指令表
https://docs.soliditylang.org/en/v0.6.2/yul.html#evm-dialect
汇编相关知识介绍
什么是汇编?
任何以高级语言(例如C,Go或Java)编写的程序,在执行之前都将先编译为“汇编语言”。 但是什么是汇编?
汇编(也称为汇编语言)是指可使用汇编器转换为机器代码的低级编程语言。 汇编语言与物理机或虚拟机绑定,因为它们实现了指令集。 一条指令告诉CPU执行一些基本任务,例如将两个数字相加。
这里示例的处理器是Intel x86或ARM。 英特尔x86大约有1503条机器指令。它们是通常称为操作码。
理解虚拟机和栈
以太坊虚拟机EVM有自己的指令集,该指令集中目前包含了 144个操作码,详情参考Geth代码
这些指令被Solidity语言 抽象之后,用来编写智能合约,但是Solidity 也支持使用内联汇编。例如:
contract Assembler {function do_something_cpu() public {assembly {// start writing evm assembler language}}}
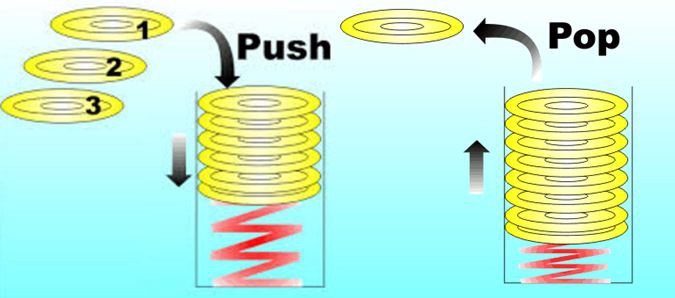
EVM是一个基于栈的虚拟机(stack machine),栈这种数据结构只允许两个操作:压入(PUSH)或弹出(POP)数据。 最后压入的数据位于栈顶,因此将被第一个弹出,这被称为后进先出 (LIFO:Last In, First Out):
栈虚拟机将所有的操作数保存在栈上,
关于栈虚拟机的详细信息 可以参考stack machine一系列文章
stack machine 也是一种处理器,其中所有操作数都存储在栈中。 它仍然具有PC(程序计数器)和SP(堆栈指针)的存储器和寄存器,但是所有内容都存储在栈中。
操作码基础
为了能够解决实际问题,基于栈结构机器需要实现一些额外的指令,例如 ADD、SUBSTRACT等等。指令执行时通常会先从堆栈弹出一个或多个值作为参数, 再将执行结果压回堆栈。这通常被称为逆波兰表示法(Reverse Polish Notation):
a + b // 标准表示法Infix
a b add // 逆波兰表示法RPN
为什么Solidity中需要用汇编
细粒度控制
编写内联汇编使在以太坊上编写智能合约更加有趣。 为什么呢?
你可以使用操作码直接与EVM进行交互。 这使的可以对程序(=智能合约)要执行的操作进行更精细控制。
汇编提供了更多控制权来执行某些仅靠Solidity不可能实现的逻辑。 例如,指向特定的内存插槽。
当编写库时,细粒度控制特别有用,因为这些将被开发人员重用。 查看下面的Solidity库。 看到他们在多大程度上依赖使用Assembly,你也许会感到惊讶。
- String Utils by Nick Johnson (Ethereum Foundation开发)
Bytes Utils by Gonçalo Sá (Consensys开发)
更少的Gas消耗
在Solidity中使用汇编语言的主要优点之一是节省了Gas。
让我们通过创建简单的函数来比较Solidity和Assembly之间的Gas成本:1)简单地将两个数字(x + y)相加,然后2)返回结果。
两个版本:一个仅使用Solidity,一个仅使用内联Assembly。
先不用担心代码怎么写,我们稍后会再说:)function addAssembly(uint x, uint y) public pure returns (uint) { assembly { // Add some code here let result := add(x, y) mstore(0x0, result) return(0x0, 32) } } function addSolidity(uint x, uint y) public pure returns (uint) { return x + y; }
从上面的示例中可以看到,使用内联汇编可以节省86的gas。 对于此示例来说,这并不是很多,但这粗略地了解了我们可以为更复杂的合约节省多少gas。增强功能
有一些事情在EVM汇编中可以做,而没法在 Solidity 中实现。
关于这一点 Nick Johnson 有很好的解释Solidity 中两种类型的汇编
