聚簇索引
一句话解释:聚簇索引就是主键索引,用于确定一行数据的标识。主键索引可以唯一确定一行数据。
细说:聚簇索引在B+Tree索引树中的叶子节点存储的是行数据。
数据表:主键为id,辅助索引为name
| id | name | age |
|---|---|---|
| 1 | 陈汤姆 | 27 |
| 2 | 朱杰瑞 | 25 |
| 3 | 张三 | 29 |
| 4 | 李四 | 30 |
通过B+Tree的数据结构来表示:

非聚簇索引
一句话解释:非聚簇索引则相反,需要先确定主键索引后,再通过主键索引确定数据。
细说:非聚簇索引在B+Tree索引树中的叶子节点存储的是主键索引的值。因此通过非聚簇索引查询数据时,先定位到主键索引,然后再通过主键索引去主键索引B+Tree中查询行数据,这个过程叫回表。
数据表:主键为id,辅助索引为name
| id | name | age |
|---|---|---|
| 1 | 陈汤姆 | 27 |
| 2 | 朱杰瑞 | 25 |
| 3 | 张三 | 29 |
| 4 | 李四 | 30 |
通过B+Tree的数据结构来表示: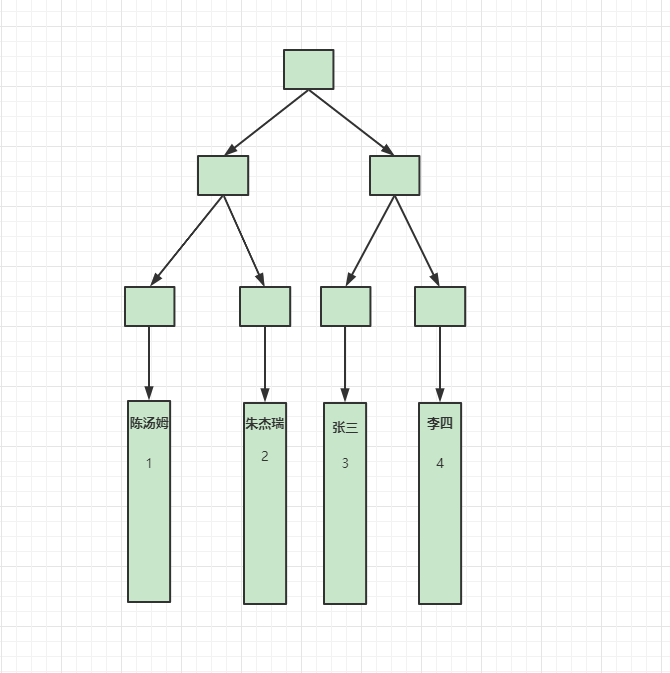
从以上的B+Tree中看到非聚簇索引的叶子节点存储的是当前辅助索引的值以及主键值,非聚簇索引要查询行数据时,通过叶子节点上的主键值在主键索引的B+Tree上进行遍历获取行数据。过程如下: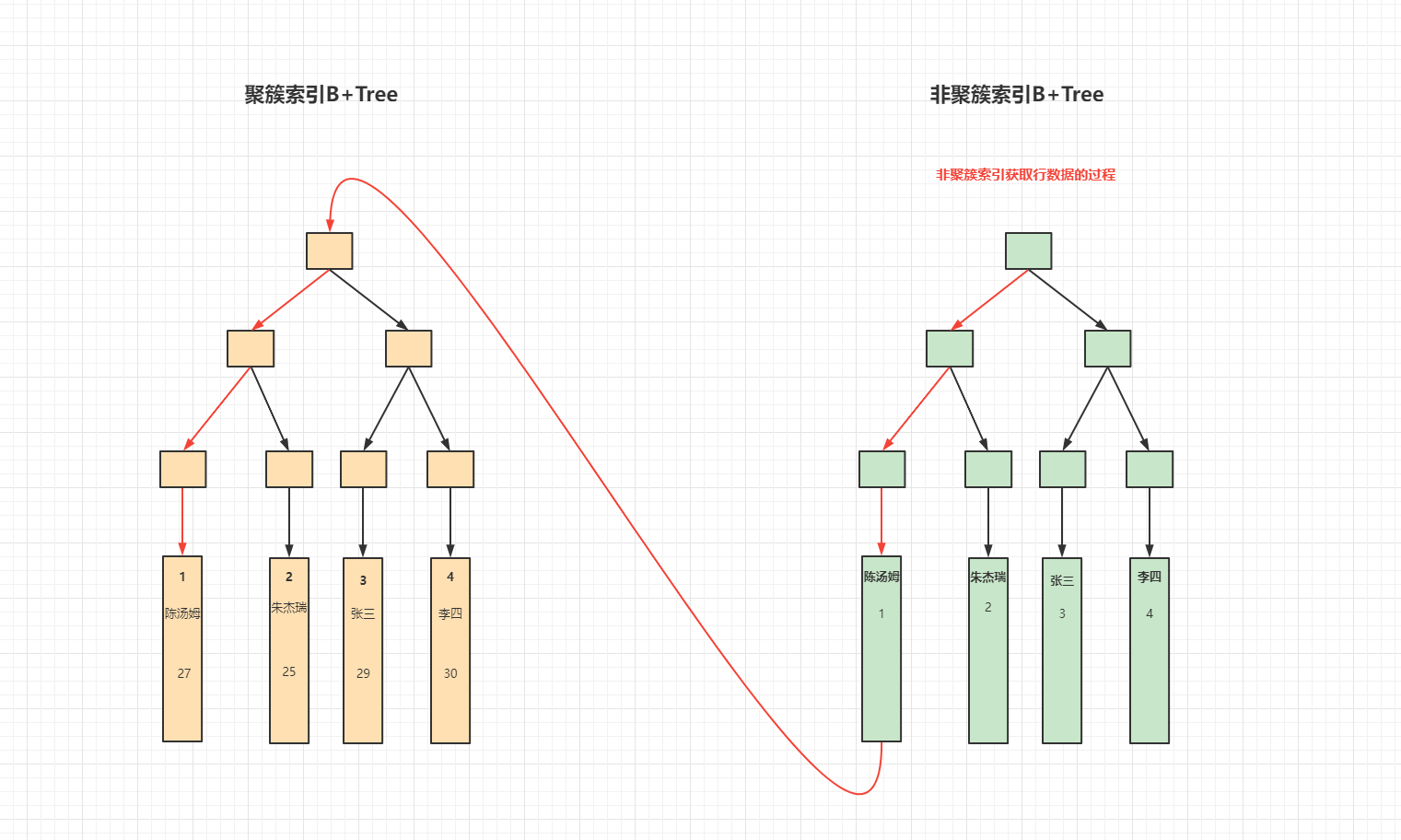
为什么要这样设计
- 主键索引构建的B+Tree中叶子节点存储的是行数据,因此当新插入一条数据时只要按照当前节点后续插入即可,无需进行寻址,也不需要重新构建树。当叶子节点的页满了之后会自动开辟一张新的页进行存储。提高了插入数据的效率
- 非聚簇索引的叶子节点指针指向的是主键而不是行数据的内存地址,这样的好处在于当数据发生变化时不需要一直维护非聚簇索引的叶子节点指针数据,无论数据如何变化,只要非聚簇索引的叶子节点指向的是主键值,那么也可以快速查询到行数据。
引用
- 阿里巴巴Java性能调优实战

若有收获,就点个赞吧
0 人点赞
