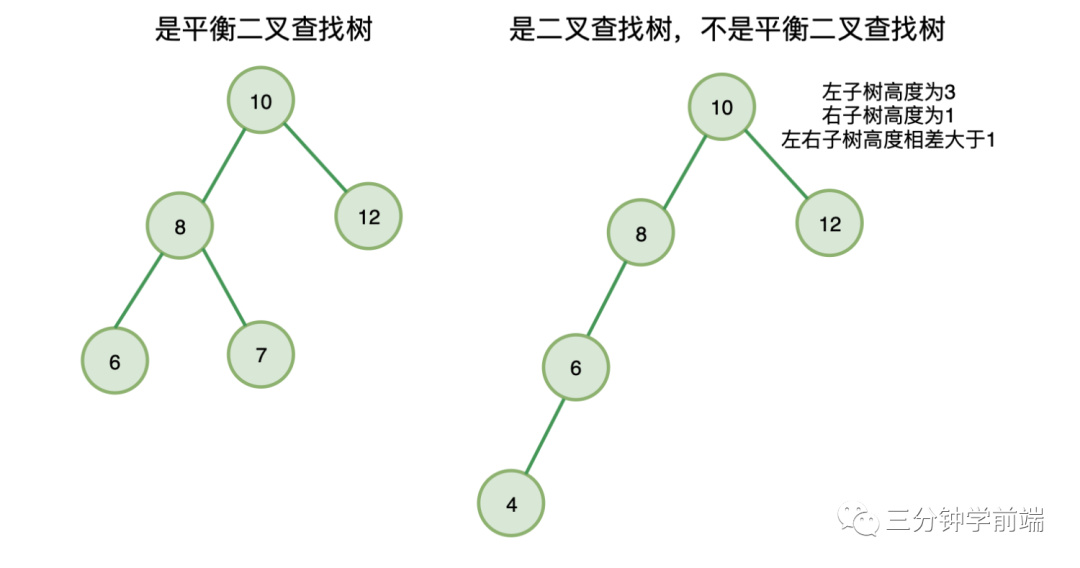
8.3 平衡二叉树
二叉树中,每一个节点的左右子树的高度相差不能大于 1,称为平衡二叉树。
另外还有满二叉树、完全二叉树等:
- 满二叉树:除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树
- 完全二叉树:深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h 层所有的结点都连续集中在最左边
8.4 在代码中如何去表示一棵二叉树
8.4.1 链式存储法
二叉树的存储很简单,在二叉树中,我们看到每个节点都包含三部分:
- 当前节点的 val
- 左子节点 left
- 右子节点 right
所以我们可以将每个节点定义为:
`function Node(val) {// 保存当前节点 key 值this.val = val// 指向左子节点this.left = null// 指向右子节点this.right = null}`
一棵二叉树可以由根节点通过左右指针连接起来形成一个树。
`function BinaryTree() {let Node = function (val) {this.val = valthis.left = nullthis.right = null}let root = null}`
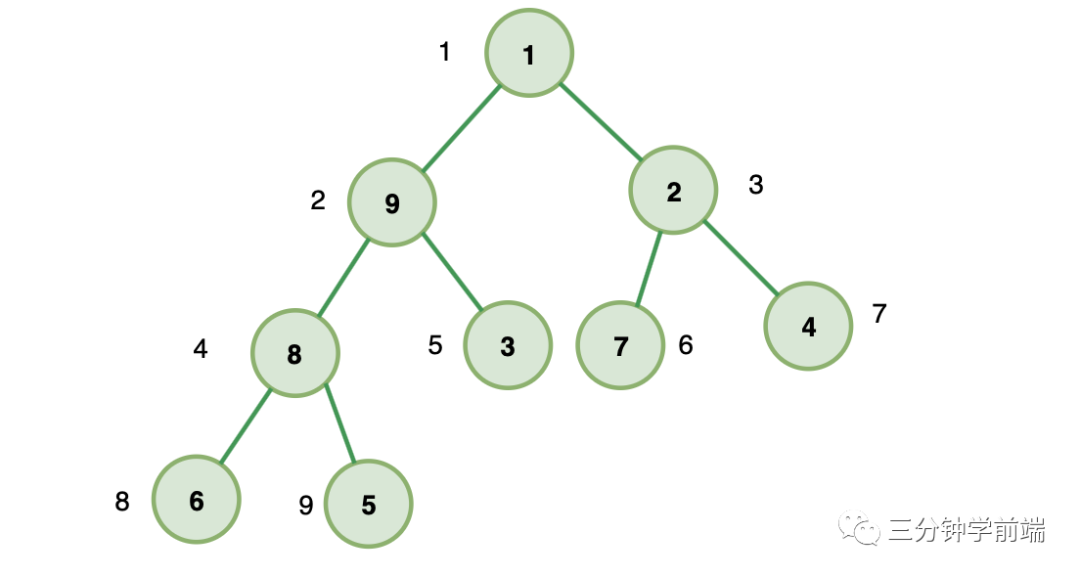
8.4.2 数组存储法(适用于完全二叉树)
下图就是一棵完全二叉树,
如果我们把根节点存放在位置 i=1 的位置,则它的左子节点位置为 2i = 2 ,右子节点位置为 2i+1 = 3 。
如果我们选取 B 节点 i=2 ,则它父节点为 i/2 = 1 ,左子节点 2i=4 ,右子节点 2i+1=5 。
以此类推,我们发现所有的节点都满足这三种关系:
- 位置为 i 的节点,它的父节点位置为
i/2 - 它的左子节点
2i - 它的右子节点
2i+1
因此,如果我们把完全二叉树存储在数组里(从下标为 1 开始存储),我们完全可以通过下标找到任意节点的父子节点。从而完整的构建出这个完全二叉树。这就是数组存储法。
数组存储法相对于链式存储法不需要为每个节点创建它的左右指针,更为节省内存。
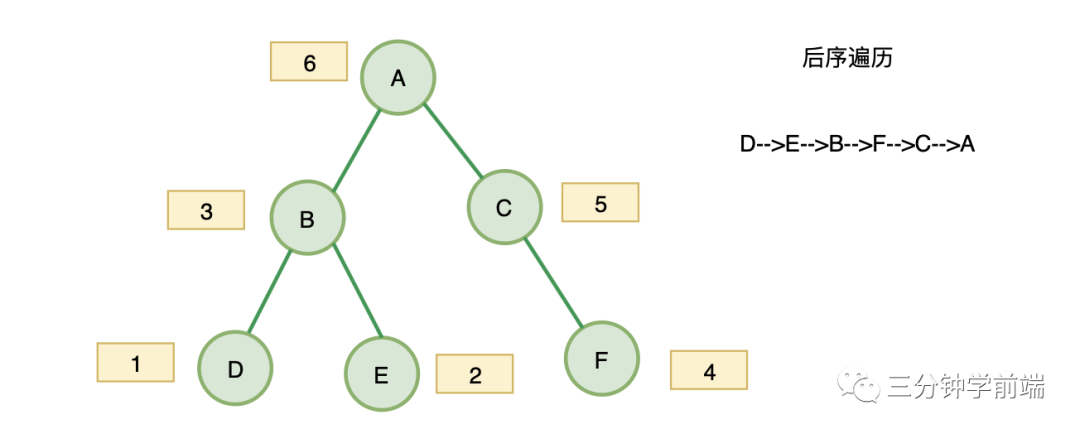
8.5 二叉树的遍历
二叉树的遍历可分为:
- 前序遍历
- 中序遍历
- 后序遍历
所谓前、中、后,不过是根的顺序,即也可以称为先根遍历、中根遍历、后根遍历
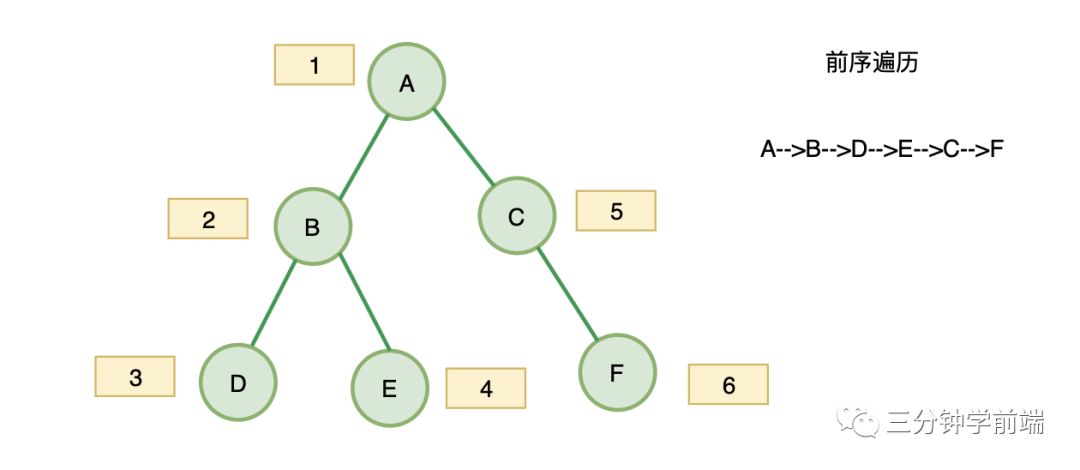
1. 前序遍历
对于二叉树中的任意一个节点,先打印该节点,然后是它的左子树,最后右子树
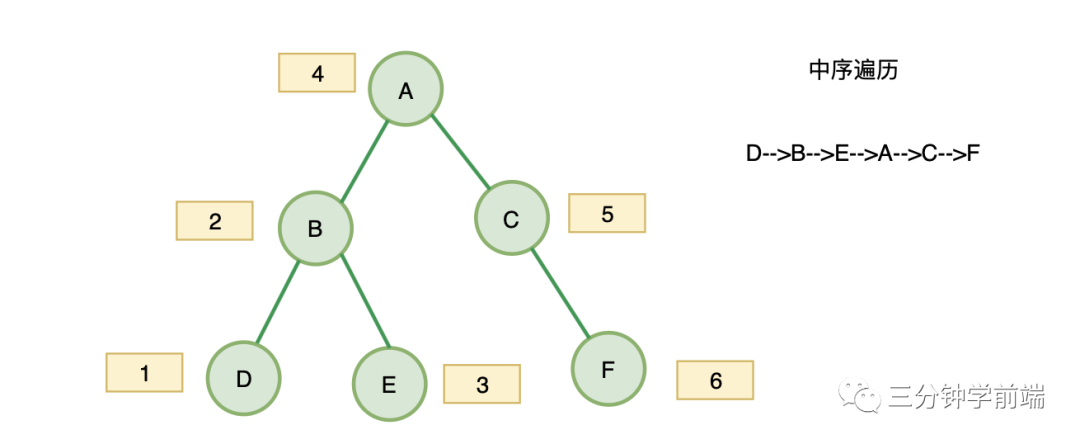
2. 中序遍历
对于二叉树中的任意一个节点,先打印它的左子树,然后是该节点,最后右子树
3. 后序遍历
对于二叉树中的任意一个节点,先打印它的左子树,然后是右子树,最后该节点
4. 代码实现(前序遍历为例)