汇编语言相对而言更接近EVM。
Solidity定义了两种汇编语言的实现方式:内联汇编(Inline Assembly ):可以在内部Solidity源代码中使用。
- 独立汇编(Standalone Assembly:可以使用,无需Solidity。
基本汇编语法
引入汇编
前面已经有个实例,可以在Solidity中使用assembly{}来嵌入汇编代码段,这被称为内联汇编:
assembly {
// some assembly code here
}
在
assembly块内的代码开发语言被称为Yul,为了简化我们称其为 汇编、汇编代码或EVM汇编。
另一个需要注意的问题时,汇编代码块之间不能通信,也就是说在 一个汇编代码块里定义的变量,在另一个汇编代码块中不可以访问。 例如:
Solidity 文档有这样的解释:
不同的内联汇编块不共享任何名称空间,即不可能调用Yul函数或访问在其他内联汇编块中定义的Yul变量。
assembly {
let x := 2
}
assembly {
let y := x // Error
}
// DeclarationError: identifier not found
// let y := x
// ^
简单汇编示例
下面的代码使用内联汇编代码计算函数的两个参数的和并返回结果:
function addition(uint x, uint y) public pure returns (uint) {
assembly {
let result := add(x, y) // x + y
mstore(0x0, result) // 在内存中保存结果
return(0x0, 32) // 从内存中返回32字节
}
}
让我们重写上面的代码,补充一些更详细的注释,以便说明每个指令在EVM内部的运行原理。
function addition(uint x, uint y) public pure returns (uint) {
assembly {
// 创建一个新的变量result
// -> 使用add操作码计算x+y
// -> 将计算结果赋值给变量result
let result := add(x, y) // x + y
// 使用mstore操作码
// -> 将result变量的值存入内存
// -> 指定内存地址 0x0
mstore(0x0, result) // 将结果存入内存
// 从内存地址0x返回32字节
return(0x0, 32)
}
}
Solidity汇编中的变量定义与赋值
在Yul中,使用let关键字定义变量。使用:=操作符给变量赋值:
assembly {
let x := 2
}
和Solidity 不同,Solidity只需要用
=, 因此不要忘了:.
如果没有使用:=操作符给变量赋值,那么该变量自动初始化为0值:
assembly {
let x // 自动初始化为 x = 0
x := 5 // x 现在的值是5
}
你可以使用复杂的表达式为变量赋值,例如:
assembly {
let x := 7
let y := add(x, 3)
let z := add(keccak256(0x0, 0x20), div(slength, 32))
let n // 自动初始化为 n = 0
}
汇编中let指令的运行机制
在EVM的内部,let指令执行如下任务:
- 创建一个新的堆栈槽位
- 为变量保留该槽位
- 当到达代码块结束时自动销毁该槽位
因此,使用let指令在汇编代码块中定义的变量,在该代码块 外部是无法访问的。
汇编的注释
在Yul汇编中注释的写法和Solidity一样,可以使用单行注释// 或多行注释/* */。例如:
assembly {
// 单行注释
/*
多
行
注释
*/
}
汇编中的字面量
在Solidity汇编中字面量的写法与Solidity一致。不过,字符串字面量最多可以包含32个字符。
assembly {
let a := 0x123 // 16进制
let b := 42 // 10进制
let c := "hello world" // 字符串
let d := "very long string more than 32 bytes" // 超长字符串,出错!