所以,遍历二叉树的过程也就是一个递归的过程,例如前序遍历,先遍历根节点,然后是根的左子树,最后右子树;遍历根节点的左子树的时候,又是先遍历左子树的根节点,然后左子树的左子树,左子树的右子树…….
所以,它的核心代码就是:
`// 前序遍历核心代码const preOrderTraverseNode = (node) => {if(node) {// 先根节点result.push(node.val)// 然后遍历左子树preOrderTraverseNode(node.left)// 再遍历右子树preOrderTraverseNode(node.right)}}`
完整代码如下:
递归实现
`// 前序遍历const preorderTraversal = (root) => {let result = []var preOrderTraverseNode = (node) => {if(node) {// 先根节点result.push(node.val)// 然后遍历左子树preOrderTraverseNode(node.left)// 再遍历右子树preOrderTraverseNode(node.right)}}preOrderTraverseNode(root)return result};`
我们既然可以使用递归实现,那么是否也可以使用迭代实现喃?
迭代实现
利用栈来记录遍历的过程,实际上,递归就使用了调用栈,所以这里我们可以使用栈来模拟递归的过程
- 首先根入栈
- 将根节点出栈,将根节点值放入结果数组中
- 然后遍历左子树、右子树,因为栈是先入后出,所以,我们先右子树入栈,然后左子树入栈
- 继续出栈(左子树被出栈)…….
依次循环出栈遍历入栈,直到栈为空,遍历完成
`// 前序遍历const preorderTraversal = (root) => {const list = [];const stack = [];// 当根节点不为空的时候,将根节点入栈if(root) stack.push(root)while(stack.length > 0) {const curNode = stack.pop()// 第一步的时候,先访问的是根节点list.push(curNode.val)// 我们先打印左子树,然后右子树// 所以先加入栈的是右子树,然后左子树if(curNode.right !== null) {stack.push(curNode.right)}if(curNode.left !== null) {stack.push(curNode.left)}}return list}`
复杂度分析:
空间复杂度:O(n)
时间复杂度:O(n)
至此,我们已经实现了二叉树的前序遍历,尝试思考一下二叉树的中序遍历如何实现喃?
8.6 二叉查找树(BST树)
有的笔者也称它为二叉搜索树,都是一个意思。
二叉树本身没有多大的意义,直到有位大佬提出一个 trick。
如果我们规定一颗二叉树上的元素拥有顺序,所有比它小的元素在它的左子树,比它大的元素在它的右子树,那么我们不就可以很快地查找某个元素了吗?