}
// TypeError: String literal too long (35 < 32)
// let d := "really long string more than 32 bytes"
//
汇编中的块和作用域
在Solidity汇编中,变量的作用范围遵循标准规则。一个块的范围使用由一对大括号标识。
在下面的示例中,y和z仅在定义所在块范围内有效。因此y变量的作用范围是scope 1,z变量的作用范围是scope 2。
assembly {
let x := 3 // x在各处可见
// Scope 1
{
let y := x // ok
} // 到此处会销毁y
// Scope 2
{
let z := y // Error
} // 到此处会销毁z
}
// DeclarationError: identifier not found
// let z := y
// ^
在Solidity汇编中访问变量
局部变量
在Solidity汇编中,只需要使用变量名就可以访问局部变量, 无论该变量是定义在汇编块中,还是汇编块之外(Solidity代码中),不过变量必须是函数的局部变量:
下面是一个示例:
function assembly_local_var_access() public pure {
uint b = 5;
assembly { // defined inside an assembly block
let x := add(2, 3)
let y := 10
z := add(x, y)
}
assembly { // defined outside an assembly block
let x := add(2, 3)
let y := mul(x, b)
}
}
内存、Calldata变量、状态变量
汇编中的循环
For循环
先看一下Solidity中for循环的使用。下面的Solidity函数代码中 对变量value 乘2计算 n次,其中value和n是函数的参数:
function for_loop_solidity(uint n, uint value) public pure returns(uint) {
for ( uint i = 0; i < n; i++ ) {
value = 2 * value;
}
return value;
}
等效的Solidity汇编代码如下:
function for_loop_assembly(uint n, uint value) public pure returns (uint) {
assembly {
for { let i := 0 } lt(i, n) { i := add(i, 1) } {
value := mul(2, value)
}
mstore(0x0, value)
return(0x0, 32)
}
}
类似于其他开发语言中的for循环,在汇编中,for循环也包含 3个元素:
- 初始化:
let i := 0 - 执行条件:
lt(i, n),必须是函数风格表达式 - 迭代后续步骤:
add(i, 1)注意:for循环中变量的作用范围略有不同。在初始化部分定义的变量在循环的其他部分都有效。 在 for 循环的其他部分中声明的变量遵守前面介绍的常规语法作用域规则。
汇编中的 while循环
在Solidity 汇编中实际上是没有while循环关键字的,但是可以使用 for 循环实现同样的功能:只要留空for循环的初始化部分和后迭代部分即可。
assembly {
let x := 0
let i := 0
for { } lt(i, 0x100) { } { // 等价 while(i < 0x100)
x := add(x, mload(i))
i := add(i, 0x20)
}
}
在Solidity汇编的判断语句
使用If
Solidity内联汇编支持使用if语句来设置代码执行的条件,但是没有其他语言中的else部分。
assembly {
if slt(x, 0) { x := sub(0, x) } // Ok
if eq(value, 0) revert(0, 0) // Error, 需要大括号
}
if语句强制要求代码块使用大括号,即使需要保护的代码只有一行, 也需要使用大括号。这和Solidity 有点不同。
function calculate_delivery_charges(uint ether_sent) public pure returns (uint) {
// free delivery on orders less than 0.25 ethers
if ( ether_sent < 0.25 ether) revert();
// more code...
}
如果需要在Solidity内联汇编中检查多种条件,可以考虑使用 switch 语句。
使用switch语句
EVM汇编中也有switch语句,它将一个表达式的值于多个常量进行对比,并选择相应的代码分支来执行。switch语句支持 一个默认分支default,当表达式的值不匹配任何其他分支条件时,将执行默认分支的代码。
assembly {
let x := 0
switch calldataload(4)
case 0 {
x := calldataload(0x24)
}
default {
x := calldataload(0x44)
}
sstore(0, div(x, 2))
}
switch语句在语法上有一些限制:
- 分支列表不需要大括号,但是分支的代码块需要大括号;
- 所有的分支条件值必须:1)具有相同的类型 2)具有不同的值
如果分支条件已经涵盖所有可能的值,那么不允许再出现default条件 ``` assembly {
let x := 34
switch lt(x, 30) case true {
// do something} case false {
// do something els} default {
// 不允许}
}
我个人认为switch语句是内联汇编语言最有趣的功能之一。原因如下:
1. Solidity 支持 `if { ... } else { ... }` 语句, `while`, `do` 和 `for` 循环, 但是没有 `switch`语句。
1. 当比较的值与一个 `case` 匹配时,控制流将停止。它不会从一个`case`延续到下一个`case`。
因此,我们可以认为 EVM 汇编中的 `switch` 语句可用于不同的目的:
- 作为非常基本版本的"if/else"
- 作为 if 语句的扩展版本
<a name="87398394"></a>
## Solidity汇编的函数
你也可以在 Solidity内联汇编中定义底层函数,他们可以包含自己的逻辑,调用这些自定义的函数和使用内置的操作码一样。<br />下面的汇编函数用来分配指定长度`length`的内存,并返回内存指针`pos`:
assembly {
function allocate(length) -> pos {
pos := mload(0x40)
mstore(0x40, add(pos, length))
}
let free_memory_pointer := allocate(64)
}
汇编函数的运行机制很有趣,让跟我们深入看一看。汇编函数运行如下:
1. 从栈顶提取参数
1. 将结果压入栈
和Solidity函数不同,不需要指定汇编函数的可见性,例如`public`或`private`, 因为汇编函数仅在定义所在的汇编代码块内有效。<br />汇编变量遵循相同作用域规则。最新的 Solidity 文档对此给出了明确的解释:<br />Yul 允许定义函数。它们不应与 Solidity 中的函数混淆,因为它们从来不是合约外部接口的一部分,并且独立于 Solidity 函数的命名空间。
<a name="2d518350"></a>
### 函数定义
使用 `function` 关键字,后跟其名称、两个括号`()`和一组大括号 `{...} `,这种标准方式定义汇编函数。<br />它还可以声明参数。它们的类型不需要像 `Solidity` 函数一样指定。<br />如:
assembly {
function my_assembly_function(param1, param2) {
// assembly code here
}
}
<a name="8cabd9e8"></a>
### 函数返回值
像 Rust一样,返回值用`->` 指定会返回一个值.
assembly {
function my_assembly_function(param1, param2) -> my_result {
// param2 - (4 * param1)
my_result := sub(param2, mul(4, param1))
}
let some_value = my_assembly_function(4, 9) // 4 - (9 * 4) = 32
}
不需要显式返回语句。为了返回一个值,只需在最终语句中将其分配给返回变量(如前面的示例中`my_result`)。
> **重要提示**:EVM 包含了 `return` 的内置操作代码。如果在汇编函数中编写了`return` 操作码,它将停止完全执行当前上下文(内部消息调用),而不仅仅是当前汇编函数。
<a name="5dc345f3"></a>
### 变量访问
在汇编函数内部,无法访问该函数之外声明的变量
<a name="158f9ece"></a>
### 退出函数
可以使用特殊语句退出当前函数。<br />`leave` 关键字可以放置在汇编函数体的任意位置,以停止其执行流并退出它。它的工作原理与空返回语句完全相同,有一个例外:函数将返回上次复制的变量给返回变量。
> 注意:`leave` 关键字只能在函数内使用
<a name="505a9215"></a>
## 操作码(Opcodes)和汇编
我们终于要深入这个主题的核心:**操作码(opcodes)**。以太坊虚拟机的指令集!
<a name="6c0c7e10"></a>
### 操作码简介
EVM 操作码可以分为以下几类:
- 算数和比较操作
- 位操作
- 密码学计算,目前仅包含`keccak256`
- 环境操作码,主要指与区块链相关的全局信息,例如:`blockhash`或`coinbase`
- 存储、内存和栈操作
- 交易与合约调用操作
- 停机操作
- 日志操作
<a name="f165578f"></a>
### 有哪些操作码
操作码列表可以查看[Solidity文档](https://solidity.readthedocs.io/en/v0.6.2/yul.html#evm-dialect),有关这个表的更多详细信息:
- 操作码始终从堆栈顶部获取参数(在括号中给出)。<br />
- 标有 `-`(第二列)的操作码不会将项推送到栈上。这些操作码的大多数是返回内存中的值。<br />
- 所有其他操作码会将项(其"返回"值)压入到堆栈上。<br />