不得不说这是一个非常天才的想法,于是,二叉查找树诞生了。
所以,二叉查找树与二叉树不同的是,它在二叉树的基础上,增加了对二叉树上节点存储位置的限制:二叉搜索树上的每个节点都需要满足:
- 左子节点值小于该节点值
- 右子节点值大于等于该节点值
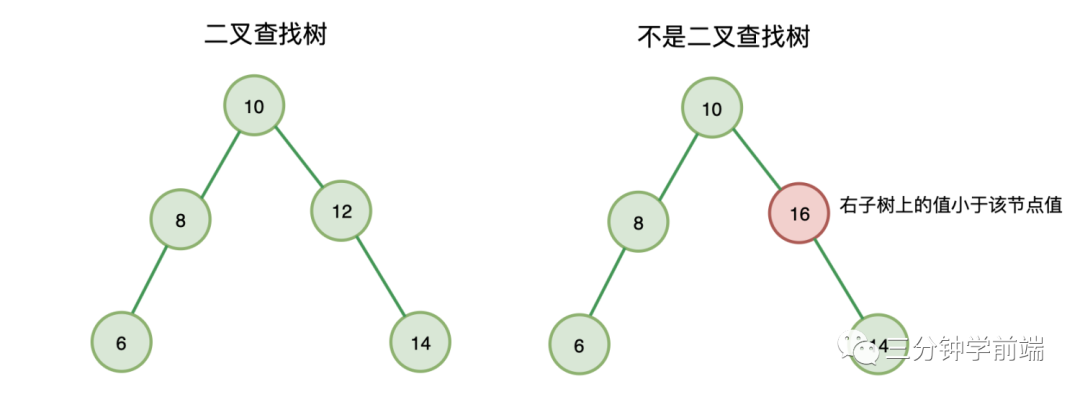
在二叉树中,所有子节点值都是没有固定规律的,所以使用二叉树存储结构存储数据时,查找数据的时间复杂度为 O(n),因为它要查找每一个节点。
而使用二叉查找树就不同了,例如上图,我们如果要查找 6 ,先从根节点 10 比较,6 比 10 小,则查找左子树,再与 8 比较,6 比 8 小,继续查找 8 的左子树,也就是 6,我们找到了元素,结束。
8.6.1 基本操作
`function BinarySearchTree() {let Node = function (key) {this.key = keythis.left = nullthis.right = null}let root = null// 插入this.insert = function(key){}// 查找this.search = function(key){}// 删除this.remove = function(key){}// 最大值this.max = function(){}// 最小值this.min = function(){}// 中序遍历this.inOrderTraverse = function(){}// 先序遍历this.preOrderTraverse = function(){}// 后序遍历this.postOrderTraverse = function(){}}`
插入:
- 首先创建一个新节点
- 判断树是否为空,为空则设置插入的节点为根节点,插入成功,返回
- 如果不为空,则比较该节点与根结点,比根小,插入左子树,否则插入右子树
`function insert(key) {// 创建新节点let newNode = new Node(key)// 判断是否为空树if(root === null) {root = newNode} else {insertNode(root, newNode)}}// 将 insertNode 插入到 node 子树上function insertNode(node, newNode) {if(newNode.key < node.key) {// 插入 node 左子树if(node.left === null) {node.left = newNode} else {insertNode(node.left, newNode)}} else {// 插入 node 右子树if(node.right === null) {node.right = newNode} else {insertNode(node.right, newNode)}}}`
最值:
最小值:树最左端的节点
最大值:树最右端的节点
`// 最小值function min() {let node = rootif(node) {while(node && node.left !== null) {node = node.left}return node.key}return null}// 最大值function max() {let node = rootif(node) {while(node && node.right !== null) {node = node.right}return node.key}return null}`
查找:
`function search(key) {return searchNode(root, key)}function searchNode(node, key) {if(node === null)return falseif(key < node.key) {return searchNode(node.left, key)} else if(key > node.key) {return searchNode(node.right, key)} else {return true}}`
删除:
`function remove(key) {root = removeNode(root, key)}function removeNode(node, key) {if(node === null)return nullif(key < node.key) {return removeNode(node.left, key)} else if(key > node.key) {return removeNode(node.right, key)} else {// key = node.key 删除//叶子节点if(node.left === null && node.right === null) {node = nullreturn node}// 只有一个子节点if(node.left === null) {node = node.rightreturn node}if(node.right === null) {node = node.leftreturn node}// 有两个子节点// 获取右子树的最小值替换当前节点let minRight = findMinNode(node.right)node.key = minRight.keynode.right = removeNode(node.right, minRight.key)return node}}// 获取 node 树最小节点function findMinNode(node) {if(node) {while(node && node.right !== null) {node = node.right}return node}return null}`
8.6.2 遍历
中序遍历:
顾名思义,中序遍历就是把根放在中间的遍历,即按先左节点、然后根节点、最后右节点(左根右)的遍历方式。
由于BST树任意节点都大于左子节点值小于等于右子节点值的特性,所以 中序遍历其实是对🌲进行排序操作 ,并且是按从小到大的顺序排序。