- 标有`F`、`H`、`B`和`C`的操作码,表示从相应的版本:Frontier、Homestead、Byzantium和Constantinople(君士坦丁堡)加入。
> 译者注: 以太坊经历了哪些升级版本,可以查看:[以太坊发展简史](https://learnblockchain.cn/2019/06/15/eth-history1/)
- `mem[a...b)` 表示从位置 a 开始到(但不包括位置 b)开始的内存字节。<br />
- `storage[p]` 表示位置 p 处的存储内容。<br />
操作码`pushi`和`Jumpdest`不能直接使用。 相反,您可以通过输入以十进制或十六进制表示形式的整数常量来使用它们。 将自动生成适当的`PUSHi`指令。
<a name="0c257896"></a>
### 汇编中使用操作码
待补充...(不知道还会不会补充,文章原作者是在 Dec 25, 2019 写的,挺久了... )
<a name="d74cc07b"></a>
## 高级的汇编概念
<a name="fbd75a6d"></a>
### 多个赋值
如果调用一个函数反复多个值,可以将他们赋值给元组(tuple)<br />前面我们已经可以在汇编中创建函数,这些函数可以返回多个值。<br />使用汇编函数可以一次分配多个值。 请参阅代码段:
assembly {
function f() -> a, b {}
let c, d := f()
}
<a name="b4b7e98d"></a>
### 栈平衡(Stack balancing)
在每个 `assembly { ... }` 块的末尾,必须平衡堆栈(除非另有要求)。 否则,编译器将生成警告。
<a name="ec35a9d6"></a>
## Solidity中的独立汇编(Standalone Assembly)
为了实现向后兼容性,Solidity也支持独立汇编 ,但Solidity文档中不再有说明。<br />以下的特性只存在于独立汇编中:
<a name="39998066"></a>
### 直接的栈控制
独立汇编允许使用两组操作码:`dup`和`swap`指令。 这些操作码可直接控制堆栈(Int
- `dup1`到`dup16`的du``p指令允许在堆栈上复制值。
- `swap`指令(从swap1到swap16)允许交换堆栈上的值。
**直接堆栈分配**(以“指令样式”):`3 =: x`<br />**跳转操作码**:`jump`和`jumpi`
<a name="736915ad"></a>
## Solidity中的函数式风格汇编
对于一些操作码,可能很难看到实际的参数是什么。 为什么?<br />因为Solidity Assembly中的操作码必须以函数样式编写。 让我们来看一个来自Solidity文档的示例:
// Functional style mstore(0x80, add(mload(0x80), 3))
本示例是在位于内存地址0x80的内容加3。 我们可以用非函数式重新编写此操作码序列,如下所示:
// Non-Functional style 3 0x80 mload add 0x80 mstore
让我们更仔细地分析。 从右到左读取代码,您将得到完全相同的常量和操作码序列。 因此其实:汇编代码的函数式版本只是非函数式版本的符号调转。<br />两个版本有各自的优缺点:
- **函数式**: 更容易了解哪个操作数(operand)作用于哪个操作码(opcode)。
- **非函数式**:更容易看到这些值最终在堆栈中的位置。
为了让理解更简单,我绘制了每个指令后的堆栈表现图。:
mstore(0x80, add(mload(0x80), 3)) // Functional style
3 0x80 mload add 0x80 mstore // Non-Functional style
// Layout of the stack after each instructions
empty PUSH 3 PUSH 0x80 MLOAD ADD PUSH 0x80 MSTORE
|0x80| > |5| |0x80|
|_| > |3| > |3| > |3| > |8| > |8| > |_|
```
非函数式(我称其为指令式)可以更好地概述堆栈布局。 因为它提供了有关EVM执行顺序的清晰图。
因此,如果您关心确切的堆栈布局,请记住:操作码的第一个参数始终在堆栈的顶部结束!
内联汇编不能做的事
不同的内联汇编块不共享任何名称空间,即,不可能调用Yul函数或访问在其他内联汇编块中定义的Yul变量。
编写汇编的缺点
Solidity文档指出以下内容:
内联汇编是一种以较低级别访问以太坊虚拟机的方法。 这绕过了几个重要的安全功能和Solidity的检查。 仅当您有信心及必需时才使用它。
实际上,在Solidity中编写汇编代码并非没有挑战。 我列出了一些重要的点。
汇编中都是uint
EVM汇编中的算术运算忽略了某些类型可以小于256位的(例如:uint64)。
例如,一个地址长20个字节。 你还可以在Solidity中指定较小的类型,例如bytes10或uint128。
为了提高效率,EVM汇编将每个值都视为256位数字。
高阶位仅在必要时才清除(例如:执行比较或写入内存之前)
这意味着,如果您从内联汇编中访问此类变量,则可能必须先手动清除高阶位。编写汇编代码会很快成为负担…

若有收获,就点个赞吧
0 人点赞