`function inOrderTraverse(callback) {inOrderTraverseNode(root, callback)}function inOrderTraverseNode(node, callback) {if(node !== null) {// 先遍历左子树inOrderTraverseNode(node.left, callback)// 然后根节点callback(node.key)// 再遍历右子树inOrderTraverseNode(node.right, callback)}}// callback 每次将遍历到的结果打印到控制台function callback(key) {console.log(key)}`
先序遍历:
已经实现的中序遍历,先序遍历就很简单了,它是按根左右的顺序遍历
`function preOrderTraverse() {preOrderTraverseNode(root, callback)}function preOrderTraverseNode(node, callback) {if(node !== null) {// 先根节点callback(node.key)// 然后遍历左子树preOrderTraverseNode(node.left, callback)// 再遍历右子树preOrderTraverseNode(node.right, callback)}}// callback 每次将遍历到的结果打印到控制台function callback(key) {console.log(key)}`
后序遍历:
后序遍历按照左右根的顺序遍历,实现也很简单。
`function postOrderTraverse() {postOrderTraverseNode(root, callback)}function postOrderTraverseNode(node, callback) {if(node !== null) {// 先遍历左子树postOrderTraverseNode(node.left, callback)// 然后遍历右子树postOrderTraverseNode(node.right, callback)// 最后根节点callback(node.key)}}// callback 每次将遍历到的结果打印到控制台function callback(key) {console.log(key)}`
8.6.3 BST树的局限
在理想情况下,二叉树每多一层,可以存储的元素都增加一倍。也就是说 n 个元素的二叉搜索树,对应的树高为 O(logn)。所以我们查找元素、插入元素的时间也为 O(logn)。
当然这是理想情况下,但在实际应用中,并不是那么理想,例如一直递增或递减的给一个二叉查找树插入数据,那么所有插入的元素就会一直出现在一个树的左节点上,数型结构就会退化为链表结构,时间复杂度就会趋于 O(n),这是不好的。
而我们上面的平衡树就可以很好的解决这个问题,所以平衡二叉查找树(AVL树,下一章节探讨)由此诞生。
8.7 平衡二叉查找树(AVL树)
故名思义,既满足左右子树高度不大于 1, 又满足任意节点值大于它的左子节点值,小于等于它的右子节点值。
AVL 这个名字的由来,是它的两个发明者G. M. Adelson-Velsky 和 Evgenii Landis 的缩写,AVL最初是他们两人在1962 年的论文「An algorithm for the organization of information」中提出来一种数据结构
8.8 红黑树
红黑树也是一种特殊的「二叉查找树」。
到目前为止我们学习的 AVL 树和即将学习的红黑树都是二叉查找树的变体,可见二叉查找树真的是非常重要基础二叉树,如果忘了它的定义可以先回头看看。
红黑树是一种比较难的数据结构,面试中很少有面试官让你手写一个红黑树,最多的话是考察你是否理解红黑树,以及为什么有了 AVL 树还需要红黑树,本部分就主要介绍这块。
8.8.1 什么是红黑树
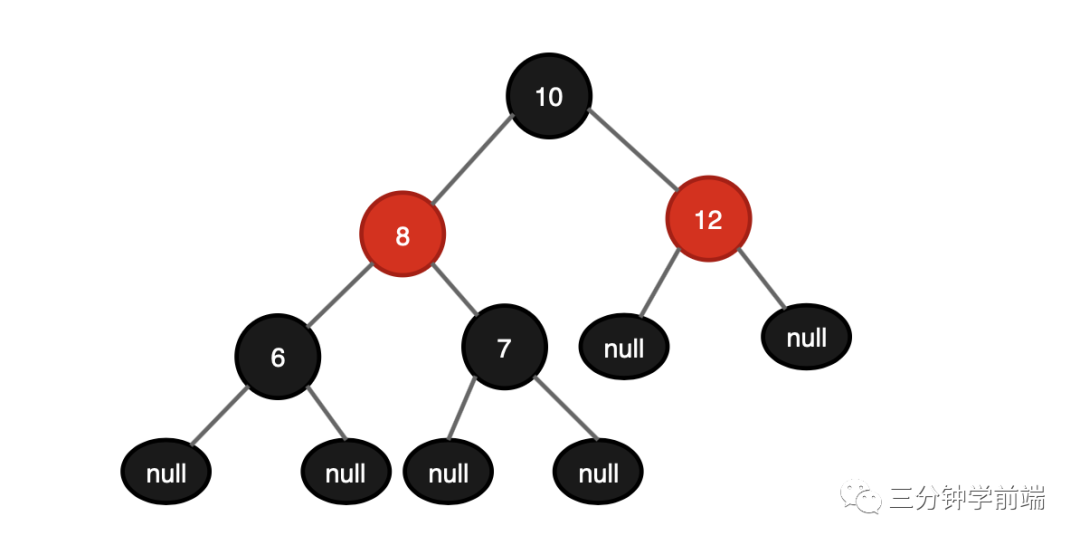
红黑树是一种自平衡(并不是绝对平衡)的二叉查找树,它除了满足二分查找树的特点外,还满足以下条件:
- 节点是红色或黑色
- 根节点必须是黑色节点
- 所有的叶子节点都必须是值为 NULL 的黑节点
- 如果一个节点是红色的,则它两个子节点都是黑色的
- 从任一节点到达它的每个叶子节点的所有的路径,都有相同数目的黑色节点
很多人不理解为神马要有那么多条条框框,这里引用王争老师的说法:
我们都玩过魔方吧,其实魔方的复原是有固定算法的,遇到哪几面是什么样的,你就对应转几下,只要跟着这个复原步骤,最终肯定能把魔方复原。红黑树也是的,它也有固定的条条框框,在插入、删除时也有固定的调整方案。
这些条条框框保证红黑树的自平衡,保证红黑树从根节点到达每一个叶子节点的最长路径不会超过最短路径的 2 倍。
而节点的路径长度决定着对节点的查询效率,这样我们确保了,最坏情况下的查找、插入、删除操作的时间复杂度不超过 O(logn) ,并且有较高的插入和删除效率。
8.8.2 红黑树 VS 平衡二叉树(AVL树)
- 插入和删除操作,一般认为红黑树的删除和插入会比 AVL 树更快。因为,红黑树不像 AVL 树那样严格的要求平衡因子小于等于1,这就减少了为了达到平衡而进行的旋转操作次数,可以说是牺牲严格平衡性来换取更快的插入和删除时间。
- 红黑树不要求有不严格的平衡性控制,但是红黑树的特点,使得任何不平衡都会在三次旋转之内解决。而 AVL 树如果不平衡,并不会控制旋转操作次数,旋转直到平衡为止。
- 查找操作,AVL树的效率更高。因为 AVL 树设计比红黑树更加平衡,不会出现平衡因子超过 1 的情况,减少了树的平均搜索长度。
8.9 Trie 树
8.9.1 什么是 Trie 树
Trie 树,也称为字典树或前缀树,顾名思义,它是用来处理字符串匹配问题的数据结构,以及用来解决集合中查找固定前缀字符串的数据结构。
8.9.2 Trie树的应用:字符串匹配
在搜索引擎中输入关键字,搜索引擎都会弹出下拉框,显示各种关键字提示,例如必应:
必应是如何处理这一过程的喃?
或者,假设我们有n个单词的数据集,任意输入一串字符,如何在数据集中快速匹配出具有输入字符前缀的单词?
这样类似的问题还有很多,在日常开发中,遇到类似的问题,我们应该如何去处理?选择怎样的数据结构与算法?尤其是遇到大规模数据时,如何更高效的处理?
最简单的方法就是暴力,将数据集中的每个字符串,逐个字符的匹配输入字符,所有字符都匹配上则前缀匹配成功。这种方式也是我们开发当中最常用,最简单的方式,时间复杂度为 O(m*n) ,其中 m 为输入字符串长度, n 为数据集规模。
这个时间复杂度是很高的,当 n 很大时,暴力法性能就会很差,此时必须重新寻找合适的算法。
我们知道在树上查找、插入都比较方便,一般时间复杂度只与树的高度相关,我们可以通过树结构来处理,也就是我们要说的 Trie 树。其实,引擎搜索关键字提示底层也是通过 Trie 树实现的。
举个例子:假设数据集有:are 、 add 、 adopt 、set 、so ,它构键过程:
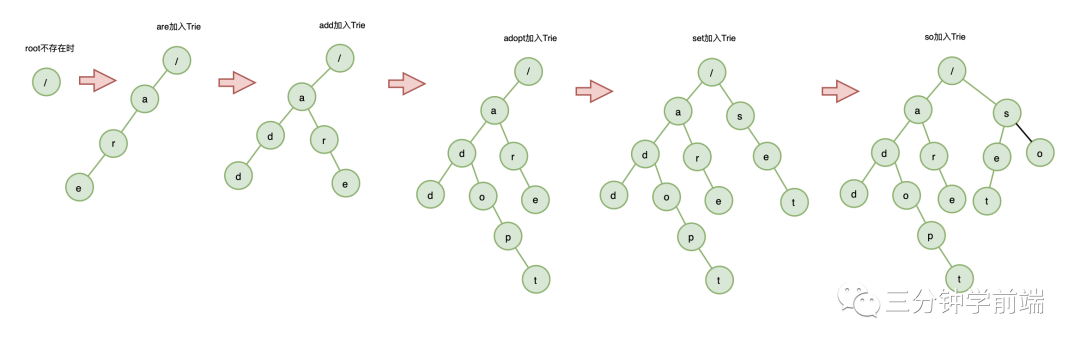
当所以的字符串插入完成,Trie树就构建完成了。
Trie树的本质是利用字符串的公共前缀,将重复的前缀合并在一起,其中根节点不包含任何信息,每个节点表示一个字符串中的字符,从根节点到叶节点的路径,表示一个字符串。
在字符串匹配的时候,我们只要按照树的结构从上到下匹配即可。
8.10 B 树、B+ 树(感兴趣进)
8.10.1 多叉查找树
既然二叉查找树已经理解了,那多叉查找树就很好理解了,它与二叉查找树唯一不同的是,它是多叉的。也就是说,多叉查找树允许一个节点存储多个元素,并且可以拥有多个子树。
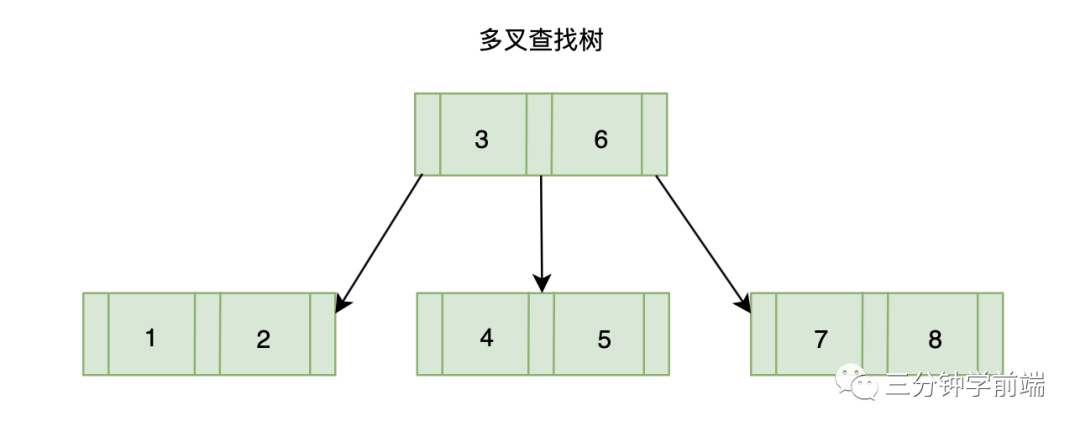
为什么在有二叉查找树的情况下,还要有多叉查找树喃?
我们知道树的深度越高,时间复杂度越高,性能越差,多叉查找树相对于二叉查找树来说,每个节点不止能拥有两个子节点,每层存放的节点数可比二叉查找树多,自然多叉查找树的的深度就要更小,性能也就更好。例如主要用于各大存储文件系统与数据库系统中的 B 树。
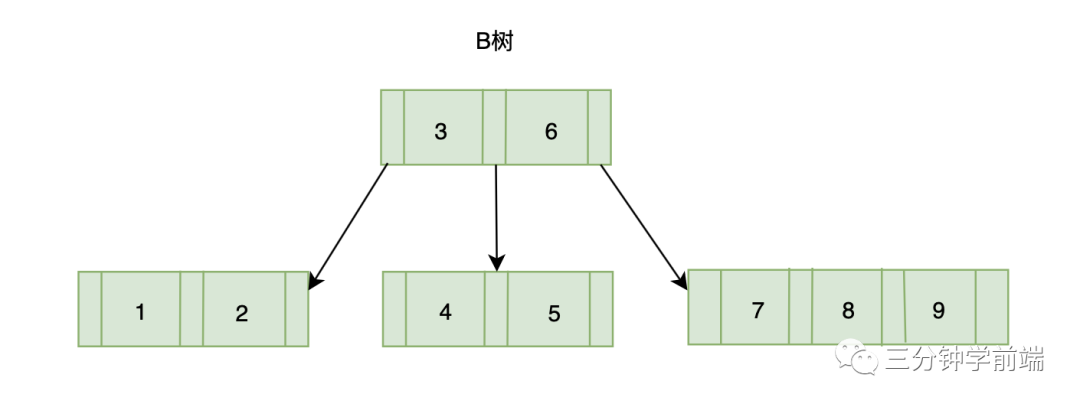
8.10.2 B 树(B-tree)
B 树,又称平衡多叉查找树。它是一种自平衡的多叉查找树。
如果一棵多路查找树满足以下规则,则称之为 B 树:
- 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
- 子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M叉(或路),当M=2则是2叉树,M=3则是3叉);
- 关键字数:枝节点(非根非叶)的关键字数量(K)应满足 (M+1)/2 < K < M
- 所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
最后,我们使用一张图加深一下理解:
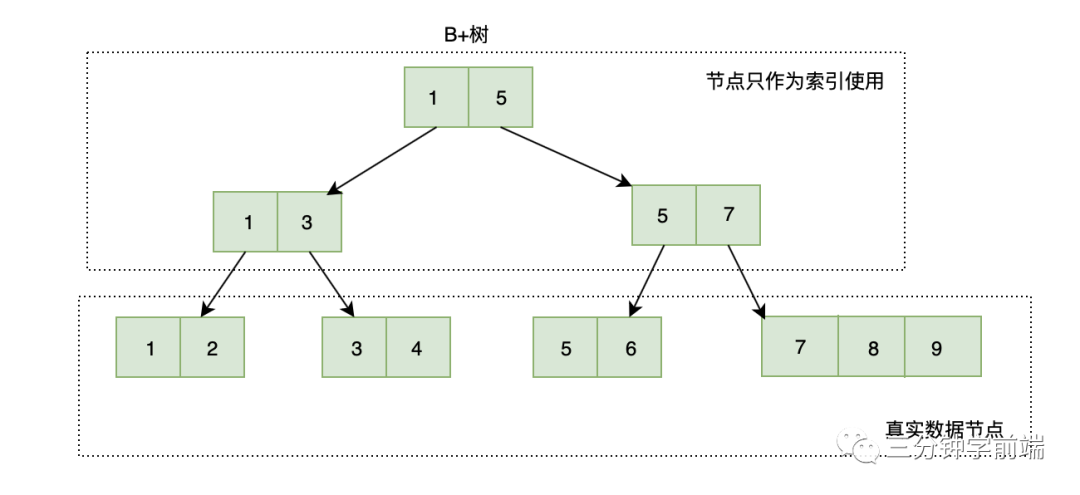
8.10.3 B+树
B+树与B树一样都是多叉平衡查找树(又名多路平衡查找树),B+树与B树不同的是:
- B+树改进了B树,让内结点(非叶节点)只作索引使用,去掉了其中指向data的指针,使得每个结点中能够存放更多的key, 因此能有更大的出度。
这有什么用?这样就意味着存放同样多的key,树的层高能进一步被压缩,使得检索的时间更短 - 中间节点的元素数量与子树一致,而B树子树数量与元素数量多1
- 叶子节点是一个链表,可以通过指针顺序查找
8.11 加深
8.11.1 二叉树的中序遍历
递归实现:
`// 中序遍历const inorderTraversal = (root) => {let result = []var inorderTraversal = (node) => {if(node) {// 先遍历左子树inorderTraversal(node.left)// 再根节点result.push(node.val)// 最后遍历右子树inorderTraversal(node.right)}}inorderTraversal(root)return result};`
迭代实现:
`const inorderTraversal = function(root) {let list = []let stack = []let node = rootwhile(stack.length || node) {if(node) {stack.push(node)node = node.leftcontinue}node = stack.pop()list.push(node.val)node = node.right}return list};`
进一步简化:
`// 中序遍历const inorderTraversal = (root) => {let list = []let stack = []let node = rootwhile(node || stack.length) {// 遍历左子树while(node) {stack.push(node)node = node.left}node = stack.pop()list.push(node.val)node = node.right}return list}`
复杂度分析:
- 空间复杂度:O(n)
- 时间复杂度:O(n)
更多解答
8.11.2 二叉树的后序遍历
递归实现
`// 后序遍历const postorderTraversal = function(root) {let result = []var postorderTraversalNode = (node) => {if(node) {// 先遍历左子树postorderTraversalNode(node.left)// 再遍历右子树postorderTraversalNode(node.right)// 最后根节点result.push(node.val)}}postorderTraversalNode(root)return result};`
迭代实现
解题思路: 后序遍历与前序遍历不同的是:
- 后序遍历是左右根
- 而前序遍历是根左右
如果我们把前序遍历的 list.push(node.val) 变更为 list.unshift(node.val) (遍历结果逆序),那么遍历顺序就由 根左右 变更为 右左根
然后我们仅需将 右左根 变更为 左右根 即可完成后序遍
`// 后序遍历const postorderTraversal = (root) => {const list = [];const stack = [];// 当根节点不为空的时候,将根节点入栈if(root) stack.push(root)while(stack.length > 0) {const node = stack.pop()// 根左右=>右左根list.unshift(node.val)// 先进栈左子树后右子树// 出栈的顺序就变更为先右后左// 右先头插法入list// 左再头插法入list// 实现右左根=>左右根if(node.left !== null) {stack.push(node.left)}if(node.right !== null) {stack.push(node.right)}}return list}`
复杂度分析:
- 空间复杂度:O(n)
- 时间复杂度:O(n)
更多解答
8.11.3 二叉树的层次遍历
给定一个二叉树,返回其节点值自底向上的层次遍历。(即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
例如:给定二叉树 [3,9,20,null,null,15,7] ,
`3/ \9 20/ \15 7`
返回其自底向上的层次遍历为:
`[[15,7],[9,20],[3]]`
解法一:BFS(广度优先遍历)
BFS 是按层层推进的方式,遍历每一层的节点。题目要求的是返回每一层的节点值,所以这题用 BFS 来做非常合适。BFS 需要用队列作为辅助结构,我们先将根节点放到队列中,然后不断遍历队列。
`const levelOrderBottom = function(root) {if(!root) return []let res = [],queue = [root]while(queue.length) {let curr = [],temp = []while(queue.length) {let node = queue.shift()curr.push(node.val)if(node.left) temp.push(node.left)if(node.right) temp.push(node.right)}res.push(curr)queue = temp}return res.reverse()};`
复杂度分析
- 时间复杂度:O(n)
- 空间复杂度:O(n)
解法二:DFS(深度优先遍历)
DFS 是沿着树的深度遍历树的节点,尽可能深地搜索树的分支
DFS 做本题的主要问题是:DFS 不是按照层次遍历的。为了让递归的过程中同一层的节点放到同一个列表中,在递归时要记录每个节点的深度 depth 。递归到新节点要把该节点放入 depth 对应列表的末尾。
当遍历到一个新的深度 depth ,而最终结果 res 中还没有创建 depth 对应的列表时,应该在 res 中新建一个列表用来保存该 depth 的所有节点。
`const levelOrderBottom = function(root) {const res = []var dep = function (node, depth){if(!node) returnres[depth] = res[depth]||[]res[depth].push(node.val)dep(node.left, depth + 1)dep(node.right, depth + 1)}dep(root, 0)return res.reverse()};`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(h),h为树的高度
更多解答
8.11.4 二叉树的层序遍历
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。(即逐层地,从左到右访问所有节点)。
示例:二叉树:[3,9,20,null,null,15,7] ,
`3/ \9 20/ \15 7`
返回其层次遍历结果:
`[[3],[9,20],[15,7]]`
感谢 @plane-hjh 的解答:
这道题和二叉树的层次遍历相似,只需要把 reverse() 去除就可以了
广度优先遍历
`const levelOrder = function(root) {if(!root) return []let res = [],queue = [root]while(queue.length) {let curr = [],temp = []while(queue.length) {let node = queue.shift()curr.push(node.val)if(node.left) temp.push(node.left)if(node.right) temp.push(node.right)}res.push(curr)queue = temp}return res};`
深度优先遍历
`const levelOrder = function(root) {const res = []var dep = function (node, depth){if(!node) returnres[depth] = res[depth]||[]res[depth].push(node.val)dep(node.left, depth + 1)dep(node.right, depth + 1)}dep(root, 0)return res};`
更多解答
8.11.5 重构二叉树:从前序与中序遍历序列构造二叉树
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
注意:你可以假设树中没有重复的元素。
例如,给出
`前序遍历 preorder = [3,9,20,15,7]中序遍历 inorder = [9,3,15,20,7]`
返回如下的二叉树:
`3/ \9 20/ \15 7`
限制:
0 <= 节点个数 <= 5000
推荐 @luweiCN 的解答:
仔细分析前序遍历和中序遍历可以知道(以题目为例):
- 前序遍历的第一个元素一定是根节点,这里是
3 - 找到根节点之后,根节点在中序遍历中把数组一分为二,即两个数组
[9]和[15, 20, 7],这两个数组分别是根节点3的左子树和右子树的中序遍历。 - 前序遍历数组去掉根节点之后是
[9,20,15,7],而这个数组的第1项[9](左子树的大小)和后3项[20, 15, 7](右子树的大小)又分别是左子树和右子树的前序遍历 到这里已经很明显了,用递归
`function TreeNode(val) {this.val = val;this.left = this.right = null;}const buildTree = function (preorder, inorder) {if (preorder.length) {let head = new TreeNode(preorder.shift());let index = inorder.indexOf(head.val);head.left = buildTree(preorder.slice(0, index),inorder.slice(0, index));head.right = buildTree(preorder.slice(index), inorder.slice(index + 1));// 这里要注意,preorder前面shift一次长度比inorder小1return head;} else {return null;}};`
更多解答
8.11.6 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:给定二叉树 [3,9,20,null,null,15,7] ,
`3/ \9 20/ \15 7`
返回它的最大深度 3
解答:递归
`const maxDepth = function(root) {if(!root) return 0return 1 + Math.max(maxDepth(root.left), maxDepth(root.right))};`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(logn)
更多解答
8.11.7 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
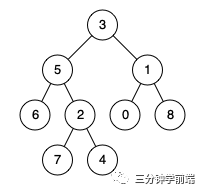
示例 1:
`输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1输出: 3解释: 节点 5 和节点 1 的最近公共祖先是节点 3。`
示例 2:
`输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4输出: 5解释: 节点 5 和节点 4 的最近公共祖先是节点 5。因为根据定义最近公共祖先节点可以为节点本身。`
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉树中。
解答:递归实现
解题思路:
如果树为空树或 p 、 q 中任一节点为根节点,那么 p 、 q 的最近公共节点为根节点
如果不是,即二叉树不为空树,且 p 、 q 为非根节点,则递归遍历左右子树,获取左右子树的最近公共祖先,
- 如果
p、q节点在左右子树的最近公共祖先都存在,说明p、q节点分布在左右子树的根节点上,此时二叉树的最近公共祖先为root - 若
p、q节点在左子树最近公共祖先为空,那p、q节点位于左子树上,最终二叉树的最近公共祖先为右子树上p、q节点的最近公共祖先 - 若
p、q节点在右子树最近公共祖先为空,同左子树p、q节点的最近公共祖先为空一样的判定逻辑 - 如果
p、q节点在左右子树的最近公共祖先都为空,则返回null
代码实现:
`const lowestCommonAncestor = function(root, p, q) {if(root == null || root == p || root == q) return rootconst left = lowestCommonAncestor(root.left, p, q)const right = lowestCommonAncestor(root.right, p, q)if(left === null) return rightif(right === null) return leftreturn root};`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(n)
更多解答
8.11.8 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
`3/ \9 20/ \15 7`
返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
`1/ \2 2/ \3 3/ \4 4`
返回 false 。
解答一:自顶向下(暴力法)
解题思路: 自顶向下的比较每个节点的左右子树的最大高度差,如果二叉树中每个节点的左右子树最大高度差小于等于 1 ,即每个子树都平衡时,此时二叉树才是平衡二叉树
代码实现:
`const isBalanced = function (root) {if(!root) return truereturn Math.abs(depth(root.left) - depth(root.right)) <= 1&& isBalanced(root.left)&& isBalanced(root.right)}const depth = function (node) {if(!node) return -1return 1 + Math.max(depth(node.left), depth(node.right))}`
复杂度分析:
- 时间复杂度:O(nlogn),计算
depth存在大量冗余操作 - 空间复杂度:O(n)
解答二:自底向上(优化)
解题思路: 利用后续遍历二叉树(左右根),从底至顶返回子树最大高度,判定每个子树是不是平衡树 ,如果平衡,则使用它们的高度判断父节点是否平衡,并计算父节点的高度,如果不平衡,返回 -1 。
遍历比较二叉树每个节点 的左右子树深度:
- 比较左右子树的深度,若差值大于
1则返回一个标记-1,表示当前子树不平衡 - 左右子树有一个不是平衡的,或左右子树差值大于
1,则二叉树不平衡 - 若左右子树平衡,返回当前树的深度(左右子树的深度最大值
+1)
代码实现:
`const isBalanced = function (root) {return balanced(root) !== -1};const balanced = function (node) {if (!node) return 0const left = balanced(node.left)const right = balanced(node.right)if (left === -1 || right === -1 || Math.abs(left - right) > 1) {return -1}return Math.max(left, right) + 1}`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(n)
更多解答
8.11.9 路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
说明: 叶子节点是指没有子节点的节点。
示例: 给定如下二叉树,以及目标和 sum = 22 ,
`5/ \4 8/ / \11 13 4/ \ \7 2 1`
返回 true , 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
解题思路:
只需要遍历整棵树
- 如果当前节点不是叶子节点,递归它的所有子节点,传递的参数就是 sum 减去当前的节点值;
- 如果当前节点是叶子节点,判断参数 sum 是否等于当前节点值,如果相等就返回 true,否则返回 false。
代码实现:
`var hasPathSum = function(root, sum) {// 根节点为空if (root === null) return false;// 叶节点 同时 sum 参数等于叶节点值if (root.left === null && root.right === null) return root.val === sum;// 总和减去当前值,并递归sum = sum - root.valreturn hasPathSum(root.left, sum) || hasPathSum(root.right, sum);};`
更多解答
8.11.10 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
`1/ \2 2/ \ / \3 4 4 3`
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
`1/ \2 2\ \3 3`
进阶:
你可以运用递归和迭代两种方法解决这个问题吗?
解答:
一棵二叉树对称,则需要满足:根的左右子树是镜像对称的
也就是说,每棵树的左子树都和另外一颗树的右子树镜像对称,左子树的根节点值与右子树的根节点值相等
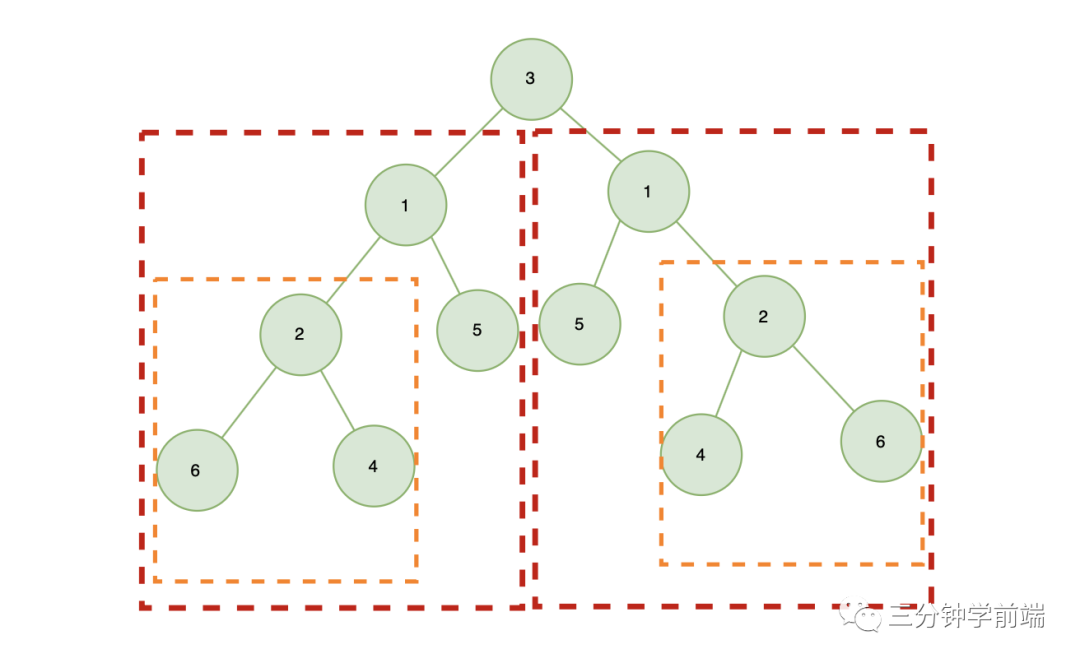
所以,我们需要比较:
- 左右子树的根节点值是否相等
- 左右子树是否镜像对称
边界条件:
- 左右子树都为
null时,返回true - 左右子树有一个
null时,返回false
解法一:递归
`const isSymmetric = function(root) {if(!root) return truevar isEqual = function(left, right) {if(!left && !right) return trueif(!left || !right) return falsereturn left.val === right.val&& isEqual(left.left, right.right)&& isEqual(left.right, right.left)}return isEqual(root.left, root.right)};`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(n)
解法二:迭代
利用栈来记录比较的过程,实际上,递归就使用了调用栈,所以这里我们可以使用栈来模拟递归的过程
- 首先根的左右子树入栈
- 将左右子树出栈,比较两个数是否互为镜像
- 如果左右子树的根节点值相等,则将左子树的
left、右子树的right、左子树的right、右子树的left依次入栈 - 继续出栈(一次出栈两个进行比较)…….
依次循环出栈入栈,直到栈为空
`const isSymmetric = function(root) {if(!root) return truelet stack = [root.left, root.right]while(stack.length) {let right = stack.pop()let left = stack.pop()if(left && right) {if(left.val !== right.val) return falsestack.push(left.left)stack.push(right.right)stack.push(left.right)stack.push(right.left)} else if(left || right) {return false}}return true};`
复杂度分析:
- 时间复杂度:O(n)
- 空间复杂度:O(n)
剑指Offer&leetcode101:对称二叉树
8.11.11给定一个二叉树, 找到该树中两个指定节点间的最短距离
function TreeNode(val) { this.val = val; this.left = this.right = null; }
解答:
求最近公共祖先节点,然后再求最近公共祖先节点到两个指定节点的路径,再求两个节点的路径之和
`const shortestDistance = function(root, p, q) {// 最近公共祖先let lowestCA = lowestCommonAncestor(root, p, q)// 分别求出公共祖先到两个节点的路经let pDis = [], qDis = []getPath(lowestCA, p, pDis)getPath(lowestCA, q, qDis)// 返回路径之和return (pDis.length + qDis.length)}// 最近公共祖先const lowestCommonAncestor = function(root, p, q) {if(root === null || root === p || root === q) return rootconst left = lowestCommonAncestor(root.left, p, q)const right = lowestCommonAncestor(root.right, p, q)if(left === null) return rightif(right === null) return leftreturn root}const getPath = function(root, p, paths) {// 找到节点,返回 trueif(root === p) return true// 当前节点加入路径中paths.push(root)let hasFound = false// 先找左子树if (root.left !== null)hasFound = getPath(root.left, p, paths)// 左子树没有找到,再找右子树if (!hasFound && root.right !== null)hasFound = getPath(root.right, p, paths)// 没有找到,说明不在这个节点下面,则弹出if (!hasFound)paths.pop()return hasFound}`
更多解答
8.11.12 二叉搜索树中第K小的元素
给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素。
说明:你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数。
示例 1:
`输入: root = [3,1,4,null,2], k = 13/ \1 4\2输出: 1`
示例 2:
`输入: root = [5,3,6,2,4,null,null,1], k = 35/ \3 6/ \2 4/1输出: 3`
进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化 kthSmallest 函数?
解答:
我们知道:中序遍历其实是对🌲进行排序操作 ,并且是按从小到大的顺序排序,所以本题就很简单了
解题思路: 中序遍历二叉搜索树,输出第 k 个既可
代码实现(递归):
`const kthSmallest = function(root, k) {let res = nulllet inOrderTraverseNode = function(node) {if(node !== null && k > 0) {// 先遍历左子树inOrderTraverseNode(node.left)// 然后根节点if(--k === 0) {res = node.valreturn}// 再遍历右子树inOrderTraverseNode(node.right)}}inOrderTraverseNode(root)return res}`
复杂度分析:
- 时间复杂度:O(k)
- 空间复杂度:不考虑递归栈所占用的空间,空间复杂度为 O(1)
代码实现(迭代):
`const kthSmallest = function(root, k) {let stack = []let node = rootwhile(node || stack.length) {// 遍历左子树while(node) {stack.push(node)node = node.left}node = stack.pop()if(--k === 0) {return node.val}node = node.right}return null}`
复杂度分析:
- 时间复杂度:O(H+K)
- 空间复杂度:空间复杂度为 O(H+K)
更多解答
8.11.13 实现 Trie(前缀树)
实现一个 Trie (前缀树),包含 insert , search , 和 startsWith 这三个操作。
示例:
`Trie trie = new Trie();trie.insert("apple");trie.search("apple"); // 返回 truetrie.search("app"); // 返回 falsetrie.startsWith("app"); // 返回 truetrie.insert("app");trie.search("app"); // 返回 true`
说明:
- 你可以假设所有的输入都是由小写字母 a-z 构成的。
- 保证所有输入均为非空字符串。
解答:
我们可以搭建一个初始 Trie 树结构:
`// Trie 树var Trie = function() {};// 插入Trie.prototype.insert = function(word) {};// 搜索Trie.prototype.search = function(word) {};// 前缀匹配Trie.prototype.startsWith = function(prefix) {};`
1. 如何存储一个 Trie 树
首先,我们需要实现一个 Trie 树,我们知道,二叉树的存储(链式存储)是通过左右指针来实现的,即二叉树中的节点:
`function BinaryTreeNode(key) {// 保存当前节点 key 值this.key = key// 指向左子节点this.left = null// 指向右子节点this.right = null}`
在这里,它不止有两个字节点,它最多有 a-z 总共有26个子节点。最简单的实现是把她们保存在一个字典里:
isEnd:当前是否是结束节点children:当前节点的子节点,这里我们使用key:value形式实现,key为子节点字符,value指向子节点的孩子节点
`var TrieNode = function() {// next 放入当前节点的子节点this.next = {};// 当前是否是结束节点this.isEnd = false;};`
所以:
`// Trie 树var Trie = function() {this.root = new TrieNode()};`
2. 插入
- 首先判断插入节点是否为空,为空则返回
- 遍历待插入字符,从根节点逐字符查找 Trie 树,如果字符查找失败则插入,否则继续查找下一个字符
- 待插入字符遍历完成,设置最后字符的
isEnd为true - 返回插入成功
`Trie.prototype.insert = function(word) {if (!word) return falselet node = this.rootfor (let i = 0; i < word.length; i++) {if (!node.next[word[i]]) {node.next[word[i]] = new TrieNode()}node = node.next[word[i]]}node.isEnd = truereturn true};`
3. 搜索
`Trie.prototype.search = function(word) {if (!word) return falselet node = this.rootfor (let i = 0; i < word.length; ++i) {if (node.next[word[i]]) {node = node.next[word[i]]} else {return false}}return node.isEnd};`
4. 前缀匹配
`Trie.prototype.startsWith = function(prefix) {if (!prefix) return truelet node = this.rootfor (let i = 0; i < prefix.length; ++i) {if (node.next[prefix[i]]) {node = node.next[prefix[i]]} else {return false}}return true};`
最近开源了一个github仓库:百问百答,在工作中很难做到对社群问题进行立即解答,所以可以将问题提交至 https://github.com/Advanced-Frontend/Just-Now-QA ,我会在每晚花费 1 个小时左右进行处理,更多的是鼓励与欢迎更多人一起参与探讨与解答🌹
本文转自 https://mp.weixin.qq.com/s/d1abOH39sf-yQ0ctuv2EFw,如有侵权,请联系删除。

若有收获,就点个赞吧
0 人点赞
